
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、动态WRR调度算法
这是一个目前普遍使用的调度算法,算法在WRR的基础上加入了根据服务器端的负载信息周期性地调整服务器性能权值的过程。其基本思想是:根据CPU利用率、内存利用率、磁盘使用情况、连接数、进程数等硬件资源信息综合计算各个服务器的负载值,然后与一个己设定的代表系统利用率的阀值比较,如大于阀值则说明负载较重应调小权值,反之则调大权值。权值的大小决定了该服务器服务请求的能力大小。动态WRR是一种在算法复杂度和效率方面折中的较好算法,研究表明在请求的服务时间长度变化不大的情况下,动态WRR有较高的吞吐率和可伸缩性,包括思科和IBM的商业集群产品采用的也是动态WRR。
在已提出的动态调度算法中,无论是内容感知还是内容透明的调度算法,基本都会使用服务器的负载信息来实现负载均衡。服务器负载反馈信息的精确度和有效性是动态调度算法性能的重要影响因素。使用服务器负载信息需要考虑几个问题,一:选择服务器上的什么负载信息;二:如何处理这些负载信息以及信息采样的频率;三:如何传递它们到调度器。不同的选择方案对调度算法的性能将产生巨大差异。
大多数算法收集的负载信息可分为三类:输入指标、服务器指标、响应指标。输入指标是在调度器上收集到的单位时间内服务器收到新连接数与平均连接数的比例;服务器指标是在服务器上的各种负载信息;响应指标是服务器所提供服务的响应延迟。其中服务器指标主要记录服务器各种负载信息,如服务器当前CPU负载Ci、服务器当前磁盘使用情况Di、当前内存利用率Mi、当前进程数目Pi等。服务器指标可以在调度器上运行SNMP(simple Network Management Protocol)服务进程查询获得这些信息,或是在服务器上实现和运行收集信息的Agent。收集的负载信息周期性的反馈到调度器。调度器引入一组可以动态调整表示各个负载参数重要程度的系数Ri,然后服务器的综合负载值可以由如下的公式计算出:
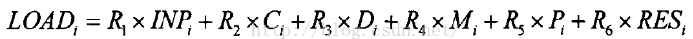
其中INPi表示输入指标值,RESi表示响应延迟。这种负载反馈方法里面反馈周期的长短设置对系统稳定性很重要,如果太长可能导致系统性能下降,因为系统参考的是太老旧的状态信息;如果太短则使得系统频繁调整,导致不稳定。另外因为计算服务器端负载状态考虑的参数过多,当应用改变或是对服务器进行调整后,选择合适的指标系数值使之准确计算服务器端负载状态是一件很困难的事情。
二、Nginx负载均衡
nginx不单可以作为强大的web服务器,也可以作为一个反向代理服务器,而且nginx还可以按照调度规则实现动态、静态页面的分离,可以按照轮询、ip哈希、URL哈希、权重等多种方式对后端服务器做负载均衡,同时还支持后端服务器的健康检查。
如果只有一台服务器时,这个服务器挂了,那么对于网站来说是个灾难.因此,这时候的负载均衡就会大显身手了,它会自动剔除挂掉的服务器。
nginx 的upstream目前支持4 种方式的分配 :
-
轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
-
weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
-
ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
-
fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
三、基本的网络负载均衡算法
均衡算法设计的好坏直接决定了集群在负载均衡上的表现,设计不好的算法,会导致集群的负载失衡。一般的均衡算法主要任务是决定如何选择下一个集群节点,然后将新的服务请求转发给它。有些简单均衡方法可以独立使用,有些必须和其他简单或高级方法组合使用。而一个好的负载均衡算法也并不是万能的,它一般只在某些特殊的应用环境下才能发挥最大效用。因此在考察负载均衡算法的同时,也要注意算法本身的适用面,并在采取集群部署的时候根据集群自身的特点进行综合考虑,把不同的算法和技术结合起来使用。
3.1 轮转法
轮转算法是所有调度算法中最简单也最容易实现的一种方法。在一个任务队列里,队列的每个成员(节点)都具有相同的地位,轮转法简单的在这组成员中顺序轮转选择。在负载均衡环境中,均衡器将新的请求轮流发给节点队列中的下一节点,如此连续、周而复始,每个集群的节点都在相等的地位下被轮流选择。这个算法在DNS域名轮询中被广泛使用。
轮转法的活动是可预知的,每个节点被选择的机会是1/N,因此很容易计算出节点的负载分布。轮转法典型的适用于集群中所有节点的处理能力和性能均相同的情况,在实际应用中,一般将他与其他简单方法联合使用时比较有效。
3.2 散列法
散列法也叫哈希法(HASH),通过单射不可逆的HASH函数,按照某种规则将网络请求发往集群节点。哈希法在其他几类均衡算法不是很有效时会显示出特别的威力。例如,在前面提到的UDP会话的情况下,由于轮转法和其他几类基于连接信息的算法,无法识别出会话的起止标记,会引起应用混乱。
而采取基于数据包源地址的哈希映射可以在一定程度上解决这个问题:将具有相同源地址的数据包发给同一服务器节点,这使得基于高层会话的事务可以以适当的方式运行。相对称的是,基于目的地址的哈希调度算法可以用在Web Cache集群中,指向同一个目标站点的访问请求都被负载均衡器发送到同一个Cache服务节点上,以避免页面缺失而带来的更新Cache问题。
3.3 最少连接法
在最少连接法中,均衡器纪录目前所有活跃连接,把下一个新的请求发给当前含有最少连接数的节点。这种算法针对TCP连接进行,但由于不同应用对系统资源的消耗可能差异很大,而连接数无法反映出真实的应用负载,因此在使用重型Web服务器作为集群节点服务时(例如Apache服务器),该算法在均衡负载的效果上要打个折扣。为了减少这个不利的影响,可以对每个节点设置最大的连接数上限(通过阈值设定体现)。
3.4 最低缺失法
在最低缺失法中,均衡器长期纪录各节点的请求情况,把下个请求发给历史上处理请求最少的节点。与最少连接法不同的是,最低缺失记录过去的连接数而不是当前的连接数。
3.5 最快响应法
均衡器记录自身到每一个集群节点的网络响应时间,并将下一个到达的连接请求分配给响应时间最短的节点,这种方法要求使用ICMP包或基于UDP包的专用技术来主动探测各节点。
在大多数基于LAN的集群中,最快响应算法工作的并不是很好,因为LAN中的ICMP包基本上都在10 ms内完成回应,体现不出节点之间的差异;如果在WAN上进行均衡的话,响应时间对于用户就近选择服务器而言还是具有现实意义的;而且集群的拓扑越分散,这种方法越能体现出效果来。这种方法是高级均衡基于拓扑结构重定向用到的主要方法。
3.6 加权法
加权方法只能与其他方法合用,是他们的一个很好的补充。加权算法根据节点的优先级或当前的负载状况(即权值)来构成负载均衡的多优先级队列,队列中的每个等待处理的连接都具有相同处理等级,这样在同一个队列里可以按照前面的轮转法或者最少连接法进行均衡,而队列之间按照优先级的先后顺序进行均衡处理。在这里权值是基于各节点能力的一个估计值。
四、动态反馈负载均衡
当客户访问集群资源时,提交的任务所需的时间和所要消耗的计算资源是千差万别的,他依赖于很多因素。例如:任务请求的服务类型、当前网络带宽的情况、以及当前服务器资源利用的情况等等。一些负载比较重的任务需要进行计算密集的查询、数据库访问、很长响应数据流;而负载比较轻的任务请求往往只需要读一个小文件或者进行很简单的计算。
对任务请求处理时间的不同可能会导致处理结点利用率的倾斜(Skew),即处理结点的负载不均衡。有可能存在这样的情况,有些结点已经超负荷运行,而其他结点基本是闲置着。同时,有些结点已经忙不过来,有很长的请求队列,还不断地收到新的请求。反过来说,这会导致客户长时间的等待,而集群整体的服务质量下降。因此,有必要采用一种机制,使得均衡器能够实时地了解各个结点的负载状况,并能根据负载的变化做出调整。
具体的做法上采用了基于负反馈机制的动态负载均衡算法,该算法考虑每一个结点的实时负载和响应能力,不断调整任务分布的比例,来避免有些结点超载时依然收到大量请求,从而提高单一集群的整体吞吐率。
在集群内,负载均衡器上运行服务端监控进程,监控进程负责监视和收集集群内各个结点的负载信息;而每个结点上运行客户端进程,负责定时向均衡器报告自身的负载状况。监控进程根据收到的全部结点的负载信息来进行同步操作,即对将要分配的任务按照权值的比例重新进行分布。权值的计算主要根据各个结点的 CPU利用率、可用内存以及磁盘I/O状况计算出新的权值,若新权值和当前权值的差值大于设定的阀值,监控器采用新的权值对集群范围内的任务重新进行分布,直到下一次的负载信息同步到来之前。均衡器可以配合动态权值,采用加权轮询算法来对接受的网络服务请求进行调度。
4.1 加权轮询调度
加权轮询调度(Weighted Round-Robin Scheduling)算法用相应的权值表示结点的处理性能。该算法根据权值的高低顺序并按照轮询的方式将任务请求分配到各结点。权值高的结点比权值低的结点处理更多的任务请求,相同权值的结点处理相同份额的请求。加权轮询的基本原理可描述为:
假设某集群内有一组结点N={N0,N1,…,Nn-1},W(Ni)表示结点Ni的权值,一个指示变量i表示上一次选择的服务器,T(Ni)表示结点Ni当前所分配的任务量。
∑T(Ni)表示当前同步周期需要处理的任务总量。
∑W(Ni)表示结点的权值总和。
则:
W(Ni)/∑W(Ni)=T(Ni)/∑T(Ni)
表示任务的分配是按照各个结点权值占权值总数的比例来进行分配。
4.2 权值计算
当集群的结点初次投入系统中使用时,系统管理员根据结点的硬件配置情况对每个结点都设定一个初始权值DW(Ni)(通常根据结点的硬件配置来定义,硬件配置越高的结点默认值越高),在负载均衡器上也先使用这个权值。然后,随着结点负载的变化,均衡器对权值进行调整。
动态权值是由结点运行时各方面的参数计算出来的。我们在实验中选取了最重要的几项,包括:CPU资源、内存资源、当前进程数、响应时间等信息作为计算公式的因子。结合每个结点当前的权值,可以计算出新的权值的大小。动态权值的目的是要正确反映结点负载的状况,以预测结点将来可能的负载变化。对于不同类型的系统应用,各个参数的重要程度也有所不同。典型的Web应用环境下,可用内存资源和响应时间就非常重要;如果用户以长的数据库事务为主,则CPU使用率和可用内存就相对重要一些。为了方便在系统运行过程中针对不同的应用对各个参数的比例进行适当调整,我们为每一个参数设定一个常量系数Ri,用来表示各个负载参数的重要程度,其中∑Ri=1。因此,任何一个结点Ni的权值公式就可以描述为:
LOAD(Ni)=R1*Lcpu(Ni)+R2*Lmemory(Ni)+R3*Lio(Ni)+R4*Lprocess(Ni)+R5*Lresponse(Ni)
其中:Lf(Ni)表示结点Ni当前某一项参数的负载值。上述公式中依次表示为:CPU使用率、内存使用率、磁盘I/O访问率、进程总数以及响应时间。
例如,在Web服务器集群中,我们采用系数{0.1,0.4,0.1,0.1,0.3},这里认为服务器的内存和请求响应时间较其他参数重要一些。若当前的系数Ri不能很好地反映应用的负载,系统管理员可以对系数不断地修正,直到找到贴近当前应用的一组系数。
另外,关于采集权值的周期值,虽然很短的周期可以更确切地反映各个结点的负载,但是很频繁地采集(如1 s 1次或者多次)会给均衡器和结点带来负担,也可能增加不必要的网络负荷。另外,由于采集器是在采集时刻进行负载计算的,经实验证明,均衡器反映出来各个结点的负载信息会出现剧烈的抖动,均衡器无法准确捕捉结点真实的负载变化趋势。因此解决这些问题,一方面要适当地调整采集负载信息的周期,一般在5~10 s;另一方面,可以使用移动均匀线或者是滑动窗口来避免抖动,使得均衡器收集到的负载信息表现为均滑曲线,这样在负反馈机制的调整效果上就会比较好。
均衡器的动态权值采集程序周期性地运行,若缺省权值不为0,则查询该结点的各负载参数,并计算出动态权值LOAD(Ni)。我们引入以下权值计算公式,结合结点的初始权值和采集的动态权值来计算最终的权值结果。
Wi=A*DW(Ni)+B*(LOAD(Ni)-DW(Ni))1/3
在公式中,如果动态权值恰好等于初始权值,最终权值不变,则说明系统的负载状况刚好达到理想状况,等于初始权值DW(Ni)。如果动态权值计算结果高于初始权值,最终权值变高,则说明系统负载很轻,均衡器将会增加分配给该结点的任务比率。如果动态权值低于初始权值,最终权值变低,说明系统开始处于重载状况,均衡器将会减少对该结点分配的任务。在实际使用中,若发现所有结点的权值都小于他们的DW(Ni),则说明当前个集群处于超载状态,这时需要加入新的结点到集群中来处理部分负载;反之,若所有结点的权值大大高于DW(Ni),则说明当前系统的负载都比较轻。
五、结语
网络负载均衡是集群作业调度系统的具体实现。由于其处理的作业单元是TCP/IP协议下的网络连接,因此可以采用面向网络连接的集中基本调度算法。考虑集群负载不均衡的可能,采取了动态获取服务节点的权值并使用负反馈机制调整均衡器对网络服务请求的分布,以适应服务节点在运行过程中资源的变化。实践证明,采用动态均衡在集群系统的整体吞吐量方面有所提高,特别是在集群各个节点性能不一,集群提供的网络服务程序所访问的资源多样化的情况下,负反馈机制的效果尤其明显。在其他类型的集群中,负反馈机制的动态负载均衡也能够得到很好的应用,只是均衡器所处理的作业单元不同于网络连接,而具体的负载算法上也将有所不同。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182256.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...