大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Precision,Recall,F1score,Accuracy四个概念容易混淆,这里做一下解释。
假设一个二分类问题,样本有正负两个类别。那么模型预测的结果和真实标签的组合就有4种:TP,FP,FN,TN,如下图所示。这4个分别表示:实际为正样本你预测为正样本,实际为负样本你预测为正样本,实际为正样本你预测为负样本,实际为负样本你预测为负样本。


那么Precision和Recall表示什么意思?一般Precision和Recall都是针对某个类而言的,比如正类别的Recall,负类别的Recall等。如果你是10分类,那么可以有1这个类别的Precision,2这个类别的Precision,3这个类别的Recall等。而没有类似全部数据集的Recall或Precision这种说法。
正样本的Precision表示你预测为正的样本中有多少预测对了,如下公式。
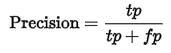
正样本的Recall表示真实标签为正的样本有多少被你预测对了,如下公式。二者的差别仅在于分母的不同。
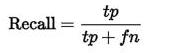
还有一个概念:Accuracy,表示你有多少比例的样本预测对了,公式如下,分母永远是全部样本的数量,很好理解。很容易扩展到多类别的情况,比如10分类,那么分子就是第一个类别预测对了多少个+第二个类别预测对了多少个+…+第十个类别预测对了多少个。
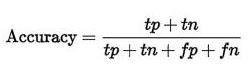
F1score的计算是这样的:1/F1score = 1/2(1/recall + 1/precision)*,简单换算后就成了:F1score=2recallprecision/(recall+precision)。同样F1score也是针对某个样本而言的。一般而言F1score用来综合precision和recall作为一个评价指标。还有F1score的变形,主要是添加一个权重系数可以根据需要对recall和precision赋予不同的权重。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181981.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
