大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1.准备好需要安装的软件
虚拟机VMware12.pro


操作系统CentOS 6.5

远程控制虚拟机的终端SecureCRT8.1

2.在虚拟机中安装CentOS操作系统
安装好虚拟机,图形界面如下图
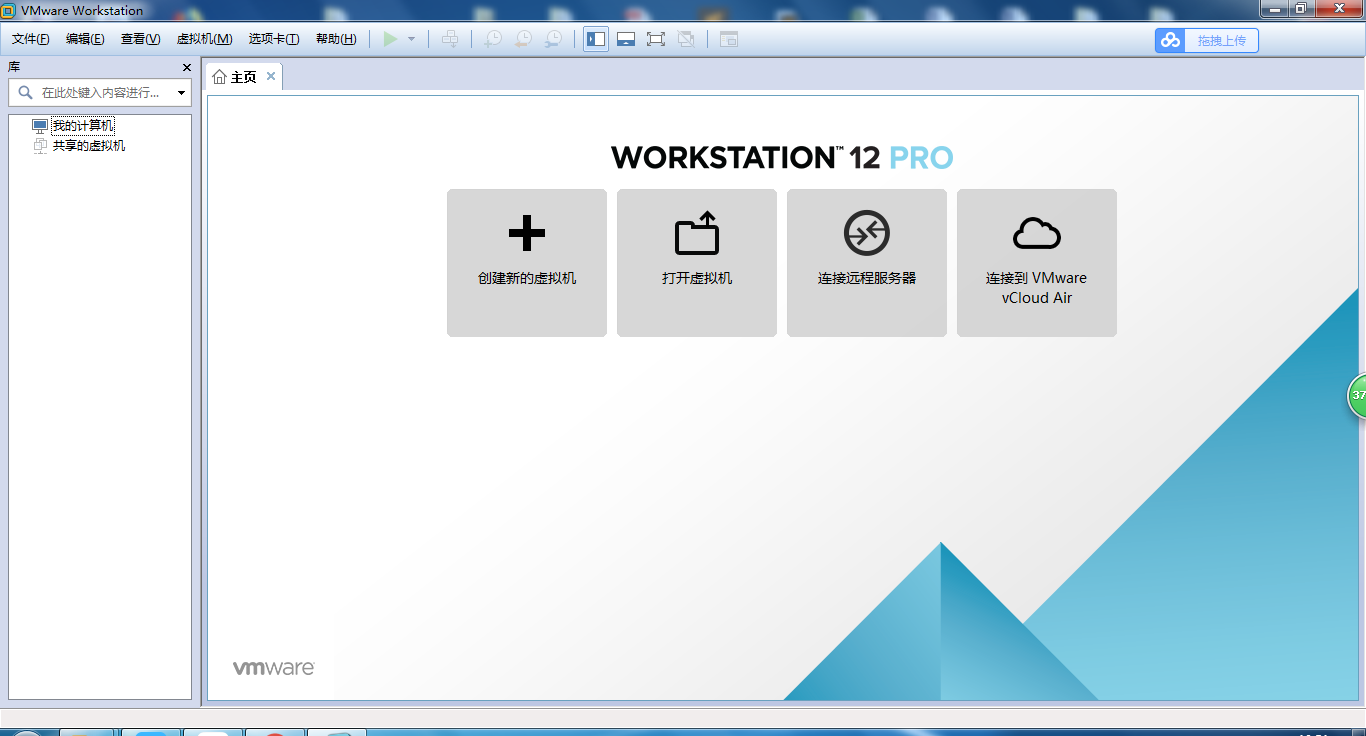
创建新的虚拟机,选择自定义(高级),点击下一步
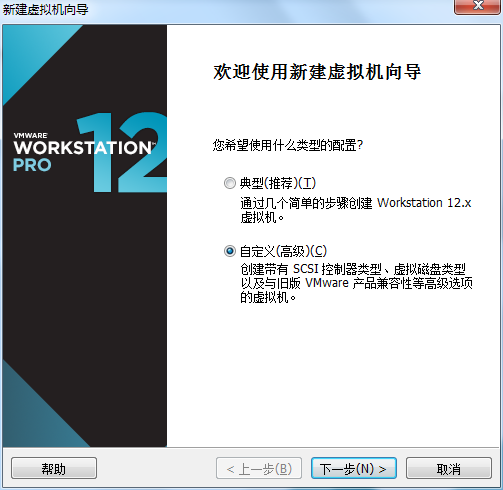
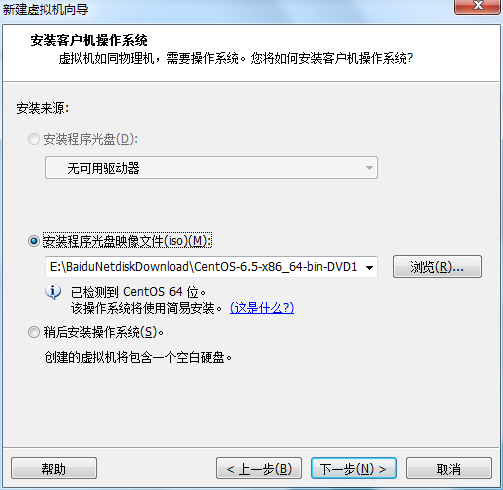
虚拟机硬件兼容性默认,浏览需要安装的CentOS6.5镜像文件
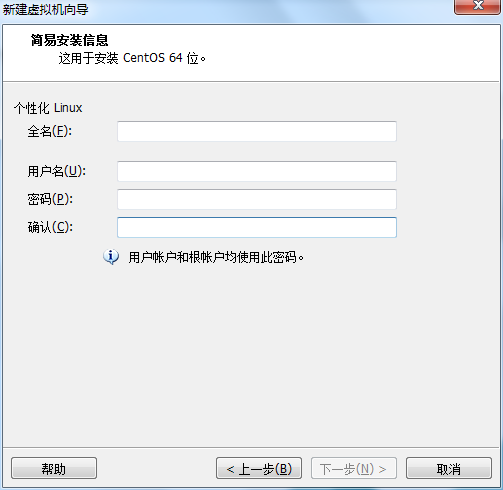
自定义用户名和密码(用于登录)
设置虚拟机名称和存储路径
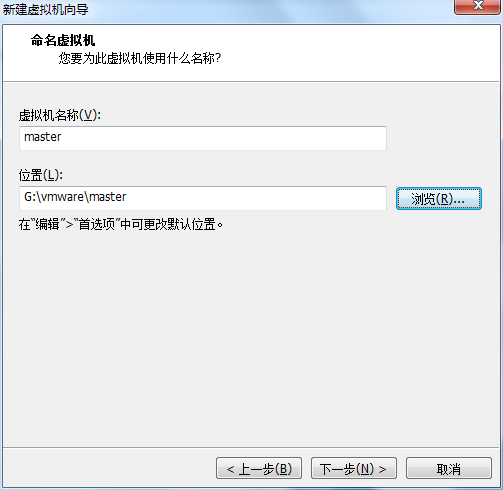
处理器设置默认(后面可以修改),内存设为1GB
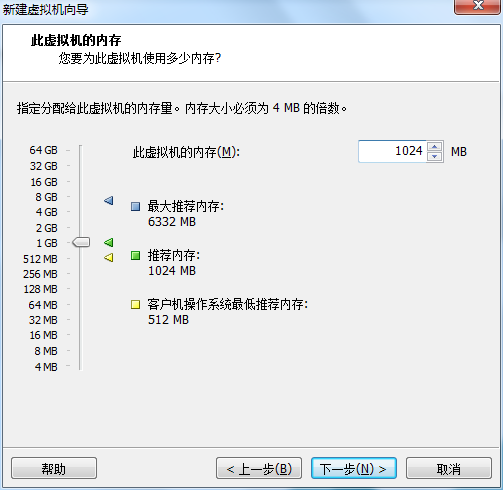
网络类型选择NAT模式
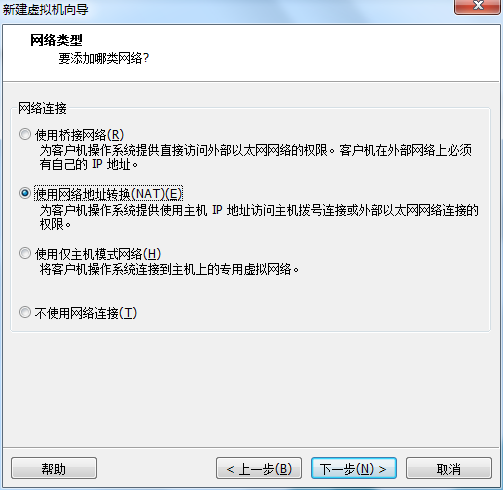
选择创建新虚拟磁盘
最大磁盘大小设为20GB,然后将虚拟磁盘存储为单个文件
将创建好的磁盘文件存储在虚拟机指定目录下
虚拟机创建完成
3. 虚拟网络配置
编辑虚拟网络设置,选择NAT模式
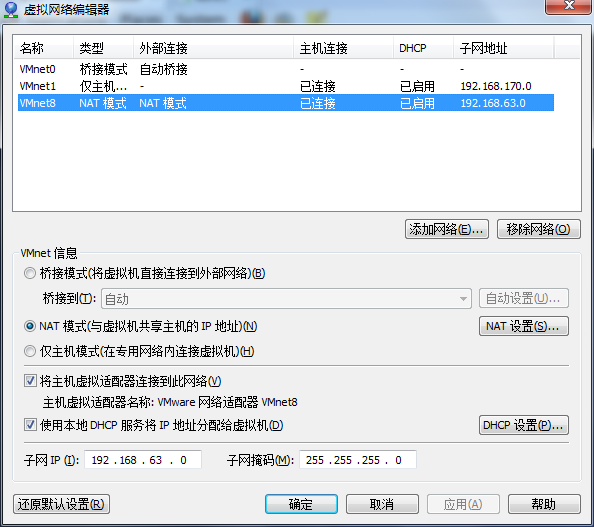
点击NAT设置,查看网络信息(后面设置ip会用到)
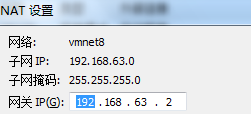
查看主机ip地址
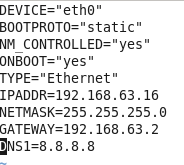
修改网络配置文件,将BOOTPROTO值修改为”static”
重启网络服务network
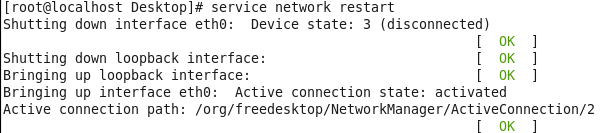
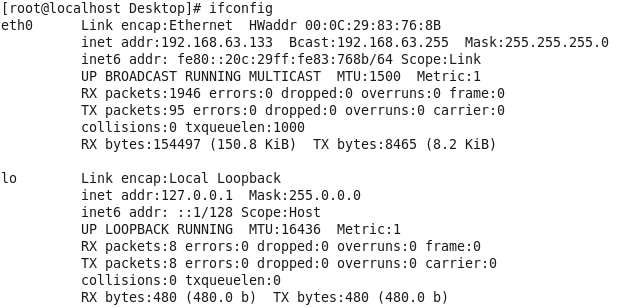
再次查看主机ip

4. 更改主机名称
修改主机名文件(重启永久生效)

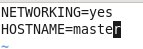
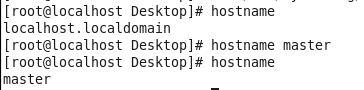
查看主机名hostname(文件修改后没有重启主机名没有生效,可以用hostname临时生效)
复制master文件两次,重命名为slave1和slave2,打开虚拟机文件,然后按照同样的方法设置两个节点的ip和主机名



5.建立主机名和ip的映射
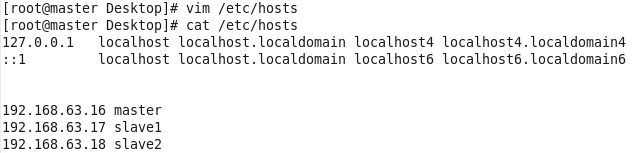
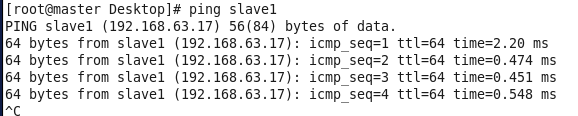
查看是否能ping通
6.配置ssh免密码登录
在root用户下输入ssh-keygen -t rsa 一路回车
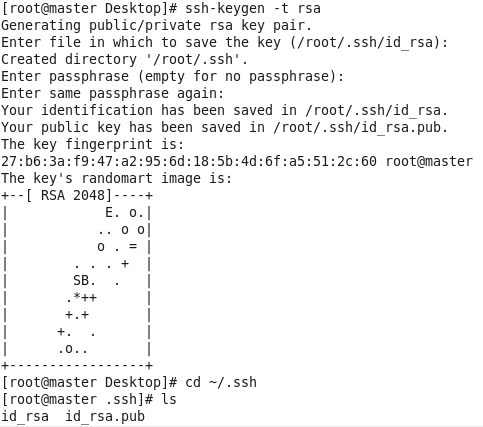
秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限

同理在slave1和slave2节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys


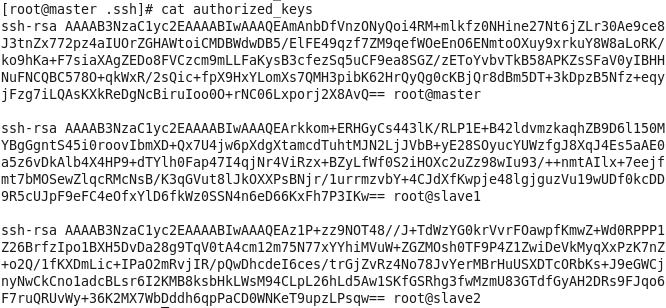
将master节点上的authoized_keys远程传输到slave1和slave2的~/.ssh/目录下
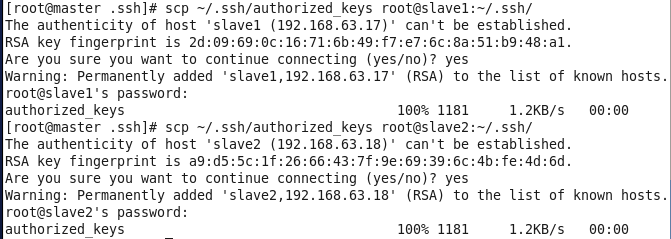
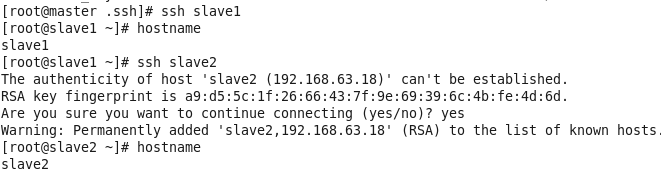
检查是否免密登录(第一次登录会有提示)
7.关闭防火墙
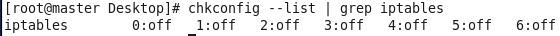
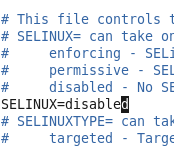
关闭selinux(永久)
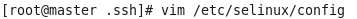
8.安装JDK
三个节点安装java并配置java环境变量

解压压缩包

在/etc/profile文件里添加jdk路径
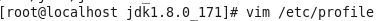
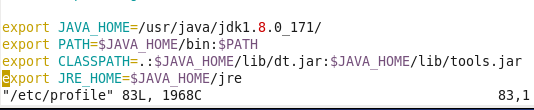
执行命令source /etc/profile使配置文件生效,并查看java版本信息

9.安装MySQL(主节点)
查询系统已安装的mysql

彻底卸载mysql及其所依赖的包

解压MySQL包
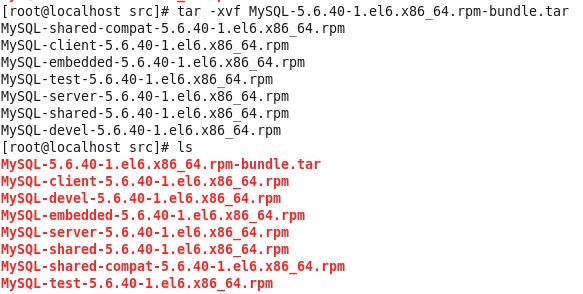
安装MySQL有关的三个rpm包,分别为server、client和devel包
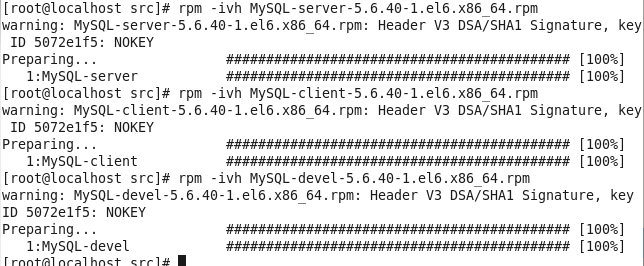
启动mysql /usr/bin/mysqld_safe –skip-grant-tables & 并登陆mysql数据库
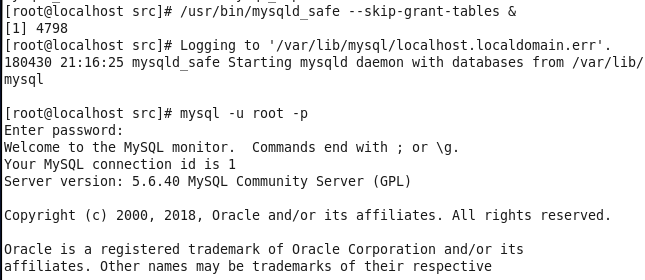
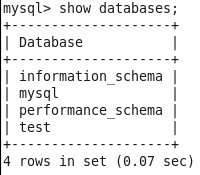
查看mysql中的数据库
10.安装SecureCRT
操作比较简单,安装好的图形界面如图

连接好之后
12.搭建集群
12.1 集群结构
三个结点:一个主节点master两个从节点 内存1GB 磁盘20GB
|
Ip地址 |
主机名 |
Namenode |
Secondary namenode |
Datanode |
Resource Manager |
NodeManager |
|
192.168.63.16 |
master |
Y |
Y |
N |
Y |
N |
|
192.168.63.17 |
slave1 |
N |
N |
Y |
N |
Y |
|
192.168.63.18 |
slave2 |
N |
N |
Y |
N |
Y
|
12.2 新建hadoop用户及其用户组
用adduser新建用户并设置密码
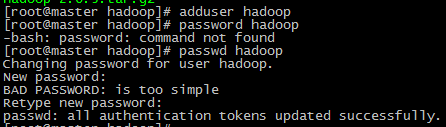
将新建的hadoop用户添加到hadoop用户组

前面hadoop指的是用户组名,后一个指的是用户名


赋予hadoop用户root权限


12.3 安装hadoop并配置环境变量
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/目录下并解压

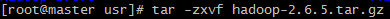

配置环境变量
在/etc/profile文件中添加如下命令

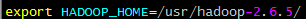

12.4 搭建集群的准备工作
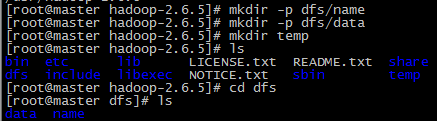
在master节点上创建以下文件夹
/usr/hadoop-2.6.5/dfs/name
/usr/hadoop-2.6.5/dfs/data
/usr/hadoop-2.6.5/temp
12.5 配置hadoop文件
接下来配置/usr/hadoop-2.6.5/etc//hadoop/目录下的七个文件
slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh yarn-env.sh
配置hadoop-env.sh

配置yarn-env.sh
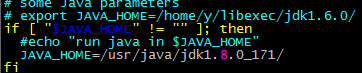
配置slaves文件,删除localhost

配置core-site.xml
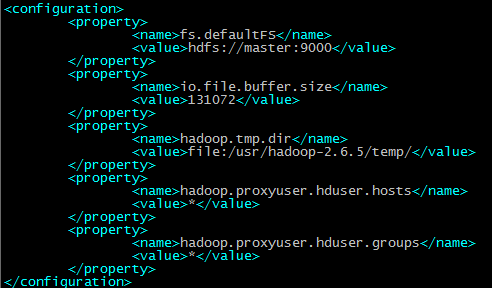
配置hdfs-site.xml
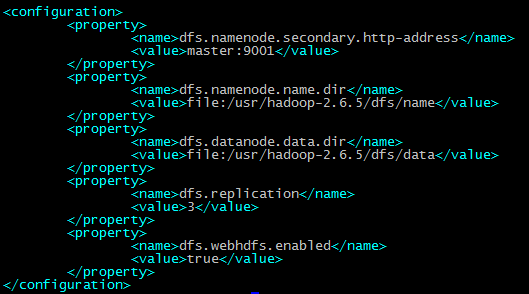
配置mapred-site.xml
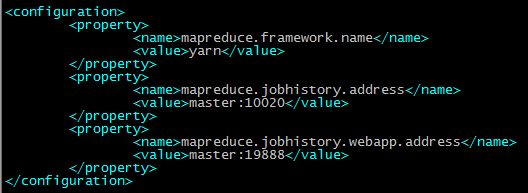
配置yarn-site.xml
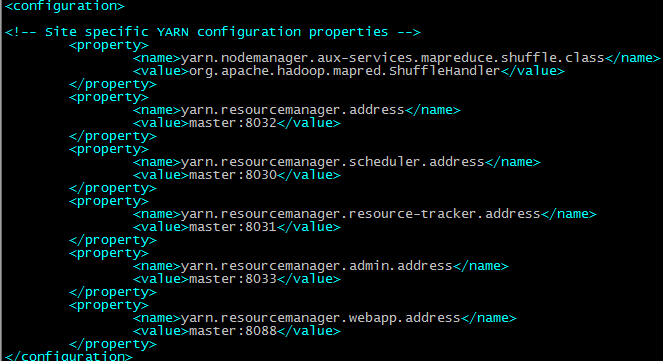
将配置好的hadoop文件复制到其他节点上


12.6 运行hadoop
格式化Namenode

source /etc/profile

13. 启动集群
[root@master sbin]# ./start-all.sh
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181748.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
