大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
小伙伴想精准查找自己想看的MySQL文章?喏 → MySQL江湖路 | 专栏目录
一条慢查询会造成什么后果?年轻时,我一直觉得不就是返回数据会慢一些么,用户体验变差?其实远远不止,我经历过几次
线上事故,有一次就是由一条SQL慢查询导致的。


记得那是一条查询SQL,数据量万级时还保持在0.2秒内,随着某一段时间数据猛增,耗时一度达到了2-3秒!没有命中索引,导致全表扫描。explain 中extra显示:Using where; Using temporary; Using filesort,被迫使用了临时表排序,由于是高频查询,并发一起来很快就把DB线程池打满了,导致大量查询请求堆积,DB服务器cpu长时间100%+,大量请求timeout。。最终系统崩溃。老板登场~
对了,那次是十月二日晚上8点半,我在老家枣庄,和哥儿几个正坐在大排档吹着牛B!你猜,我将面临什么尴尬局面?

可见,团队如果对慢查询不引起足够的重视,风险是很大的。经过那次事故我们老板就说了:谁的代码再出现类似事故,开发和部门领导一起走人,吓得一大堆领导心发慌,赶紧招了两位DBA同事???。

慢查询,顾名思义,执行很慢的查询。有多慢?超过 long_query_time 参数设定的时间阈值(默认10s),就被认为是慢的,是需要优化的。慢查询被记录在慢查询日志里。
慢查询日志默认是不开启的,如果你需要优化SQL语句,就可以开启这个功能,它可以让你很容易地知道哪些语句是需要优化的(想想一个SQL要10s就可怕)。
墨菲定律:会出错的事情就一定会出错。
这是太真实的事情之一了。为了防患于未然,一起来看看慢查询该怎么处理。本文很干,记得接杯水,没时间看的先收藏哦!
目录
一、慢查询配置
1-1、开启慢查询
MySQL支持通过
- 1、输入命令开启慢查询(临时),在MySQL服务重启后会自动关闭;
- 2、配置my.cnf(windows是my.ini)系统文件开启,修改配置文件是持久化开启慢查询的方式。
方式一:通过命令开启慢查询
步骤1、查询 slow_query_log 查看是否已开启慢查询日志:
show variables like '%slow_query_log%';
mysql> show variables like '%slow_query_log%';
+---------------------+-----------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+---------------------+-----------------------------------+
2 rows in set (0.01 sec)
步骤2、开启慢查询命令:
set global slow_query_log='ON';
步骤3、指定记录慢查询日志SQL执行时间得阈值(long_query_time 单位:秒,默认10秒)
如下我设置成了1秒,执行时间超过1秒的SQL将记录到慢查询日志中
set global long_query_time=1;
步骤4、查询 “慢查询日志文件存放位置”
show variables like '%slow_query_log_file%';
mysql> show variables like '%slow_query_log_file%';
+---------------------+-----------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------+
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+---------------------+-----------------------------------+
1 row in set (0.01 sec)
slow_query_log_file 指定慢查询日志的存储路径及文件(默认和数据文件放一起)
步骤5、核对慢查询开启状态
需要退出当前MySQL终端,重新登录即可刷新;
配置了慢查询后,它会记录以下符合条件的SQL:
- 查询语句
- 数据修改语句
- 已经回滚的SQL
方式二:通过配置my.cnf(windows是my.ini)系统文件开启
(版本:MySQL5.5及以上)
在my.cnf文件的[mysqld]下增加如下配置开启慢查询,如下图
# 开启慢查询功能
slow_query_log=ON
# 指定记录慢查询日志SQL执行时间得阈值
long_query_time=1
# 选填,默认数据文件路径
# slow_query_log_file=/var/lib/mysql/localhost-slow.log
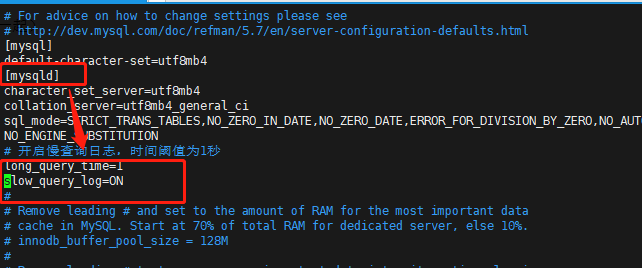
重启数据库后即持久化开启慢查询,查询验证如下:
mysql> show variables like '%_query_%';
+------------------------------+-----------------------------------+
| Variable_name | Value |
+------------------------------+-----------------------------------+
| have_query_cache | YES |
| long_query_time | 1.000000 |
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+------------------------------+-----------------------------------+
6 rows in set (0.01 sec)
1-2、慢查询日志介绍
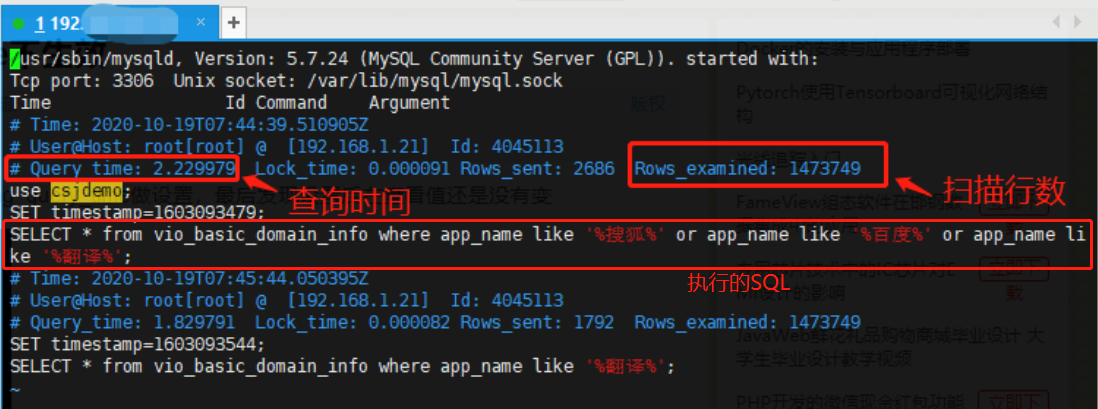
如上图,是执行时间超过1秒的SQL语句(测试)
- 第一行:记录时间
- 第二行:用户名 、用户的IP信息、线程ID号
- 第三行:执行花费的时间【单位:秒】、执行获得锁的时间、获得的结果行数、扫描的数据行数
- 第四行:这SQL执行的时间戳
- 第五行:具体的SQL语句
二、Explain分析慢查询SQL
分析mysql慢查询日志 ,利用explain关键字可以模拟优化器执行SQL查询语句,来分析sql慢查询语句,下面我们的测试表是一张137w数据的app信息表,我们来举例分析一下;
SQL示例如下:
-- 1.185s
SELECT * from vio_basic_domain_info where app_name like '%陈哈哈%' ;
这是一条普通的模糊查询语句,查询耗时:1.185s,查到了148条数据;
我们用Explain分析结果如下表,根据表信息可知:该SQL没有用到字段app_name上的索引,查询类型是全表扫描,扫描行数137w。
mysql> EXPLAIN SELECT * from vio_basic_domain_info where app_name like '%陈哈哈%' ;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | ALL | NULL | NULL | NULL | NULL | 1377809 | 11.11 | Using where |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
当这条SQL使用到索引时,SQL如下:查询耗时:0.156s,查到141条数据
-- 0.156s
SELECT * from vio_basic_domain_info where app_name like '陈哈哈%' ;
Explain分析结果如下表;根据表信息可知:该SQL用到了idx_app_name索引,查询类型是索引范围查询,扫描行数141行。由于查询的列不全在索引中(select *),因此回表了一次,取了其他列的数据。
mysql> EXPLAIN SELECT * from vio_basic_domain_info where app_name like '陈哈哈%' ;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | range | idx_app_name | idx_app_name | 515 | NULL | 141 | 100.00 | Using index condition |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
当这条SQL使用到覆盖索引时,SQL如下:查询耗时:0.091s,查到141条数据
-- 0.091s
SELECT app_name from vio_basic_domain_info where app_name like '陈哈哈%' ;
Explain分析结果如下表;根据表信息可知:和上面的SQL一样使用到了索引,由于查询列就包含在索引列中,又省去了0.06s的回表时间。
mysql> EXPLAIN SELECT app_name from vio_basic_domain_info where app_name like '陈哈哈%' ;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | range | idx_app_name | idx_app_name | 515 | NULL | 141 | 100.00 | Using where; Using index |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
那么是如何通过EXPLAIN解析结果分析SQL的呢?各列属性又代表着什么?一起往下看。
2-1、各列属性的简介:
- id:SELECT的查询序列号,体现执行优先级,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- select_type:表示查询的类型。
- table:输出结果集的表,如设置了别名,也会显示
- partitions:匹配的分区
type:对表的访问方式- possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引- key_len:索引字段的长度
- ref:列与索引的比较
rows:扫描出的行数(估算的行数)- filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
以上标星的几类是我们优化慢查询时常用到的
2-2、慢查询分析常用到的属性
1、type:
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
存在的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从低到高),介绍三个咱们天天见到的:
ALL:(Full Table Scan) MySQL将遍历全表以找到匹配的行,常说的全表扫描
index: (Full Index Scan) index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
2、key
key列显示了SQL实际使用索引,通常是possible_keys列中的索引之一,MySQL优化器一般会通过计算扫描行数来选择更适合的索引,如果没有选择索引,则返回NULL。当然,MySQL优化器存在选择索引错误的情况,可以通过修改SQL强制MySQL“使用或忽视某个索引”。
- 强制使用一个索引:
FORCE INDEX (index_name)、USE INDEX (index_name) - 强制忽略一个索引:IGNORE INDEX (index_name)
3、rows
rows是MySQL估计为了找到所需的行而要读取(扫描)的行数,可能不精确。
4、Extra
这一列显示一些额外信息,很重要。
- Using index
查询的列被索引覆盖,并且where筛选条件是索引的是前导列,Extra中为Using index。意味着通过索引查找就能直接找到符合条件的数据,无须回表。
注:前导列一般指联合索引中的第一列或“前几列”,以及单列索引的情况;这里为了方便理解我统称为前导列。
- Using where
说明MySQL服务器将在存储引擎检索行后再进行过滤;即没有用到索引,回表查询。
可能的原因:
- 查询的列未被索引覆盖;
- where筛选条件非索引的前导列或无法正确使用到索引;
- Using temporary
这意味着MySQL在对查询结果排序时会使用一个临时表。
- Using filesort
说明MySQL会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。
- Using index condition
查询的列不全在索引中,where条件中是一个前导列的范围
- Using where;Using index
查询的列被索引覆盖,并且where筛选条件是索引列之一,但不是索引的前导列或出现了其他影响直接使用索引的情况(如存在范围筛选条件等),Extra中为Using where; Using index,意味着无法直接通过索引查找来查询到符合条件的数据,影响并不大。
三、一些慢查询优化经验分享
3-1、优化LIMIT分页
在系统中需要分页的操作通常会使用limit加上偏移量的方法实现,同时加上合适的order by 子句。如果有对应的索引,通常效率会不错,否则MySQL需要做大量的文件排序操作。
一个非常令人头疼问题就是当偏移量非常大的时候,例如可能是limit 1000000,10这样的查询,这是mysql需要查询1000000条然后只返回最后10条,前面的1000000条记录都将被舍弃,这样的代价很高,会造成慢查询。
优化此类查询的一个最简单的方法是尽可能的使用索引覆盖扫描,而不是查询所有的列。然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候这样做的效率会得到很大提升。
对于下面的查询:
-- 执行耗时:1.379s
SELECT * from vio_basic_domain_info LIMIT 1000000,10;
Explain分析结果:
mysql> EXPLAIN SELECT * from vio_basic_domain_info LIMIT 1000000,10;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | ALL | NULL | NULL | NULL | NULL | 1377809 | 100.00 | NULL |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.00 sec)
该语句存在的最大问题在于limit M,N中偏移量M太大,导致每次查询都要先从整个表中找到满足条件 的前M条记录,之后舍弃这M条记录并从第M+1条记录开始再依次找到N条满足条件的记录。如果表非常大,且筛选字段没有合适的索引,且M特别大那么这样的代价是非常高的。
那么如果我们下一次的查询能从前一次查询结束后标记的位置开始查找,找到满足条件的10条记录,并记下下一次查询应该开始的位置,以便于下一次查询能直接从该位置 开始,这样就不必每次查询都先从整个表中先找到满足条件的前M条记录,舍弃掉,再从M+1开始再找到10条满足条件的记录了。
处理分页慢查询的方式一般有以下几种
思路一:构造覆盖索引
通过修改SQL,使用上覆盖索引,比如我需要只查询表中的app_name、createTime等少量字段,那么我秩序在app_name、createTime字段设置联合索引,即可实现覆盖索引,无需全表扫描。适用于查询列较少的场景,查询列数过多的不推荐。
耗时:0.390s
mysql> EXPLAIN SELECT app_name,createTime from vio_basic_domain_info LIMIT 1000000,10;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | index | NULL | idx_app_name | 515 | NULL | 1377809 | 100.00 | Using index |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
思路二:优化offset
无法用上覆盖索引,那么重点是想办法快速过滤掉前100w条数据。我们可以利用自增主键有序的条件,先查询出第1000001条数据的id值,再往后查10行;适用于主键id自增的场景。
耗时:0.471s
SELECT * from vio_basic_domain_info where
id >=(SELECT id from vio_basic_domain_info ORDER BY id limit 1000000,1) limit 10;
原理:先基于索引查询出第1000001条数据对应的主键id的值,然后直接通过该id的值直接查询该id后面的10条数据。下方EXPLAIN 分析结果中大家可以看到这条SQL的两步执行流程。
mysql> EXPLAIN SELECT * from vio_basic_domain_info where id >=(SELECT id from vio_basic_domain_info ORDER BY id limit 1000000,1) limit 10;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | PRIMARY | vio_basic_domain_info | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 10 | 100.00 | Using where |
| 2 | SUBQUERY | vio_basic_domain_info | NULL | index | NULL | PRIMARY | 8 | NULL | 1000001 | 100.00 | Using index |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
2 rows in set, 1 warning (0.40 sec)
方法三:“延迟关联”
耗时:0.439s
延迟关联适用于数量级较大的表,SQL如下;
SELECT * from vio_basic_domain_info inner join (select id from vio_basic_domain_info order by id limit 1000000,10) as myNew using(id);
这里我们利用到了覆盖索引+延迟关联查询,相当于先只查询id列,利用覆盖索引快速查到该页的10条数据id,然后再把返回的10条id拿到表中通过主键索引二次查询。(表数据增速快的情况对该方法影响较小。)
mysql> EXPLAIN SELECT * from vio_basic_domain_info inner join (select id from vio_basic_domain_info order by id limit 1000000,10) as myNew using(id);
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1000010 | 100.00 | NULL |
| 1 | PRIMARY | vio_basic_domain_info | NULL | eq_ref | PRIMARY | PRIMARY | 8 | myNew.id | 1 | 100.00 | NULL |
| 2 | DERIVED | vio_basic_domain_info | NULL | index | NULL | PRIMARY | 8 | NULL | 1000010 | 100.00 | Using index |
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
3-2、排查索引没起作用的情况
- 模糊查询尽量避免用通配符’%’开头,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE '%陈哈哈%'
优化方式:尽量在字段后面使用模糊查询。如下:
SELECT * FROM t WHERE username LIKE '陈哈哈%'
如果需求是要在前面使用模糊查询,
- 使用MySQL内置函数INSTR(str,substr) 来匹配,作用类似于java中的indexOf(),查询字符串出现的角标位置。
- 使用FullText全文索引,用match against 检索
- 数据量较大的情况,建议引用ElasticSearch、solr,亿级数据量检索速度秒级
- 当表数据量较少(几千条儿那种),别整花里胡哨的,直接用like ‘%xx%’。
但不得不说,MySQL模糊匹配大字段是硬伤,毕竟保证事务的ACID特性耗费了太多性能,因此,如果实际场景中有类似业务需求,建议果断更换大数据存储引擎如ElasticSearch、Hbase等。这里和情怀无关~
- 尽量避免使用 not in,会导致引擎走全表扫描。建议用 not exists 代替,如下:
-- 不走索引
SELECT * FROM t WHERE name not IN ('提莫','队长');
-- 走索引
select * from t as t1 where not exists (select * from t as t2 where name IN ('提莫','队长') and t1.id = t2.id);
- 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
- 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
- 尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。
可以将表达式、函数操作移动到等号右侧。如下:
-- 全表扫描
SELECT * FROM T WHERE score/10 = 9
-- 走索引
SELECT * FROM T WHERE score = 10*9
- 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT username, age, sex FROM T WHERE 1=1
优化方式:用代码拼装sql时进行判断,没 where 条件就去掉 where,有where条件就加 and。
- 查询条件不要用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。如确实业务需要,使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中其他索引字段代替。
- where条件仅包含复合索引非前导列
如:复合(联合)索引包含key_part1,key_part2,key_part3三列,但SQL语句没有包含索引前置列”key_part1″,按照MySQL联合索引的最左匹配原则,不会走联合索引。
-- 不走索引
select col1 from table where key_part2=1 and key_part3=2
-- 走索引
select col1 from table where key_part1 =1 and key_part2=1 and key_part3=2
- 隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select col1 from table where col_varchar=123;
总结
好了,通过这篇文章,希望你Get到了一些分析MySQL慢查询的方法和心得。慢查询,在MySQL中始终是绕不开的话题,慢的方式多种多样,如果你想完全避免慢查询?年轻人,我建议你耗子尾汁~
我们需要做的是及时发现并解决慢查询,其实很多慢查询是被动出现的,比如由于某业务数据量猛增数量级变化、由于业务需求变化而改了字段或操作了既有索引等。虽然不是你的错,但这锅可能还得你来背????

如果你觉得这篇文章不错,记得分享给朋友或同事,让大家少踩点坑。
MySQL系列文章汇总与《MySQL江湖路 | 专栏目录》
往期热门MySQL系列文章:
- 原创 | MySQL中特别实用的几种SQL语句送给大家
- 原创 | SQL优化最干货总结 – MySQL(2020最新版)
- 原创 | 为什么大家都说SELECT * 效率低
- 原创 | 面试让HR都能听懂的MySQL锁机制,欢声笑语中搞懂MySQL锁
- 原创 | MySQL中的 utf8 并不是真正的UTF-8编码 ! !
- 原创 | MySQL数据中有很多换行符和回车符!!该咋办?
- 原创 | delete后加 limit是个好习惯么
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182111.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
