大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Mysql Replication 概述
什么是Mysql Replication?
Replication 可以实现将数据从一台数据库服务器(master)复制到一台或多台数据库服务器(slave),默认情况下属于异步复制,无需维持长连接。通过配置,可以复制所有的库或者几个库,甚至库中的一些表。它是 MySQL 内建的,本身自带的功能。
Replication 的原理
简单的说就是 master 将数据库的改变写入二进制日志,slave 同步这些二进制日志,并根据这些二进制日志进行数据操作以实现主从同步。
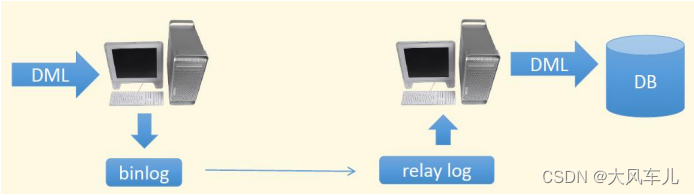

DML:SQL 操作语句,update, insert,delete
binlog:二进制日志
relay log :中继日志
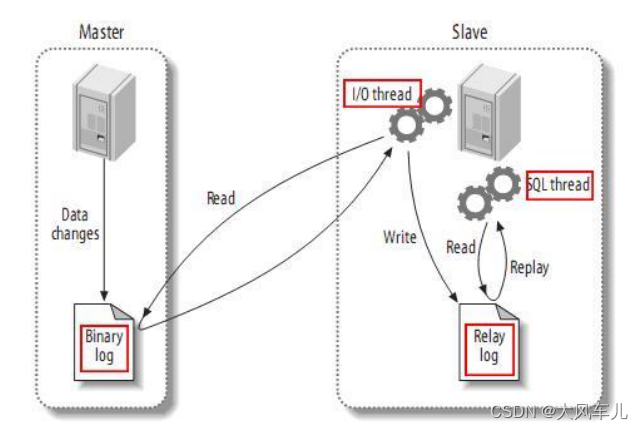
MySQL 主从复制中:
第一步:master 记录二进制日志。在每个事务更新数据完成之前,master 在二进制日志记录这些改变。MySQL 将事务写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master 通知存储引擎提交事务。
第二步:slave 将 master 的 binary log 拷贝到它自己的中继日志。首先,slave 开始一个工作线程——I/O 线程。I/O 线程在 master 上打开一个普通的连接,然后开始 binlog dump process。Binlog dump process 从 master 的二进制日志中读取事件,如果已经执行完 master 产生的所有文件,它会睡眠并等待 master 产生新的事件。I/O 线程将这些事件写入中继日志。
第三步:SQL slave thread(SQL 从线程)是处理该过程的最后一步。SQL 线程从中继日志读取事件,并重新执行其中的事件而更新 slave 的数据,使其与 master 中的数据一致。
Replication的作用
- 1、Fail over (故障切换)
- 2、Backup server (备份服务,无法对 SQL 语句执行产生的故障恢复,有限的备份)
- 3、High Performance (高性能,可以多台 slave,实现读写分离)
Replication 常见方案
1. One master and Muti salve 一主多备
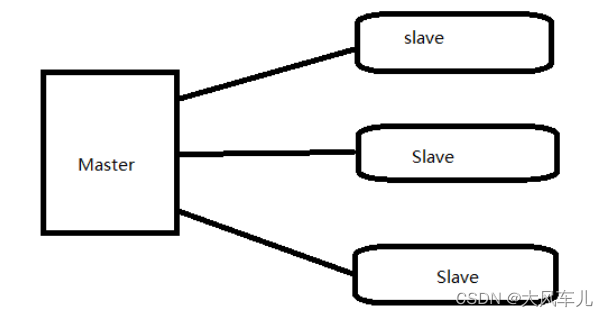
一般用来做读写分离的,master 写,其他 slave 读,这种架构最大问题 I/O 压力集中在 Master 上<多台同步影响 IO>
2. M-S-S
使用一台 slave 作为中继,分担 Master 的压力,slave 中继需要开启 bin-log,并配置 log-slave-updates
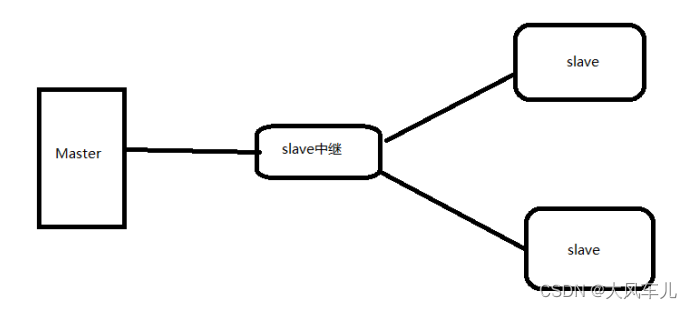
Slave 中继可使用 Black-hole 存储引擎,不会把数据存储到磁盘,只记录二进制日志。
3. M-M 双主互备 (互为主从)
很多人误以为这样可以做到 MySQL 负载均衡,实际没什么好处,每个服务器需要做同样的同步更新,破坏了事物的隔离性和数据的一致性。
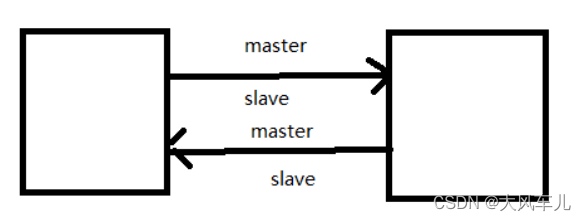
4. M-M-M
监控三台机器互相作对方的 master
天生的缺陷:复制延迟,slave 上同步要慢于 master,如果大并发的情况那延迟更严重
mysql 在 5.6 已经自身可以实现 fail over 故障切换
5. One slave Muti master 一从对多主
好处:节省成本,将多个 master 数据自动化整合
缺陷:对库和表数据的修改较多
部署 MySQL 主从同步
环境准备
基础环境:关防火墙、关selinux、hosts、免密登录、yum源
基础环境的准备不赘述
以下环境准备操作在master、slave都要做
集群规划
| 主机名 | IP | 系统/MySQL 版本 | 角色 |
|---|---|---|---|
| s66 | 192.168.1.66 | CentOS7.6/5.7.25 | Master |
| s67 | 192.168.1.67 | CentOS7.6/5.7.25 | Slave |
| s68 | 192.168.1.68 | CentOS7.6 | MyCat |
安装mysql
到官网下载rpm安装包,下载好后上传到服务器。
官网地址:https://www.mysql.com/cn/
tar xf mysql-5.7.tar.gz # 解压安装包
yum install -y ./mysql*.rpm # 安装mysql
关闭密码强度审计插件
为了实验方便而设置简单密码,生产环境可设置复杂密码而不用关闭。
systemctl start mysqld # 开启mysql
echo "validate-password=OFF">> /etc/my.cnf # 关闭密码强度审计插件
systemctl restart mysqld # 重启mysql
修改mysql root用户密码
grep "password" /var/log/mysqld.log # 查看临时密码
mysql -uroot -p'-NEjo1gbPllh' # 使用临时密码登录数据库
set password for root@localhost = password('123456');
exit
配置主数据库 s66
创建需要同步的数据库
mysql -u root -p'123456' # 登录数据库
create database HA; # 创建数据库HA
use HA; # 进入数据库HA
create table T1(id int,name varchar(20)); # 创建表T1
exit # 退出数据库
修改配置文件
vim /etc/my.cnf
在 [mysqld] 下面加如下内容:
log-bin=mysql-bin-master # 启用二进制日志
server-id=1 # 本机数据库 ID 标示
binlog-do-db=HA #可以被从服务器复制的库, 二进制需要同步的数据库名
binlog-ignore-db=mysql #不可以被从服务器复制的库
systemctl restart mysqld # 重启mysql
授权
mysql -u root -p'123456'
grant replication slave on *.* to slave@192.168.1.64 identified by "123456";
show master status; # 查看状态信息
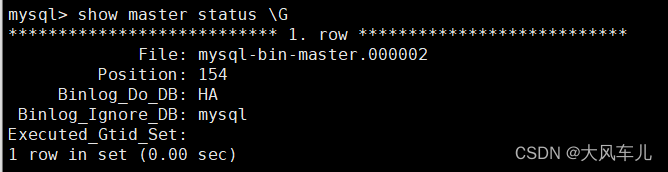
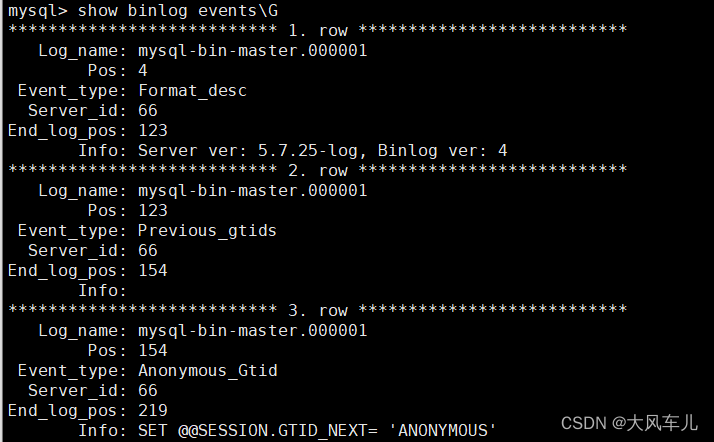
show binlog events\G # 查看二进制日志
exit # 退出
导出要同步的数据库
mysqldump -uroot -p123456 -B HA >HA.sql # 导出要同步的数据库
scp HA.sql s67:/root/ # 将备份文件传到slave服务器
配置从数据库 s67
要同步的两台数据库服务器Mysql版本要一致
mysql -u root -p123456
show variables like '%version%'; # 查看mysql版本
测试连接主服务器
mysql -u slave -p123456 -h 192.168.1.66 # 在s67登录s66数据库
show databases; # 查看数据库
exit
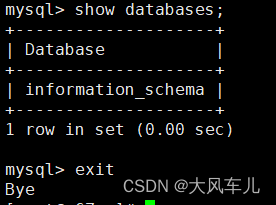
因为slave账号只有复制权限,所以看不到HA数据库。
导入数据
mysql -uroot -p123456 <HA.sql # 导入数据
修改从服务器配置文件
vim /etc/my.cnf
在 [mysqld] 下添加如下内容:
server-id = 67 # 服务器ID,全局唯一
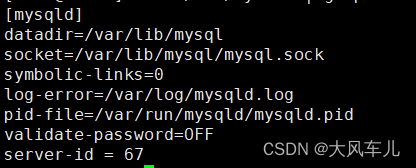
systemctl restart mysqld # 重启服务
mysql -u root -p123456
change master to master_host='192.168.1.66',master_user='slave',master_password='123456'; # 指定要复制的数据库信息
start slave; # 启动slave
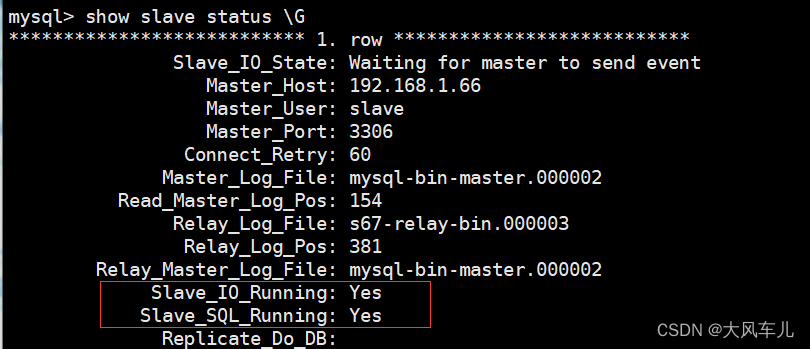
Slave_IO_Running :一个负责与 Master 主机的 IO 通信
Slave_SQL_Running:负责自己的 slave mysql 进程
看到图中标红的两个线程均为 YES 则成功
主从同步情况测试
到master上查看状态
mysql -u root -p123456
show processlist \G
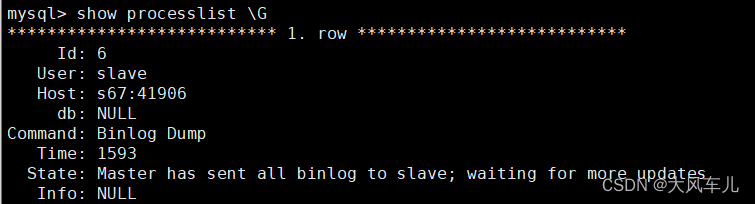
插入数据测试同步
在master上插入数据:
use HA;
insert into T1 values (1,'man'); # 插入数据
在slave上查看 :
use HA;
select * from T1; # 查看数据
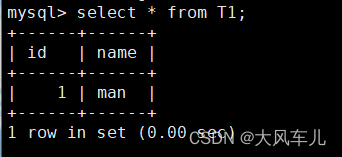
主从同步搭建成功!
排错
如果遇到主从不同步,看一下主从 bin-log 的位置,然后再同步。
show master status;
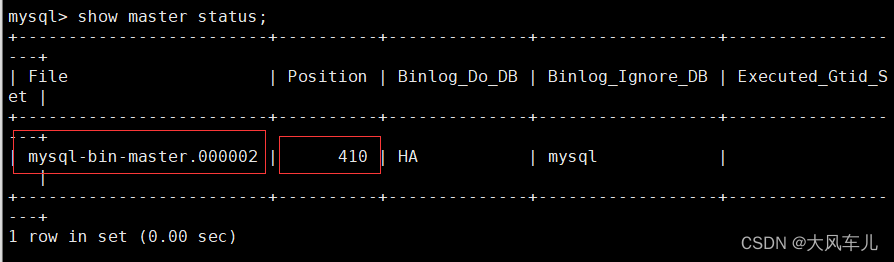
从服务器执行如下mysql 命令:
stop slave; # 停止slave 服务
# 根据上面主服务器的 show master status 的结果,进行从服务器的二进制数据库记录回归,达到同步的效果
change master to master_log_file='mysql-bin-master.000002',master_log_pos=410;
start slave; # 启动 I/O 线程和 SQL 线程
show slave status\G; # 看一下从服务器的同步情况
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
看到两个都是 YES,代表同步成功。
可能出现的问题:
- io线程
- 防火墙没关
- ip地址写错,用户名密码写错。
使用MyCat实现读写分离
MySQL读写分离概述
工作原理
基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理 SELECT 查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
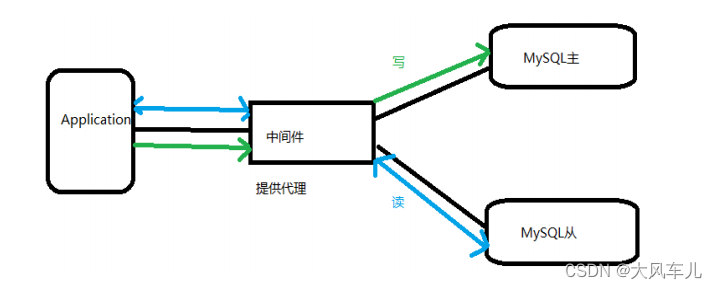
为什么要读写分离
-
- 面对越来越大的访问压力,单台的服务器的性能成为瓶颈,需要分担负载。
-
- 主从只负责各自的写和读,极大程度的缓解 X(写)锁和 S(读)锁争用。
-
- 从库可配置 myisam 引擎,提升查询性能以及节约系统开销。
-
- 增加冗余,提高可用性。
实现读写分离的方式
应用程序层实现
应用程序层实现指的是在应用程序内部及连接器中实现读写分离
优点:
- 应用程序内部实现读写分离,安装既可以使用;
- 减少一定部署难度;
- 访问压力在一定级别以下,性能很好。
缺点:
- 架构一旦调整,代码要跟着变;
- 难以实现高级应用,如自动分库,分表;
- 无法适用大型应用场景。
中间件层实现
中间件层实现是指在外部中间件程序实现读写分离
常见的中间件:
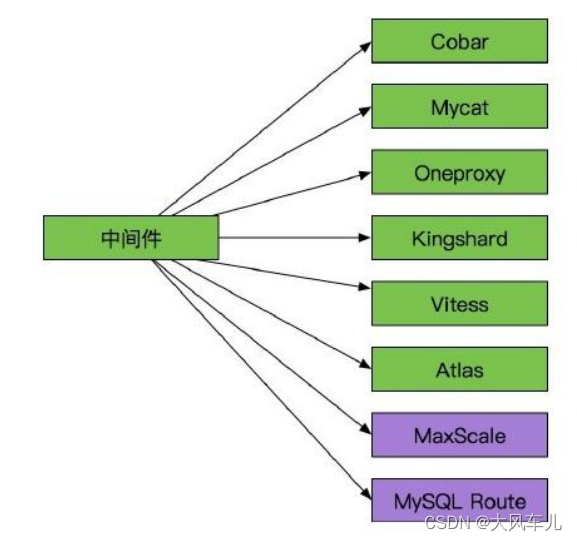
优点:
- 架构设计更灵活;
- 可以在程序上实现一些高级控制,如:透明化水平拆分,failover,监控;
- 可以依靠技术手段提高 mysql 性能;
- 对业务代码的影响小,同时也安全。
缺点:
- 需要一定的开发运维团队的支持。
MyCat服务安装与配置
架构:
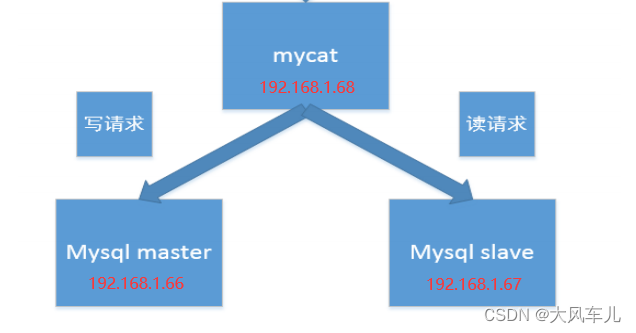
上面我们已经安装并配置好了mysql的主从,接下来只需安装并配置mycat。
JDK安装
Mycat 需要安装 JDK 1.7 或者以上版
下载文件
到官网下载jdk:https://www.oracle.com/java/technologies/downloads/
本实验用到的JDK版本为 :“1.8.0_191”
上传并解压
将下载的安装包上传到服务器
mkdir /usr/java # 创建文件夹
tar xf jdk-8u191-linux-x64.tar.gz -C /usr/java/ # 解压到新建的文件夹
配置环境变量
vim /etc/profile.d/java.sh # /etc/profile.d/目录下创建java.sh 文件并定入如下内容
JAVA_HOME=/usr/java/jdk1.8.0_191
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
chmod +x /etc/profile.d/java.sh # 赋予可执行权限
source /etc/profile.d/java.sh # 使环境变量生效
java -version # 查看java版本
mycat安装
下载上传
上传到s68并解压:
tar xf Mycat-server-1.5.1-RELEASE-20161130213509-linux.tar.gz -C /usr/local/
配置环境变量
vim /etc/profile.d/mycat.sh # 在/etc/profile.d 目录下创建mycat.sh 文件,并写入如下
MYCAT_HOME=/usr/local/mycat
PATH=$MYCAT_HOME/bin:$PATH
source /etc/profile.d/mycat.sh # 使环境变量生效
mycat配置
账号授权
分别到master、slave上创建mycat登录数据库使用的账号,进入数据库执行如下命令:
GRANT ALL PRIVILEGES ON *.* TO 'mycat'@"%" IDENTIFIED BY "123456";
修改mycat 的用户账号和授权信息
在s68进行如下操作:
vim /usr/local/mycat/conf/server.xml # 用户账户和授权信息文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<!--以下设置为应用访问帐号权限 -->
<user name="root"> # 定义管理员用户,也就是连接 Mycat 的用户名
<property name="password">123456</property> # 密码
<property name="schemas">ha</property> # 定义一个逻辑库,与schema 配置文件对应
</user>
<!--以下设置为应用只读帐号权限 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">ha</property> # 定义一个逻辑库,与schema 配置文件对应
<property name="readOnly">true</property>
</user>
</mycat:server>
修改schema.xml
mv /usr/local/mycat/conf/schema.xml /usr/local/mycat/conf/schema.xml.bak # 备份原文件
vim /usr/local/mycat/conf/schema.xml # 新建,写入如下内容
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<!--下面schema的name为逻辑数据库 -->
<schema name="ha" checkSQLschema="false" sqlMaxLimit="100" dataNode='dn1'>
</schema>
<!--dataNode的database对应物理数据库(实际存在) -->
<dataNode name="dn1" dataHost="dthost" database="HA"/>
<dataHost name="dthost" maxCon="500" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="s66" url="192.168.1.66:3306" user="mycat" password="123456">
</writeHost>
<writeHost host="s67" url="192.168.1.67:3306" user="mycat" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
dataNode里设置的database为我们做主从同步的数据库名
注释:
- schema 标签用于定义 MyCat 实例中的逻辑库,name:后面就是逻辑库名,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
- checkSQLschema 这个属性默认就是 false,官方文档的意思就是是否去掉表前面的数据库的名称,”select * from db1.testtable” ,设置为 true 就会去掉 db1。但是如果 db1 的名称不是schema 的名称,那么也不会被去掉,因此官方建议不要使用这种语法。同时默认设置为 false。
- sqlMaxLimit 当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应的值。例如设置值为 100,执行”select * from test_table”,则效果为“selelct * from test_table limit 100”.
- dataNode 标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个dataNode 标签就是一个独立的数据分片.
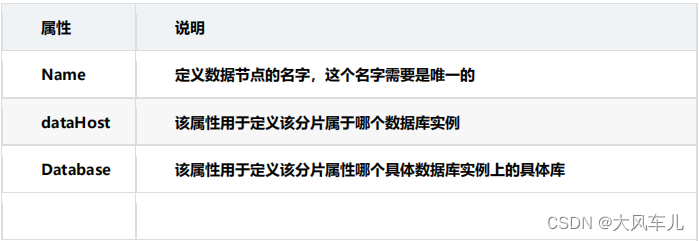
dataHost 该标签定义了具体的数据库实例、读写分离配置和心跳语句
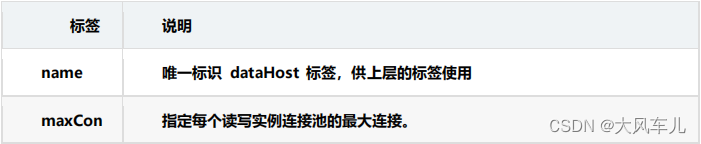

writeHost /readHost 这两个标签都指定后端数据库的相关配置,用于实例化后端连接池。唯一不同的是,writeHost 指定写实例、readHost 指定读实例。 在一个 dataHost 内可以定义多个writeHost 和 readHost。但是,如果 writeHost 指定的后端数据库宕机,那么这个 writeHost 绑定的所有 readHost 都将不可用。另一方面,由于这个 writeHost 宕机,系统会自动的检测到,并切换到备用的 writeHost 上去。这两个标签的属性相同。
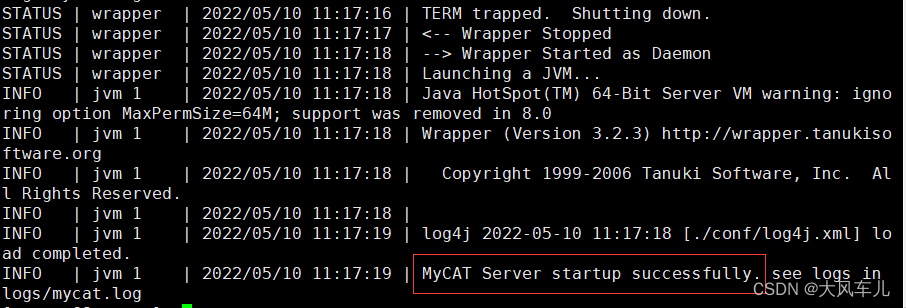
经过以上两个步骤的配置,就可以到/usr/local/mycat/bin 目录下执行 ./mycat start,即可启动mycat 服务!
/usr/local/mycat/bin/mycat start
cat /usr/local/mycat/logs/wrapper.log # 查看日志,启动成功
测试读写分离
使用mysql客户端登录mycat进行数据读、写操作
mysql -uroot -p123456 -h 192.168.1.63 -P8066
use HA;
insert into T1 values(1,'dafengche');
select * from T1;
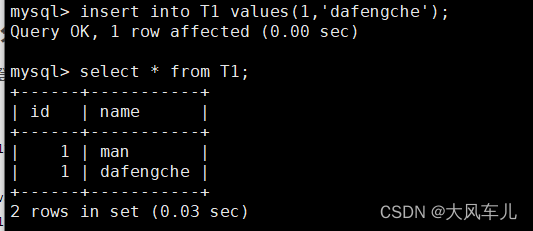
可以看到读、写数据正常,如果打开数据库速度非常慢,则检查schema中关于物理库的配置是否正确。
修改schema.xml里switchType的值可以实现故障自动切换
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182258.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
