大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用


摘要:本文详细介绍如何利用深度学习中的YOLO及SORT算法实现车辆、行人等多目标的实时检测和跟踪,并利用PyQt5设计了清新简约的系统UI界面,在界面中既可选择自己的视频、图片文件进行检测跟踪,也可以通过电脑自带的摄像头进行实时处理,可选择训练好的YOLO v3/v4等模型参数。该系统界面优美、检测精度高,功能强大,设计有多目标实时检测、跟踪、计数功能,可自由选择感兴趣的跟踪目标。博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
文章目录
环境配置及演示视频链接:https://www.bilibili.com/video/BV1S64y1U7VA/(正在更新中,欢迎关注博主B站视频)
前言
前段时间博主写了一篇基于深度学习的车辆检测系统博文,里面是利用MATLAB实现的YOLO检测器,效果还不错,其完善的UI界面也受到不少粉丝的关注。最近有不少朋友发消息询问是否打算出一期Python版的车辆检测系统,其实我也早有写一篇类似博文的想法,毕竟老不更新粉丝都要跑( ๑ŏ ﹏ ŏ๑ )了。但每次想写博客又看到自己每天满满当当的日程,感觉无可奈何,没办法只得强行挤出一点点时间写点东西。那这里就强行开一个新坑,更新一下最近推出了车辆行人检测跟踪系统,准备从算法到模型训练、QT界面等实现细节跟大家做一个分享。由于博主实在太忙,这一系列可能不会更新很快,还请见谅,感兴趣的朋友可以在下方评论督促一下或私信交流,如若大家反响热烈,必定立即更新下一篇!
书归正传,车辆/行人等多目标的检测跟踪毫无疑问是当前视觉领域的网红方向,因为智能交通、无人驾驶的时代正呼之欲出,视觉检测自当是研究的基础。那么抛开这些大概念,我们如果想自己实现多目标检测跟踪的功能,有没有合适的算法去借鉴的呢?考虑到实时性,个人更加青睐YOLO算法,YOLO经过几代的发展,性能上有了很大提升,这里便采用YOLO模型进行目标检测。至于目标跟踪,权衡几种算法后我选择 SORT (Simple Online and Realtime Tracking, SORT)算法。
除此之外,一个舒服的系统界面是非常必要的,网上检测跟踪的代码很多,但几乎没有人将其开发成一个完整软件,有的也是粗犷简陋的界面。为此博主花了一番时间,精心设计了一款合适的界面,也是参考当前流行的客户端样式,不敢说精美,也算是保持了博主对界面清新、简约的风格了。这里上一张清晰的初始界面截图(点击图片可放大):
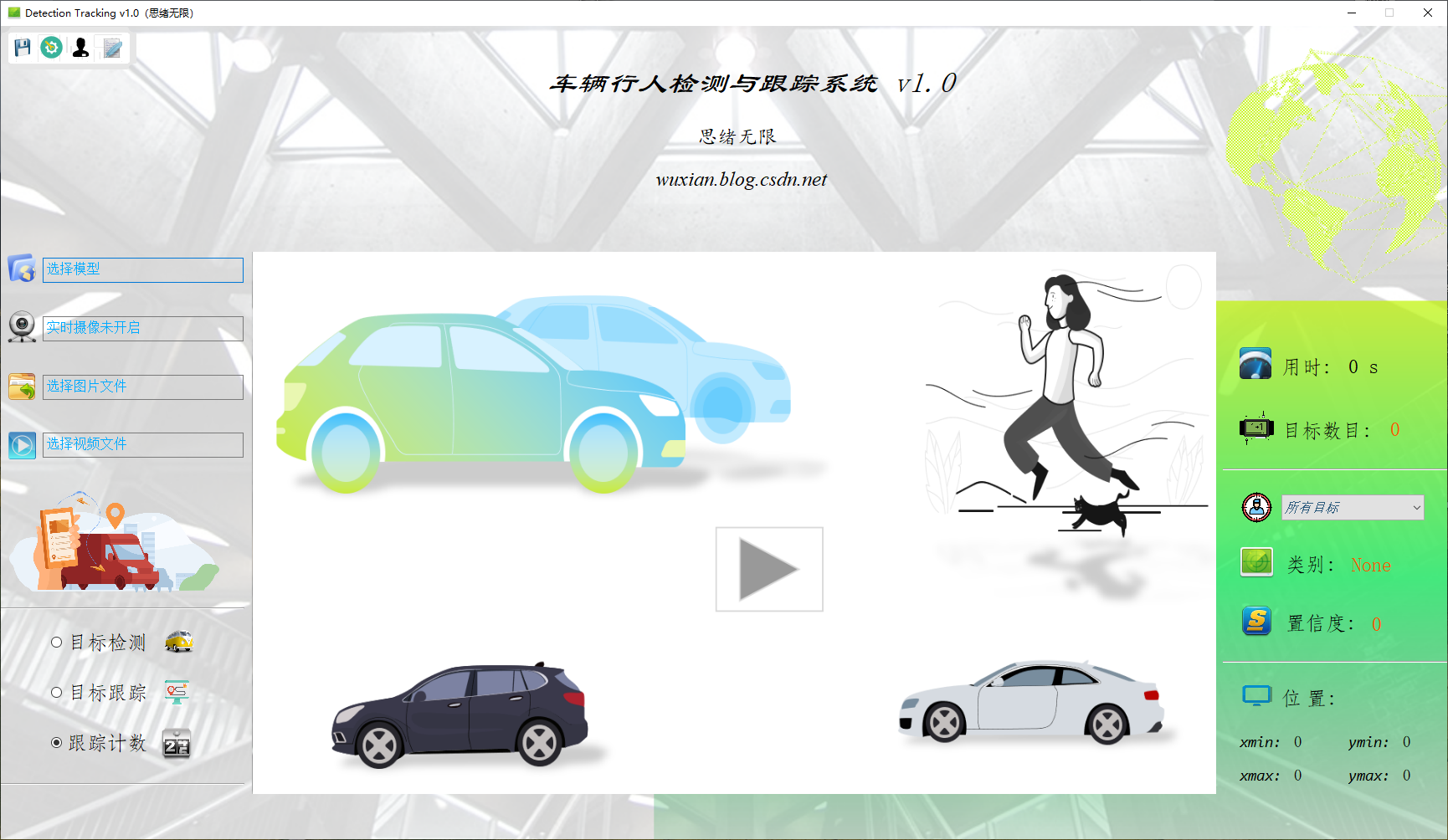
检测图片时的截图(点击图片可放大)如下,若为视频检测则可选择增加轨迹效果:

详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
1. 功能及效果演示
首先展示一下检测跟踪系统软件的功能和效果,系统主要实现的功能是车辆、行人等多目标的实时检测和跟踪,在界面中既可选择自己的视频、图片文件进行检测跟踪,也可以通过电脑自带的摄像头进行实时处理,可选择训练好的YOLO v3/v4等模型参数。
(1)选择视频文件进行检测跟踪:点击左侧视频按钮可弹出文件选择窗口,选择一个自己的MP4或AVI视频文件即可显示视频画面,目标标注在画面框中,右侧显示用时、目标数、置信度、位置坐标,要跟踪的目标可通过下拉框选择。

(2)选择画面中要跟踪的目标:在视频或摄像检测跟踪的过程中,如若想指定某个目标进行跟踪,可通过右侧的目标下拉选框选择,选择时画面暂停等待选择完成,画面中标注框定位到选中的目标。

(3)目标检测、跟踪、计数功能的切换:选择左侧选项,可切换检测、跟踪、计数功能,选择“跟踪计数”可在目标上标记运动轨迹并计数。

(4)利用摄像头进行检测跟踪:点击左侧摄像头按钮,则自动打开电脑上的摄像头设备,检测跟踪的标记信息同样显示在界面中。

(5)选择图片进行目标检测:点击图片选择按钮,弹出图片选择框选中一张图片进行检测,可自由浏览选中某个或多个对象。

2. 视频中的目标检测
由于整个软件的实现代码复杂,为了使得介绍循序渐进,首先介绍如何利用YOLO进行视频中目标对的检测。对于图像中的目标检测算法,其中比较流行的有YOLO、SSD等算法。这里我们使用YOLO v4/v3,这篇博文更多介绍的是如何通过代码使用YOLO,对于算法的原理细节和训练过程会在接下来的博文介绍。首先导入需要的依赖包,其代码如下:
from collections import deque
import numpy as np
import imutils
import time
import cv2
import os
from tqdm import tqdm
接下来进行参数设置,首先设置要检测的视频路径,这里需要修改为自己的视频路径;然后我们需要加载训练好的配置、模型权重参数,以及训练数据集的标签名称(类别)文件,它们的路径分别由变量labelPath、weightsPath、configPath表示。还有一些预定义的参数:filter_confidence(置信度阈值)和threshold_prob(非极大值抑制阈值),它们分别用于筛除置信度过低的识别结果和利用NMS去除重复的锚框:
# 参数设置
video_path = "./video/pedestrian.mp4" # 要检测的视频路径
filter_confidence = 0.5 # 用于筛除置信度过低的识别结果
threshold_prob = 0.3 # 用于NMS去除重复的锚框
model_path = "./yolo-obj" # 模型文件的目录
# 载入数据集标签
labelsPath = os.path.sep.join([model_path, "coco.names"])
LABELS = open(labelsPath).read().strip().split("\n")
# 载入模型参数文件及配置文件
weightsPath = os.path.sep.join([model_path, "yolov4.weights"])
configPath = os.path.sep.join([model_path, "yolov4.cfg"])
以下代码通过上面给出的路径从配置和参数文件中载入模型,载入模型使用OpenCV的readNetFromDarknet方法载入,我们可以利用它载入自行训练的模型权重以进行检测操作:
# 从配置和参数文件中载入模型
print("[INFO] 正在载入模型...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
为了后面标记检测的目标标记框以及目标移动路径,这里创建两个变量存储标记框的颜色及移动路径的点坐标,其代码如下:
# 初始化用于标记框的颜色
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(200, 3), dtype="uint8")
# 用于展示目标移动路径
pts = [deque(maxlen=30) for _ in range(9999)]
准备就绪,开始从视频文件路径初始化视频对象,其代码如下:
# 初始化视频流
vs = cv2.VideoCapture(video_path)
(W, H) = (None, None)
frameIndex = 0 # 视频帧数
尝试读取视频帧并获取视频总帧数total、每帧画面的尺寸(vw, vh),同时创建一个视频写入对象output_video用于后面保存检测标记的视频,该部分代码如下:
# 试运行,获取总的画面帧数
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
else cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
print("[INFO] 视频总帧数:{}".format(total))
# 若读取失败,报错退出
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
fourcc = cv2.VideoWriter_fourcc(*'XVID')
ret, frame = vs.read()
vw = frame.shape[1]
vh = frame.shape[0]
print("[INFO] 视频尺寸:{} * {}".format(vw, vh))
output_video = cv2.VideoWriter(video_path.replace(".mp4", "-det.avi"), fourcc, 20.0, (vw, vh)) # 处理后的视频对象
接下来开始遍历视频帧进行检测,为了清楚地显示检测进度,我这里使用了tqdm,它可以在运行的命令行中显示当前的进度条。读取当前视频帧可以使用OpenCV中VideoCapture的read(),该方法返回当前画面和读取标记,可通过标记判断是否到达视频最后一帧:
# 遍历视频帧进行检测
for fr in tqdm(range(total)):
# 从视频文件中逐帧读取画面
(grabbed, frame) = vs.read()
# 若grabbed为空,表示视频到达最后一帧,退出
if not grabbed:
break
# 获取画面长宽
if W is None or H is None:
(H, W) = frame.shape[:2]
接下来的代码在以上for循环中进行。首先将当前读取到的画面帧读入YOLO网络中,在利用网络预测前需要对输入画面(图片)进行处理,利用cv2.dnn.blobFromImage对图像进行归一化并将其尺寸设置为(416,416),这也是YOLO网络训练时图片的尺寸。处理后可利用net.forward进行预测,得到检测结果,其代码实现如下:
# 将一帧画面读入网络
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
以上代码中layerOutputs即为检测结果,这里写一个循环从中将检测框坐标、置信度值、识别到的类别序号分别存放在boxes、confidences、classIDs变量中。layerOutputs的结果是按照检测对象存放的,在循环中我们还需根据置信度值的阈值过滤掉一些置信度值不高的结果:
boxes = [] # 用于检测框坐标
confidences = [] # 用于存放置信度值
classIDs = [] # 用于识别的类别序号
# 逐层遍历网络获取输出
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability)
# of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# 过滤低置信度值的检测结果
if confidence > filter_confidence:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 转换标记框
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新标记框、置信度值、类别列表
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
对于以上整理出的结果,可能存在重复或者接近的标记框位置,我们可以使用NMS(非极大值抑制)技术去除:
# 使用NMS去除重复的标记框
idxs = cv2.dnn.NMSBoxes(boxes, confidences, filter_confidence, threshold_prob)
最终我们将得到去除后的索引,利用它可以得到NMS操作后的标记框坐标、置信度值、类别序号列表,可通过以下的for循环实现,最终结果存放在dets变量中:
dets = []
if len(idxs) > 0:
# 遍历索引得到检测结果
for i in idxs.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
dets.append([x, y, x + w, y + h, confidences[i], classIDs[i]])
np.set_printoptions(formatter={
'float': lambda x: "{0:0.3f}".format(x)})
dets = np.asarray(dets)
目标检测的效果如下图所示:

3. 多目标跟踪
通过上一节的介绍我们了解了如何使用YOLO进行目标检测,当在对视频中的多个对象进行检测时,可以看到标记框随着目标的移动而不断移动,那么如何才能确定当前帧中的对象与之前一帧中的对象是否是同一个呢?这其实涉及到目标跟踪的概念,可以理解为随着时间的推移,多次进行检测以识别某些特定的目标,并得到目标运动的轨迹。
对于目标跟踪部分,在权衡几种算法后,我决定选择 SORT (Simple Online and Realtime Tracking, SORT)算法,它易于实现、运行速度快。该算法其实来源于Alex Bewley等人在2017年发表的一篇论文:Bewley A, Ge Z, Ott L, et al. Simple online and realtime tracking[C]//2016 IEEE international conference on image processing (ICIP). IEEE, 2016: 3464-3468.,该论文提出使用卡尔曼滤波器来预测先前识别出的物体的轨迹,并将它们与新的检测结果相匹配。论文作者给出了SORT算法的Python实现,网址为:https://github.com/abewley/sort,博主目标跟踪的这部分代码引用自该实现,在其基础上我作了改写以适合使用。
首先初始化一个SORT对象tracker,使用tracker.update方法进行跟踪,得到跟踪到的标记结果boxes(标记框坐标)、indexIDs(当前目标计数序号,即第几个出现的目标)、cls_IDs(类别序号),该部分代码如下:
# 使用sort算法,开始进行追踪
tracker = Sort() # 实例化追踪器对象
tracks = tracker.update(dets)
boxes = [] # 存放追踪到的标记框
indexIDs = []
cls_IDs = []
c = []
for track in tracks:
boxes.append([track[0], track[1], track[2], track[3]])
indexIDs.append(int(track[4]))
cls_IDs.append(int(track[5]))
得到跟踪结果后,就剩在图像帧中进行标记了。我们遍历所有的标记框,按照标记框的坐标以及对应的类别、置信度值、目标个数可以达到可视化的效果。为了更加形象了解目标运动的情况,通过遍历pts变量,利用OpenCV的cv2.line方法可以绘制出目标的运动轨迹:
if len(boxes) > 0:
i = int(0)
for box in boxes: # 遍历所有标记框
(x, y) = (int(box[0]), int(box[1]))
(w, h) = (int(box[2]), int(box[3]))
# 在图像上标记目标框
color = [int(c) for c in COLORS[indexIDs[i] % len(COLORS)]]
cv2.rectangle(frame, (x, y), (w, h), color, 4)
center = (int(((box[0]) + (box[2])) / 2), int(((box[1]) + (box[3])) / 2))
pts[indexIDs[i]].append(center)
thickness = 5
# 显示某个对象标记框的中心
cv2.circle(frame, center, 1, color, thickness)
# 显示目标运动轨迹
for j in range(1, len(pts[indexIDs[i]])):
if pts[indexIDs[i]][j - 1] is None or pts[indexIDs[i]][j] is None:
continue
thickness = int(np.sqrt(64 / float(j + 1)) * 2)
cv2.line(frame, (pts[indexIDs[i]][j - 1]), (pts[indexIDs[i]][j]), color, thickness)
# 标记跟踪到的目标和数目
text = "{}-{}".format(LABELS[int(cls_IDs[i])], indexIDs[i])
cv2.putText(frame, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 3)
i += 1
以上操作成功将标记信息写入了frame画面中,要想实时显示在屏幕上只需调用OpenCV中的imshow方法开启一个窗口显示:
# 实时显示检测画面
cv2.imshow('Stream', frame)
output_video.write(frame) # 保存标记后的视频
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# print("FPS:{}".format(int(0.6/(end-start))))
frameIndex += 1
if frameIndex >= total: # 可设置检测的最大帧数提前退出
print("[INFO] 运行结束...")
output_video.release()
vs.release()
exit()
运行以上代码可以得到下图中的效果:

至此视频中多目标检测跟踪的代码实现部分介绍完毕,后面的博文中将给出训练程序以及UI界面的详细介绍,至于程序如何使用、依赖包安装、pycharm及anaconda软件的安装过程将通过博主的B站视频进行演示介绍,敬请关注!
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括模型权重,py, UI文件等,如下图),这里已打包上传至博主的面包多平台和CSDN下载资源。本资源已上传至面包多网站和CSDN下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
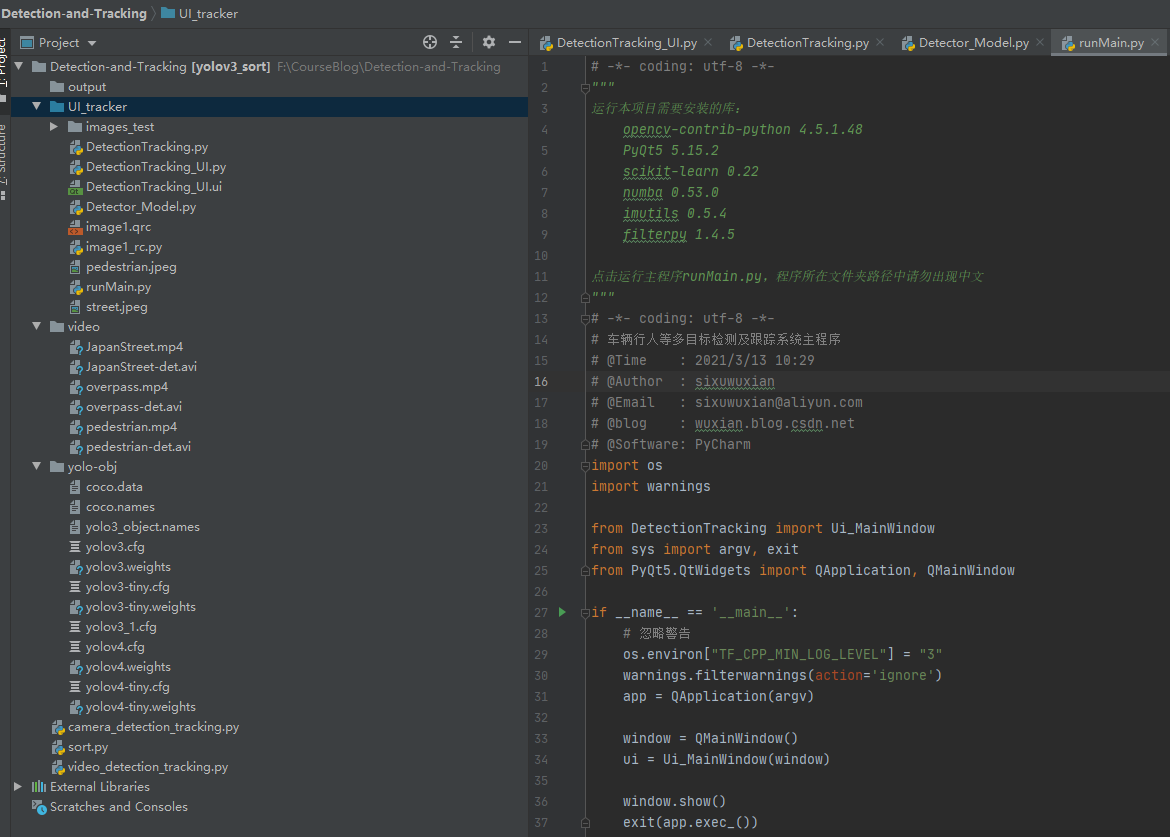
注意:本资源已经过调试通过,下载后可通过PyCharm运行;运行界面的主程序为runMain.py,在配置好Python环境后可完美运行;camera_detection_tracking.py及video_detection_tracking.py这两个分别为使用摄像头、视频检测跟踪的脚本文件,亦可直接运行;为确保程序顺利运行,建议配置的Python依赖包版本如下:➷➷➷
(Python版本:3.8)
opencv-contrib-python 4.5.1.48
PyQt5 5.15.2
scikit-learn 0.22
numba 0.53.0
imutils 0.5.4
filterpy 1.4.5
tqdm 4.56.0
完整资源下载链接:博主的完整资源下载页
代码使用介绍及演示视频链接:https://www.bilibili.com/video/BV1S64y1U7VA/(尚在更新中,欢迎关注博主B站视频)
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。如果本博文反响较好,其界面部分也将在下篇博文中介绍,所有涉及的GUI界面程序也会作细致讲解,敬请期待!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182560.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
