大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
使用两种方法,通过python计算基尼系数。
在sql中如何计算基尼系数,可以查看我的另一篇文章。两篇文章取数相同,可以结合去看。
文章中方法1的代码来自于:(加入了一些注释,方便理解)。为精确计算。
如果对于基尼系数概念不太清楚,可以看原文的第一部分。
方法2和3借鉴资料:方法2和3是近似算法。其中方法3:只适用于一些特殊情况。
http://www.360doc.com/content/14/0911/13/87990_408644530.shtml
————————————————————————————————-
方法一:
#方法1
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as pl
from scipy.integrate import odeint
def gini():
# 计算数组累计值,从 0 开始
wealths = [346, 559, 198, 420, 39, 709, 225, 731, 708, 369, 519,
46, 48, 446, 117, 127, 905, 652, 528, 832, 217, 536,
942, 608, 37, 802, 422, 884, 746, 959, 759, 397, 245,
83, 542, 907, 128, 933, 740, 506, 458, 830, 874, 570,
914, 592, 585, 574, 636, 462, 86, 321, 174, 238, 670,
690, 456, 918, 70, 801, 695, 908, 57, 497, 605, 334,
265, 255, 235, 199, 739, 81, 131, 68, 229, 602, 390,
571, 733, 440, 528, 409, 222, 55, 876, 606, 906, 549,
487, 552, 796, 454, 301, 914, 635, 304, 503, 688, 631,
705]
# 一共是100个数字
# wealths = [1.5, 2, 3.5, 10, 4.2, 2.1, 1.1, 2.2, 3.1, 5.1, 9.5, 9.7, 1.7, 2.3, 3.8, 1.7, 2.3, 5, 4.7, 2.3, 4.3, 12]
cum_wealths = np.cumsum(sorted(np.append(wealths, 0)))
#加上0,再排序,再计算cumsum
# 取最后一个,也就是原数组的和
sum_wealths = cum_wealths[-1]
#倒数第一个
# 人数的累积占比
#就是每个点都会产生一个横坐标
xarray = np.array(range(0, len(cum_wealths))) / np.float(len(cum_wealths) - 1)
# 均衡收入曲线
#就是45度曲线
upper = xarray
# 收入累积占比
yarray = cum_wealths / sum_wealths
#cumsum的占比
# 绘制基尼系数对应的洛伦兹曲线
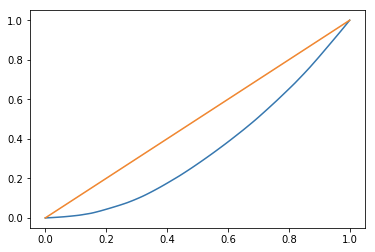
pl.plot(xarray, yarray)
pl.plot(xarray, upper)
# 上面画的是45度线
#ax.plot(xarray, yarray)
#ax.plot(xarray, upper)
#ax.set_xlabel(u'人数累积占比')
#ax.set_ylabel(u'收入累积占比')
#pl.show()
# 计算曲线下面积的通用方法
B = np.trapz(yarray, x=xarray)
# 总面积 0.5
A = 0.5 - B
G = A / (A + B)
print (G)
# 执行函数输出结果
gini()
# 结果为
0.3109641735512392画出来的图:

方法二:
近似的求上图中的面积,将其分割成多个梯形,通过近似计算多个梯形面积,将其加和得到蓝色线条线条下面的面积。
通过简化推到多个梯形面积求和公式,得到一个比较简单的公式,就是链接2中结尾的公式。
如果分组的数量跟样本数量相同,就可以得到精确的数字,计算出来的基尼系数跟上面方法1的结果相等。
如果分组数量降低,获得的基尼系数将稍低于准确的基尼系数,因为更多的将非直线的曲线假设成了直线,即梯形的一边。
# 第二个方法
# 接着上面的定义
# 可能会出现样本数量不能被分组数量均分的情况,所以需要借助python自己包含的分布数组pd.cut
# 分成n个组
n = 100
m = pd.cut(pd.Series(range(1, len(cum_wealths))), bins = n, labels = False)
# 将1到样本数量的整数,分成‘均匀’的n个组
# labels = false生成一些组数,表示这个位置原来的值属于1到n的哪个组
y = m.groupby(by = m).size().cumsum()
# 得到每个分组中的最后一个数的位置在哪里
# size表示每个组里面有多少个元素
# cumsum之后显示每个组里面最后一个元素的位置
#就是图中分为点的位置
t = yarray[y[:]]
#取得在yarray上的值
#就是图中w0 w1 w2等的值
g = 1 - (1/n)*(2*(sum(t)-1)+1)
# 跟文档中的有一点不一样,在最后的计算中减去了1
# 但其实是一致的,文档中分成了5组,w1到w5,求和的是4个y轴值的和,即为w1-w4,是到n-1的和
# 所以可改写成(不要刻意减去1,按照公式,加总到n-1)
g = 1 - (1/n)*(2*(sum(t[0:n-1]))+1)
g
# 结果为
0.3109641735512395
# 相同的计算,只是起始位置稍有不同
# 上面是从1开始,这里是从0开始
# 如果是从0开始,如果第一组中有6个元素,需要取第6个元素,在python中的index是5,所以需要减去1
n = 100
m = pd.cut(pd.Series(range(0, len(cum_wealths))), bins = n, labels = False)
y = m.groupby(by = m).size().cumsum() - 1
t = yarray[y[:]]
g = 1 - (1/n)*(2*(sum(t)-1)+1)
#或者是
g = 1 - (1/n)*(2*(sum(t[0:n-1]))+1)
g
# 结果为
0.3109641735512395
n = 19
m = pd.cut(pd.Series(range(1, len(cum_wealths))), bins = n, labels = False)
y = m.groupby(by = m).size().cumsum()
t = yarray[y[:]]
g = 1 - (1/n)*(2*(sum(t)-1)+1)
g
# 结果为
0.3133532456894873
n = 9
m = pd.cut(pd.Series(range(1, len(cum_wealths))), bins = n, labels = False)
y = m.groupby(by = m).size().cumsum()
t = yarray[y[:]]
g = 1 - (1/n)*(2*(sum(t)-1)+1)
g
#结果为
0.300356286353766
n = 20
m = pd.cut(pd.Series(range(1, len(cum_wealths))), bins = n, labels = False)
y = m.groupby(by = m).size().cumsum()
t = yarray[y[:]]
g = 1 - (1/n)*(2*(sum(t[0:n-1]))+1)
g
#结果为
0.31025484587225693
———————————————————————————————————————————————————————–
最初开始计算时候做的比较简单的思路,但是并不适用于样本数量不能被分组数整除的情况。但可能有助于对基尼系数近似计算的理解,所以放在了这里。
方法三
样本数量能够被分组数均匀分配的情况(仅适用于这个情况),更好的方法详见方法二。
数据的精确度可能还会受样本量和分组量的关系。本文中采用的100个样本和分成100/20/50都是可均匀分配的情况。如果不能均匀分配,可能取m的方式需要优化,应该采取python内含的最大力度均匀分组的函数。
# 第二个方法
#只适用于样本数量能够被分组数量整除的情况
# 接着上面的定义
n = 100
#分成100个组,100个数据分成100个组,每个点和点之间的梯形都计算其面积,‘最精确的近似‘
m = round(len(wealths) / n)
#每个组之间的距离
y = yarray[range(0, len(wealths), m)]
#在y轴上选择那些矩形底部x轴相对应的y轴值
g = 1 - (1/100)*(2*sum(y)+1)
g
# 结果为
0.3109641735512395
#与上面计算的图形下面的面积相等
# 分成20个组
n = 20
m = round(len(wealths) / n)
# 每个组的距离
y = yarray[range(0, len(wealths), m)]
# 这些点的y坐标
g = 1 - (1/n)*(2*sum(y)+1)
g
# 结果为
0.31025484587225693
n = 50
m = round(len(wealths) / n)
y = yarray[range(0, len(wealths), m)]
g = 1 - (1/n)*(2*sum(y)+1)
g
# 结果为
0.3108691564481606
# 当样本量不能被分组数量均匀分配,会出现比较大的偏差。需优化,见方法3。
n = 40
m = round(len(wealths) / n)
y = yarray[range(0, len(wealths), m)]
g = 1 - (1/n)*(2*sum(y)+1)
g
# 结果为
0.13858644556020072
# 不准确
n = 9
m = round(len(wealths) / n)
y = yarray[range(0, len(wealths), m)]
g = 1 - (1/n)*(2*sum(y)+1)
g
# 结果为
0.1003202798725994发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182450.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
