大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
《斯坦福算法博弈论二十讲》学习笔记(持续更新)
-
-
- —————————-第一部分机制设计—————————
- 第一章 简介和实例
- 第二章 机制设计基础
- 第三章 迈尔森引理
- 第四章 算法机制设计
- 第五章 收益最大化拍卖
- 第六章 简单的近似最优拍卖
- 第七章 多参数机制设计
- 第八章 频谱拍卖
- 第九章 含支付约束的机制设计
- 第十章 肾脏交换和稳定匹配
- —————————第二部分无秩序代价————————-
- 第十一章 自私路由与无秩序代价
- 第十二章 超额配置和单元自私路由
- 第十三章 均衡:定义、示例和存在性
- 第十四章 平滑博弈的鲁棒无秩序代价界
- 第十五章 最好情况和强纳什均衡
- —————————-第三部分均衡计算————————–
- 第十六章 最优反应动力学
- 第十七章 无憾动力学
- 第十八章 交换遗憾和最小最大化定理
- 第十九章 纯策略纳什均衡和PLS完全性
- 第二十章 混合策略纳什均衡和PPAD完全性
-
—————————-第一部分机制设计—————————
第一章 简介和实例
- 羽毛球比赛中的规则漏洞
12年伦敦奥运会的羽毛球赛事中发生了一件钻规则漏洞的“丑闻”。赛制规则如下:共分为两个小组,每个小组四只队伍,小组赛阶段各个小组的前两名晋级,A组第1名对阵B组第2名,A组第2名对阵B组第1名,之后进行两两淘汰赛。
TZ是本届赛事公认的强队,已经提前小组赛出线。WY与JK进行一场小组赛,二者之间的胜者将会对阵TZ,因此两只队伍都不想赢,都在“打假赛”。最终两只队伍都被取消资格。
得到结论:在一个由策略型参与者(理性)组成的系统中,规则是至关重要的。博弈参与者采取自私的策略无可非议,因此问题出在机制设计者上。机制设计的目的是设计一系列规则,从而使得参与者的策略型行为能导致好的结果。 - 布雷斯悖论
悖论内容:在简单的公路网络上增加一条线路,反而会增加整体的运行时间。按照常理来说,多修路是可以缓解交通压力的,布雷斯悖论之所以是悖论就是因为与常识不符。
悖论发生来源于每一位司机的自私选择,每个人都想要走最短的路,在不经过交流的情况下,很容易都“一拥而上”。证明了个体最优选择不一定构成全局的最优选择。
无秩序代价 POA
定义为策略型参与者自组织情况下系统的表现与系统最优表现得比例。
用于表示局部最优解汇总与全局最优解的接近程度。
部分系统中,局部最优解的汇总就是全局最优解。POA接近于1。
- 均衡定义与均衡计算
在大多数博弈中,一个参与者的最优动作要取决于其他参与者在做什么。均衡就是系统的稳定状态。参与者的策略符合分布的是混合策略纳什均衡。
纳什定理
任何一个有限的双人博弈都含有纳什均衡。
纳什定理在任何含有有限人数的博弈中都成立。
纳什均衡是否可以由一种算法或者一个策略型参与者自己很快计算出来呢?部分简单的博弈中,可以使用线性规划、迭代学习等算法求解纳什均衡。这些算法的结果使得我们相信纳什均衡对于零和博弈有很好的预测能力。
但是在非零和双人博弈中,并不存在能计算纳什均衡的快速算法。计算双人博弈的纳什均衡是一个少有的、自然的且展现出中等计算困难度的问题。
只有存在有效算法快速求解均衡,均衡对于博弈的预测能力才具有意义。博弈中也可能存在多个纳什均衡,均衡的不唯一性也削弱了均衡的预测能力。对于计算机从业者来说,严格均衡的不可计算性使得我们开始研究计算可行的均衡概念,例如相关均衡、粗糙相关均衡。
第二章 机制设计基础
- 单物品拍卖
竞拍者使用的效用模型是拟线性效用模型。每位竞拍者都会对于物品有一个非负的估值 v i v_i vi,即他愿意为该物品支付的最高额度。竞拍者希望在价格不超过 v i v_i vi的前提下,尽可能便宜地获得该物品。如果竞拍者在拍卖中输了,那么获得效用为0。如果竞拍者以价格 p p p赢得了这场竞拍,则他的效用为 v i − p v_i-p vi−p。 - 密封价格拍卖
1.每个竞拍者 i i i私下将他的报价 b i b_i bi提交给卖家。
2.卖家决定谁能够得到物品(如果存在这样的竞拍者)。
3.卖家决定卖出的价格。
可以看出,密封价格拍卖由三部分构成:密封报价、拍品分配规则、赢家支付规则。赢家不一定支付自己的报价,自己的报价一定程度上帮助自己赢得竞拍,最终的支付规则由卖家制定。 - 一价拍卖与二价拍卖
一价拍卖就是竞拍获胜者支付自己的出价,同时也是最高的出价。
二价拍卖中的动机
在二价拍卖中,每一个竞拍者 i i i都有占优策略,即将自己的报价 b i b_i bi设定为自己的真正估值 v i v_i vi。
二价拍卖的占优策略表明,二价拍卖对于参与者来说很容易参与,只需根据自己的估值喜好出价即可,不需要过分关注其他参与者。而一价拍卖中,如果按照真实喜好报价,只会保证自己的效用为0(无论获胜与否)。
证明过程:
其他竞拍者的报价向量为 b − i b_{-i} b−i,我们需要证明其他竞拍者报价任意的前提下,竞拍者 i i i的效用在 b i = v i b_i=v_i bi=vi时最大。令 B = m a x j ≠ i b j B=max_{j\neq i}b_j B=maxj=ibj表示除i以外的最高报价。如果 b i < B b_i<B bi<B,那么输掉竞拍,效用为0。如果 b i > = B b_i>=B bi>=B,那么赢得竞拍,效用为 v i − B v_i-B vi−B。当 v i < B v_i<B vi<B时,最高效用为 m a x { 0 , v i − B } = 0 max\{0,v_i-B\}=0 max{
0,vi−B}=0, i i i说谎不会获得更高收益。当 v i > = B v_i>=B vi>=B时,最高效用为 m a x { 0 , v i − B } = v i − B max\{0,v_i-B\}=v_i-B max{
0,vi−B}=vi−B, i i i说谎同样不会获得更高收益。
二价拍卖中的非负效用
二价拍卖都保证每一个说真话的竞拍者的效用不为负。
无论竞拍输赢,易得竞拍者的效用都非负。这条也叫做个体理性,所有参与者提前预估自己的期望效用,非负才有参加的动力。
- 二价拍卖的理想化
占优策略激励相容 DSIC
在一场拍卖中,如果对于每一个竞拍者按照自己的估值真实报价都是一个占优策略,并且真实报价的竞拍者的效用都非负,则称这个拍卖是占优策略激励相容。
二价拍卖的理想性
1.二价拍卖是DSIC的。
2.二价拍卖是社会福利最大化的。
3.二价拍卖可以在输入量的多项式时间内实施。
DSIC的性质使得参与者的报价选择变得容易,也使得机制设计者对于拍卖结果的预测变得容易。社会福利最大化这个性质,即使卖家提前不知道竞拍者的估值,拍卖也能选出最高估值的竞拍者。二价拍卖可以让拍品来到最需要的人手里(真实估值最高)。
- 经典案例:关键字搜索拍卖
案例背景:网页上有许多空白广告位招商,广告位与广告位之间位置不同、点击率不同,因此存在多个、不同性质的拍品。竞拍者是各大商家,通过密封竞拍的方式完成广告位拍卖。
我们想要设计的机制仍旧是理想化的,依旧满足以下性质:1.DSIC。2.社会福利最大化。3.计算高效。
设计理想化拍卖的一般化方法是:
1.假设报价都是真实的,决定如何分配物品以实现社会福利最大化。
2.设计交易价格,从而使得真实报价成为占优策略。
以下结论待证明:
自然的贪心算法是能够实现最优的(而且是计算高效的),即对于所有的 i = 1 , 2 , . . . , k i=1,2,…,k i=1,2,...,k,将报价第 i i i高的竞拍者分配到点击率第 i i i高的广告位上。
第三章 迈尔森引理
- 迈尔森引理是一个强大且通用的理论工具,它可以帮助我们实现理想化拍卖设计方法的第二步,也就是:设计合适的交易价格,从而使得真实报价成为占优策略。
- 单参数环境
单参数环境是一种对于机制的建模方法,这里的机制不仅局限于拍卖。在单参数环境中,有 n n n个智能体,每个智能体 i i i都对单个物品有非负的估值 v i v_i vi,此估值为私人信息。有一个可行集 X X X,其中每一个元素 x x x都是一个 n n n维向量 ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn),其中 x i x_i xi代表智能体 i i i获得的物品数量。
我们将拍卖拓展泛化到全部机制。拍卖中的概念竞拍者、出价、估值转化到机制中的智能体(agent)、报告(report)、估值。 - 迈尔森引理内容
以下是分配规则应具有的两大良好特性:
可实施的分配规则
对于一个单参数环境,对于一个分配规则 x x x,如果存在一个支付规则 p p p使得直接显示机制 ( x , p ) (x,p) (x,p)是DSIC的,那么就称这个分配规则 x x x是可实施的。
DSIC占优策略激励相容是指,说真话是占优策略并且符合个体理性。如果针对分配规则 x x x可以找到一个支付规则 p p p使得组合后的机制是DSIC的,那么该分配规则就是可实施的。
也就是说DSIC机制的分配规则一定是可实施的。可实施的分配规则决定了“机制设计的空间”。例如分配方式为拍品分配给出价最高的竞拍者,那么存在一种支付规则,也就是二价拍卖,使得组合后的机制是DSIC的。
单调分配规则
简而言之,在一个单调分配规则下,更高的出价会为你赢得更多的物品(或者单物品拍卖中获得更高的获胜概率)。
迈尔森引理内容
1.一个分配规则 x x x是可实施的,当且仅当它是单调的。
2.如果 x x x是单调的,那么存在唯一的支付规则,使得直接显示机制 ( x , p ) (x,p) (x,p)是DSIC的,且使得对于所有报价 b i = 0 b_i=0 bi=0均有 p i ( b ) = 0 p_i(\bold{b})=0 pi(b)=0。
3.(2)中的支付规则有明确的表达式。
迈尔森引理的内容将分配规则的两条特性以及支付规则串联了起来。(1)表明了分配规则的可实施性与单调性是等价的,可实施性如果本身不好判断的话,可以通过单调性来判断。(2)(3)表明了,通过单调性判断可实施性之后,一定存在唯一的支付规则,满足要求且为DSCI,并且该支付规则可以用表达式明确表示。
- 迈尔森引理的证明
迈尔森引理的证明一共分为三个步骤:
1.假设分配规则可实施,证明该分配规则是单调的。
2.在单调的基础上,求解出唯一一个表达式确定的支付规则。
3.在单调且唯一支付规则确定的基础上,证明该机制是DSIC的,也就是该分配规则可实施。
证明前的符号声明:针对任意一个固定的 i i i和 b i b_i bi, i i i的报价为 z z z,为了简化书写将 x i ( z , b − i ) x_i(z,\bold{b_{-i}}) xi(z,b−i)写为 x ( z ) x(z) x(z),将 p i ( z , b − i ) p_i(z,\bold{b_{-i}}) pi(z,b−i)写为 p ( z ) p(z) p(z)。
1.假设分配规则可实施,证明该分配规则是单调的。
假设有一个单调或非单调的分配规则 x x x和一个支付规则 p p p,机制 ( x , p ) (x,p) (x,p)是DSIC的。
存在两个报价 0 < = y < z 0<=y<z 0<=y<z,第一种情况:智能体 i i i私人估值是 z z z,报价是 y y y,即低于估值报价。 z × x ( z ) − p ( z ) > = z × x ( y ) − p ( y ) z\times x(z)-p(z)>=z\times x(y)-p(y) z×x(z)−p(z)>=z×x(y)−p(y);第二种情况:智能体 i i i的私人估值为 y y y,报价为 z z z,即高于估值报价。 y × x ( y ) − p ( y ) > = y × x ( z ) − p ( z ) y\times x(y)-p(y)>=y\times x(z)-p(z) y×x(y)−p(y)>=y×x(z)−p(z),二式联立得:
z × [ x ( y ) − x ( z ) ] < = p ( y ) − p ( z ) < = y × [ x ( y ) − x ( z ) ] z\times [x(y)-x(z)]<=p(y)-p(z)<=y\times [x(y)-x(z)] z×[x(y)−x(z)]<=p(y)−p(z)<=y×[x(y)−x(z)],从而证得单调。
2.在单调的基础上,求解出唯一一个表达式确定的支付规则。
我们首先考虑分配规则是分段常函数,该函数图像仅仅在某几个点存在突变,其他位置都是平坦的。我们来看不同位置的 z z z,支付函数在 z z z的变化与分配函数在 z z z的变化有什么关系。首先假设 z z z处无突变, y y y逼近于 z z z,那么不等式左右两边都是0。假设 z z z处有突变 h h h,不等式左右两边都是 z × h z\times h z×h,因此得到:
p 在 z 处 的 变 化 = z × [ x 在 z 处 的 变 化 ] p在z处的变化=z\times[x在z处的变化] p在z处的变化=z×[x在z处的变化]
p i ( b i , b − i ) = ∑ j = 1 l z j × [ x i ( . , b − i ) 在 z j 处 的 变 化 ] p_i(b_i,b_{-i})=\sum_{j=1}^l z_j\times [x_i(.,b_{-i})在z_j处的变化] pi(bi,b−i)=∑j=1lzj×[xi(.,b−i)在zj处的变化]
其中 z 1 , . . , z l z_1,..,z_l z1,..,zl是分配函数在 [ 0 , b i ] [0,b_i] [0,bi]之间的断点。也就是说,只有分配函数的断点位置才会对支付函数起到累加作用,因此范围内累加所有断点处的突变即可。
如果分配函数 x x x可微,我们便可以将支付函数推广到一般单调函数。
将上式不等式除以 y − z y-z y−z,目的是去凑微分的定义,使得 y y y从上到下无限逼近 z z z,得到下式: p ′ ( z ) = z × x ′ ( z ) p'(z)=z\times x'(z) p′(z)=z×x′(z),结合初始条件 p ( 0 ) = 0 p(0)=0 p(0)=0可以得到以下支付函数: p i ( b i , b − i ) = ∫ 0 b i z × d d z x i ( z , b − i ) d z p_i(b_i,b_{-i})=\int_0^{b_i} z\times \frac{d}{dz}x_i(z,b_{-i})dz pi(bi,b−i)=∫0biz×dzdxi(z,b−i)dz。
3.在单调且唯一支付规则确定的基础上,证明该机制是DSIC的,也就是该分配规则可实施。
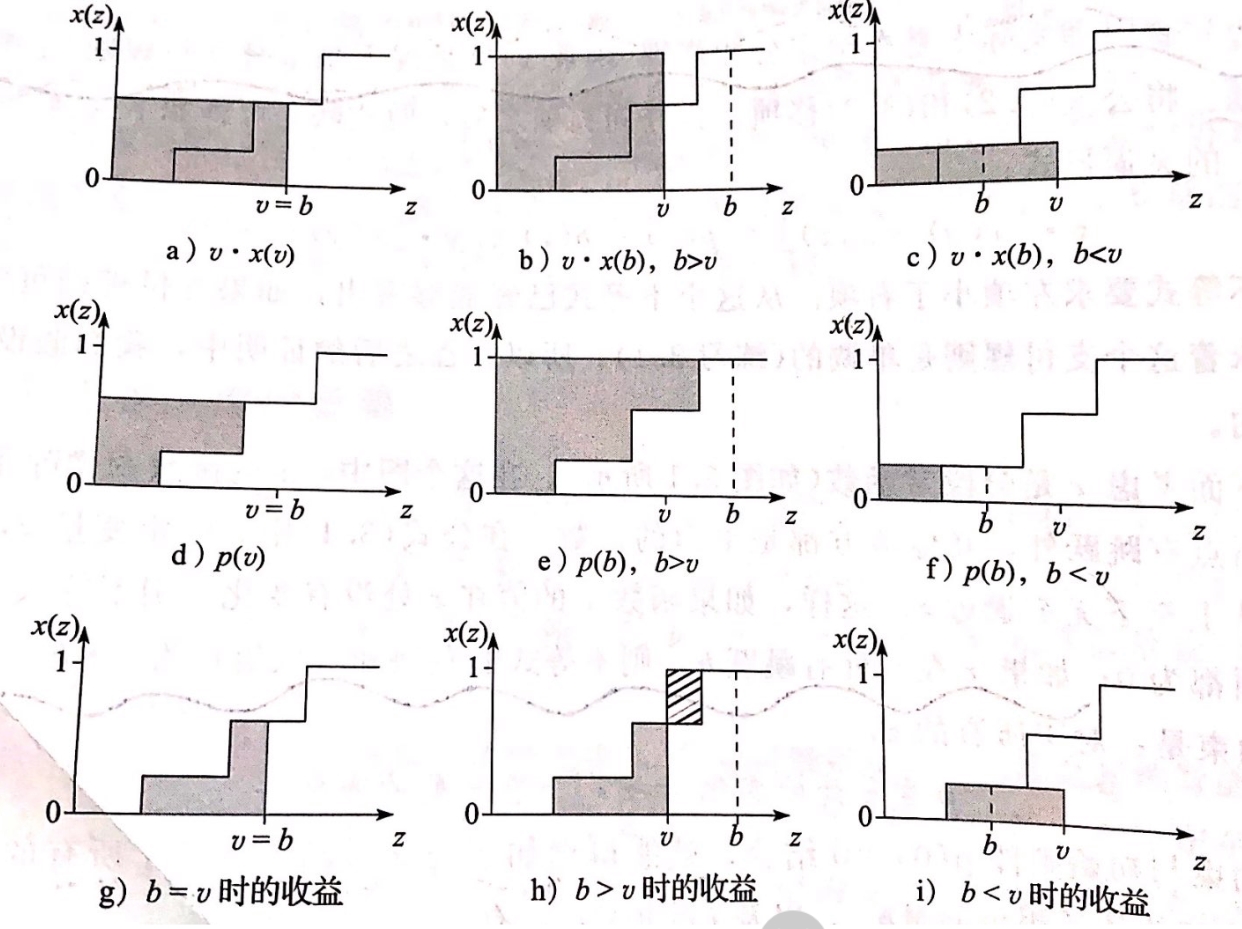

第一、二、三排分别代表拍品带来的效用、效用支付、最后的收益,第一、二、三列分别代表出价等于估值、出价高于估值、出价低于估值。分析最后一排三张图片可以看出,当出价等于估值时收益最高,因此说真话就是占优策略并且收益非负,由此证得机制为DSIC。 - 支付公式的应用
迈尔森引理中的支付公式,效用支付的大小与单调分配函数的增长趋势 x ( z ) x(z) x(z)以及出价 z z z有关。接下来我们用该公式分析一下二价拍卖。
二价拍卖中分配函数只有一个突变点,就是在 B = m a x j ≠ i b j B=max_{j\neq i}b_j B=maxj=ibj处由0突变到1。因此 p i ( b i , b − i ) = B p_i(b_i,b_{-i})=B pi(bi,b−i)=B,看来二价拍卖的设计不是凭空设想,根据迈尔森引理是可以严格证明DSIC的。
第四章 算法机制设计
- 本章节将在更复杂的单参数环境下探究DSIC、福利最大化和计算高效的机制是什么样的。这些足够一般化的环境使得福利最大化称为NP-Hard问题。
- 背包拍卖
在背包拍卖中,每一个竞拍者 i i i都有一个公开的规模 w i w_i wi和一个私有的估值。卖家有容量 W W W。可行集合 X X X是一个 0 − 1 0-1 0−1向量 ( x 1 , . . . , x n ) (x_1,…,x_n) (x1,...,xn),且 ∑ i = 1 n w i x i < = W \sum_{i=1}^n w_ix_i <=W ∑i=1nwixi<=W。
背包拍卖可以简单理解为算法中的单物品非0-1背包问题,只不过物品的获得通过拍卖实现。举个例子说明,电视台在某个时间段有 W W W长度的空闲时间可以用来播放广告,每个竞拍者都有想要播放的广告长度 w i w_i wi以及可以接受的最大出价 v i v_i vi(广告要么不播,要么完全播放,不存在部分满足竞拍者的需求的情况)。
我们想为实现背包拍卖设计一个理想机制。理想机制的设计一般遵从两步走策略:1.假设收到的报价都是真实的,并给出分配规则。2.设计一个支付规则,将该分配规则扩展为一个DSIC机制。
- 福利最大化的背包拍卖
背包拍卖想要实现社会福利最大化,也就是物尽其用,拍品尽可能来到估值最高的人手里,估值最高一般也就代表需求度越高。
x ( b ) = a r g m a x X ∑ i = 1 n b i x i \bold{x}(\bold{b})=argmax_X \sum_{i=1}^n b_ix_i x(b)=argmaxX∑i=1nbixi - 福利最大化的计算困难性
理想机制的三大条件再回顾一下,分别是:(1)DSIC、(2)社会福利最大化、(3)计算可行性。理想机制为何叫理想机制?原因就在于这三个条件很难实际同时成立,只存在于理想中。其中矛盾最大的两个条件就是社会福利最大化与计算可行性,DSIC与计算可行性都会一定程度上降低社会福利最大化,但满足社会福利最大化的分配规则一般无法在多项式时间内完成求解。
既然三个条件无法同时满足,那么应该如何解决呢?**需要在三个条件中至少放松一个。**一般不会放松(1),只会在(2)、(3)上动手。其中算法机制设计研究领域的基本思想,就是在第二个目标上妥协,使用近似最优的福利最大化换取计算的高效性,同时保证DSIC。 - 算法机制设计
算法机制设计的主导模式是:放松理想化拍卖的第二个要求(即社会福利最大化),放松的程度越小越好,同时收到第一个(DSIC)和第三个(多项式时间)要求的约束。
迈尔森引理的作用是在现有可实施的分配规则的基础上,确定支付函数,将该分配规则扩展为DSIC的。 - 背包问题的贪心算法
1.将竞拍者按照以下公式的顺序从高到低排序: b 1 w 1 > = b 2 w 2 > = . . . > = b n w n \frac{b_1}{w_1}>=\frac{b_2}{w_2}>=…>=\frac{b_n}{w_n} w1b1>=w2b2>=...>=wnbn
2.按照这个顺序依次选取赢家,直到背包剩余容量容纳不下新的竞拍者的规模,算法停止。
3.要么返回上一步中的解,要么直接返回最高报价者。判断方法是,对比这两者的社会福利值,哪个更大就返回哪个。
贪心思想如何理解?假设每位竞拍者都真实出价,那么出价越高的代表自己的内心估值越高,对拍品的渴望程度也就越强,对社会福利的贡献也就越大。并且如果竞拍者的需求量越小,就越方便满足更多的竞拍者。换个思路理解,出价除以需求量,可以理解为单位需求的出价密度,当然是越高越优先。
算法何时停止?这类似一个整数背包问题,首先按照贪心顺序,最大化的填满整体规模,当然最后可能会剩下一小块空间,无法支持当前下一个竞拍者的全部规模。
为什么需要二者选一?可能存在一个估值非常高并且规模同时很大的竞拍者,其按照贪心思想并不优先,很可能得不到机会满足。但可能只满足这一个“巨无霸”,就会获得更大的社会福利。
背包拍卖的近似保证
如果竞价都是真实的,那么使用贪心算法分配下的社会福利至少是最大社会福利的 50 % 50\% 50%。
证明思路:贪心算法的第二步其实是非整数背包的前 k k k项估值之和,易得第三步返回的结果至少是非整数背包最优值的二分之一。并且整数背包的最优值小于等于非整数背包,因此原结论得证。
算法机制设计的特点:对于一个NP-Hard的优化问题,首先检查是否可以依靠最先进的近似算法直接实现DSIC机制,如果不行,就将这个问题进行调整,或者设计一种新的近似算法,并尽量保证这种新的算法仍然满足近似率的要求。
- 针对福利最大化问题,最先进的近似算法也许能产生出单调的分配规则,也许不能。也就是说近似算法可能不会满足DSIC。
- 显示原理告诉我们,对于每一个含有占优策略均衡的机制,都存在一个与它等价的、直接显示是占优策略均衡的机制。(机制替你撒谎,你本身不需要对机制撒谎)
- 在许多复杂的机制设计问题中,非DSIC机制可以实现DSIC机制所实现不了的性能。
第五章 收益最大化拍卖
- 之前我们所研究的拍卖的目的都是最大化社会福利,并不太重视拍卖中卖家的收益。本章节我们来考虑拍卖的目的是最大化卖家收益。
举个例子说明一下,考虑单物品只有一个买家,卖家设置一个保留价格 r r r。那么只有两种情况,买家心理估值大于 r r r那么交易成功,否则交易失败。如果目的是最大化社会福利,那么保留价格应设置为 0 0 0,显然这样很不合理。如果目的是最大化卖家收益,那么保留价格应设置为买家估值 v i v_i vi,但估值是买家私人信息,卖家无从知晓。 - 贝叶斯分析最优拍卖
在贝叶斯情境中,如何定义“收益最优”机制一目了然:在所有满足DSIC的机制中,期望收益最高的机制就是“收益最优”机制(假设智能体都真实竞价)。其中,期望是基于给定的分布 F 1 × F 2 × . . . × F n F_1\times F_2\times … \times F_n F1×F2×...×Fn。
考虑单竞拍者单物品拍卖:竞拍者服从 [ 0 , 1 ] [0,1] [0,1]上均匀分布,期望收益为 r × ( 1 − F ( r ) ) = − r 2 + r r\times (1-F(r))=-r^2+r r×(1−F(r))=−r2+r,垄断价格为 1 / 2 1/2 1/2,期望收益为 1 / 4 1/4 1/4。
多竞拍者拍卖:从收益的角度看,增设一个保留价格有好有坏:当所有竞价都低于保留价格时,卖家会损失收益;但只要有一个竞价高于保留价格时,卖家就会增加收益。 - 最优DSIC机制的性质
1.在任意单参数环境和概率分布 F 1 , . . , F n F_1,..,F_n F1,..,Fn下,给出最优DSIC机制(期望收益最大化机制)的明确形式。我们希望找到期望收益的第二种表达形式,该形式只与分配规则有关而与支付规则无关,使用了虚拟估值这个概念。
2.虚拟估值定义如下:
ψ i ( v i ) = v i − 1 − F i ( v i ) f i ( v i ) \psi_i(v_i)=v_i-\frac{1-F_i(v_i)}{f_i(v_i)} ψi(vi)=vi−fi(vi)1−Fi(vi)
虚拟估值最大为 v i v_i vi,且可能为负。虚拟估值的定义可以理解如下: v i v_i vi代表卖家可以从该代理者处获得的最大收益,第二项代表因为 v i v_i vi不确定而造成的收益损失。
3.期望收益等于期望虚拟福利
在任意单参数环境下,若估值分布为 F 1 , . . . , F n F_1,…,F_n F1,...,Fn,在所有满足DSIC的机制 ( x , p ) (x,p) (x,p)中,对于任意智能体 i i i和其他智能体的估值组合 v − i v_{-i} v−i,都有 E v i ∼ F i [ p i ( v ) ] = E v i ∼ F i [ ψ i ( v i ) × x i ( v ) ] E_{v_i \sim F_i}[p_i(v)]=E_{v_i\sim F_i}[\psi_i(v_i)\times x_i(v)] Evi∼Fi[pi(v)]=Evi∼Fi[ψi(vi)×xi(v)]。
也就是说,对于每一个智能体,其期望支付等于其期望虚拟估值。
在任意单参数环境下,若估值分布为 F 1 , . . . , F n F_1,…,F_n F1,...,Fn,在所有满足DSIC的机制 ( x , p ) (x,p) (x,p)中,都有: E v ∼ F [ ∑ i = 1 n p i ( v ) ] = E v ∼ F [ ∑ i = 1 n ψ i ( v i ) × x i ( v ) ] E_{v\sim F}[\sum_{i=1}^np_i(v)]=E_{v\sim F}[\sum_{i=1}^n\psi_i(v_i)\times x_i(v)] Ev∼F[∑i=1npi(v)]=Ev∼F[∑i=1nψi(vi)×xi(v)]
也就是说,期望收益等于期望虚拟福利。
结论表明,即便我们关心的只是收益,我们仍然只需要聚焦在分配规则的优化问题上。之前研究的最大化社会福利的机制设计中,也只是关心分配规则的优化问题上,收益最大化机制设计与之唯一不同的地方就在于,将实际估值函数替换为了虚拟估值。在单物品拍卖中,虚拟福利最大化分配规则就是将物品分配给虚拟估值最高的竞拍者。
4.目前我们已经确定了收益最大化机制的分配规则,那么按照迈尔森定理,我们接下来需要证明分配规则满足单调性,从而利用迈尔森定理设计支付规则。一个完整的收益最大化机制就被设计出来了。
正则分布
如果估值分布 F F F对应的虚拟估值函数 v − 1 − F ( v ) f ( v ) v-\frac{1-F(v)}{f(v)} v−f(v)1−F(v)是关于 v v v非减的,则称该估值分布是正则的。
分配规则单调性
如果所有分布函数都是正则分布,那么虚拟福利最大化分配规则就是单调性的。
第六章 简单的近似最优拍卖
- 上一章节我们可以使用一句话来概括:在单参数环境下,即智能体的估值相互独立且服从正则分布的情况下,在所有满足DSIC的机制中,虚拟福利最大化机制能够最大化期望收益。
- 如果所有竞拍者都独立同分布于一个正则分布,最优单物品拍卖就会变得特别简单。但是实际情况中,更多的是独立分布于不同的正则分布。那么是否存在更加简单实用的单物品拍卖形式,从而使得拍卖至少是近似最优的呢?
- 预知不等式
游戏背景: n n n个阶段的游戏,每个阶段都可以获得一个非负的奖励 π i \pi_i πi,奖励服从分布 G i G_i Gi。你提前知道分布,并且这些分布相互独立。在每回合得知 π i \pi_i πi后,你可以选择接受并退出游戏,也可以选择继续等待进入下一轮。博弈点在于,过早接受可能因小失大,过晚接受又“狗熊掰棒子”。
神奇的预知不等式给出了一个简单的策略,该策略几乎能像先知一样取得很好的奖励。
对于每个元素都服从独立分布的序列 G 1 , . . . , G n G_1,…,G_n G1,...,Gn,存在一个策略能够保证期望收益至少是 1 2 E π ∼ G [ m a x i π i ] \frac{1}{2}E_{\pi \sim G}[max_i\pi_i] 21Eπ∼G[maxiπi]。另外存在一个这样的阈值策略,当且仅当 π i \pi_i πi至少达到阈值 t t t时才接受奖励 i i i。
- 预知不等式应用于简单的单物品拍卖
我们需要对模型做一下迁移。预知不等式中的参与游戏者变成拍卖中的卖家,卖家同样只能选择接受一次或不接受支付。将奖励定义 π i \pi_i πi为竞拍者 i i i虚拟估值的正部 ψ i ( v i ) + \psi_i(v_i)^+ ψi(vi)+。期望收益和奖励为 ψ 1 ( v 1 ) + , . . . , ψ n ( v n ) + \psi_1(v_1)^+,…,\psi_n(v_n)^+ ψ1(v1)+,...,ψn(vn)+的最优停止游戏中先知得到的奖励一样。
E v ∼ F [ ∑ i = 1 n ψ i ( v i ) x i ( v ) ] = E v ∼ F [ m a x i = 1 n ψ i ( v i ) + ] E_{v\sim F}[\sum_{i=1}^n\psi_i(v_i)x_i(v)]=E_{v\sim F}[max_{i=1}^n\psi_i(v_i)^+] Ev∼F[i=1∑nψi(vi)xi(v)]=Ev∼F[maxi=1nψi(vi)+]
虚拟阈值分配规则
1.选择t,使得 P r [ m a x i ψ i ( v i ) + > = t ] = 1 2 Pr[max_i\psi_i(v_i)^+>=t]=\frac{1}{2} Pr[maxiψi(vi)+>=t]=21
2.如果有竞拍者 i i i的 ψ i ( v i ) + > = t \psi_i(v_i)^+>=t ψi(vi)+>=t,就将物品分配给 i i i,当存在多个这样的竞拍者时,随机分配给任意一个打破僵局。
虚拟阈值分配规则是近似最优的,实际收益至少为1/2的最优收益。
带“竞拍者走向”保留价的二价拍卖
1.给每个竞拍者设置特定的保留价 r i = ψ i − 1 ( t ) r_i=\psi_i^{-1}(t) ri=ψi−1(t),其中t与虚拟阈值规则中定义相同。
2.如果存在一个竞价最高的竞拍者,且他的竞价超过保留价,就将物品分配给这个竞拍者。
拥有竞拍者定向保留价的二价拍卖在两个方面比最优拍卖更简单。第一,虚拟估值函数只是用来设置保留价。第二,竞价最高的竞拍者要赢得物品,只需要竞价超过他自己的保留价。
- 先验独立机制是那些表达式中不含有任何估值分布信息的机制。最大化福利机制是先验独立的;而最大化虚拟福利机制不是先验独立的。
- Bulow-Klemperer定理表明,最优单物品拍卖的期望收益至多和多一个竞拍者的二价拍卖一样。
第七章 多参数机制设计
- 单参数机制与多参数机制
单参数机制:智能体的唯一私人参数是他对某个事物的估值。多参数机制:每个智能体都有多个私人参数,机制设计变得更加困难。 - 一般化的机制设计环境
一般化的多参数机制设计环境由以下部分组成:
1. n n n个策略型的参与者,或者叫作智能体。
2.一个结果的有限集合 Ω \Omega Ω。
3.每个智能体对每个结果 ω ∈ Ω \omega\in \Omega ω∈Ω都有一个非负的私人估值 v i ( ω ) v_i(\omega) vi(ω)
单参数单物品拍卖:结果集合中只有 n + 1 n+1 n+1个元素,对应 n n n位智能体获胜以及没人获胜的情况。智能体 i i i只针对自己获胜的结果有估值参数 v i v_i vi,其他结果估值均为 0 0 0。
多参数单物品拍卖:修改设定,竞拍者对于自己未获胜的情况同样有不同的估值,比如说虽然自己不获胜,但是宁愿让A获胜,也不愿意让B获胜。这种就是多参数情况。
组合拍卖:拍卖中物品与物品之间可能存在关联关系,一次拍卖某位竞拍者可能一次性拍下多件物品。假定有 n n n个竞拍者, m m m个物品,结果集合 Ω \Omega Ω中的元素 ω = ( S 1 , . . . , S n ) \omega=(S_1,…,S_n) ω=(S1,...,Sn), S i S_i Si表示分配给 i i i的物品组合,并且每件物品只可以被分配一次。那么一共有 ( n + 1 ) m (n+1)^m (n+1)m种情况(每件物品都可以分配给 n n n个人或者谁也不分配,一共有 m m m件物品)。每位竞拍者都对每一个可能得到的物品组合有一个估值,因此每个竞拍者就有 2 m 2^m 2m个参数。 - VCG机制
多参数最大化福利机制
在任意的一般化的机制设计环境中,都存在一个福利最大化的DSIC机制。
在单参数环境下,我们使用迈尔森引理,来将可实施的分配规则制定合适的支付规则补充为一个DSIC机制。但是当环境不是单参数时,迈尔森引理就不成立了。此时VCG机制应运而生,VCG机制就是为了多参数环境制定了一种DSIC机制的通用解法。
VCG机制
分配规则和支付规则分别如下式的机制 ( x , p ) (x,p) (x,p)叫作VCG机制。
分 配 规 则 最 大 化 社 会 福 利 : x ( b ) = a r g m a x ω ∈ Ω ∑ i = 1 n b i ( ω ) 支 付 规 则 支 付 自 己 的 外 部 性 : p i ( b ) = ( m a x ω ∈ Ω ∑ j ≠ i b j ( ω ) ) − ∑ j ≠ i b j ( ω ∗ ) 分配规则最大化社会福利:x(b)=argmax_{\omega \in \Omega}\sum_{i=1}^n b_i(\omega)\\ 支付规则支付自己的外部性:p_i(b)=(max_{\omega \in \Omega}\sum_{j\neq i}b_j(\omega))-\sum_{j\neq i}b_j(\omega^*) 分配规则最大化社会福利:x(b)=argmaxω∈Ωi=1∑nbi(ω)支付规则支付自己的外部性:pi(b)=(maxω∈Ωj=i∑bj(ω))−j=i∑bj(ω∗)
支付规则中, ω ∗ \omega^* ω∗是由上面分配规则决定的结果,前一项表示不考虑 i i i的效用,寻找最大化其他智能体效用总和的结果。每位智能体支付自己的外部性,也就是自己的边际效用,因为自己的加入对结果造成影响,所带来的其他智能体效用总和的损失。
- VCG机制的实际应用局限
VCG的确为了多参数环境下DSIC机制的设计提供了可能,但仅仅是一个理论结果,实际应用存在着许多问题。
1.偏好获取困难。多参数环境中代表每个人的参数都可能有十万甚至百万量级,挨个调查搜索明显是不实际的。
2.计算困难。福利最大化的分配规则在时间复杂度上也可能是计算困难的。
3.VCG机制的收益和激励存在问题。收益体现出非单调的性质,可能会导致合谋、假名竞价等问题。
第八章 频谱拍卖
- 本章以案例分析的形式介绍在无限频谱配置中运用的组合拍卖,这是一类重要且具有挑战性的多参数机制设计问题。
- 非直接机制
直接机制直接完全暴露自己的估值,这有时是不合时宜或者是不安全的,因此催生了非直接机制。除了一些最简单的场景外,对绝大部分的组合拍卖问题来说,使用抽取适量竞拍者估值信息的非直接机制都是不可避免的。 - 分开拍卖多个物品
组合拍卖中,竞拍者可以一次性拍下多个物品的组合,同时也需要向中心提交自己对于多物品组合的估值偏好,这样会泄露大量信息。那么我们为了尽可能地少泄露信息,想到将多个物品分开拍卖。
组合拍卖中地物品存在两种关系:互为替代品、互为互补品。
互为替代品: v ( A B ) < = v ( A ) + v ( B ) v(AB)<=v(A)+v(B) v(AB)<=v(A)+v(B)。当物品之间互为替代品时,把多个物品分开单独拍卖能取得良好的效果。
互为互补品: v ( A B ) > = v ( A ) + v ( B ) v(AB)>=v(A)+v(B) v(AB)>=v(A)+v(B)。当物品之间互为互补品时,像把多个物品分开单独拍卖的简单机制无法获得良好的效果。
通常在组合拍卖中,待拍物品往往是替代品与互补品的混合体,如果物品大部分是替代品,那么通过合适的设计,分开拍卖单个物品会有良好的表现。否则,我们需要设计更复杂的拍卖形式,来获得具有高社会福利的分配。 - 案例分析:同时升价拍卖
当拍卖多个物品时,有很多种方法都可以用来组织分离式单物品拍卖。我们在正式接受同时升价拍卖之前,先看两种错误的设计方案。
1.逐次进行单物品拍卖,每次拍卖一个物品。这种竞价行为会导致拍卖结果的不可预测性,并有可能获得低社会福利的资源分配以及低的收益。
2.使用密封竞价式单物品拍卖。在同时密封竞价拍卖中明智地进行竞价是富有挑战性的,这也最终导致此种拍卖很容易就以低社会福利和低收益结尾。
同时升价拍卖的优点:
1.防止出现竞拍者“狙击”的行为。
2.同时升价拍卖具有价值发现的特性。即竞拍者可以随着竞拍的进行调整自己的偏好以及估值。
3.竞拍者只需要根据“有必要知晓”原则来确定对物品的估值。
4.拍卖结束后只有少量或者是没有转卖行为,并且转卖价格与成交价接近。
5.相似物品的成交价应该接近。
6.拍卖获得的收益应该达到或者超过预期。
同时升价拍卖的缺点:
1.存在需求递减的情况。是指竞拍者发布一个比真实需求更小的需求量,以求降低竞争,并以较低的价格获得一些物品。
2.当物品为互补品的时候,存在怕披露问题。过于激进的竞拍者有可能获得不想要的物品,过于犹豫的竞拍者可能错过对他来说估值最高的物品。
发送竞价信号
竞拍者之间可能通过发布奇怪的数字来起到交流的作用,比如警告、威胁等等。机制设计者想要通过规则约束,不过无法通过规则设计消除所有的策略型行为。 - 组合竞价
当物品为互补品时,采用同时升价拍卖可能会导致披露问题,也就是说竞拍者可能最终只获得一个自己偏好的无用物品子集。使用组合竞价的方法可以解决此问题,组合竞价是指不仅可以针对单一物品出价,也可以针对部分物品组合出价。但同时组合竞价增加了实用型拍卖的复杂度并且可能会导致不可预测的结果。组合竞价的实际应用可能性有待商榷。
组合竞价目前有以下两种可能的应用方案:
1.第一种设计方法是在同时升价拍卖结束后附加一个额外的回合,在这个回合里竞拍者在满足活跃规则下可以提交任何他想要的物品子集的竞价。
2.第二种方法是预先定义好一些可被允许进行组合竞价的物品集合,而不是让竞拍者自由地进行组合竞价。 - 案例分析:2016年FCC激励拍卖
1.在无线频谱拍卖中,待拍卖的频谱资源从何而来呢?这些资源不可能一开始是空闲的,肯定是掌握在其所有者手里,因此频谱资源需要竞拍组织者使用逆向拍卖的方式从所有者手里获得。
2.逆向拍卖中竞拍者成了卖家,卖家出价。交易的决定者成了买家,买家比较拍品以及价格,选择自己偏好的交易。每个竞拍者对广播许可证有一个私有估值 v i v_i vi(可以理解为从竞拍者 i i i手里购买的最低出价),如果竞拍者失败(没卖出去),那么获得收益为0;如果他以价格 p p p赢得了拍卖(也就是以 p p p价格自己的许可证被收购),获得收益为 p − v i p-v_i p−vi。 N N N表示所有竞拍者集合, W W W表示赢家集合(也就是被卖出去的许可证集合)。如果剩余许可证可以被重新配置到目标区间内,那么该赢家集合就是可行的,该分配方案也是可行。(判断剩下许可证是否可行是一个 N P NP NP问题)
3.延迟分配规则:初始化赢家集合为全部集合 W = N W=N W=N,进入循环每次按照顺序检查当前许可证 i i i被剔除出赢家集合后,剩余许可证是否可行,如果可行就剔除否则继续下一层循环。全部遍历后,返回最后的赢家集合。通过设置赋分函数来贪心决定遍历顺序。延迟分配规则是一大类拥有良好动机属性的逆向拍卖分配规则。
第九章 含支付约束的机制设计
- 本章节中,除了常规的激励和可行性约束外,我们首次考虑含有支付约束的机制设计问题。
- 预算约束
预算约束,也就是说每一位竞拍者都有一个能够支付钱数的上限,在多物品拍卖中常见,预算约束也就是限制了竞拍拍品的个数。加入预算约束的效用模型如下:
v i ( w ) − p i , p i < = B i − ∞ , p i > B i v_i(w)-p_i,p_i<=B_i\\ -\infty,p_i>B_i vi(w)−pi,pi<=Bi−∞,pi>Bi
预算约束的加入使得之前的很多问题需要重新设计拍卖形式。 - 同一价格多单位拍卖
拍卖背景:有 m m m个相同物品,每位竞拍者对于获得的每个物品都有一个私有估值 v i v_i vi,假设竞拍者都想尽可能多的获得拍品,且获得多个拍品的估值相同。每位竞拍者都有一个公开的预算 B i B_i Bi。
定义每位竞拍者在当前拍品价格设定为 p p p时的需求量:
D i ( p ) = m i n { ⌊ B i p ⌋ , m } , p < v i D i ( p ) = 0 , p > v i D_i(p)=min\{\lfloor\frac{B_i}{p}\rfloor,m\},p<v_i\\ D_i(p)=0,p>v_i Di(p)=min{
⌊pBi⌋,m},p<viDi(p)=0,p>vi
我的理解是这里的需求量更多指的是可以承担量,并不是针对竞拍者的真实需求建模,而是针对承担能力建模。估值约束决定了竞拍者是否参与竞拍,而预算约束决定了竞拍者有能力竞拍多少个。
定义价格设定为 p p p下,整个系统的总需求如下:
A ( p ) = ∑ i = 1 n D i ( p ) A − ( p ) = l i m q ↑ p ∑ i = 1 n D i ( p ) , A + ( p ) = l i m q ↓ p ∑ i = 1 n D i ( p ) A(p)=\sum_{i=1}^nD_i(p)\\ A^-(p)=lim_{q\uparrow p}\sum_{i=1}^nD_i(p),A^+(p)=lim_{q\downarrow p}\sum_{i=1}^nD_i(p) A(p)=i=1∑nDi(p)A−(p)=limq↑pi=1∑nDi(p),A+(p)=limq↓pi=1∑nDi(p)
同一价格拍卖规则:
1.选定 p p p使得供应量等于总需求,即 A − ( p ) > = m > = A + ( p ) A^-(p)>=m>=A^+(p) A−(p)>=m>=A+(p)。
2.把 D i ( p ) D_i(p) Di(p)个物品分配给竞拍者 i i i,其中每个物品价格为 p p p。(特殊情况当 v i = p v_i=p vi=p时, D i ( p ) D_i(p) Di(p)设定为满足其他人需求后剩下的量,因为他竞拍成功没收益,数量就无所谓)
同一价格拍卖满足所有竞拍者的预算约束,但该拍卖不是DSIC的,可能存在着需求缩减的问题。竞拍者可能会虚报估值以及预算,以获得个人更高的收益。 - 锁定拍卖
在竞拍者存在公开预算约束时,锁定拍卖是一个DSIC的多单位拍卖。拍卖的关键点在于随着价格的升高,逐个把物品卖出去。不同的物品会议不同的价格在不同的轮次被卖掉。
锁定拍卖需要建模考察剩余需求量:
D i ^ ( p ) = m i n { ⌊ B i ^ p ⌋ , s } , p < v i D i ^ ( p ) = 0 , p > v i \hat{D_i}(p)=min\{\lfloor \frac{\hat{B_i}}{p}\rfloor,s\},p<v_i\\ \hat{D_i}(p)=0,p>v_i Di^(p)=min{
⌊pBi^⌋,s},p<viDi^(p)=0,p>vi

锁定拍卖中不存在需求递减的情况,虚报竞价与预算也不会获得更好的收益。锁定拍卖总会结束,且完全分配 m m m个物品,收取的支付最多是竞拍者的预算。在竞拍者拥有公开的预算约束时,锁定拍卖是DSIC的。 - 不含钱的机制设计
在很多重要的应用中,激励问题很重要,但同时金钱的参与却是不可行甚至是非法的。在不适用金钱的情况下,机制设计者所能施展的空间被束缚了,甚至比含有预算约束时的情况束缚得更紧。
代表性的例子:房屋分配问题。每位智能体都拥有一个房屋,且每位智能体都对所有的房屋有一个全排序作为自己的私人信息。不一定智能体会最喜欢自己的房屋。那么如何重新分配房屋使得每个智能体的情况都变得更好?或者说达成社会福利最大化呢?该问题可以使用交易环算法解决(TTC算法)。

TTC算法是DSIC的。对任何房屋分配问题,由TTC算法得到的分配是唯一的核心配置。(核心配置是指不存在阻塞联盟的分配。阻塞联盟是指某个子集内部的某种分配使得某些成员的情况变糟糕)
第十章 肾脏交换和稳定匹配
- 首先我们来看一下肾脏交换问题。问题的背景如下:一些病人肾脏衰竭急需肾脏移植,一般也只有亲友等关系要好的人才会答应活体移植,我们设定因为感情纽带形成了一对对病人-供体对。但是感情形成的病人-供体对,不一定成功匹配。因此我们考虑,多个病人-供体对之间进行肾脏交换,希望能够最大化匹配个数。肾脏交易的违法的,因此肾脏交换机制同样也是不含钱机制。
- 我们考虑上节中介绍的TTC算法。TTC算法重新把供体分配给病人的这种模式只能提高每个病人成功进行移植的概率。使用TTC算法的唯一缺点是可能会使用很长的环来进行肾脏重分配。假设长度为2的环,就需要同时进行4场手术(如果不同时进行,供体就会担心自己白白贡献出肾脏给别人,自己本来的病人却被放了鸽子),很长的环就需要同时进行多场手术,实现难度很大。除此之外,TTC算法将病人对供体进行全序建模,实际上是不合理的,病人只关系合适与否,而不关心在合适的里面最偏好哪个。
- 应用匹配算法
二值偏好和较短的重分配链促使我们采用图匹配算法。每个病人-供体对作为一个节点,如果两个节点之间肾脏交换都可以匹配,那么两个节点之间存在一条无向边。机制设计的目标是最大化肾脏移植的数目。
成对匹配肾脏交换机制
1.从智能体 i i i收集一个汇报 F i F_i Fi。
2.建立图 G = ( V , E ) G=(V,E) G=(V,E)。点与边的含义上面已介绍。
3.返回图 G G G中的一个最大(基数)匹配。
该机制中还存在一个问题:最大匹配是指某个边集中边的个数最多,并且满足所有边没有相同端点。那么可能最大匹配有多个,对应相同的边数,我们该如何选择呢?一个解决方案是在机制开始前就给所有病人-供体对排出一个优先级,参考的因素比如等待时间、兼容难易程度、病重程度等等。根据以下算法返回唯一的最大匹配。以下算法中假设顶点 { 1 , 2 , . . . , n } \{1,2,…,n\} {
1,2,...,n}按照优先级排序。

肾脏匹配优先级机制是DSIC的。因此不存在虚假的汇报使得机制产生更好的结果。这里虚假的汇报,不可能汇报与自己不匹配的结果,只可能汇报的匹配集合比真实集合更小。
- 医院方的动机因素
病人-供体对肯定是有医院上报给国家或者是中心的,因此出于某些因素的考虑,医院可能选择全部或者局部上报自己的病人-供体对信息。某些情况下,医院全部上报信息可能会让某些医院内部无法实现配对的可以实现医院间的配对。某些情况下,医院隐藏部分信息,可能会让自己的全部病人-供体对得到配对。 - 稳定匹配
机制场景:有三个医学院毕业生要分配给三家不同的医院,每位毕业生针对医院都有自己的偏好顺序,每家医院针对毕业生也有偏好顺序。为了寻找一个完美匹配(匹配集覆盖所有点),并且该完美匹配是稳定的。稳定的含义是匹配中不存在阻塞对。阻塞对的含义是,在某个匹配中并没有将v与w匹配,但相比于各自已经匹配的点,v更喜欢w,w也更喜欢v,他们两个有趋势脱离匹配自行组队。 - 输出稳定匹配的优美算法——延迟接受算法

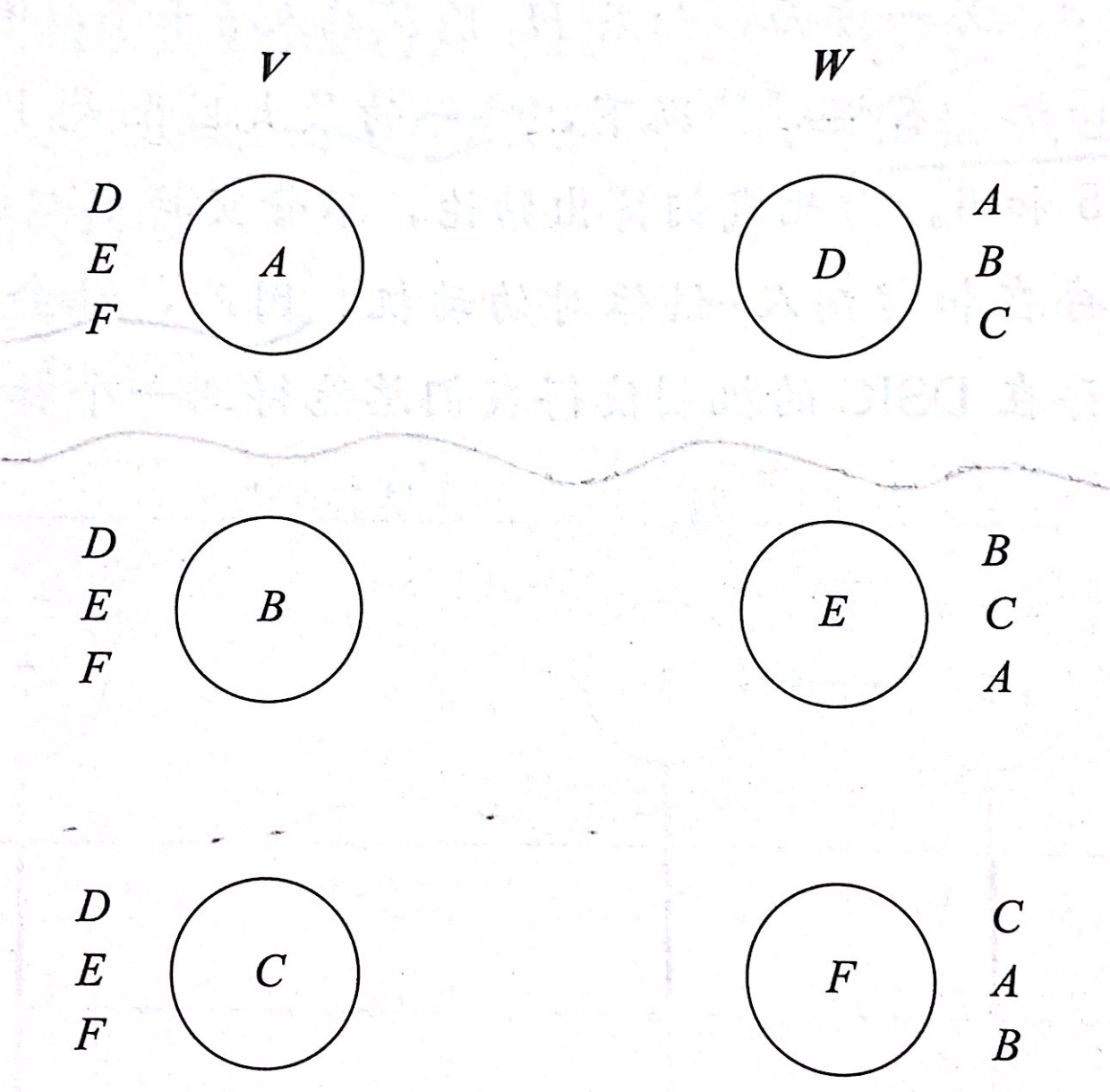
以上图为例解释一下算法的流程。假设我们遍历毕业生的顺序为C、B、A(后续结论表明顺序无关结果)。首先C选择D,D目前空闲接受C。B选择D,D比较B、C后选择B拒绝C。A选择D,D比较A、B后选择A拒绝B。C选择E,E目前空闲接受C。B选择E,E比较B、C后选择B拒绝C。C选择F,F空闲接受C。至此完美匹配达成,算法结束。 - 延迟接受算法的多条性质结论
1.延迟接受算法最多 n 2 n^2 n2轮迭代后得到一个稳定匹配,其中 n n n为任意一方的顶点数目。
2.对任意一组申请人和医院的偏好列表,至少存在一个稳定匹配。
3.延迟接受算法的结果与在每一轮迭代中选择哪一个未匹配的申请人无关。
4.毕业生申请,医院接受或者拒绝的机制中。毕业生如实上报偏好是DSIC的,但医院如实上报偏好不是DSIC的。
—————————第二部分无秩序代价————————-
第十一章 自私路由与无秩序代价
- 之前的十个章节主要介绍机制设计部分,第十一章到第十五章介绍无秩序代价理论,这是关于实际博弈中均衡的近似保证。本章节我们将在自私路由模型下研究无秩序代价(POA)这一指标。
- 我们用布雷斯悖论的内容来引出自私路由模型以及无秩序代价指标
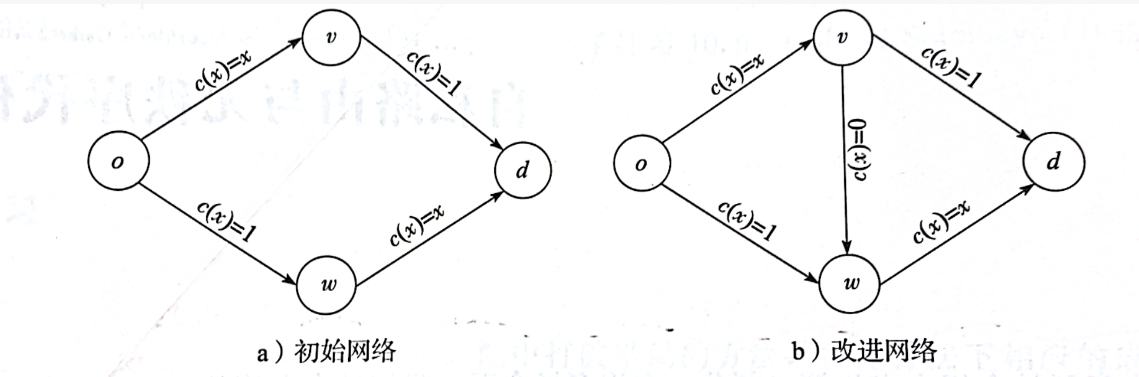
背景介绍:有一个单位的交通流从o到d,初始网络上下两条路代价相同,因此均衡情况下各承载 1 / 2 1/2 1/2的交通流,那么每位司机的通行时间都是 2 / 3 2/3 2/3。假设修建一条瞬移通道从v到w,那么此时有三条路 o → v → d , o → v → w → d , o → w → d o\rightarrow v\rightarrow d,o\rightarrow v \rightarrow w \rightarrow d,o\rightarrow w \rightarrow d o→v→d,o→v→w→d,o→w→d,选择 o → v → w → d o\rightarrow v \rightarrow w \rightarrow d o→v→w→d是占优策略,那么每位司机的通行时间都是 2 2 2。布雷斯悖论就体现在,网络中加入新通道,通行时间不降反升。 正是因为每位司机自私选择路由的缘故,导致局部最优导致的均衡可能偏离全局最优。
无秩序代价(POA)定义为:均衡情况下所用时间与最小的平均时间的比值,即 2 / ( 3 / 2 ) = 4 / 3 2/(3/2)=4/3 2/(3/2)=4/3。也就是说自私导致的均衡结果代价是全局最优的 4 / 3 4/3 4/3倍。 - Pigou示例
Pigou图是一类更加简单的自私路由模型,首先我们来看左图。分析可得,走下面的路径是一个占优策略,即无论其他交通流怎么选择,司机走下面的路径都会是最优的,那么均衡状态下所有司机的通行时间都是1。我们假设有 r r r的交通流选择下面, 1 − r 1-r 1−r的交通流选择上面,那么总代价为 r 2 − r + 1 r^2-r+1 r2−r+1,因此当 r = 1 / 2 r=1/2 r=1/2时得到最小代价。也就是说 如果存在一个利他的分流员,各自分配 1 / 2 1/2 1/2的交通流到上下两路,总体代价就会降低到 3 / 4 3/4 3/4。POA为 1 / ( 3 / 4 ) = 4 / 3 1/(3/4)=4/3 1/(3/4)=4/3。
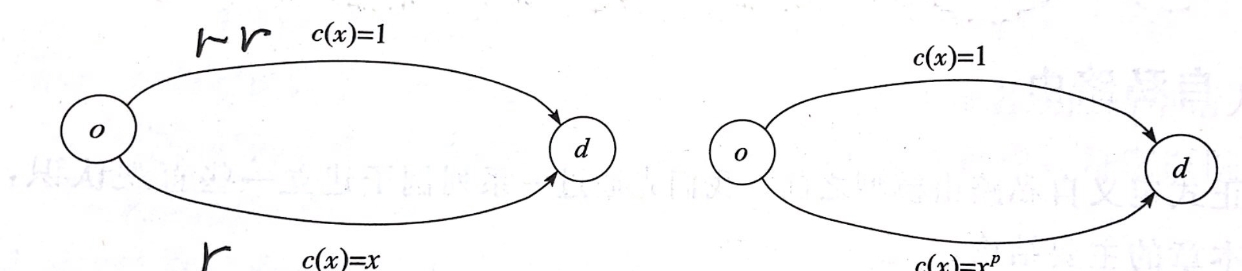
接下来我们分析右图,唯一区别在于下方路径代价变成了交通流的高次函数。下方路径仍然是每位司机占优策略的选择。假设有 1 − ϵ 1-\epsilon 1−ϵ的交通流选择下方路径, ϵ \epsilon ϵ选择上方路径,当 p → ∞ , ϵ → 0 p\rightarrow \infty,\epsilon \rightarrow 0 p→∞,ϵ→0时,此时代价近似为0。此时POA近似无界。 - 分析得出结论
自私路由的POA可大可小,当POA接近于1时表明自私抉择导致的均衡接近于全局最优。代价函数非线性的情况下,POA可能会比较大,代价函数为线性函数的时候,POA接近于1。因此我们推测:代价函数的高非线性是实现较小POA的唯一障碍。即对于任意复杂的路由网络,如果其代价函数的非线性不高,则它的POA都接近于1。
自私路由的严格POA界
在所有代价函数集合为 C C C的网络中,和Pigou示例类似的网络的POA最大。
该定理的存在,可以将计算最差POA的问题归约成很简单的问题。我们想要找出POA最大的网络,只需要在类似Pigou示例的网络中进行搜索就可以了。可以理解为一个网络的POA值由两大因素决定,一是代价函数集合 C C C,另一个是网络结构。而类似Pigou示例的网络结构下的POA值是相同代价函数集合中的最大值,也就是上界。
类似Pigou网络的组成成分:
1.两个顶点 o 、 p o、p o、p。
2.从起点到终点的两条边,一条边在上面,一条边在下面。
3.非负的交通流率 r r r。
4.下面那条边的代价函数 c ( x ) c(x) c(x)。
5.上面那条边的代价函数处处相等且为 c ( r ) c(r) c(r)。
类似Pigou网络中最少时间代价就可以写成:
i n f 0 < = x < = r { x ⋅ c ( x ) + ( r − x ) ⋅ c ( r ) } inf_{0<=x<=r}\{x\cdot c(x)+(r-x)\cdot c(r)\} inf0<=x<=r{
x⋅c(x)+(r−x)⋅c(r)}
类似Pigou网络中的POA为:
s u p x > = 0 { r ⋅ c ( r ) x ⋅ c ( x ) + ( r − x ) ⋅ c ( r ) } sup_{x>=0}\{\frac{r\cdot c(r)}{x\cdot c(x)+(r-x)\cdot c(r)}\} supx>=0{
x⋅c(x)+(r−x)⋅c(r)r⋅c(r)}
代价函数集合为 C C C时的Pigou界为:
α ( C ) = s u p c ∈ C s u p r > = 0 s u p x > = 0 { r ⋅ c ( r ) x ⋅ c ( x ) + ( r − x ) ⋅ c ( r ) } \alpha(C)=sup_{c\in C}sup_{r>=0}sup_{x>=0}\{\frac{r\cdot c(r)}{x\cdot c(x)+(r-x)\cdot c(r)}\} α(C)=supc∈Csupr>=0supx>=0{
x⋅c(x)+(r−x)⋅c(r)r⋅c(r)}
自私路由的严格POA界
对于所有代价函数的集合 C C C及代价函数属于 C C C的自私路由网络,其POA至多是 α ( C ) \alpha(C) α(C)。
- 分流与均衡分流:
分流表示交通流是如何被分配到不同的起点-终点路径上的,它是一个非负的向量 { f p } p ∈ P 且 ∑ p ∈ P f p = r \{f_p\}_{p\in P}且\sum_{p\in P}f_p=r {
fp}p∈P且∑p∈Pfp=r。每一个分流由多个0-1数值组成,每个数值代表了某条可能路径的分配概率,并且所有数值的和为1(以1作为交通量)。
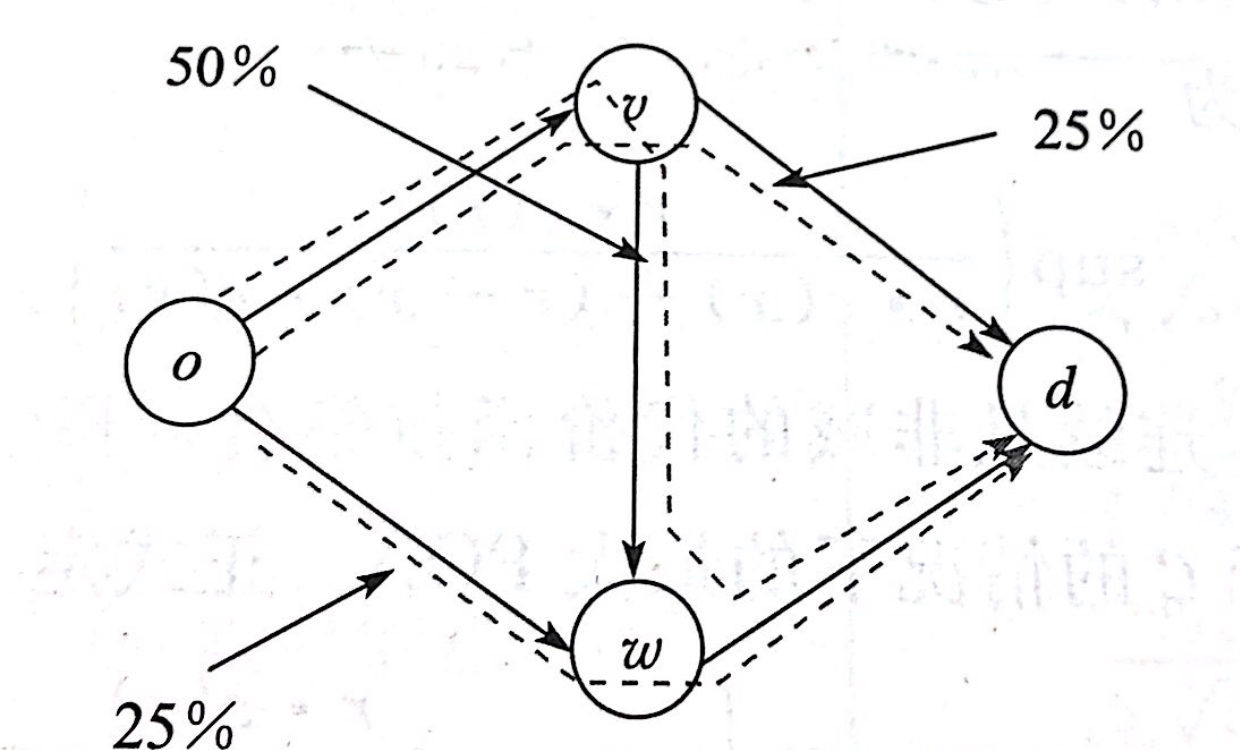
比如上图所示的一个分流 f f f就是, o → v → w → d o\rightarrow v\rightarrow w\rightarrow d o→v→w→d的概率为 50 % 50\% 50%, o → v → d o\rightarrow v \rightarrow d o→v→d与 o → w → d o\rightarrow w \rightarrow d o→w→d的概率都是 25 % 25\% 25%。
对于边 e ∈ E e\in E e∈E和分流 f f f,我们用 f e = ∑ p ∈ P : e ∈ p f p f_e=\sum_{p\in P:e\in p}f_p fe=∑p∈P:e∈pfp表示选择的路径中包含边 e e e的交通流量。比如上图中 f ( o , v ) = f ( w , d ) = 3 / 4 f_{(o,v)}=f_{(w,d)}=3/4 f(o,v)=f(w,d)=3/4。
均衡分流的含义是:在均衡分流下,交通流只会选择哪些最短的起点-终点路径。也就是说如果存在多条最短路径,那么只有最短路径上会分配有交通流,不是最短路径上一定不会有交通流。
第十二章 超额配置和单元自私路由
- 案例分析:网络超额配置
自私路由的研究为各种网络的配置提供了指导,包括运输、通信和电力网络。通信网络有一个很大的优势:为通信网络增加额外的配置成本比较低,因此通信网络常用的策略就是提供超过需求的容量(即超额配置)。网络超额配置的好处,一是可以适应未来需求的增长,二是超额配置可以优化网络性能。
我们设定边 e e e在流量 x x x下的代价(延迟)为:
c e ( x ) = 1 u e − x , x < u e c e ( x ) = + ∞ , x > = u e c_e(x)=\frac{1}{u_e-x},x<u_e\\ c_e(x)=+\infty,x>=u_e ce(x)=ue−x1,x<uece(x)=+∞,x>=ue
我们设定剩余容量 β ∈ ( 0 , 1 ) \beta \in (0,1) β∈(0,1),如果说对于所有边都有 f e < = ( 1 − β ) u e f_e<=(1-\beta)u_e fe<=(1−β)ue,其中 f e f_e fe为均衡分流下边 e e e的分流(本身是概率,由于总流量设置为1,概率与流量重合),也就是说在均衡分流下,网络中边的最大利用率最多是 ( 1 − β ) ⋅ 100 % (1-\beta)\cdot 100\% (1−β)⋅100%,我们称这样的网络是 β \beta β-超额配置的。由类Pigou网络计算最差POA得:
1 2 ( 1 + 1 β ) \frac{1}{2}(1+\sqrt{\frac{1}{\beta}}) 21(1+β1)
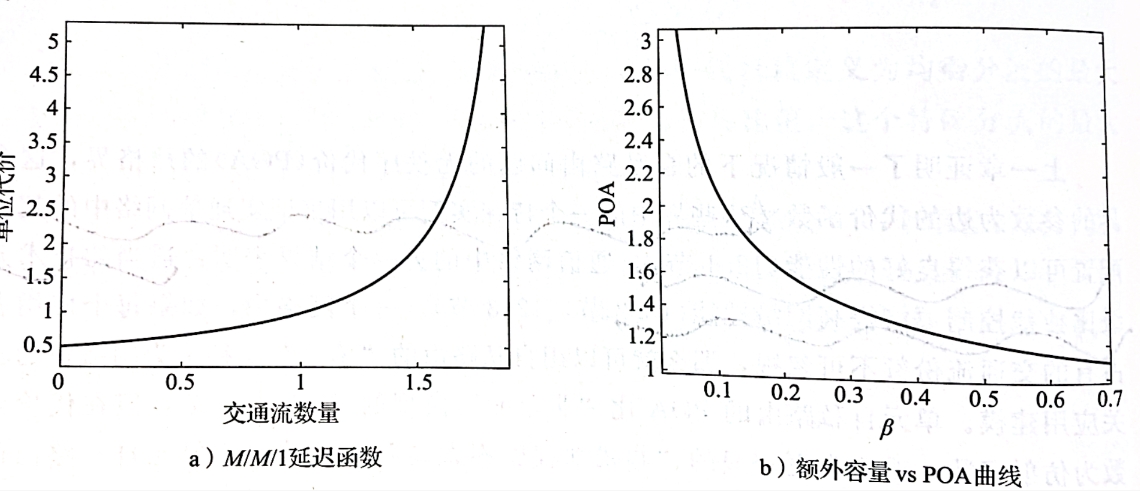
上图中左图为代价函数曲线,右图为POA相对于额外容量参数 β \beta β的变化曲线。首先分析左图,假设容量为2,交通流一般处于 ( 0 , 1 ) (0,1) (0,1)之间,因此这是一个 0.5 0.5 0.5-超额配置的网络。当交通流离容量较远时,代价很低;当接近于容量时,代价飙升。然后分析右图,剩余容量为0时POA很大,但只要超额配置 0.1 0.1 0.1,POA就可以降低到2.1的可接受范围。因此少量的超额配置就可以使自私路由趋近最优,这与实际情况相符。 - 资源增广界
在所有自私路由网络中,若 r > 0 r>0 r>0,则交通流率为 r r r的均衡分流的代价至多等于交通流量为 2 r 2r 2r的最优分流的代价。
- 单元自私路由
之前我们研究的都是自私路由的非单元模型,也就是智能体所占交通流的份额极小的情况,适合于建模高速公路上的汽车、通信网络中的小型用户等等。本节我们将介绍单元自私路由网络,当每个智能体都能控制交通流中相当大的份额时,单元自私路由更适用。
单元自私路由中,每位智能体都有自己的起点 o i o_i oi和终点 d i d_i di,并且都需要从起点到终点传输 1 1 1个单位的交通流。均衡分流的含义是,在该状态下智能体 i i i无法通过只改变自己的分流来减少自身代价。
我们来分析一下Pigou示例的单元自私路由变种:
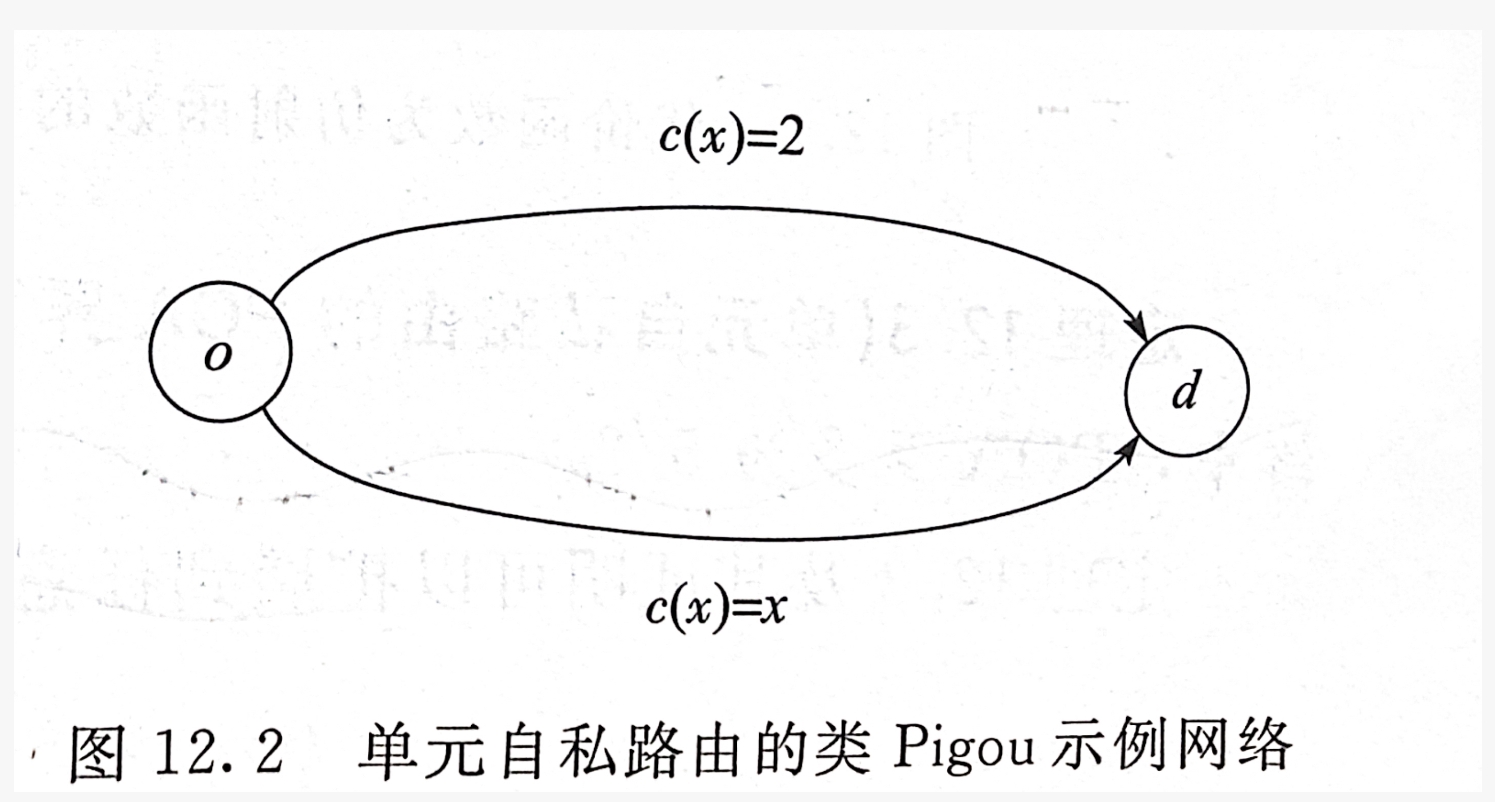
假设有两个智能体各自携带1单位交通流需要从 o o o到 d d d。最优解为上下两路各有一个智能体携带1交通流,这样总体代价为 1 + 2 = 3 1+2=3 1+2=3,同时这也是一个均衡分流,因为两个智能体单独改变自身决策都无法减小代价。该网络还有第二个均衡分流,两个智能体都选择下面的边,那么总代价为 2 + 2 = 4 2+2=4 2+2=4。可以分析得到单元自私路由和非单元自私路由的一个区别:单元自私路由的均衡分流总代价可能不同,但非单元自私路由的均衡分流总代价一定相同。
单元自私路由模型中的POA定义如下:
P O A = 最 坏 情 况 均 衡 分 流 代 价 / 最 优 分 流 代 价 POA=最坏情况均衡分流代价/最优分流代价 POA=最坏情况均衡分流代价/最优分流代价
单元自私路由与非单元自私路由的另一个区别:单元自私路由的POA更大。
单元自私路由的POA界
在代价函数为仿射函数的单元自私路由网络中,POA至多为5/2。
第十三章 均衡:定义、示例和存在性
- 均衡概念的层级结构:
均衡概念共分为四层,按概念从小到大依次是:纯策略纳什均衡 < < <混合策略纳什均衡 < < <相关均衡 < < <粗糙相关均衡。
纯策略纳什均衡(PNE):未必存在。
混合策略纳什均衡(MNE):一定存在但很难计算。
相关均衡(CE):容易计算。
粗糙相关均衡(CCE):非常容易计算。 - 代价最小化博弈与收益最大化博弈
一定程度上,代价最小化博弈与收益最大化博弈是等价的。二者适用于不同的情况背景。由于本质相同,我们以代价最小化博弈为例来展示形式化定义。
1.有限的 k k k个智能体。
2.对于每个智能体 i i i,都存在一个策略集 S i S_i Si。
3.对于每个智能体 i i i,都存在一个非负的代价函数 C i ( s ) C_i(s) Ci(s),其中 s ∈ S 1 × S 2 × . . . S k s\in S_1\times S_2\times … S_k s∈S1×S2×...Sk表示策略组合或者博弈局势。 - 纯策略纳什均衡(PNE)
若对于任意一个智能体 i ∈ { 1 , 2 , . . . , k } i\in\{1,2,…,k\} i∈{
1,2,...,k}和其单方面策略改变 s i ′ ∈ S i s_i’\in S_i si′∈Si,都有:
C i ( s ) < = C i ( s i ′ , s − i ) C_i(s)<=C_i(s_i’,s_{-i}) Ci(s)<=Ci(si′,s−i)
则称这样的策略组合 s s s是代价最小化博弈的一个纯策略纳什均衡。
式子中 s , s − i s,s_{-i} s,s−i是个策略组合, s i s_i si是单个策略。由于是代价最小化博弈,更优的情况是代价减小。单独改变 s i → s i ′ s_i\rightarrow s_i’ si→si′,无法减小代价。也就是说纯策略均衡状态下,每个智能体策略 s i s_i si都是针对 s − i s_{-i} s−i的最优响应。 - 混合策略纳什均衡(MNE)
若对于任意一个智能体 i ∈ { 1 , 2 , . . . , k } i\in\{1,2,…,k\} i∈{
1,2,...,k}和其单方面策略改变 s i ′ ∈ S i s_i’\in S_i si′∈Si,都有:
E s ∼ σ [ C i ( s ) ] < = E s ∼ σ [ C i ( s i ′ , s − i ) ] E_{s\sim \sigma}[C_i(s)]<=E_{s\sim \sigma}[C_i(s_i’,s_{-i})] Es∼σ[Ci(s)]<=Es∼σ[Ci(si′,s−i)]
其中 σ \sigma σ表示联合概率分布 σ 1 × . . . × σ k \sigma_1\times…\times \sigma_k σ1×...×σk(联合概率分布可用乘积表示,说明这里变量之间相互独立),我们就称策略集 S 1 × . . . × S k S_1\times … \times S_k S1×...×Sk上的分布 σ 1 × . . . × σ k \sigma_1 \times …\times \sigma_k σ1×...×σk是代价最小化博弈的一个混合策略纳什均衡。
混合策略中,每位代理者都针对自己的策略集 S i S_i Si有一个分布 σ i \sigma_i σi,因此我们用针对分布求代价期望的方式来衡量分布的好坏。
混合策略纳什均衡有如下性质:
1.每个PNE都是一个MNE。
2.每个代价最小化博弈都至少有一个MNE。
3.代价最小化博弈中MNE的POA定义为:最坏MNE的期望目标函数值/最好局势的目标函数值。
4.即便只有两个代理者,计算MNE也是一个困难的问题,因此研究MNE的POA界未必是有意义的。 - 相关均衡(CE)
若对于任意一个智能体 i ∈ { 1 , 2 , . . . , k } i\in\{1,2,…,k\} i∈{
1,2,...,k}和其单方面策略改变 s i ′ ∈ S i s_i’\in S_i si′∈Si,都有:
E s ∼ σ [ C i ( s ) ∣ s i ] < = E s ∼ σ [ C i ( s i ′ , s − i ) ∣ s i ] E_{s\sim \sigma}[C_i(s)|s_i]<=E_{s\sim \sigma}[C_i(s_i’,s_{-i})|s_i] Es∼σ[Ci(s)∣si]<=Es∼σ[Ci(si′,s−i)∣si]
则称局势集合 S 1 × . . . × S k S_1\times …\times S_k S1×...×Sk上的分布 σ \sigma σ是代价最小化博弈的一个相关均衡。
注意这里的分布 σ \sigma σ不一定是独立的,也就是说变量之间是相关的(叫相关均衡的原因)。MNE是CE的特殊一种,MNE对应分布 σ \sigma σ彼此独立的CE。因为相互独立,所以 E s ∼ σ [ C i ( s ) ∣ s i ] = E s ∼ σ [ C i ( s ) ] E_{s\sim \sigma}[C_i(s)|s_i]=E_{s\sim \sigma}[C_i(s)] Es∼σ[Ci(s)∣si]=Es∼σ[Ci(s)],从而有CE定义式推得MNE定义式。
解释相关均衡需要引入一个信任的第三方。策略组合的分布 σ \sigma σ公共已知。第三方会根据 σ \sigma σ抽取一个策略组合样本 s s s,然后为每一位代理者推荐响应的策略 s i s_i si,代理者可以接受也可以不接受。代理者在做决策之前,已知策略组合分布 σ \sigma σ以及自己被建议的策略 s i s_i si,同时可以推理得到一个针对其他代理者的后验分布 s − i s_{-i} s−i。相关均衡的定义表明,在其他代理者均采纳第三方建议的基础上,代理者 i i i采纳建议可以获得最小的代价。
CE不像MNE,它不是计算困难的。甚至还存在分布式的算法能引导博弈朝着CE收敛。因此我们可以针对CE研究POA界,这就是一个有意义的均衡的性能保障。 - 粗糙相关均衡
若对于任意一个智能体 i ∈ { 1 , 2 , . . . , k } i\in\{1,2,…,k\} i∈{
1,2,...,k}和其单方面策略改变 s i ′ ∈ S i s_i’\in S_i si′∈Si,都有:
E s ∼ σ [ C i ( s ) ] < = E s ∼ σ [ C i ( s i ′ , s − i ) ] E_{s\sim \sigma}[C_i(s)]<=E_{s\sim \sigma}[C_i(s_i’,s_{-i})] Es∼σ[Ci(s)]<=Es∼σ[Ci(si′,s−i)]
则称局势集合 S 1 × . . . × S k S_1\times …\times S_k S1×...×Sk上的分布 σ \sigma σ是代价最小化博弈上的一个粗糙相关均衡。
粗糙相关均衡同样是不具有分布间相互独立的性质,也就是分布之间具有相关性。相对于CE,CCE粗糙在,都不用条件概率来刻画代价函数了,我们知道具有相关性,但直接忽略相关性。CCE只防止无条件的单方面策略改变。某些分布式的学习算法能引导博弈快速收敛到CCE集合上去。 - 势博弈是具有势函数的博弈,在势博弈中,某个智能体单方面改变策略导致的势函数值的变化,等于这个智能体自身的代价变化。所有势博弈都至少有一个PNE。所有单元自私路由博弈都是势博弈。
势函数有如下性质:当某个智能体偏离均衡时,势函数值得变化等于偏离这自身的代价变化。即对每个策略组合 s s s,智能体 i i i及其单方面策略改变 s i ′ ∈ S i s_i’\in S_i si′∈Si都有:
Φ ( s i ′ , s − i ) − Φ ( s ) = C i ( s i ′ , s − i ) − C i ( s ) \Phi(s_i’,s_{-i})-\Phi(s)=C_i(s_i’,s_{-i})-C_i(s) Φ(si′,s−i)−Φ(s)=Ci(si′,s−i)−Ci(s)
也就是说势博弈的智能体都在无意间共同优化 Φ \Phi Φ。
第十四章 平滑博弈的鲁棒无秩序代价界
- 将均衡集扩大的好处是能够增加可信性和计算可行性,缺点是无秩序界只会随着均衡集的扩大而变差。本章介绍平滑博弈,在平滑博弈中PNE的POA界可以在不变差的情况下,扩展到一些宽松的均衡概念下,包括粗糙相关均衡下。
- POA界四阶段式处理方法
四阶段式方法是证明PNE的POA界的常用方法,我们将其应用在单元自私路由的POA界证明上,来初步接触一下该方法。典型的POA证明分为以下四步骤:
1.对于每一个智能体都调用一次均衡假设,假设智能体使用最优局势中的策略偏离均衡,从而找出所有智能体在均衡下的代价的界。
2.将得到的不等式加和得到总的均衡代价。
3.将纠缠的界和均衡代价及最优代价联系起来。
4.解POA。
单元自私路由的POA界
在代价函数为仿射函数的单元自私路由网络中,POA至多为5/2。
一个均衡分流对应一个POA,而单元自私路由多个均衡分流的代价不同,因此对应多个POA值。因此才有了定理中POA至多为5/2的结论(针对于所有均衡分流)。
该定理证明过程如下:
我们的目标在于找出所有均衡分流的POA上界,最优分流代价固定的前提下,也就是找到均衡分流的代价上界。令 f ∗ f^* f∗表示最优分流, f e f_e fe和 f e ∗ f_e^* fe∗表示分流 f f f和 f ∗ f^* f∗中使用边 e e e的智能体数目(一个智能体拥有1个单位的交通流,因此每条边上的交通流数目都是整数)。仿射函数 c e ( x ) = a e x + b e c_e(x)=a_ex+b_e ce(x)=aex+be,其中 a e , b e > = 0 a_e,b_e>=0 ae,be>=0。
证明第一步:
假设 f f f是均衡分流。智能体 i i i在 f f f中选择路径 p i p_i pi,在 f ∗ f^* f∗中选择路径 p i ∗ p_i^* pi∗,假设智能体 i i i选择路径由 p i p_i pi偏移到 p i ∗ p_i^* pi∗。我们可以得到如下式子:
∑ e ∈ p i c e ( f e ) < = ∑ e ∈ p i ∗ ∩ p i c e ( f e ) + ∑ e ∈ p i ∗ \ p i c e ( f e + 1 ) \sum_{e\in p_i}c_e(f_e)<=\sum_{e\in p_i^* \cap p_i}c_e(f_e)+\sum_{e\in p_i^* \backslash p_i}c_e(f_e+1) e∈pi∑ce(fe)<=e∈pi∗∩pi∑ce(fe)+e∈pi∗\pi∑ce(fe+1)
不等号右侧需要解释一下。 e ∈ p i ∗ ∩ p i e\in p_i^* \cap p_i e∈pi∗∩pi是指 p i p_i pi与 p i ∗ p_i^* pi∗共同的部分流量不变。 e ∈ p i ∗ \ p i e\in p_i^* \backslash p_i e∈pi∗\pi是指 p i ∗ p_i^* pi∗独有的部分因为策略便宜导致流量+1。我们利用均衡分流的假设得到了每个智能体均衡代价的上界。
证明第二步:
将所有智能体个人的均衡代价上界相加,得到总体均衡上界为:
∑ i = 1 k ∑ e ∈ p i c e ( f e ) < = ∑ i = 1 k ( ∑ e ∈ p i ∗ ∩ p i c e ( f e ) + ∑ e ∈ p i ∗ \ p i c e ( f e + 1 ) ) \sum_{i=1}^{k}\sum_{e\in p_i}c_e(f_e)<=\sum_{i=1}^k(\sum_{e\in p_i^* \cap p_i}c_e(f_e)+\sum_{e\in p_i^* \backslash p_i}c_e(f_e+1)) i=1∑ke∈pi∑ce(fe)<=i=1∑k(e∈pi∗∩pi∑ce(fe)+e∈pi∗\pi∑ce(fe+1))
由于代价函数是非减的,将 c e ( f e ) c_e(f_e) ce(fe)放缩到 c e ( f e + 1 ) c_e(f_e+1) ce(fe+1)得到:
∑ i = 1 k ∑ e ∈ p i c e ( f e ) < = ∑ i = 1 k ∑ e ∈ p i ∗ c e ( f e + 1 ) \sum_{i=1}^{k}\sum_{e\in p_i}c_e(f_e)<=\sum_{i=1}^k\sum_{e\in p_i^*}c_e(f_e+1) i=1∑ke∈pi∑ce(fe)<=i=1∑ke∈pi∗∑ce(fe+1)
针对于 ∑ i = 1 k \sum_{i=1}^k ∑i=1k其实就是统计所有代理者的路径中经过边 e e e的数目,这个数目其实是 f e ∗ f_e^* fe∗
∑ i = 1 k ∑ e ∈ p i c e ( f e ) < = ∑ e ∈ E f e ⋅ c e ( f e + 1 ) \sum_{i=1}^{k}\sum_{e\in p_i}c_e(f_e)<=\sum_{e\in E}f_e\cdot c_e(f_e+1) i=1∑ke∈pi∑ce(fe)<=e∈E∑fe⋅ce(fe+1)
最后代入仿射函数的具体形式:
∑ i = 1 k ∑ e ∈ p i c e ( f e ) < = ∑ e ∈ E [ a e f e ∗ ( f e + 1 ) + b e f e ∗ ] \sum_{i=1}^{k}\sum_{e\in p_i}c_e(f_e)<=\sum_{e\in E}[a_ef_e^*(f_e+1)+b_ef_e^*] i=1∑ke∈pi∑ce(fe)<=e∈E∑[aefe∗(fe+1)+befe∗]
证明第三步:
我们利用如下不等式:
对于所有的 y , z ∈ { 0 , 1 , 2 , 3 , . . . } y,z\in \{0,1,2,3,…\} y,z∈{
0,1,2,3,...}有: y ( z + 1 ) < = 5 3 y 2 + 1 3 z 2 y(z+1)<=\frac{5}{3}y^2+\frac{1}{3}z^2 y(z+1)<=35y2+31z2
我们令 y = f e ∗ , z = f e y=f_e^*,z=f_e y=fe∗,z=fe得到:
C ( f ) < = ∑ e ∈ E [ a e ( 5 3 ( f e ∗ ) 2 + 1 3 f e 2 ) + b e f e ∗ ] C(f)<=\sum_{e\in E}[a_e(\frac{5}{3}(f_e^*)^2+\frac{1}{3}f_e^2)+b_ef_e^*] C(f)<=e∈E∑[ae(35(fe∗)2+31fe2)+befe∗]
将 b e f e ∗ b_ef_e^* befe∗放缩到 5 3 b e f e ∗ \frac{5}{3}b_ef_e^* 35befe∗得:
C ( f ) < = 5 3 [ ∑ e ∈ E f e ∗ ( a e f e ∗ + b e ) ] + 1 3 ∑ e ∈ E a e f e 2 C ( f ) < = 5 3 [ ∑ e ∈ E f e ∗ c e ( f e ∗ ) ] + 1 3 ∑ e ∈ E a e f e 2 C ( f ) < = 5 3 ∑ i = 1 k ∑ e ∈ p i ∗ c e ( f e ∗ ) + 1 3 ∑ i = 1 k ∑ e ∈ p i c e ( f e ) C ( f ) < = 5 3 C ( f ∗ ) + 1 3 C ( f ) C(f)<=\frac{5}{3}[\sum_{e\in E}f_e^*(a_ef_e^*+b_e)]+\frac{1}{3}\sum_{e\in E}a_ef_e^2\\ C(f)<=\frac{5}{3}[\sum_{e\in E}f_e^*c_e(f_e^*)]+\frac{1}{3}\sum_{e\in E}a_ef_e^2\\ C(f)<=\frac{5}{3}\sum_{i=1}^k\sum_{e \in p_i^*}c_e(f_e^*)+\frac{1}{3}\sum_{i=1}^k\sum_{e \in p_i}c_e(f_e)\\ C(f)<=\frac{5}{3}C(f^*)+\frac{1}{3}C(f) C(f)<=35[e∈E∑fe∗(aefe∗+be)]+31e∈E∑aefe2C(f)<=35[e∈E∑fe∗ce(fe∗)]+31e∈E∑aefe2C(f)<=35i=1∑ke∈pi∗∑ce(fe∗)+31i=1∑ke∈pi∑ce(fe)C(f)<=35C(f∗)+31C(f)
证明第四步:
解得:
C ( f ) < = 5 3 ⋅ 3 2 C ( f ∗ ) = 5 2 ⋅ C ( f ∗ ) C(f)<=\frac{5}{3}\cdot \frac{3}{2}C(f^*)=\frac{5}{2}\cdot C(f^*) C(f)<=35⋅23C(f∗)=25⋅C(f∗)
- 选址博弈
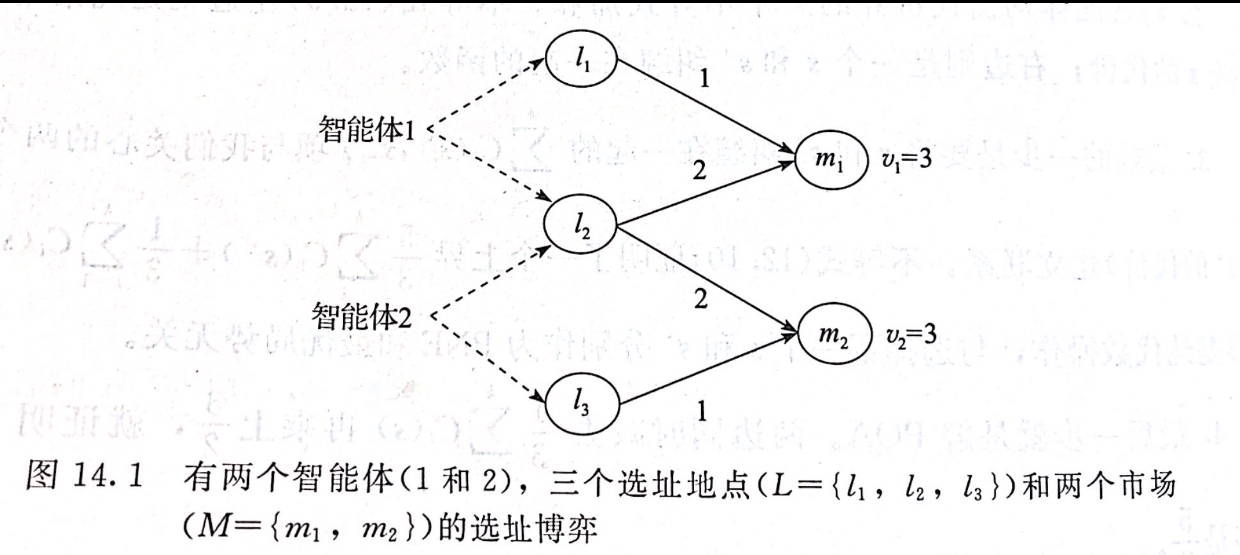
我们用上图所示得例子来说明选址博弈的模型。模型共分为三部分:智能体集合、地点集合、市场集合。大体思路是,智能体选择唯一的地点生成服务,市场选择唯一的地点消费服务,市场针对服务有自己的出价极限,地点与市场之间也有不同的代价。智能体选择地点服务市场,获得市场的报酬,支付地点与市场之间的代价。
如上图所示,智能体包括智能体1、2;地点 L = { l 1 , l 2 , l 3 } L=\{l_1,l_2,l_3\} L={
l1,l2,l3},其中 L 1 = { l 1 , l 2 } , L 2 = { l 2 , l 3 } L_1=\{l_1,l_2\},L_2=\{l_2,l_3\} L1={
l1,l2},L2={
l2,l3};市场 M = { m 1 , m 2 } M=\{m_1,m_2\} M={
m1,m2},各自出价极限为 v 1 = 3 , v 2 = 3 v_1=3,v_2=3 v1=3,v2=3。地点与市场之间的代价(可理解为距离) c 11 = c 32 = 1 , c 12 = c 31 = ∞ , c 21 = c 22 = 2 c_{11}=c_{32}=1,c_{12}=c_{31}=\infty,c_{21}=c_{22}=2 c11=c32=1,c12=c31=∞,c21=c22=2。
假设智能体1、2分别选择 l 1 , l 3 l_1,l_3 l1,l3,那么智能体1、2分别是市场1、2的垄断者,可以最大化要价。因此两个智能体要价均为3,收益都为 3 − 1 = 2 3-1=2 3−1=2。
假设智能体1选择 l 2 l_2 l2,智能体2选择 l 3 l_3 l3。那么智能体1仍然是 m 1 m_1 m1的垄断者,要价为3,收益为 3 − 2 = 1 3-2=1 3−2=1。市场 m 2 m_2 m2需要在 l 2 , l 3 l_2,l_3 l2,l3之间选择,每个智能体的要价都至少大于代价才能获利,因此智能体1针对 m 2 m_2 m2要价一定大于2,智能体2想要赢下市场的话需要要价2,这样收益为 2 − 1 = 1 2-1=1 2−1=1。
我们定义选址博弈的一个策略组合 s s s,其中 T T T为选中的地点集,则智能体 i i i从市场 j ∈ M j\in M j∈M获得的收益为:
π i j ( s ) = 0 , 如 果 c i j > = v j 或 者 l 不 是 T 中 离 j 最 近 的 选 址 地 点 π i j ( s ) = d j ( s ) − c i j , 其 他 情 况 \pi_{ij}(s)=0,如果c_{ij}>=v_j或者l不是T中离j最近的选址地点\\ \pi_{ij}(s)=d_j(s)-c_{ij},其他情况 πij(s)=0,如果cij>=vj或者l不是T中离j最近的选址地点πij(s)=dj(s)−cij,其他情况
d j ( s ) d_{j}(s) dj(s)是某个策略组合下,智能体 i i i针对市场 j j j的最高要价。选址博弈的目标函数是最大化社会福利,其定义为:
W ( s ) = ∑ j ∈ M ( v j − d j ( s ) ) W(s)=\sum_{j\in M}(v_j-d_j(s)) W(s)=j∈M∑(vj−dj(s))
选址博弈的POA界
任意选址博弈的POA至少是1/2,在最坏情况下POA的界为1/2。
选址博弈的特殊性质以及POA界定理证明略。
- 平滑博弈
由于该部分难度较大,现只写出简单结论,有待进一步理解。
由平滑性质得到的POA界能扩展到所有粗糙相关均衡。
由平滑性质得到的POA界能扩展到所有近似均衡,且这个界随着近似参数温和地退化。
第十五章 最好情况和强纳什均衡
- 网络代价分摊博弈
我们来介绍一种与自私路由博弈模型很类似的模型——网络代价分摊博弈。但该模型却有着正外部性,也就是说代理者的加入为其他代理者带来了好处。
网络代价分摊博弈同样产生于图 G = ( V , E ) G=(V,E) G=(V,E)上,边可以是无向边或者是有向边,每条边 e ∈ E e\in E e∈E都有一个固定的代价 γ e > = 0 \gamma_e>=0 γe>=0。共有 k k k个智能体,每个智能体 i i i都有一个起点 o i o_i oi一个终点 d i d_i di, i i i的策略集为图中所有 o i − d i o_i-d_i oi−di的路径。博弈的策略组合是每位代理者所选择的路径集合。
我们把 γ e \gamma_e γe看作构建边 e e e的代价,也就是说,这个代价与使用该边的智能体数目无关,但是由使用该边的智能体共同分担该代价(比如平均分摊)。因此智能体 i i i在策略组合 P P P下的代价为:
C i ( P ) = ∑ e ∈ p i γ e f e C_i(P)=\sum_{e\in p_i}\frac{\gamma_e}{f_e} Ci(P)=e∈pi∑feγe
总体代价,也就是说最小化的目标函数为:
c o s t ( P ) = ∑ e ∈ E : f e > = 1 γ e = ∑ i = 1 k C i ( P ) cost(P)=\sum_{e\in E:f_e>=1}\gamma_e=\sum_{i=1}^kC_i(P) cost(P)=e∈E:fe>=1∑γe=i=1∑kCi(P)
这里也就解释了为什么该博弈是正外部性的,每条边的代价是固定的,但是分摊的人越多,对于每位代理者来说需要支付的代价就越少。(但好像总代价是不变的?) - 网络代价分摊博弈的两个示例
第一个示例的主题是:VHS 还是 Betamax?
有 k k k个智能体,共享一个源点和终点。可以将这个例子看作是两个相互竞争的产品技术中做选择。例如上世纪80年代中,有两种新兴技术用于电影租赁,VHS以及Betamax。VHS出现较早,较早占据了大部分的市场份额,设定消费者在选择时会与大多数其他人选择一致,因此虽然Betamax更先进代价更小但无法挽回市场份额从而惨遭淘汰。
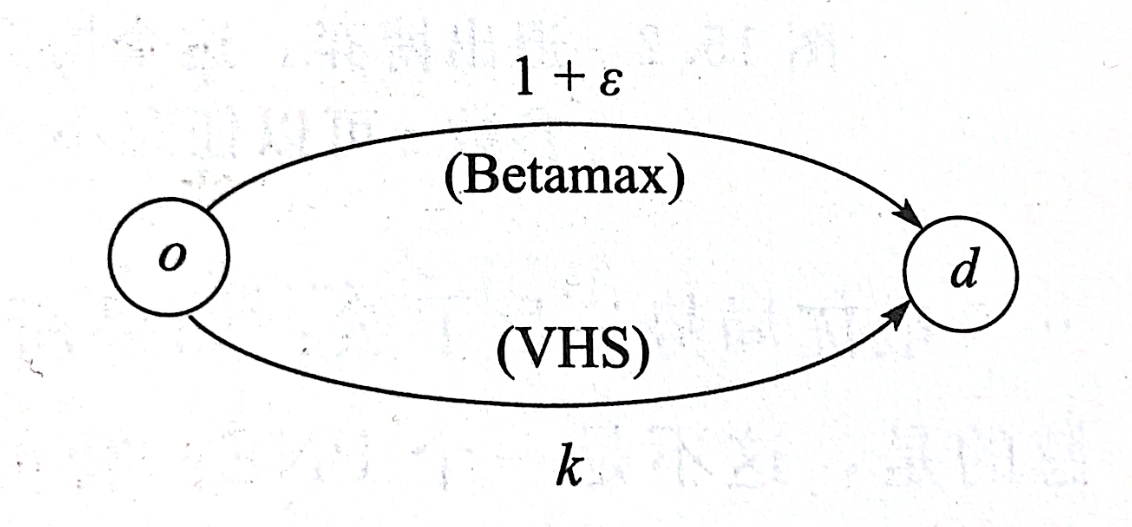
该博弈中存在两个PNE,分别是全部人选择上面那条边以及全部人选择下面那条边。但POA却相差巨大,由于VHS较早占据市场,不外加干预的话更有可能形成第二种PNE,其POA接近于k。不合理均衡使得该博弈存在低效率的问题。
第二个示例的主题是:退出博弈
此博弈中每位代理者都有一个自己的起点 o i o_i oi,共享同一终点。智能体可以选择一起来到集合点 v v v,然后一起来到终点。当然智能体也可以选择退出该博弈,自行前往终点。
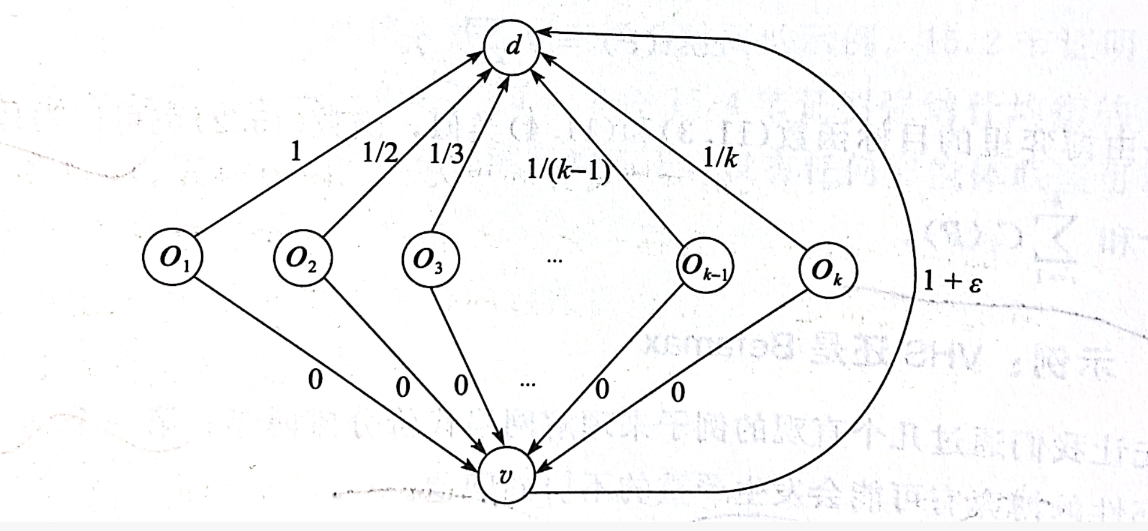
分析可得,所有智能体选择退出是一个PNE,并且这个唯一的PNE的代价为 ∑ i = 1 k 1 i \sum_{i=1}^k \frac{1}{i} ∑i=1ki1,此数介于 l n k ∼ l n k + 1 lnk\sim lnk+1 lnk∼lnk+1,用 H k H_k Hk表示。当 ϵ → 0 \epsilon \rightarrow 0 ϵ→0时,退出博弈的POA接近于 H k H_k Hk,同样也是一个非常不合理的均衡,非常低效率的均衡。
—————————-第三部分均衡计算————————–
第十六章 最优反应动力学
第十七章 无憾动力学
第十八章 交换遗憾和最小最大化定理
第十九章 纯策略纳什均衡和PLS完全性
第二十章 混合策略纳什均衡和PPAD完全性
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181699.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
