大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
mycat读写分离
Mycat的读写分离是建立在Mysq的主从复制的基础上的 修改配置文件 schema.xml


<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="mytest" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.179.148:3306" user="root"
password="123456">
<readHost host="hostS1" url="jdbc:mysql://192.168.179.150:3306" user="root"
password="123456"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
一 设置balance=”1″与writeType=“0”
Balance参数设置: 修改的balance属性,通过此属性配置读写分离的类型 负载均衡类型,目前的取值有4 种:
(1) balance=“0”, 不开启读写分离机制, 所有读操作都发送到当前可用的 writeHost 上。
(2) balance=“1”,全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从 模式(M1->S1, M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。
(3) balance=“2”,所有读操 作都随机的在 writeHost、 readhost 上分发。
(4) balance=“3”,所有读请求随机的分发到 readhost 执行, writerHost 不负担读压力
WriteType参数设置:
- writeType=“0”, 所有写操作都发送到可用的writeHost上。
- writeType=“1”,所有写操作都随机的发送到readHost。
- writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
“readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机 了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考 虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点 还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。”
二设置switchType=“2” 与slaveThreshold=“100”
switchType 目前有三种选择:
-1:表示不自动切换
1 :默认值,自动切换
2 :基于MySQL主从同步的状态决定是否切换
“Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType=“2” 与 slaveThreshold=“100”,此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过 检测 show slave status 中的 “Seconds_Behind_Master”, “Slave_IO_Running”, “Slave_SQL_Running” 三个字段来 确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。“
垂直拆分——分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类, 分布到不同 的 数据库上面,这样也就将数据或者说压力分担到不同的库上面, 如何划分表 分库的原则: 有紧密关联关系的 表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
编写配置文件schema.xml

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="mytest" />
<dataNode name="dn2" dataHost="host2" database="mytest" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.179.148:3306" user="root"
password="123456">
<readHost host="hostS1" url="jdbc:mysql://192.168.179.150:3306" user="root"
password="123456"></readHost>
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.179.152:3306" user="root"
password="123456">
<readHost host="hostS1" url="jdbc:mysql://192.168.179.149:3306" user="root"
password="123456"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
启动mycat查看是否有mycat端口号8066

我们使用mycat中间件登录进mysql数据库并查看里面库与表
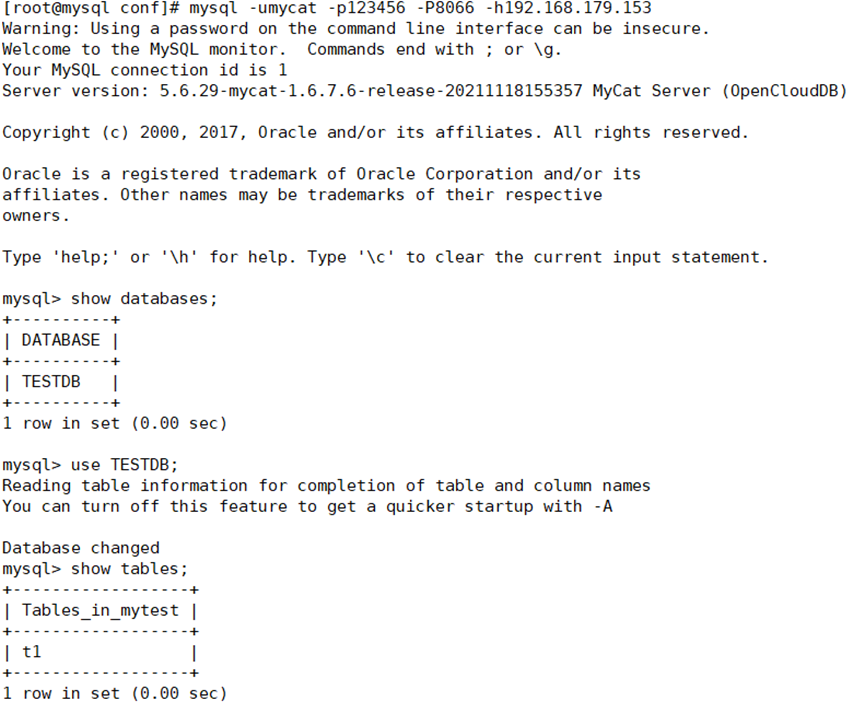
我们在库中创建四个数据表并查看是否创建成功
此时就可以在主从服务器上查看创建的表,在逻辑上来说将四个表聚合到一起

水平拆分——分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中, 每个表中 包 含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就 是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中.
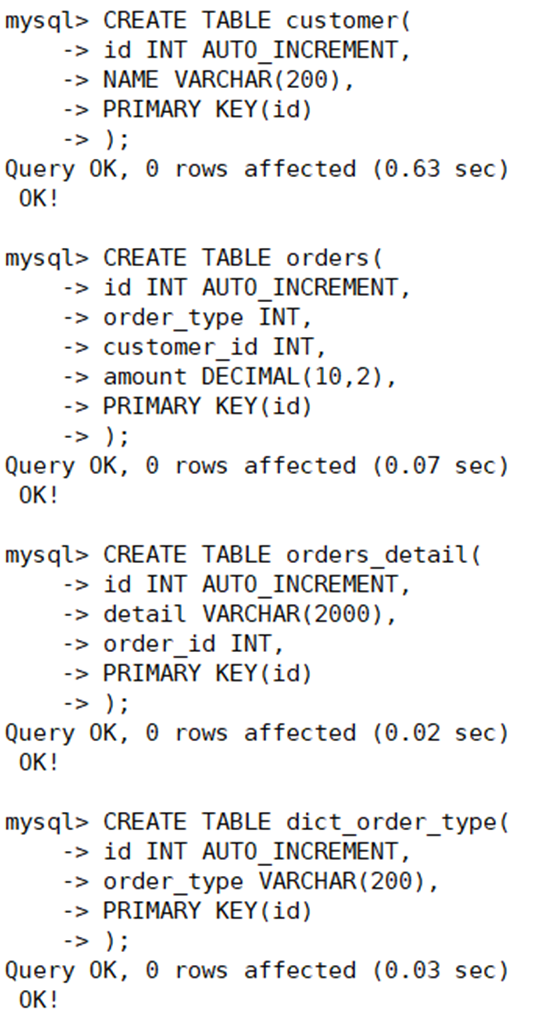
实现分表 选择要拆分的表 MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会 影响查询效率, 需要进行水平拆分(分表) 进行优化。 例如:例子中的 orders、 orders_detail 都已经达到 600 万行数据,需要进行分表优化。 分表字段 以 orders 表为例,可以根据不同自字段进行分表

编写配置文件schema.xml

将orders放到dn1,dn2上必须有一个规则
编辑rule文件
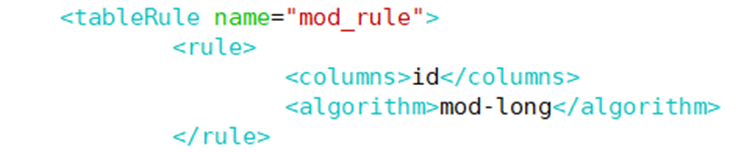
上文件下面找到mod-log更改为2

启动mycat服务
用mycat中间件登录mysql服务器
往orders表中插入几条数据查看是否插入成功

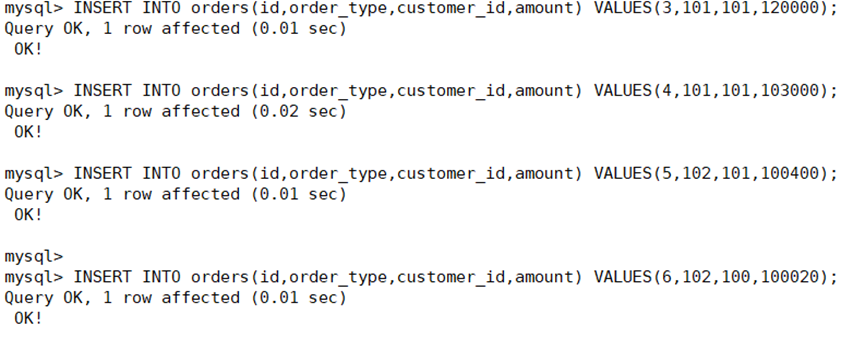
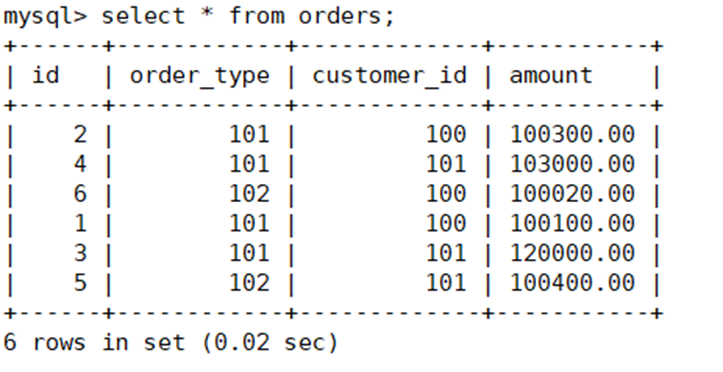
实现读写分离
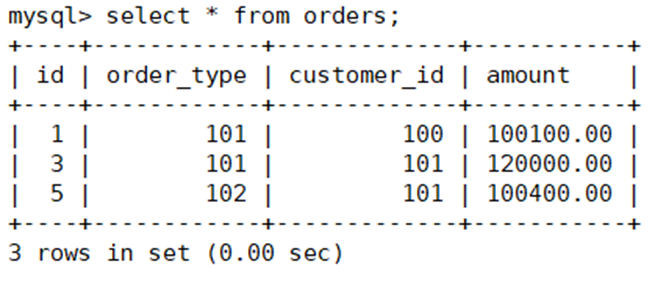
在第一台主上查看文件
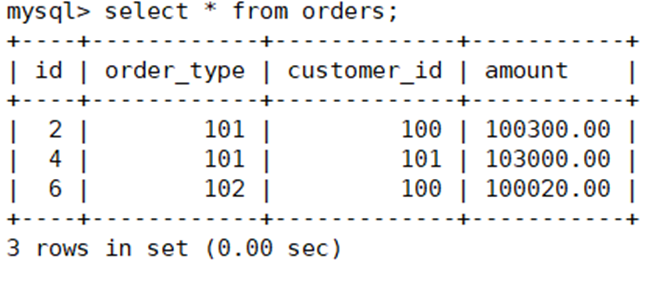
在第二台主上查看文件
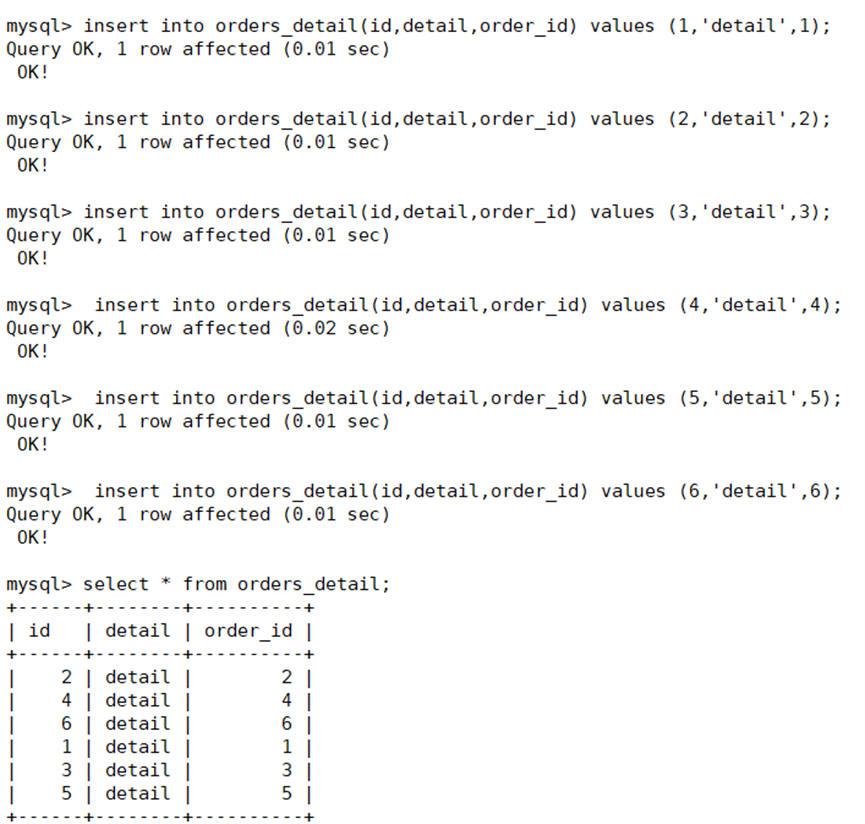
往orders_detail表中插入几条数据查看是否插入成功
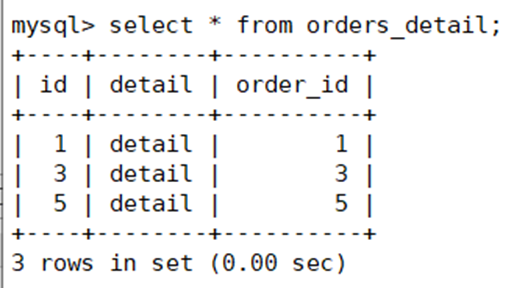
在第一台主上查看
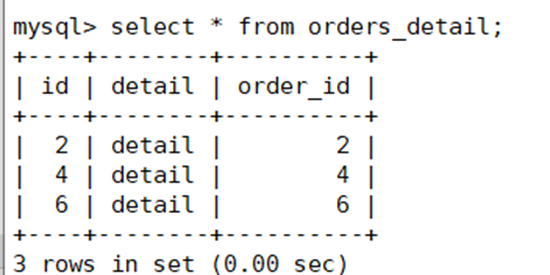
在第二台主上查看
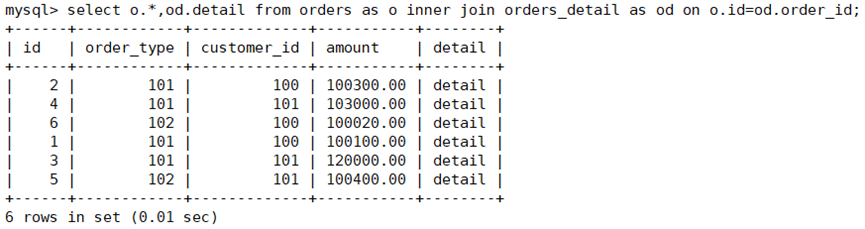
用视图查看两表结合数据
2、 全局表 在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联, 就 成了比较 棘手的问题,考虑到字典表具有以下几个特性: ① 变动不频繁 ② 数据量总体变化不大 ③ 数据规模不 大,很少有超过数十万条记录 鉴于此, Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性: ① 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性 ② 全局表的查询操作,只从 一个节点获取 ③ 全局表可以跟任何一个表进行 JOIN 操作 将字典表或者符合字典表特性的一些表定义为全局 表,则从另外一个方面,很好的解决了数据 JOIN 的难题。 通过全局表+基于 E-R 关系的分片策略, Mycat 可 以满足 80%以上的企业应用开发
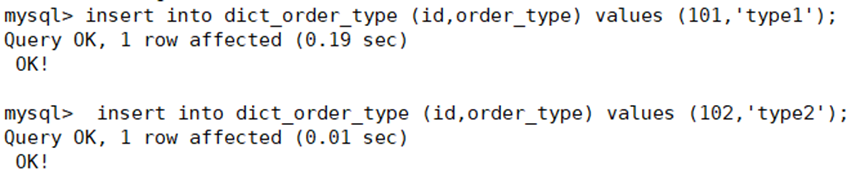
往往orders_detail表中插入几条数据查看是否插入成功
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182518.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
