大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
1、逻辑回归
逻辑回归假设数据服从伯努利分布,通过极大化似然函数方法,运用梯度下降来求解参数,来达到将数据二分目的。
2、算法推导
对数几率函数:是一种Sigmoid函数,通过此函数来输出类别概率。
对数几率函数为:
 ,其中y 代表的是样本视为正样本的可能性,则 1-y 为视为负样本的可能性。
,其中y 代表的是样本视为正样本的可能性,则 1-y 为视为负样本的可能性。
对数几率:定义为  ,其中 y/(1-y) 称为比率。
,其中 y/(1-y) 称为比率。
决策边界:作用在 n 维空间,将不同样本分开的平面或曲面,在逻辑回归中,决策边界对应$ wx+b=0 。
3、逻辑参数估计
3.1、使用极大似然法进行参数估计

现学习目标是对参数 w 和b 进行参数估计,使得逻辑回归模型能尽可能符合数据集分布。

现在,即对对数似然函数求极大值,即以对数似然函数为目标的最优化问题。 L(w) 是关于 w 的高阶连续可导凸函数,根据凸优化理论,可采用梯度下降法,牛顿法等优化方法求解。
3.2、逻辑回归的损失函数
逻辑回归的损失函数是交叉熵损失函数,交叉熵主要用于度量分布的差异性

4、逻辑回归的梯度下降
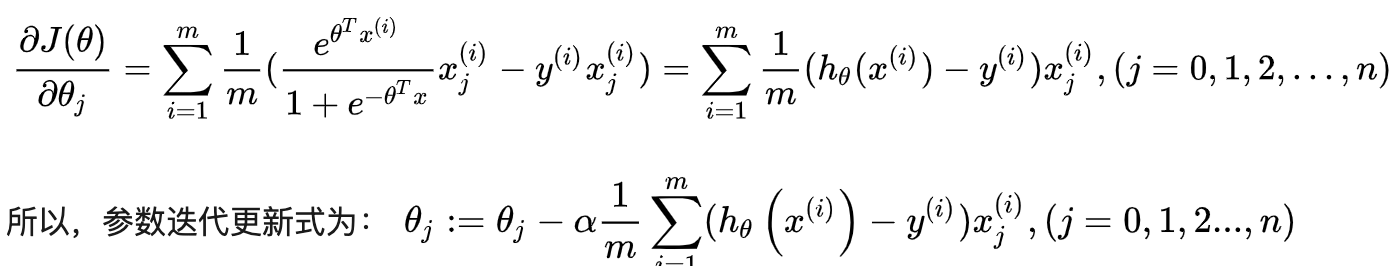
5、多分类逻辑回归
一般逻辑回归是一个二分类模型,可推广至多分类
假设:离散型随机变量 y 的取值集合是 {1,2,…K} ,共有 k 类,则多分类逻辑回归模型的输出概率为:

其中,注意 p(y=k|x)是一个取 1 到 k-1类其中一类, K 是指第 K 类, p(y=K|x) 便是由1减去其他k取值的概率就是第K类的概率。
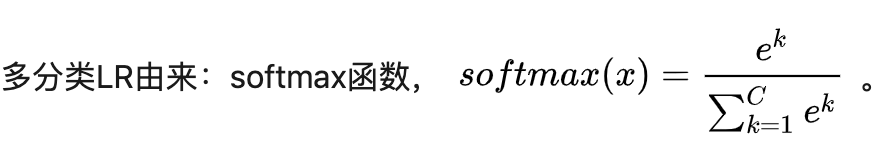
二阶逻辑回归的参数估计法也可推广到多项逻辑回归。
6、逻辑回归的欠、过拟合
6.1、解决过拟合和欠拟合问题
解决LR回归欠拟合:
- 增加特征的维度
解决LR的过拟合:
- 减少特征的数量,可人工特征选择,也可降维等模型算法选择
- 正则化(加入 L1,L2 罚项)
- 逐渐减小梯度下降学习率
6.2、LR 正则化
6.2.1、L1正则化
LASSO 回归,相当于为模型添加了这样一个先验知识:w服从零均值拉普拉斯分布。
拉普拉斯分布:
等价于原始的cross−entropy后面加上了L1正则,因此L1正则的本质其实是为模型增加了“模型参数服从零均值拉普拉斯分布”这一先验知识。
6.2.2、 L2 正则化
Ridge 回归,相当于为模型添加了这样一个先验知识:w服从零均值正态分布。

等价于原始的cross−entropy后面加上了L2正则,因此L2正则的本质其实是为模型增加了“模型参数服从零均值正态分布”这一先验知识。
6.3 、L1正则化和L2正则化的区别
- 如上面所讲,两者引入的关于模型参数的先验知识不一样。
- L1偏向于使模型参数变得稀疏(但实际上并不那么容易),L2偏向于使模型每一个参数都很小,但是更加稠密,从而防止过拟合。
L1偏向于稀疏,L2偏向于稠密,看下面两张图,每一个圆表示loss的等高线,即在该圆上loss都是相同的,可以看到L1更容易在坐标轴上达到,而L2则容易在象限里达到。

L1 L2
7、LR与最大熵模型的关系
先说结论,LR与最大熵模型是等价的,下面证明这一点。

将最大熵模型写成约束问题:


8、逻辑回归的优缺点
LR优点:
- 直接对分类的可能性建模,无需事先假设数据分布,避免了假设分布不准确带来的问题
- 不仅预测出类别,还可得到近似概率预测
- 对率函数是任意阶可导凸函数,有很好得数学性质,很多数值优化算法可直接用于求取最优解
- 容易使用和解释,计算代价低
- LR对时间和内存需求上相当高效
- 可应用于分布式数据,并且还有在线算法实现,用较小资源处理较大数据
- 对数据中小噪声鲁棒性很好,并且不会受到轻微多重共线性影响
- 因为结果是概率,可用作排序模型
LR缺点:
- 容易欠拟合,分类精度不高
- 数据特征有缺失或特征空间很大时效果不好
9、逻辑回归面对线性不可分数据
逻辑回归本质上是一个线性模型,可通过:
- 利用特殊核函数,对特征进行变换把低维空间转换到高维空间,使用组合特征映射(如多项式特征)。但组合特征泛化能力较弱
- 扩展LR算法,提出FM算法
10、逻辑回归通常稀疏的原因
- 分类特征通常采用one-hot转换成数值特征,产生大量稀疏
- 一般很少直接将连续值作为逻辑回归模型输入,而是将连续特征离散化
LR一般需要连续特征离散化原因
- 离散特征的增加和减少都很容易,易于模型快速迭代
- 稀疏向量内积乘法速廈快,计算结果方便存储,容易扩展
- 离散化的特征对异常数据有很强的鲁棒性(比如年龄为300异常值可归为年龄>30这一段
- 逻辑回归属于广义线性模型,表达能力受限。单变量离散化为N个后,每个变量有单独的权重,相当于对模型引入了非线性,能够提升模型表达能力,加大拟合
- 离散化进行特征交叉,由 M+N 个变量为 M*N 个变量(将单个特征分成 M 个取值),进一步引入非线性,提升表达能力
- 特征离散化后,模型会更稳定(比如对用户年龄离散化,20-30作为一个区间,不会因为用户年龄,增加一岁变成完全不同的人,但区间相邻处样本会相反,所以怎样划分区间很重要)
- 特征离散化后,简化了LR模型作用,降低模型过拟合风险
11、逻辑回归和线性回归的异同
相同之处:
- 都使用了极大似然估计来对样本建模。线性回归使用最小二乘法,实际上就是在自变量 x 和参数 w 确定,因变量 y 服从正态分布的假设下,使用最大似然估计的一个化简。逻辑回归通过对似然函数的学习,得到最佳参数 w
- 二者在求解参数的过程中,都可以使用梯度下降的方法
不同之处:
- 逻辑回归处理的是分类问题,线性回归处理的是回归问题
- 逻辑回归中因变量取值是一个二元分布,模型学习得出的是 E[y|x,w] ,即给定自变量和参数后,得到因变量的期望。而线性回归实际上求解的是 y=wx ,是对假设的真实关系 y=wx+e 的一个近似,其中e 是误差项
- 逻辑回归中因变量是离散的,线性回归中的因变量是连续的。并在自变量与参数 w 确定情况下,逻辑回归可以看作广义线性模型在因变量 y 服从二元分布时一个特殊情况,而使用最小二乘法求解线性回归时,我们认为因变量 y 服从正态分布
参考网址:
https://blog.csdn.net/songbinxu/article/details/79633790 (较深入的逻辑回归介绍)
https://zhuanlan.zhihu.com/p/56900935 (较基础的逻辑回归介绍)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182292.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
