大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
________________________________________________________________________________________________________
F1 score是一个用来评价二元分类器的度量。先回顾一下它的计算公式:
F1=21recall+1precision=2recall×precisionrecall+precisionF1=21recall+1precision=2recall×precisionrecall+precision
F1是针对二元分类的,那对于多元分类器,有没有类似F1 score的度量方法呢?有的,而且还不止一种,常用的有两种,这就是题主所问的两种,一种叫做macro-F1,另一种叫做micro-F1。
macro-F1
假设对于一个多分类问题,有三个类,分别记为1、2、3,
TPiTPi是指分类ii的True Positive;
FPiFPi是指分类ii的False Positive;
TNiTNi是指分类ii的True Negative;
FNiFNi是指分类ii的False Negative。
接下来,我们分别计算每个类的精度(precision)
precisioni=TPiTPi+FPiprecisioni=TPiTPi+FPi
macro精度就是所有精度的均值
precisionma=precision1+precision2+precision33precisionma=precision1+precision2+precision33
类似地,我们分别计算每个类的召回(recall)
recalli=TPiTPi+FNirecalli=TPiTPi+FNi
macro召回就是所有召回的均值
recallma=recall1+recall2+recall33recallma=recall1+recall2+recall33
最后macro-F1的计算公式为
F1,ma=2recallma×precisionmarecallma+precisionmaF1,ma=2recallma×precisionmarecallma+precisionma
micro-F1
假设对于一个多分类问题,有三个类,分别记为1、2、3,
TPiTPi是指分类ii的True Positive;
FPiFPi是指分类ii的False Positive;
TNiTNi是指分类ii的True Negative;
FNiFNi是指分类ii的False Negative。
接下来,我们来算micro精度(precision)
precisionmi=TP1+TP2+TP3TP1+FP1+TP2+FP2+TP3+FP3precisionmi=TP1+TP2+TP3TP1+FP1+TP2+FP2+TP3+FP3
以及micro召回(recall)
recallmi=TP1+TP2+TP3TP1+FN1+TP2+FN2+TP3+FN3recallmi=TP1+TP2+TP3TP1+FN1+TP2+FN2+TP3+FN3
最后micro-F1的计算公式为
F1,mi=2recallmi×precisionmirecallmi+precisionmiF1,mi=2recallmi×precisionmirecallmi+precisionmi
如果这个数据集中各个类的分布不平衡的话,更建议使用mirco-F1,因为macro没有考虑到各个类别的样本大小。
________________________________________________________________________________________________________
准确率与召回率(Precision & Recall)
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
正确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
1. 正确率 = 提取出的正确信息条数 / 提取出的信息条数
2. 召回率 = 提取出的正确信息条数 / 样本中的信息条数
两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
3. F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
2、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1,也即
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
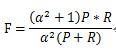

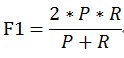
参考文章:
http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/
http://sofasofa.io/forum_main_post.php?postid=1001112
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181906.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
