大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
利用python实现方差分析
简介
方差分析是一种常用的对数据进行分析的方法,用于两个及两个以上样本均数和方差差别的显著性检验。本文介绍单因素方差分析和双因素方差分析。
方差分析存在三个假设:
1、各样本总体服从正态分布。
2、各样本总体方差一样。
3、各样本总体相互独立。
单因素方差分析
单因素方差分析就是在只有一种影响因素下判断各个样本间的均值差别的显著性。
数据会有一个总的方差(SST),这个方差可分为:因素影响产生(SSA)和由于随机误差产生(SSE)。
单因素方差分析的过程分为5步:
1、做出假设:H0:u1 = u2 = u3=…un。
2、选取置信度:sig。
3、选取测试数据的方法:F分布。
4、利用数据进行计算。
5、通过计算的数据得到的结果做出判断。
计算数学公式如下:
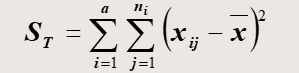

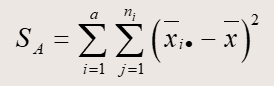
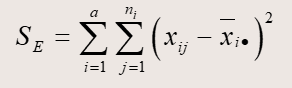
其中SSE服从自由度为n-k的卡方分布,SSA服从自由度为k-1的卡方分布。n为样本容量,k为影响因素的分组数。最后利用F分布来计算显著度。
通过python可以通过如下方式实现:
#one_way variance analysis for mean
def oneway_var_test(df, sig):
data = np.array(df)
x = np.mean(data)
n = len(data)*len(data[0])
k = len(data[0])
m = len(data)
SStotal = np.var(data)*n
df_total = n-1
SSE = np.var(df).sum()*m
SST = (np.square(np.mean(df)-np.mean(arr))).sum()*m
df_e = n-k
df_t = k-1
MST = SST/df_t
MSE = SSE/df_e
F = MST/MSE
p = stats.f.sf(F,df_t,df_e)
result = pd.DataFrame(index =['Treatment','Error','Total'],
columns = ['Sum of Squares', 'Degree of Freedom', 'Mean Square','F', 'p'])
result['Sum of Squares'],result['Degree of Freedom']= [SST, SSE, SStotal],[df_t, df_e, df_total]
result['Mean Square'],result['F'],result['p'] = [MST, MSE,np.nan],[F, np.nan, np.nan],[p, np.nan, np.nan]
if p < sig:
print('在显著度为'+str(sig)+'下,组间均值有差异')
else:
print('在显著度为'+str(sig)+'下,组间均值无差异')
print (result)
return result
其中输入的df为dataframe, sig为置信度。
双因素方差分析
双因素方差分析是指在两种因素的影响下,判断各个样本间的均值差别的显著性。
数据的总的方差SST可分解为:由因素A影响产生的方差SSA,由因素B影响产生的方差SSB,以及由随机误差影响产生的方差SSE。
双因素方差分析的过程分为5步:
1、做出假设:a)H0:A因素对数据产生的影响为0。H1:A因素对数据产生的影响不为0。
b)H0:B因素对数据产生的影响为0。H1:B因素对数据产生的影响不为0。
2、选取置信度:sig。
3、选取测试数据的方法:F分布。
4、利用数据进行计算。
5、通过计算的数据得到的结果做出判断。
数学公式如下:
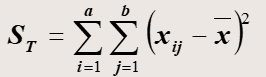
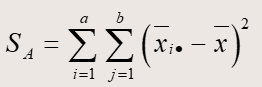
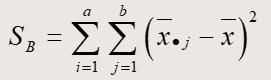
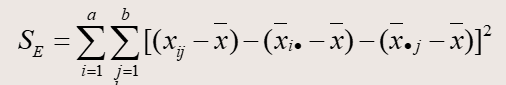
其中SSA服从自由度为k-1的卡方分布,SSB服从自由度为b-1的卡方分布,SSE服从自由度为(k-1)(b-1)
通过python可以通过如下方式实现:
#two_way variance analysis for mean
def twoway_var_test(df, sig):
data = np.array(df)
x = np.mean(data)
n = len(data)*len(data[0])
k = len(data[0])
m = len(data)
SStotal = np.var(data)*n
SST = (np.square(np.mean(df)-np.mean(arr))).sum()*m
SSB = (np.square(np.mean(df, axis=1)-np.mean(arr))).sum()*k
SSE = SStotal - SST - SSB
df_total = n-1
df_e = (k-1)*(m-1)
df_t = k-1
df_b = m-1
MST = SST/df_t
MSE = SSE/df_e
MSB = SSB/df_b
FT = MST/MSE
FB = MSB/MSE
pt = stats.f.sf(FT,df_t,df_e)
pb = stats.f.sf(FB,df_b,df_e)
result = pd.DataFrame(index =['TreatmentT','TreatmentB','Error','Total'],
columns = ['Sum of Squares', 'Degree of Freedom', 'Mean Square','F', 'p'])
result['Sum of Squares'],result['Degree of Freedom']= [SST,SSB,SSE, SStotal],[df_t,df_b,df_e, df_total]
result['Mean Square'],result['F'],result['p'] = [MST,MSB, MSE,np.nan],[FT,FB,np.nan, np.nan],[pt,pb, np.nan, np.nan]
if pt < sig:
print('在显著度为'+str(sig)+'下,T因素对均值有影响')
else:
print('在显著度为'+str(sig)+'下,T因素对均值无影响')
if pb < sig:
print('在显著度为'+str(sig)+'下,B因素对均值有影响')
else:
print('在显著度为'+str(sig)+'下,B因素对均值无影响')
print (result)
return result
其中输入的df为dataframe, sig为置信度。
python编写
编写过程中利用到的库有numpy、pandas、scipy库。利用numpy库和pandas库对数据进行处理和计算,通过scipy库的stats得到F分布的概率的分位点。最后通过同一组数据在excel表格上同样的分析,得到的结果一致,进而确定代码编写成功。
利用excel进行检验结果是否正确
利用到的数据如下:
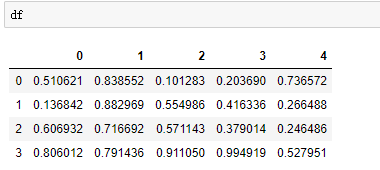
对单因素方差分析进行检验:
利用编写函数得到的结果:
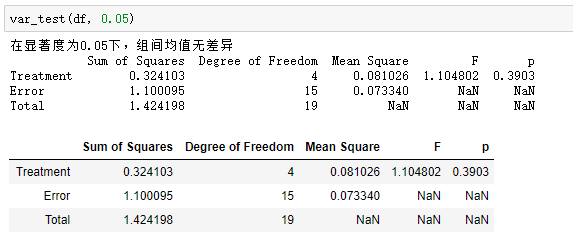
利用excel输出的结果如下:
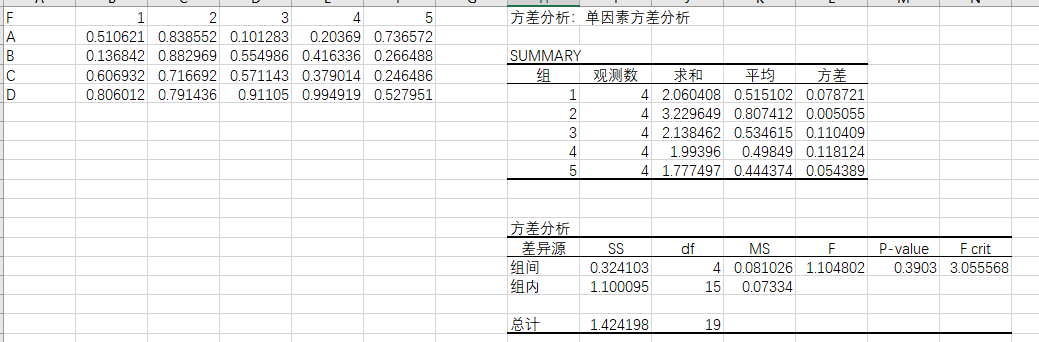
对双因素方差分析进行检验:
利用编写函数得到的结果:
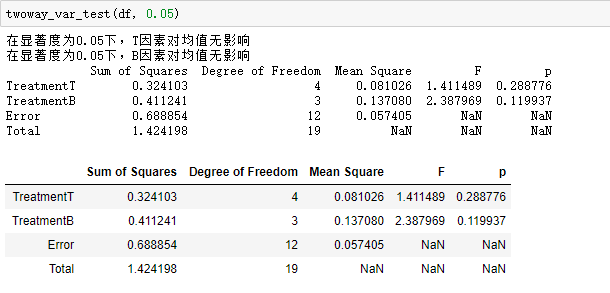
利用excel输出的结果如下: 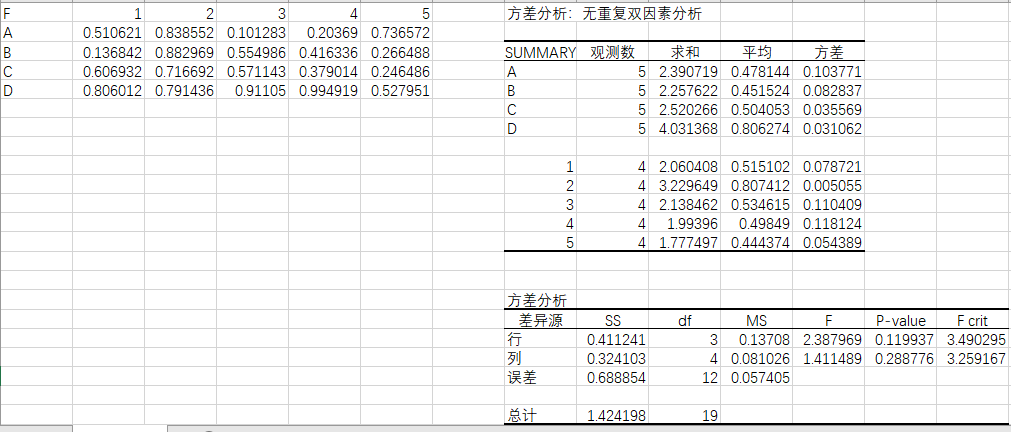
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181774.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
