大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
kafka作为一个消息流处理平台。很多开发人员都作它作为一个生产&消费的中间件,并没有细细去思考kafka可以在哪些应用场景中使用,下面根据我的经验,总结下kafka可以应用在以下场景中。
消息队列
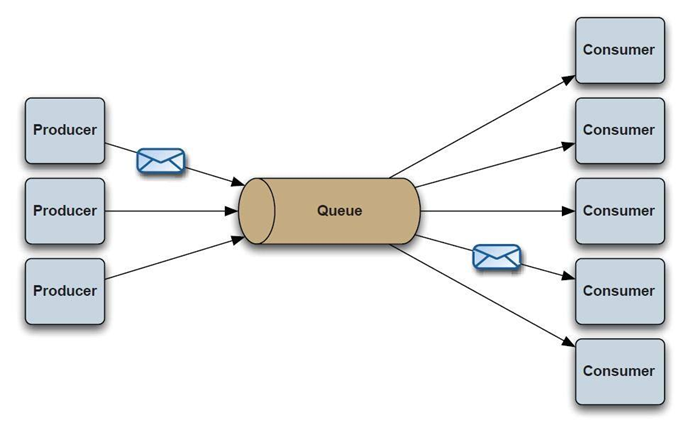

这种场景是日常用得最多之一。我日常需要将多台服务器上的日志集中收集到一个点上,通过logstash进行扫描并发到kafka队列中,然后通过消费者程序进行消费写到hbase或者es中。
消息订阅与发布

这种场景也是日常使用最多之一。在日常项目中,我们可以需要重复消费相同的数据,例如一路数据用来收集入库,另一路数据进行实时分析,两路数据消费使用不到的groupid进行区分即 可。
消息削峰
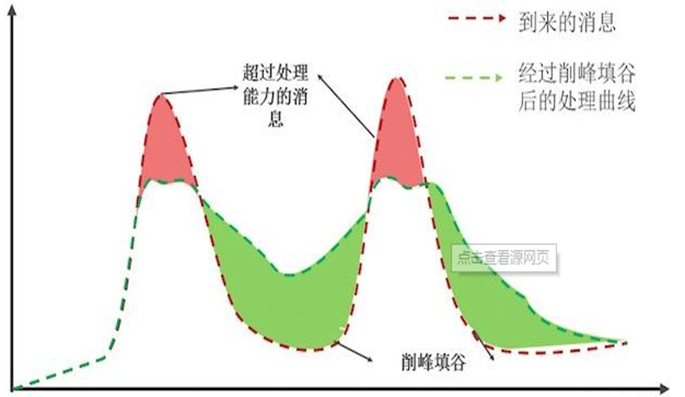
这种场景相对少一些,类似愚公移山,将超过的请求峰值降低到平缓期去处理,使用的是kafka具有一定的缓存能力,默认可以将数据保留7天,当然在硬盘资源允许情况下可以设置更长,最终还是根据实际情况而定。
数据采集
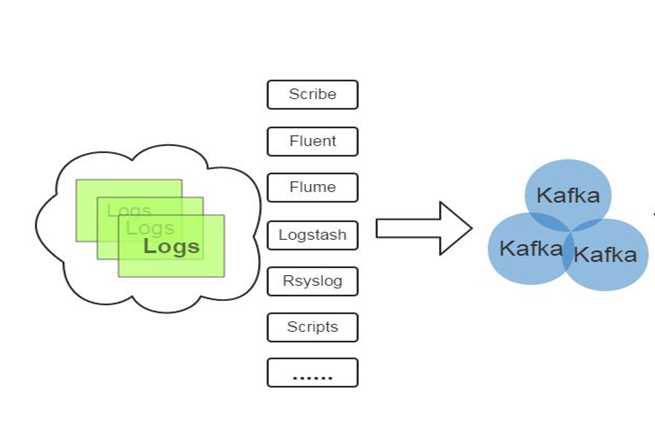
这种应用场景也是最常用之一。当我们面对很多平台或组件的日志时,需要将这些平台或组件的日志统一起来,可以通过kafka统一起来,再分类处理,毕竟kafka是将数据进行字节流处理,不关注数据格式。
流处理
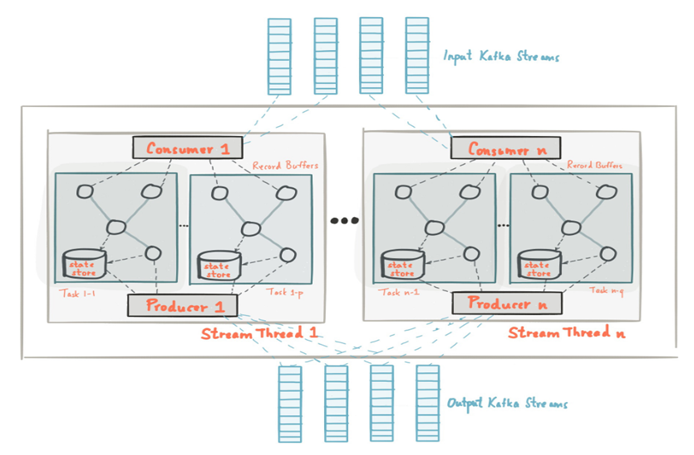
这种用法我暂时也没有用过,这种是在kafka2.0的版本才出现的,对于这种处理目前我还是使用flink或者spark进行处理,有机会可以尝试下是否具有较高的可用性,毕竟这可以减少组件的维护同时提高数据处理能力。
以上图片是积累下来的,并不是本人亲自去画的,感谢上面几个图的作者,但忘记在哪里找些图的了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182021.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
