大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
博弈论(Game Theory)入门学习笔记(已全部更新)
-
-
- 课程介绍
- 1-1 Taste-Backoff
- 1-2 Self-Interested Agents and Utility Theory
- 1-3 Define
- 1-4 Examples
- 1-5 Nash Equilibrium Intro
- 1-6 Strategic Reasoning
- 1-7 Best Response and Nash Equilibrium
- 1-8 Nash Equilibrium of Example Games
- 1-9 Dominant Strategies
- 1-10 Pareto Optimality
- 2-1 Mixed Strategies and Nash Equilibrium Taste
- 2-2 Mixed Strategies and Nash Equilibrium
- 2-3 Computing Mixed Nash Equilibrium
- 2-4 Hardness Beyond 2×2 Games
- 2-5 Example: Mixed Strategy Nash
- 2-7 Data:Professional Sports and Mixed Strategies
- 3-1 Beyond the Nash Equilibrium
- 3-2 Strictly Dominated Strategies & Iterative Removal
- 3-3 Dominated Strategies & Iterative Removal:An Application
- 3-4 Maxmin Strategies
- 3-5 Maxmin Strategies
- 3-5 Correlated Equilibrium:Intuition
- 4-1 Perfect Information Extensive Form:Taste
- 4-2 Formalizing Perfect Information Extensive Form Games
- 4-3 Perfect Information Extensive Form:Strategies,BR,NE
- 4-4 Subgame Perfection
- 4-5 Backward Induction
- 4-6 Subgame Perfect Application:Ultimatum Bargaining
- 4-7 Imperfect Information Extensive Form:Poker
- 4-8 Impect Information Extensive Form:Definition,Strategies
- 4-9 Mixed and Behavioral Strategies
- 4-10 Incomplete Information in the Extensive Form:Beyond Subgame Perfection
- 5-1 Repeated Games
- 5-2 Infinitely Repeated Games:Utility
- 5-3 Stochastic Games
- 5-4 Learning in Repeated Games
- 5-5 Equilibria of Infinitely Repeated Games
- 5-6 Discounted Repeated Games
- 5-7 A Folk Theorem for Discounted Repeated Games
- 6-1 Bayesian Games:Taste
- 6-2 Bayesian Games:First Definition
- 6-3 Bayesian Games:Second Definition
- 6-4 Analyzing Bayesian Games
- 6-5 Analyzing Bayesian Games:Another Example
- 7-1 Coalitional Game Theory:Taste
- 7-2 Coalitional Game Theory:Definitions
- 7-3 The Shapley Value
- 7-4 The Core
- 7-5 Comparng the Core and Shapley Value in an Example
-
课程介绍
- 博弈论,又称对策论,是使用严谨的数学模型研究冲突对抗条件下最优决策问题的理论,是研究竞争的逻辑和规律的数学分支。
1-1 Taste-Backoff
- 以一个经典案例引出博弈论
- TCP Backoff Game
两台电脑之间想要实现通信,两种方式可供选择,建立回退机制以及不建立回退机制。如果AB双方均建立回退机制,则双方延迟都是1。如果A、B一方建立回退机制,另一方不建立,那么建立的一方延迟是4,不建立的一方延迟是0。如果双方都不建立回退机制,则双方延迟都是3。
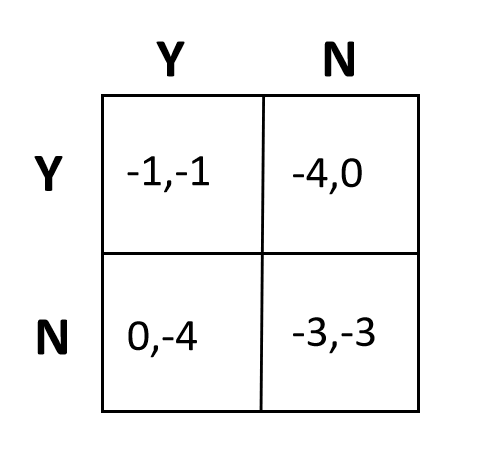

- 该问题的结果有一特点,即自己做出决策的收益不仅跟自己的决策有关,还跟对方的决策有关。因此存在一种“博弈”竞争关系。
1-2 Self-Interested Agents and Utility Theory
- Self-Interested Agents:利己代理
并不是说决策者只考虑自己或者伤害他人,而是指决策者对于世界状态有自己的独特看法,并且根据自己的判断理解做出决策。 - Utility Theory :效用理论
每个决策者都有自己的效用函数,表达了决策者对于决策的偏好,决策者做出决策都是为了最大化效用期望。
1-3 Define
-
Key Ingredients 关键组成
Players:决策者。执行决策的人。
Actions:动作。决策者可以做的事情。
Payoffs:回报。激励决策者的东西,决策带来的回报。 -
Two Standard Representations 两种标准表达方式
Normal Form:分别定义Players、Actions、Payoffs。
Extensive Form:扩展定义Timing、Information。 -
简单的博弈论问题可以使用矩阵表达,如1-1所示。
-
复杂问题无法用矩阵表达,如经典的造反问题。共有10000000个人,每个人可以选择造反或者不造反,只有达到2000000个人才算造反成功。如果造反达到人数要求,无论决策者选择什么收益都是1;如果造反没有达到人数要求,则决策者选择造反的收益是-1;如果造反没有达到人数要求,则决策者选择不造反的收益是0。
Players: N = { 1 , . . . , 10 , 000 , 000 } N=\{1,…,10,000,000\} N={
1,...,10,000,000}
Actions Set for player i i i: A i = { R e v o l t , N o t } A_i=\{Revolt,Not\} Ai={
Revolt,Not}
Utility Function for player i i i:
(1) u i ( a i ) = 1 i f { j : a j = R e v o l t } > = 2 , 000 , 000 u_i(a_i)=1 \space if \{j:a_j=Revolt\}>=2,000,000 ui(ai)=1 if{
j:aj=Revolt}>=2,000,000
(2) u i ( a i ) = − 1 i f { j : a j = R e v o l t } < 2 , 000 , 000 a n d a i = R e v o l t u_i(a_i)=-1 \space if \{j:a_j=Revolt\}<2,000,000 \space and \space a_i=Revolt ui(ai)=−1 if{
j:aj=Revolt}<2,000,000 and ai=Revolt
(3) u i ( a i ) = − 0 i f { j : a j = R e v o l t } < 2 , 000 , 000 a n d a i = N o t u_i(a_i)=-0 \space if \{j:a_j=Revolt\}<2,000,000 \space and \space a_i=Not ui(ai)=−0 if{
j:aj=Revolt}<2,000,000 and ai=Not
1-4 Examples
-
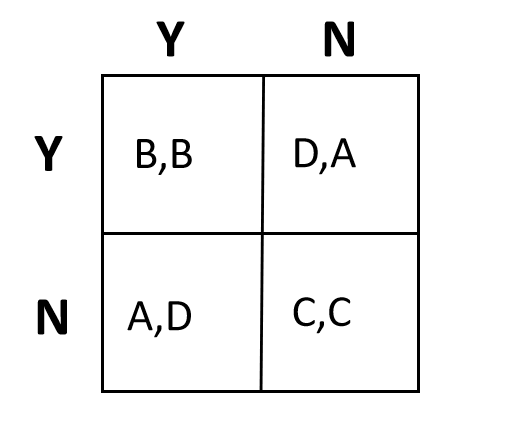
囚徒困境 Prisoner’s dilemma。故事背景:两个共谋犯罪的人被关入监狱,不能互相沟通情况。如果两个人都不揭发对方,则由于证据不确定,每个人都坐牢一年;若一人揭发,而另一人沉默,则揭发者因为立功而立即获释,沉默者因不合作而入狱十年;若互相揭发,则因证据确凿,二者都判刑八年。由于囚徒无法信任对方,因此倾向于互相揭发,而不是同守沉默。
结果的优劣程度按照A>B>C>D排序。
-
Game of Pure Competition 纯竞争博弈
博弈的双方具有完全对立的利益。
对于双方任意动作组合,其效用之和永远为一个常数。 ∀ a ∈ A , u 1 ( a ) + u 2 ( a ) = c \forall \space a \in A,u_1(a)+u_2(a)=c ∀ a∈A,u1(a)+u2(a)=c
特殊类型:零和博弈。双方效用之和永远为0。
举例说明:石头剪刀布游戏。

-
Games of Cooperation 合作博弈
博弈的多方具有相同的利益,利益之间不存在冲突。 ∀ a ∈ A , ∀ i , j , u i ( a ) = u j ( a ) \forall a\in A,\forall i,j,u_i(a)=u_j(a) ∀a∈A,∀i,j,ui(a)=uj(a)
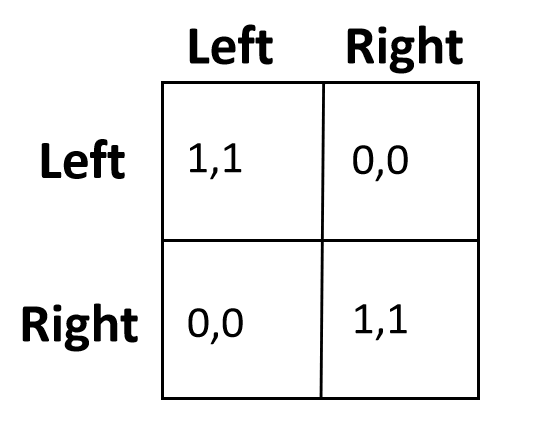
举例说明:过马路问题。马路两头两个人想同时通行,每个人可以选择靠左或者靠右行驶。
1-5 Nash Equilibrium Intro
- Keynes Beauty Contest Game:凯恩斯选美博弈
举办选美大赛,从1-100号候选者中选择自己认为最美的一位,获得票数最多的人获得选美冠军,投票给选美冠军的人也会得到一定的奖励。这个问题是老千层饼了,第一层的人只是自己觉得谁漂亮就选谁,比如A觉得10号最美投票给了10号;第二层的人考虑其他人的投票分布从而产生自己的决策,比如B觉得可能有很多人投票给30号,虽然自己喜欢10号也投票给30号;第三层的人觉得其他人可能也会因为考虑到第二层的因素,从而放弃自己最喜欢的转投自己认为最火爆的…这是一个无休止的猜想游戏。 - 猜数字游戏
每个人从1-100中选择一个整数,最后最接近平均值三分之二的人获得奖励,假设参加这项游戏的人数足够多。这个问题同样是一个千层饼问题。
第一层的人:参赛人数足够多,我假设大家所选择的数字均匀分布,那么最后的平均值应该接近于50。那么我为了获胜应该选择的数字是 50 ∗ 2 3 = 33 50*\frac{2}{3}=33 50∗32=33。
第二层的人:我想大部分人都在第一层,因此他们都选择33。那么最后的平均值应该接近于33。那么我为了获胜应该选择的数字是 33 ∗ 2 3 = 22 33*\frac{2}{3}=22 33∗32=22。
第三层的人: 22 ∗ 2 3 = 11 22*\frac{2}{3}=11 22∗32=11。
…
第n层的人:应该选择的数是0。这就得到了纳什均衡。
美国进行过一项调查,其中2%选择了66(没读懂题的笨蛋)、5%的选择了50(第一层)、10%的选择了33(第二层)、6%选择了22(第三层)、12%的选择了0或者1(思考到了最后)。但最后的结果平均值为19,第三层左右的人获得了最终的胜利。 - 以上两个故事告诉我们,在投资问题或者博弈问题中,我们的层数不可太高也不可太低。太低是傻子,太高聪明反被聪明误。
1-6 Strategic Reasoning
- 在其他人的决策确定的情况下,每一个决策者都是为了最大化个人的收获效用来做出决策。
- 一旦纳什均衡建立,没有人可以通过改变决策跳出均衡而获利受益。
- 如果某些决策者通过改变决策跳出均衡可以获利受益,那么说明纳什均衡还没有真正建立。
- 纳什均衡是一个稳定的状态,但并不是一个最优的获利状态。
1-7 Best Response and Nash Equilibrium
- Best Response 最优响应
如果知道其他所有人的动作,那么挑选对于自己最有利的动作就变得十分简单。
a i 表 示 第 i 个 决 策 者 所 做 出 的 决 策 a_i表示第i个决策者所做出的决策 ai表示第i个决策者所做出的决策
a − i = { a 1 , . . . , a i − 1 , a i + 1 , . . . , a n } 表 示 除 去 a i 以 外 其 他 人 的 决 策 a_{-i}=\{a_1,…,a_{i-1},a_{i+1},…,a_n\}表示除去a_i以外其他人的决策 a−i={
a1,...,ai−1,ai+1,...,an}表示除去ai以外其他人的决策
a = ( a i , a − i ) a=(a_i,a_{-i}) a=(ai,a−i)
a i ∗ ∈ B R ( a − i ) i f f ∀ a i ∈ A i , u i ( a i ∗ , a − i ) > = u i ( a i , a − i ) a_i^*\in BR(a_{-i})\space iff \forall a_i\in A_i,u_i(a_i^*,a_{-i})>=u_i(a_i,a_{-i}) ai∗∈BR(a−i) iff∀ai∈Ai,ui(ai∗,a−i)>=ui(ai,a−i)
其中 B R ( a − i ) BR(a_{-i}) BR(a−i)表示已知其他决策信息后第i个决策者做出的最优响应,最优响应不一定只有一个。并且最优相应集合中的所有元素 a i ∗ a_i^* ai∗都满足下列要求,当且仅当选择 a i ∗ a_i^* ai∗的效用大于等于选择其他所有响应的效用。 - Pure Strategy Nash Equilibrium 纯策略纳什均衡
实际上我们并不知道其他人会做出何种决策,因此根据他人决策制定自己的最优响应是不现实的。
a = { a 1 , . . . , a n } i s a p u r e s t r a t e g y N a s h e q u i l i b r i u m i f f ∀ i , a i ∈ B R ( a − i ) a=\{a_1,…,a_n\}is \space a \space pure \space strategy \space Nash \space equilibrium \space iff \space \forall i,a_i\in BR(a_{-i}) a={
a1,...,an}is a pure strategy Nash equilibrium iff ∀i,ai∈BR(a−i)
1-8 Nash Equilibrium of Example Games
- 纳什均衡的定义
给定其他决策者的决策,每个决策者都没有单独改变决策的动机。(也就是当前决策是最优决策)
假设一共有A、B、C三个决策者,已知A、B决策下C做出最优决策 c ∗ c^* c∗,已知A、C决策下B做出最优决策 b ∗ b^* b∗,已知B、C决策下A做出最优决策 a ∗ a^* a∗,那么 ( a ∗ , b ∗ , c ∗ ) (a^*,b^*,c^*) (a∗,b∗,c∗)就是一个纳什均衡点。 - 如何从决策矩阵中挑选纳什均衡点?
看该单元格,是否左侧的值是该列左侧值的最大值,右侧的值是否是该行右侧值的最大值。 - 纳什均衡不一定是对于全局来说最优的结果。比如囚徒困境。
- 纳什均衡也不是自发实现的,需要有一定的沟通协商规定,总之就是直接间接获取他人的决策信息。
1-9 Dominant Strategies
- Strictly\Very Weakly Dominates 决策优势、劣势关系
s i s t r i c t l y d o m i n t a t e s s i ′ i f ∀ s − i ∈ S − i , u i ( s i , s − i ) > u i ( s i ′ , s − i ) s_i \space strictly \space domintates \space s_i^{‘} \space if \forall s_{-i}\in S_{-i},u_i(s_i,s_{-i})>u_i(s_i^{‘},s_{-i}) si strictly domintates si′ if∀s−i∈S−i,ui(si,s−i)>ui(si′,s−i)
s i v e r y w e a k l y d o m i n t a t e s s i ′ i f ∀ s − i ∈ S − i , u i ( s i , s − i ) > = u i ( s i ′ , s − i ) s_i \space very \space weakly \space domintates \space s_i^{‘} \space if \forall s_{-i}\in S_{-i},u_i(s_i,s_{-i})>=u_i(s_i^{‘},s_{-i}) si very weakly domintates si′ if∀s−i∈S−i,ui(si,s−i)>=ui(si′,s−i)
严格压制关系与轻微压制关系的区别就在于取不取等号。以 s i s_i si严格压制决策 s i ′ s_i^{‘} si′为例,是指无论其他决策者制定什么决策,当前决策者选择 s i s_i si的效用一定严格优于选择 s i ′ s_i^{‘} si′。 - 如果一个决策压制其他所有决策,那么称之为占优策略。如果该决策严格压制每一个其他决策,那么称之为严格占优策略,并且该策略唯一。由占优策略组成的策略组合一定是纳什均衡点,全部由严格占优策略组成的策略组合一定是唯一的纳什均衡点。
1-10 Pareto Optimality
- 之前对于决策的选择以及评估都是站在每个决策者的角度,现在我们跳出决策者的身份,以一个外界观察者的角度来评估决策。我们只考虑最直接的一种评估方式,如果决策组合 O O O对于所有决策者的效用都优于决策 O ′ O^{‘} O′,那么我们称 O P a r e t o − d o m i n a t e s O ′ O \space Pareto-dominates \space O^{‘} O Pareto−dominates O′。
比如说 O ( 7 , 8 ) 、 O ′ ( 4 , 5 ) , 那 么 我 们 可 得 O P a r e t o − d o m i n a t e s O ′ O(7,8)、O^{‘}(4,5),那么我们可得O \space Pareto-dominates \space O^{‘} O(7,8)、O′(4,5),那么我们可得O Pareto−dominates O′。 - Pareto-Optimal 帕累托最优
一个决策组合 O ∗ O^* O∗,如果没有其他任何一个决策组合帕累托压制 O ∗ O^* O∗,那么称该决策组合是帕累托最优。
帕累托最优定义的并不是压制别人的能力,而是不被其他人压制。
一场游戏中可能有多个帕累托最优决策组合。
一场游戏中最少含有一个帕累托最优决策组合。 - 实例分析
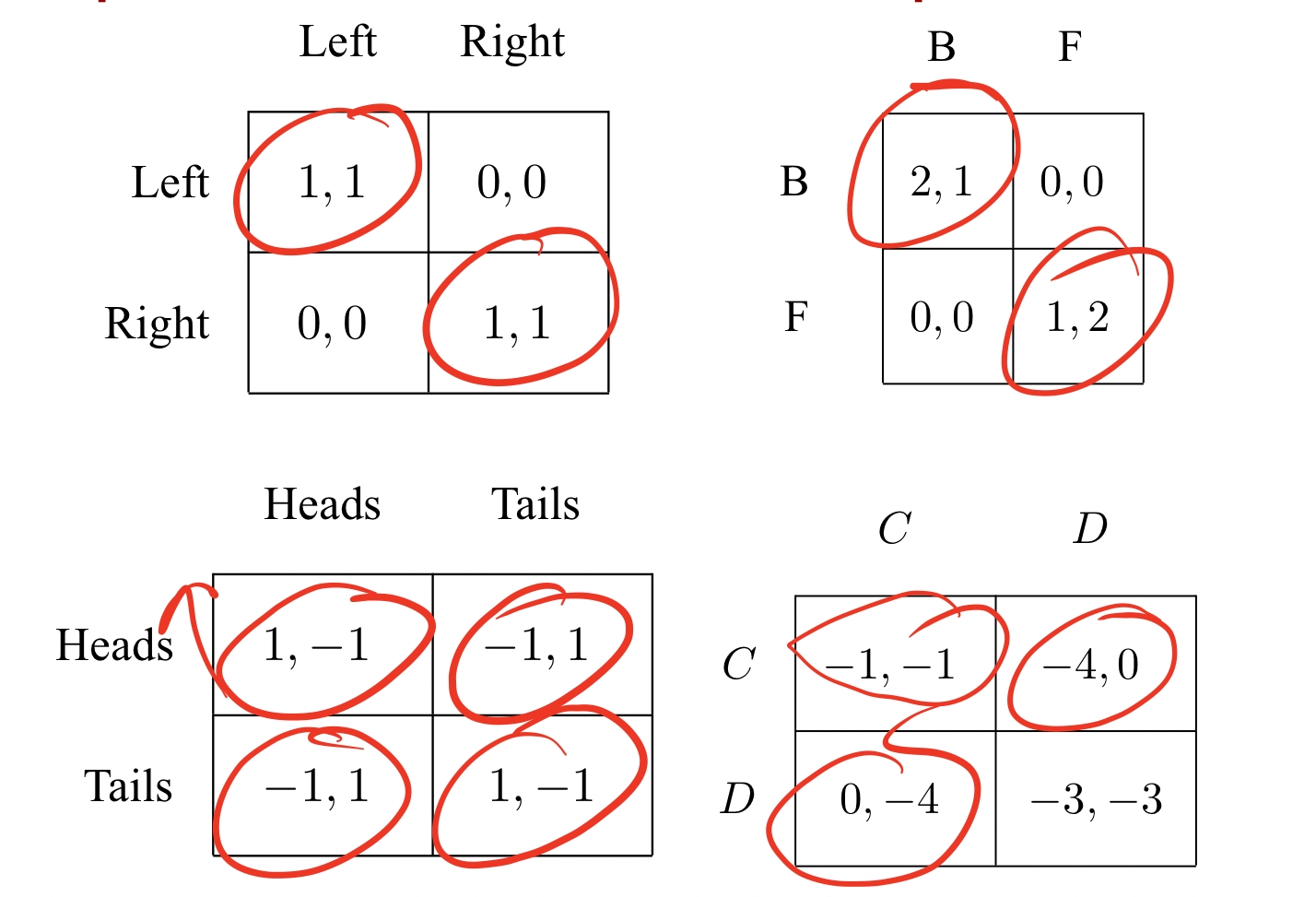
注意对于零和博弈问题来说,所有决策组合都是帕累托最优。
2-1 Mixed Strategies and Nash Equilibrium Taste
- 以安保设置检查关卡、攻击者制定策略攻击关卡的博弈问题来引出混合策略。
2-2 Mixed Strategies and Nash Equilibrium
- 纯策略每次决策选择的是具体的动作,而混合策略每次决策选择的是概率分布。纯策略纳什均衡是混合策略纳什均衡的一种。
- 纯策略均衡:每个决策者都是根据已知其他决策者的选择从而做出决策,并且在已知其他决策者选择的前提下没有改变自己决策的动机。混合策略均衡:每个决策者只可以调整自己的决策分布,而自己的效用则由其他决策者的决策分布决定。
- 在博弈游戏中,决策者每次选择固定的决策方式是最愚蠢的结果,因为竞争者会根据你的固定选择从而制定策略获利。因此决策者应该随机决策来迷惑对手,让对手猜不透你的选择。
- 区分定义:在纯策略中每个决策者每一步决定的是一个动作 a i a_i ai;在混合策略中每个决策者每一步决定的是一个策略 s i s_i si,策略包含多个动作及对应概率。针对第 i i i个决策者所有策略的组合为 S i = { s 1 , . . . , s n } S_i=\{s_1,…,s_n\} Si={
s1,...,sn},针对所有决策者的策略组合为各个决策者的策略笛卡尔积 S = S 1 × . . . × S n S=S_1\times …\times S_n S=S1×...×Sn。 - 在纯策略中我们针对每个决策者的不同动作衡量效用,在混合策略中我们针对每个决策者的不同策略概率分布来衡量效用,换句话说计算效用期望。
u i ( s ) = ∑ a ∈ A u i ( a ) P r ( a ∣ s ) , P r ( a ∣ s ) = ∏ j ∈ N s j ( a j ) u_i(s)=\sum_{a\in A}u_i(a)Pr(a|s),Pr(a|s)=\prod_{j\in N}s_j(a_j) ui(s)=∑a∈Aui(a)Pr(a∣s),Pr(a∣s)=∏j∈Nsj(aj) - 混合策略中的最优响应以及纳什均衡
只需要将之前的 a i a_i ai全部替换成 s i s_i si即可。
s i ∗ ∈ B R ( s − i ) i f f ∀ s i ∈ S i , u i ( s i ∗ , s − i ) > = u i ( s i , s − i ) s_i^*\in BR(s_{-i})\space iff \forall s_i\in S_i,u_i(s_i^*,s_{-i})>=u_i(s_i,s_{-i}) si∗∈BR(s−i) iff∀si∈Si,ui(si∗,s−i)>=ui(si,s−i)
s = { s 1 , . . . , s n } i s a N a s h e q u i l i b r i u m i f f ∀ i , s i ∈ B R ( s − i ) s=\{s_1,…,s_n\}is \space a \space Nash \space equilibrium \space iff \space \forall i,s_i\in BR(s_{-i}) s={
s1,...,sn}is a Nash equilibrium iff ∀i,si∈BR(s−i) - 纳什理论
每个有限游戏都有一个纳什均衡。(有限游戏是指有限的players、actions、utilities)。
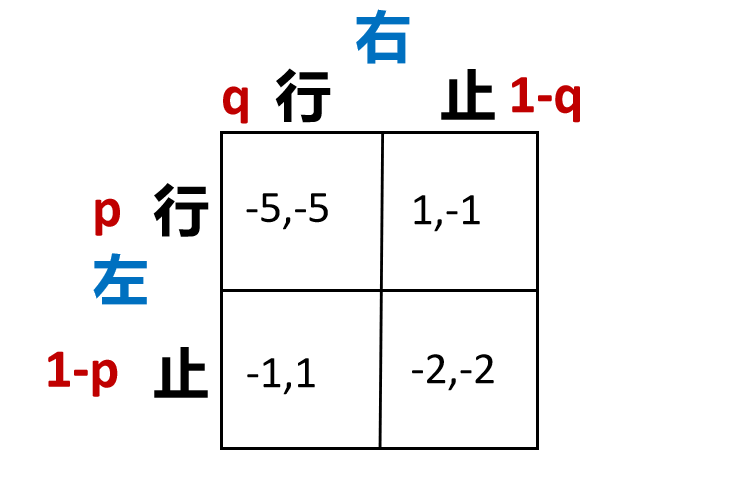
2-3 Computing Mixed Nash Equilibrium
- 以行人问题作为示例,展示两种纳什均衡的求解方法。

2-4 Hardness Beyond 2×2 Games
- 本章节介绍算法求解纳什均衡问题的困难行与复杂度。
- 寻找NE(纳什均衡)的两个经典算法:
LCP(Linear Complementarity)formulation 线性互补问题。
Support Enumeration Method 子集枚举算法。 - NE求解是一个困难的问题,现在还没有一般的NE求解方法(不仅限于双矩阵博弈)。目前还没有求解NE的多项式时间算法,并且与NE有关的几个问题已经被证明是np-hard的(比如判断当前问题是否有多于一个NE)。
- 在4 人及以上的博弈中,纳什均衡的计算是属于PPAD-Complete 的。总结来说,PPAD介于NP与P之间。最外层的NPC问题是指在多项式时间内可以判断是否存在解,NP问题是指已知存在解但无法在多项式时间内求解,P问题是指可以在多项式时间内求解。
2-5 Example: Mixed Strategy Nash
-
本节我们以足球中点球大战的例子来体会混合策略纳什均衡在实际当中的应用。
-
点球大战说的是这么一种博弈游戏。点球者可选择向左向右踢,守门员可选择向左向右扑救。最简单的情况,我们默认守门员扑空的情况,点球者收益是1,守门员收益是0;守门员选对方向的情况,点球者收益是0,守门员收益是1。但是实际情况中,收到点球者球技的影响,守门员扑空时也不一定进球,比如说该球员右脚技术很差,即便扑空,也只有75%的概率进球。
-
最基础的点球大战收益矩阵:
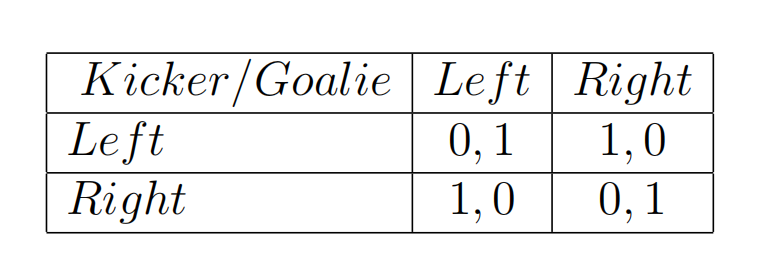
-
调整后的点球大战收益矩阵:
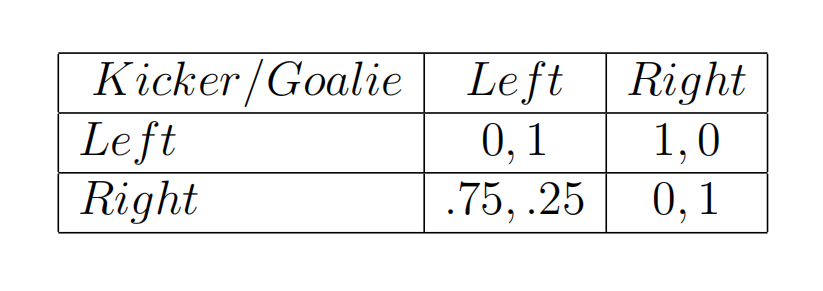
-
守门员的决策分布使得点球者对自己的决策漠不关心(收益相等):
设守门员向左扑的概率为 q q q,向右扑的概率为 1 − q 1-q 1−q
达到纳什均衡时,点球者向左向右踢得收益相同:
q × 0 + ( 1 − q ) × 1 = q × 0.75 + ( 1 − q ) × 0 , q = 4 7 q\times 0+(1-q)\times 1=q\times 0.75+(1-q)\times 0,q=\frac{4}{7} q×0+(1−q)×1=q×0.75+(1−q)×0,q=74 -
点球者的决策分布使得守门员对自己的决策漠不关心(收益相等):
设点球者向左踢的概率为 p p p,向右踢的概率为 1 − p 1-p 1−p
达到纳什均衡时,守门员向左向右扑得收益相同:
p × 1 + ( 1 − p ) × 0.25 = p × 0 + ( 1 − p ) × 1 , p = 4 7 p\times 1+(1-p)\times 0.25=p\times 0+(1-p)\times 1,p=\frac{4}{7} p×1+(1−p)×0.25=p×0+(1−p)×1,p=74 -
分析以上结果,点球者知道自己的左脚更具有优势,因此增大向左踢的概率,最终达到纳什均衡有 4 7 \frac{4}{7} 74的概率向左踢。守门员知道点球者左脚有优势会更多向左踢,因此增大向左扑的概率,最终达到纳什均衡有 4 7 \frac{4}{7} 74的概率向左扑。
2-7 Data:Professional Sports and Mixed Strategies
-
上一节中我们利用收益矩阵理论分析了点球大战中的博弈情况,这一节我们通过真实实验数据去验证理论的正确性。
-
147场点球统计出的收益矩阵信息:
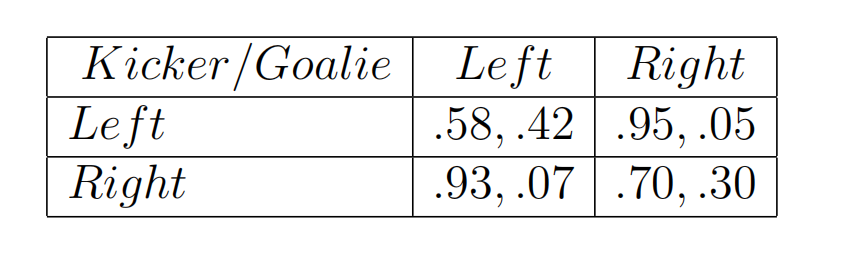
-
设点球者向左踢的概率为 P K P_K PK,守门员向左扑的概率为 P G P_G PG,计算纳什均衡点。
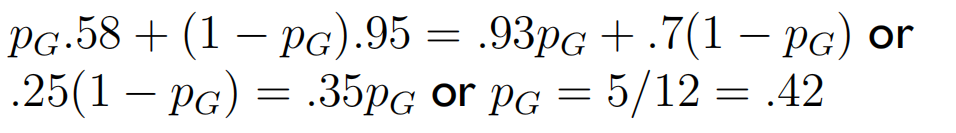
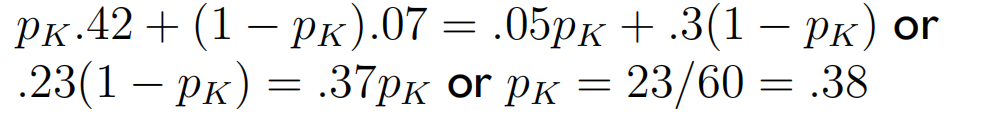
-
将计算出的概率与实际统计的概率相比,两者结果非常接近。证明纳什均衡理论的确是实际存在的、正确的理论,可以表征事物发展的内在规律。
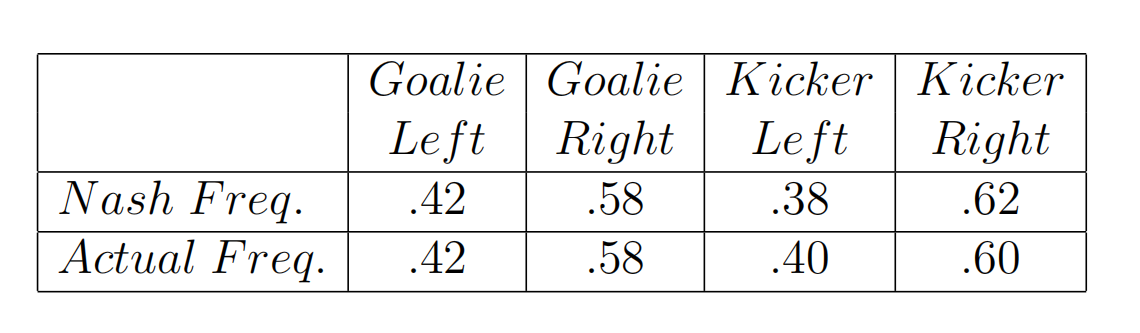
3-1 Beyond the Nash Equilibrium
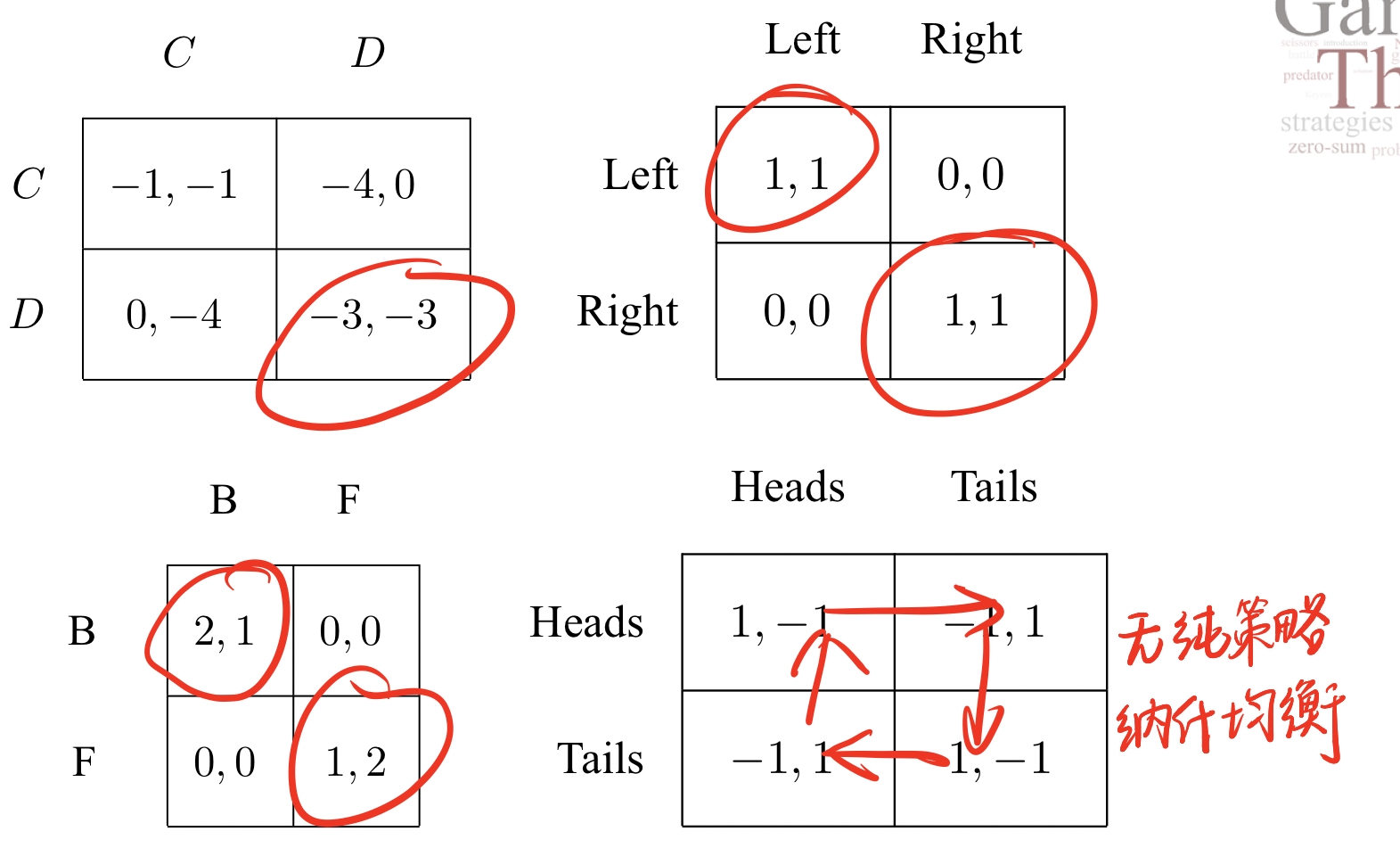
- 本章节用三张图片,三个故事分别引出Dominated Strategies、Zero-Sum Games、Coordination。
3-2 Strictly Dominated Strategies & Iterative Removal
- 本章节带来的是严格占优策略以及迭代消除法。
- Strictly Dominated Strategies 严格占优策略
A strategy a i ∈ A i a_i\in A_i ai∈Aiis strictly dominated by a i ′ ∈ A i a_i^{‘}\in A_i ai′∈Aiif u i ( a i , a − i ) < u i ( a i ′ , a − i ) ∀ a − i ∈ A − i u_i(a_i,a_{-i})<u_i(a_i^{‘},a_{-i})\forall a_{-i}\in A_{-i} ui(ai,a−i)<ui(ai′,a−i)∀a−i∈A−i.
简单来说,无论其他决策者作何决策,第 i i i个决策者选择 a i a_i ai的收益都要大于选择 a i ′ a_i^{‘} ai′。 - 迭代消除法过程图示
每次迭代消去针对的都是某一特定决策者,因此只需看对应的左侧收益或者是右侧收益,不用考虑虽然在左侧收益完全占优,但是右侧收益被消除的有更优的情况,因为博弈的过程是最大化个人收益,不会去考虑到其他决策者的收益。
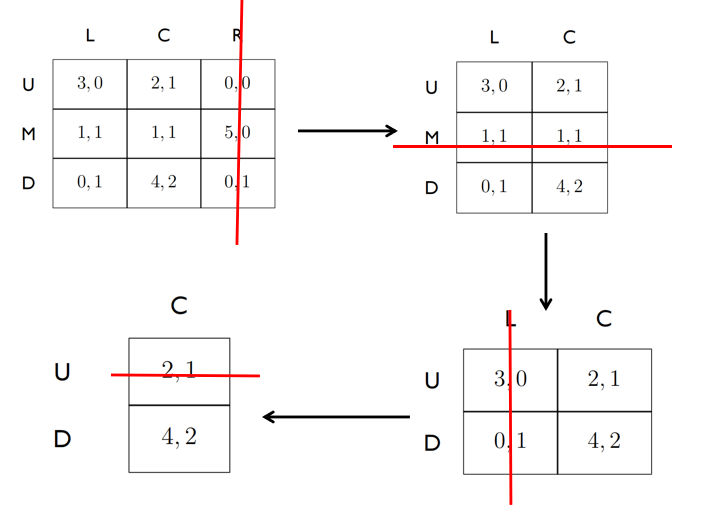
注意:迭代消除的过程同样也可以使用混合策略,比如说第二张图中,如果U行与D行以相同概率混合,混合结果同样严格占优M行,同样可以消除掉M行,虽然这里M行可以使用纯策略消除。因此给与我们提示,如果纯策略消除不掉的话或许可以尝试混合策略消除。 - 借助迭代消除的思想也可以找到纯策略纳什均衡点。
具体方法是:找到每一行左侧收益的最大值标出,找到每一列右侧收益的最大值标出。如果某一个单元下标重合,那么就是纯策略纳什均衡点。
- 依据严格占优策略的迭代消除法会保持纳什均衡的性质(即不影响纳什均衡),并且迭代消除的顺序无关紧要(最终结果相同)。
- 弱占优策略
相较于严格占优策略,弱占优策略的条件相对宽松了一些。严格占优策略要求针对所有的其他决策者决策,第 i i i个决策者选择 a i a_i ai的收益都要优于 a i ′ a_i^{‘} ai′的收益。弱占优决策是指,针对所有的其他决策者决策,第 i i i个决策者选择 a i a_i ai的收益都要大于等于 a i ′ a_i^{‘} ai′的收益,并且对于部分其他决策者的决策情况,第 i i i个决策者选择 a i a_i ai的收益都要优于 a i ′ a_i^{‘} ai′的收益。总结来说弱占优策略部分满足严格占优策略的要求。
弱占优策略同样可以用于迭代消除,但是迭代消除的顺序对结果有影响,至少一个纳什均衡点被保留。
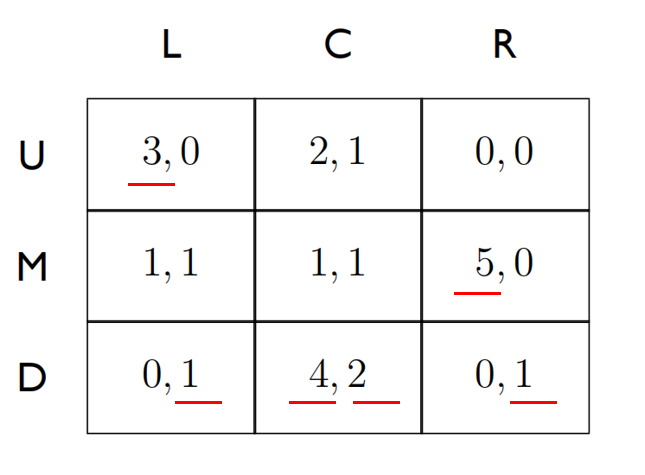
3-3 Dominated Strategies & Iterative Removal:An Application
- 本章节介绍了一个十分有趣的实验来佐证,猪都不会去选择被严格压制的策略,更何况是人类。
- 实验内容是这样的,在一个大笼子里关着一头大猪和一头小猪,两头猪都在笼子的A侧,笼子的B侧有一个机关,触发该机关在笼子的A侧就会掉落下10份食物,无论大猪小猪从A侧跑到B侧触发机关再回到A侧都需要消耗2份食物。大猪会欺负小猪,不同情况下大猪小猪获得事物配比如下:
如果大猪先得到食物,最终小猪获得1份,大猪获得9份。
如果小猪先得到食物,最终小猪获得4份,大猪获得6份。
如果大猪小猪同时获得,最终小猪获得3份,大猪获得7份。 - 该问题的收益矩阵如下图所示:
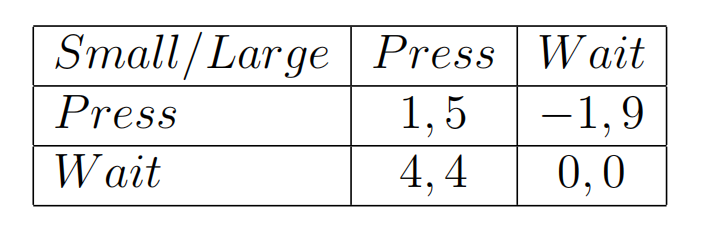
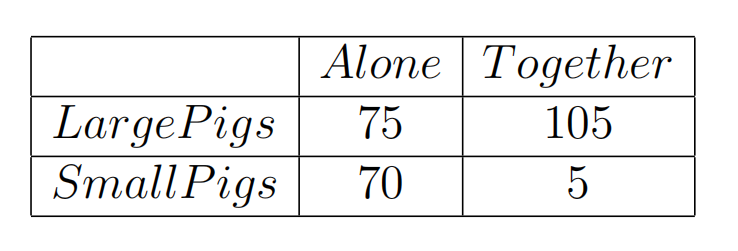
- 虽然无论谁先得到食物,都是大猪获益更多,但是对于小猪来说,正确的决策能增加自己的收益。选择花费2份食物代价去触发机关,也就以为着会较晚获得食物,因此看起来大猪小猪都选择等待是最好的选择,但同时也存在问题如果都不触发机关就都无法获得食物。
- 该问题中存在着严格占优策略,对于小猪来说,选择等待的收益永远大于选择触发的收益,因此小猪很大概率会选择等待。而大猪虽然也想“坐享其成”,但小猪的决策让大猪不得不更多时候选择去触发机关。最终实验的统计结果如下:
3-4 Maxmin Strategies
- Maxmin Strategies 最大最小策略
决策者 i i i的最大最小策略是指,决策者选定一个策略 s i s_i si使得最大化自己的最坏情况下的收益。我们设想当其他决策者的决策对决策者 i i i的收益造成最大损害时,此时的收益我们称之为最坏情况下的收益。因此决策者 i i i的最大最小策略,可以说是在最困难的外界坏境中尽可能地拯救自己。
The maxmin strategy for player i i i is a r g m a x s i m i n s − i u i ( s i , s − i ) arg \space max_{s_i}min_{s_{-i}}u_i(s_i,s_{-i}) arg maxsimins−iui(si,s−i)
The maxmin value for player i i i is m a x s i m i n s − i u i ( s i , s − i ) max_{s_i}min_{s_{-i}}u_i(s_i,s_{-i}) maxsimins−iui(si,s−i)
- Minmax Strategies 最小最大策略
决策者 i i i地最小最大策略是指,为了对抗(坑害)其他决策者,决策者 i i i选定一个策略 s i s_i si使得最小化其他决策者的最大收益**。也就是说,我们设想其他决策者已经选定策略最大化自己的收益,而决策者 i i i要尽可能最小化他们的最大收益。可以说是在别人最好的情况下拉他们下水。
In a two-player game,the minmax strategy for player i i i against player − i -i −i is a r g m i n s − i m a x s i u i ( s i , s − i ) arg \space min_{s_{-i}}max_{s_i}u_i(s_i,s_{-i}) arg mins−imaxsiui(si,s−i)
The minmax value for player i i i is m i n s − i m a x s i u i ( s i , s − i ) min_{s_{-i}}max_{s_i}u_i(s_i,s_{-i}) mins−imaxsiui(si,s−i)
- Minmax Theorem 最小最大理论
在任意一个有限的、两个玩家对立的、零和博弈的游戏中,在任何一个纳什均衡点中,两个玩家获得的收益都同时等于其maxmin value 和minmax value。
对于某个决策者来说,最大最小理论是一个防守理论,知道别人可能损害自己利益的同时尽可能止损;最小最大理论是一个进攻理论,知道别人会捍卫自己利益的同时尽可能损害他人。
在零和博弈中,两个人的利益是此消彼长的,你正我负的。因此在零和博弈中,最大最小化与最小最大化实际上是同一种过程,其他人通过最大化自己的收益来最小化你的收益,你就需要最大化自己的收益去尽可能减小其他人的收益,不存在合作共赢的可能。
- 使用LP线性规划的方法求解minmax问题
上一部分中我们了解到,当实现minmax value或者maxmin value时,此时处于纳什均衡。那么就给我们提供了另外一种纳什均衡求解的方法。
这里我们使用minmax思路来求解,以player 2 的角度,我们在满足限制条件下最小化player 1的最优收益。
m i n i m i z e U 1 ∗ ( 1 ) s u b j e c t t o ∑ k ∈ A 2 u 1 ( a 1 j , a 2 k ) × s 2 k < = U 1 ∗ ∀ j ∈ A 1 ( 2 ) ∑ k ∈ A 2 s 2 k = 1 , s 2 k > = 0 ∀ k ∈ A 2 ( 3 ) \begin{aligned} minimize \space U_1^{*}(1) \\ subject \space to \space \sum_{k\in A_2}u_1(a_1^j,a_2^k)\times s_2^k<=U_1^*\space\space\space\space \forall j\in A_1 (2)\\ \sum_{k\in A_2}s_2^k=1,s_2^k>=0\space\space\space \forall k \in A_2(3) \end{aligned} minimize U1∗(1)subject to k∈A2∑u1(a1j,a2k)×s2k<=U1∗ ∀j∈A1(2)k∈A2∑s2k=1,s2k>=0 ∀k∈A2(3)
3-5 Maxmin Strategies
- 我们通过点球大战例子来感受一下minmax与maxmin的求解。点球大战是一个经典的二人零和博弈,因此满足条件,当达到纳什均衡时,最大最小策略与最小最大策略同时满足。
- 点球大战的收益矩阵设定如下:
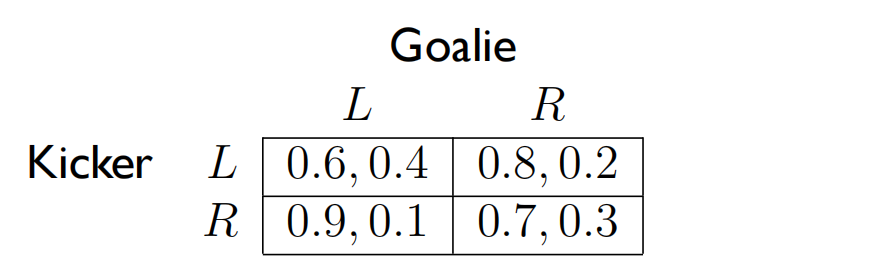
- 从Kicker角度采用最大最小值策略得到:
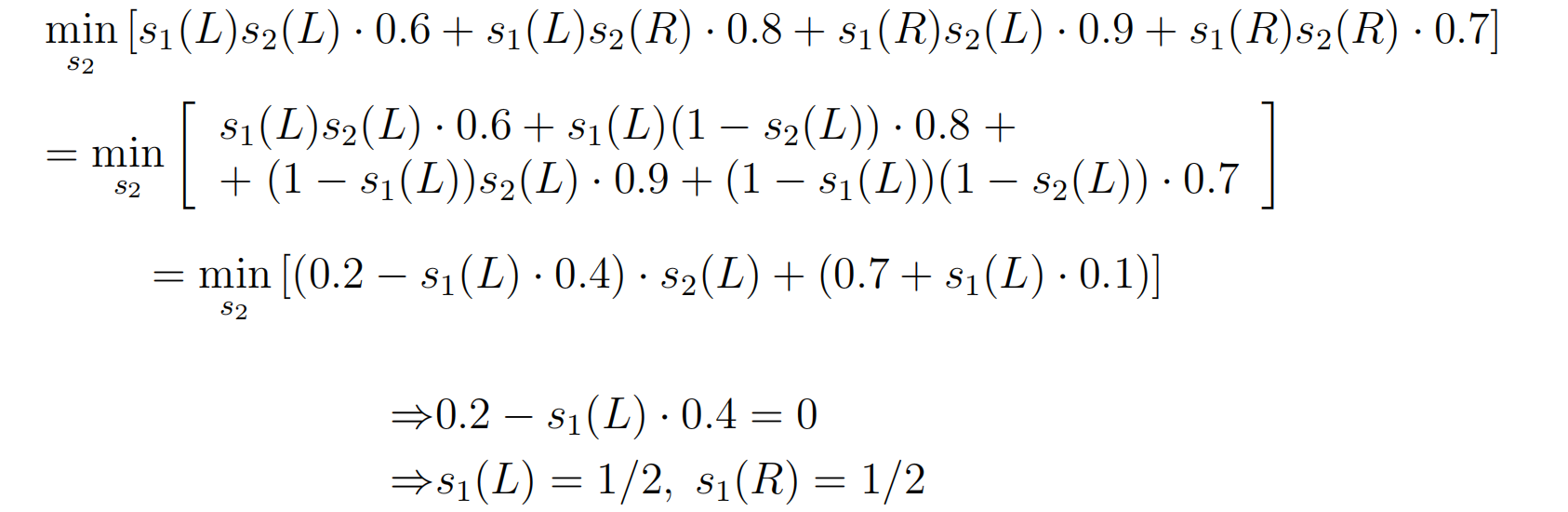
- 从Goalie角度采用最小最大值策略得到:
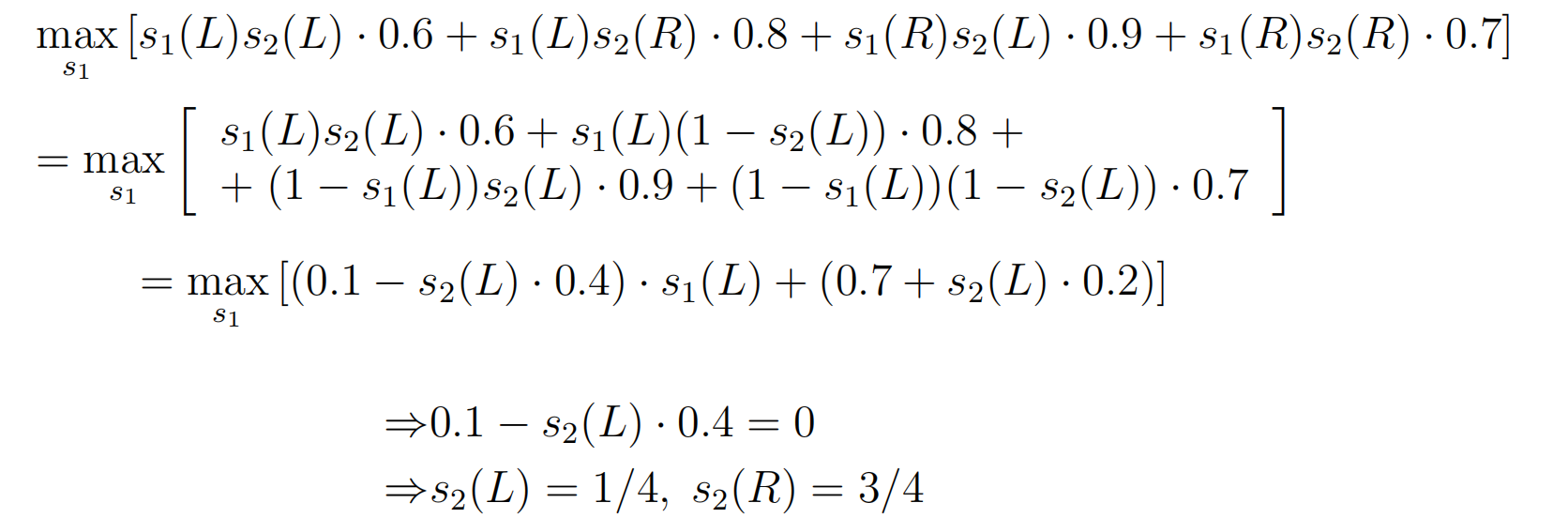
3-5 Correlated Equilibrium:Intuition
- 纯策略纳什均衡是混合策略纳什均衡的特例,后者又是相关均衡的特例。相关均衡是基于推荐的均衡。
- 相关均衡的含义是,给每个代理者随机化地分配潜在相关的决策,每个代理者根据自身被分配到的决策计算发现服从分配是对自己最优的策略,从而没有人会违背策略分配。
- 给定一个博弈和它的一个相关均衡 p p p,由于 p p p 本质上是一个相关系数, p p p给每个参与人推荐行动的过程可以理解成一个不完全信息的生成过程:每个参与人接收到自己的信息(行动推荐),同时产生了对他人信息(行动推荐)的概率估计。从而计算发现服从行动推荐对他自己来说是最优的选择。
4-1 Perfect Information Extensive Form:Taste
- 以两个传说故事引出完美信息拓展形式。
4-2 Formalizing Perfect Information Extensive Form Games
- 本节介绍完美信息拓展形式的形式化表述。
- 之前学习中我们使用的都是一般形式,一般形式并没有体现任何序列信息,比如说时间序列信息,或者是决策者的动作序列信息。拓展形式就可以让时间结构信息表述精确完整,拓展形式分为两种:perfect information extensive-form games 完美信息拓展形式、imperfect-information extensive-form games 不完美信息拓展形式。
- 一个有限的完美信息博弈游戏(拓展形式)被定义如下元组 ( N , A , H , Z , χ , ρ , σ , u ) (N,A,H,Z,\chi, \rho,\sigma,u) (N,A,H,Z,χ,ρ,σ,u)
Players: N N N。N个决策者(游戏玩家)的集合。
Actions: A A A。动作集合。
Choice nodes: H H H。选择节点,非终结节点的集合。
Action function: χ : H → 2 A \chi :H\rightarrow 2^A χ:H→2A。为每一个选择节点指派可能的动作集合。
Player function: ρ : H → N \rho:H\rightarrow N ρ:H→N。为每一个选择节点 h h h指派一个选择动作的决策者 i i i。
Terminal nodes: Z Z Z。终结节点的集合。
Successor function: σ : H × A → H ∪ Z \sigma:H\times A\rightarrow H\cup Z σ:H×A→H∪Z。后继函数,表示某个选择节点选择某一动作后状态转换到另一个选择节点或者是终结节点。
Utility function: u = ( u 1 , . . . , u n ) ; u i : Z → R u=(u_1,…,u_n);u_i:Z\rightarrow R u=(u1,...,un);ui:Z→R。效用函数,在每个终结节点上放置一个元组,表示每个决策者的最终收益。
4-3 Perfect Information Extensive Form:Strategies,BR,NE
- 之前我们学习过一般形式的策略(纯策略、混合策略)、最佳响应BR、纳什均衡NE。这一章节我们拓展定义,研究在完美信息拓展形式下的策略、BR、NE。
- Pure Strategies 纯策略
Let G = ( N , A , H , Z , χ , ρ , σ , u ) G=(N,A,H,Z,\chi,\rho,\sigma,u) G=(N,A,H,Z,χ,ρ,σ,u)be a perfect-information extensive-form game.Then the pure strategies pf player i i i consist for the cross product ∏ h ∈ H , ρ ( h ) = i χ ( h ) \prod_{h\in H,\rho(h)=i}\chi^{(h)} ∏h∈H,ρ(h)=iχ(h)
该定义的中文解释:针对于完美信息拓展形式定义下的纯策略,针对决策者 i i i来说, h ∈ H , ρ ( h ) = i h\in H,\rho(h)=i h∈H,ρ(h)=i是其对应的选择节点, χ ( h ) \chi^{(h)} χ(h)是该选择节点对应的选择可能。因此纯策略是一个集合,集合的结果是所有选择节点对应选择分支的笛卡尔积。
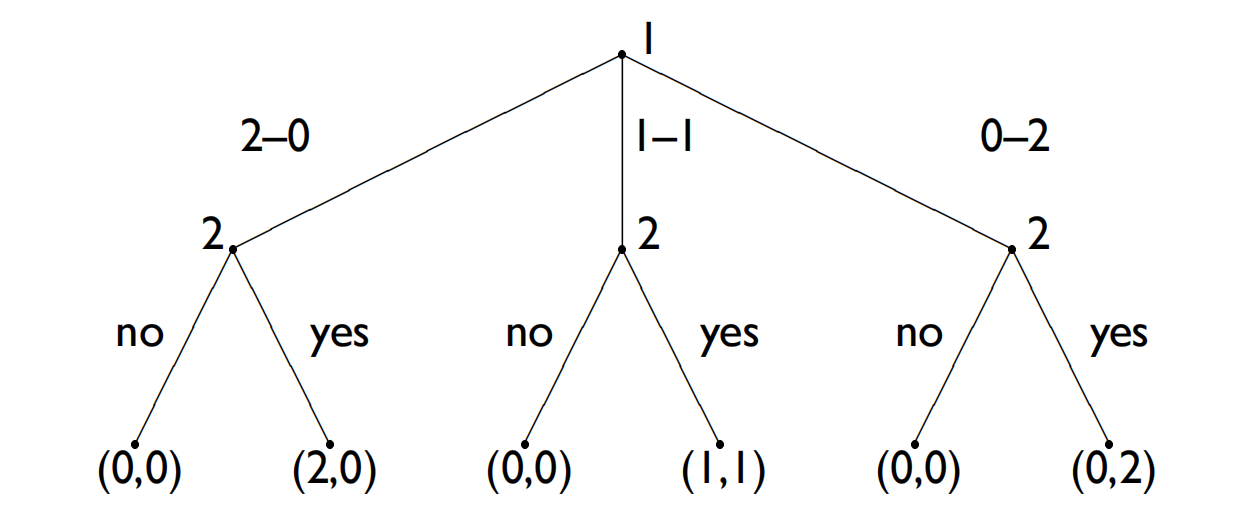
上图所示完美策略拓展形式情景介绍:兄(决策者1)妹(决策者2)两人商量策略分2元钱,哥哥提出三种方案,妹妹针对每种方案都可以选择接受或者不接受,哥哥先做决策,妹妹再做决策,最终达到终结状态也就是树的叶子节点,表达了两个人的收益。
我们来看一下决策者1、2分别有多少个纯策略?决策者1只有一个选择节点,且该选择节点有三个分支,因此纯策略个数为3;决策者2有三个选择节点,且每个选择节点有两个选择分支,因此纯策略个数为2x2x2=8。
- 纯策略在新背景下的定义已经明晰,那么我们可以进一步确定其他相关内容的定义。分别是mixed strategies 混合策略、best response 最佳响应、Nash equilibrium 纳什均衡。这三个概念均与之前相同,只不过我们的博弈游戏表达形式变了,纯策略与混合策略的定义变了。
- 我们可以将拓展形式转变为一般形式(矩阵表述),但并不是所有的一般形式表述的博弈游戏都可以转换成拓展形式表述。
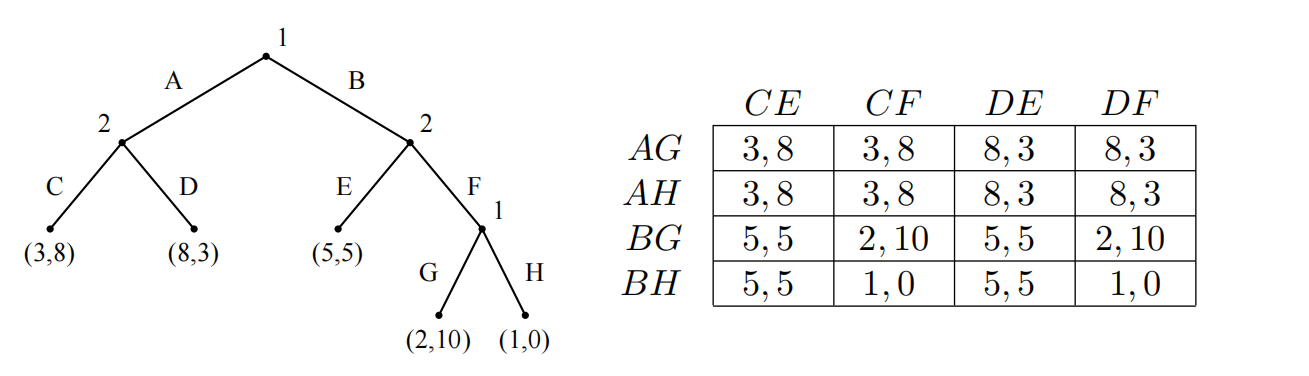
上图中,决策者1的纯策略集合为: S 1 = { ( B , G ) ; ( B , H ) ; ( A , G ) ; ( A , H ) } S_1=\{(B,G);(B,H);(A,G);(A,H)\} S1={
(B,G);(B,H);(A,G);(A,H)}、决策者2的纯策略集合为 S 2 = { ( C , E ) ; ( C , F ) ; ( D , E ) ; ( D , F ) } S_2=\{(C,E);(C,F);(D,E);(D,F)\} S2={
(C,E);(C,F);(D,E);(D,F)}。
我们该如何由拓展形式化为一般形式的矩阵表述呢? S 1 、 S 2 S_1、S_2 S1、S2纯策略分别作为矩阵的横轴与纵轴,接下来我们只需要对应寻找收益元组即可。举个例子,AG与CE组合,我们在左图中标出A、G、C、E,然后发现从起点到叶子节点只有一条通路,对应的叶子节点就是该纯策略组合的收益。 - 完美信息拓展形式中的纯策略纳什均衡(PSNE)
理论:每一个拓展形式表达的完美信息博弈游戏中,都至少有一个纯策略纳什均衡(PSNE)。
上图中有三个纯策略纳什均衡,分别是 ( A , G ) , ( C , E ) ; ( A , H ) , ( C , F ) ; ( B , H ) , ( C , E ) (A,G),(C,E);(A,H),(C,F);(B,H),(C,E) (A,G),(C,E);(A,H),(C,F);(B,H),(C,E)。我们回到收益矩阵中分析,以上三个纯策略纳什均衡点左侧收益是列中的最大值,右侧收益是行中的最大值。
4-4 Subgame Perfection
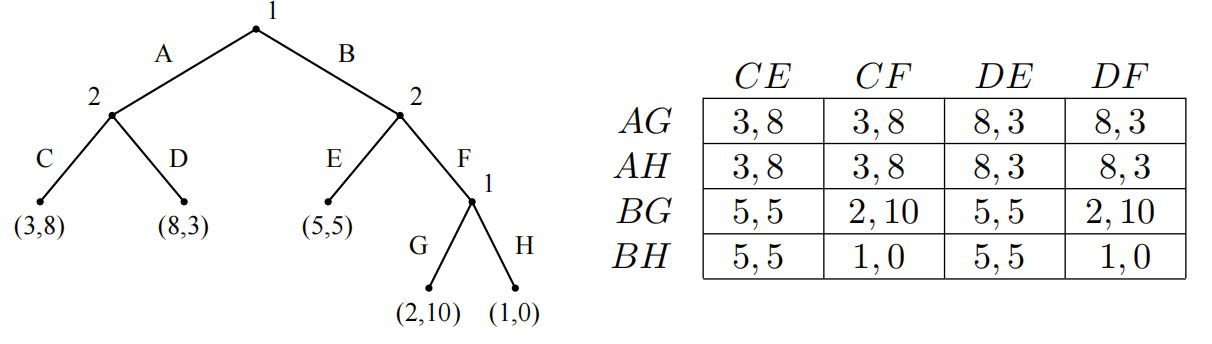
- 上一章节中我们得到了三个纯策略纳什均衡,但并不是所有的纳什均衡都是可信的或者说是合理的。比如说纳什均衡 ( B , H ) , ( C , E ) (B,H),(C,E) (B,H),(C,E),虽然满足纳什均衡的定义,任一决策者单独改变决策都不会获得更优的收益。但是我们看决策者1在第二个选择节点,明显选择G这条路是严格压制选择H的,因此如果我们单独考虑该博弈,决策者1绝对会选择G而不是H。
- 我们讨论一下威胁 threaten。决策者1选择H的目的可能是威胁决策者2,威胁他去选择E而不是F。“如果你选了F,我可就选择H让你收益变成0!”但这明显是一个不可信的威胁non-credible threat,因为即便决策者2选择了F,决策者1考虑到自己的收益也不会选择H。因此该威胁不可能实际存在。
- 那么我们如何区分合理与不合理的纳什均衡呢?只有满足子博弈均衡的才是合理的纳什均衡。
在完美信息拓展形式博弈游戏中,任何一个选择节点都构成一个子博弈。非完美信息的情况以后讨论。
如何判断一个子博弈是否均衡?在选择节点 h h h对应的子博弈中,决策者为 i i i。我们判断决策者 i i i的决策是否是针对自己的最优响应,如果是的话那么就是子博弈均衡。只有所有子博弈层层均衡的才最终判定为一个合理的纳什均衡。
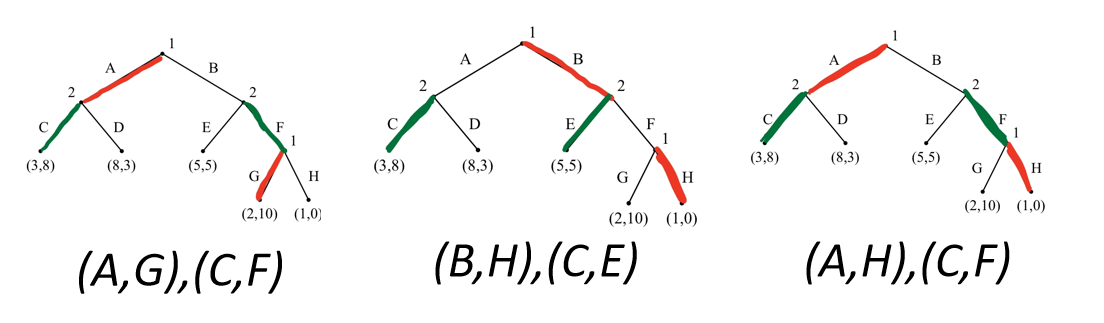
对于均衡 ( A , G ) , ( C , F ) (A,G),(C,F) (A,G),(C,F):符合子博弈完美。
对于均衡 ( B , H ) , ( C , E ) (B,H),(C,E) (B,H),(C,E):决策者1的第二个选择节点就不符合子博弈均衡。
对于均衡 ( A , H ) , ( C , F ) (A,H),(C,F) (A,H),(C,F):决策者1的第二个选择节点就不符合子博弈均衡。
4-5 Backward Induction
- 上一章节介绍了序贯博弈中的纯策略纳什均衡并不都是合理的,我们需要筛选出层层符合子博弈完美的纳什均衡。那么本章节介绍反向归纳算法来求解每个节点(包括选择节点与叶子节点)的最优收益,从而获得层层符合子博弈完美的纳什均衡。
- Backward Induction 反向归纳算法的伪代码表述:

算法输入:某个节点 h h h(选择节点或者是叶子节点)
算法输出:该节点满足子博弈完美的所有决策者收益,递归中每一步的最优决策选择都是针对于选择节点 h h h所对应的决策者 ρ ( h ) \rho(h) ρ(h)而言。
注意:变量 b e s t _ u t i l 、 u t i l _ a t _ c h i l d best\_util、util\_at\_child best_util、util_at_child都是向量,代表了所有决策者的收益
该算法非常简单,其实就是递归思想,自上而下搜索子博弈完美的均衡。
该过程并不返回均衡策略,但是给每个节点用收益向量打上标签。之前只有终结节点有对应的收益向量,该打标签的过程可以看作是将终结节点上的收益向量拓展到选择节点上。 - 零和博弈中的反向归纳法
在零和博弈问题中,BackwardInduction 反向归纳法有另外一个广为人知的名字minmax 极小化极大值算法。
众所周知,递归搜索算法是一个效率很低的算法,存在较多的冗余计算以及无用分支,如果搜索空间足够大的话甚至会无法解决。我们可以使用pruning 剪枝的方法来加速算法,比如说alpha-beta pruning,实际算法思想是分支定界法。有关分支定界法可以参照我的另一篇博客整数规划中的分支定界法,简单来说就是设置目标函数值的上界下界并不断更新,在递归过程中将上下界以外的分支剪枝不做考虑,这样就可以缩小搜索空间,提高搜索效率。 - 反向归纳法失灵了?——Centipede Game 蜈蚣博弈
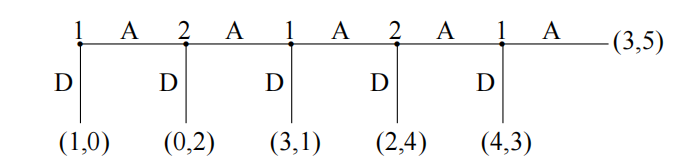
根据前面学习的知识我们知道,反向归纳法中每一步都是决策者选择对自己来说最有利的决策,按说最终达到的结果即便不是全局最优也不会太差。但是我们看上图所示例子,按照反向归纳法分析,每个选择节点决策者都会选择向下,计算到第一个选择节点,决策者1直接向下导致整个决策游戏结束,获得了基本上全局最差的收益。
这种博弈游戏我们称作是Centipede Game 蜈蚣博弈(因为博弈树长得像蜈蚣)。通过分析得知,收益 ( 3 , 5 ) (3,5) (3,5)是除了 ( 4 , 3 ) (4,3) (4,3)以外所有收益的帕累托最优(针对每个决策者都最优),就因为对于决策者1来说收益不如 ( 4 , 3 ) (4,3) (4,3)导致了整体博弈的崩塌。蜈蚣博弈也表明了,局部个人决策的最优对自己来说都不一定是全局最优决策,两个决策者的短视会导致两败俱伤。
蜈蚣博弈在实际生活中可以找到例子,我们考虑两个公司A、B的合作问题。A、B合作越久当然彼此都收益都很越高,但是不可能永久合作,最后总会有一方背叛终止合作,并且最后一位决策者选择背叛的收益一定大于选择继续合作的收益。上图中,A最后选择背叛,之前的B知道A早晚背叛不如先下手为强选择背叛…因此到最开始的A也会直接选择背叛而不是合作。
4-6 Subgame Perfect Application:Ultimatum Bargaining
- 本章节我们来学习子博弈完美的一个应用例子——Ultimatum Bargaining 最后通牒博弈。最后通牒博弈是指:玩家1可以决定 10 10 10块钱(数额可有多种选择,成为本游戏的stake赌注)中有 x x x块钱( x ∈ { 0 , 1 , . . . , 10 } x\in \{0,1,…,10\} x∈{
0,1,...,10})分配给玩家2,玩家2针对每种分配方案都可以选择接受或者拒绝,接受的话双方各自获得收益,拒绝双方收益都为0。 - 画出最后通牒博弈的博弈树,如下图所示:
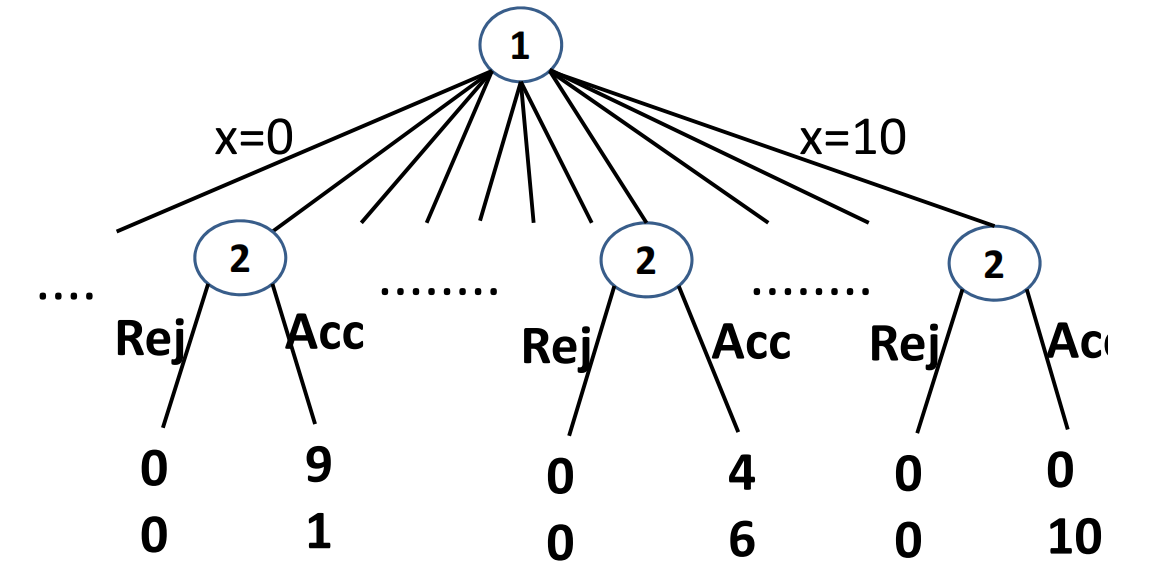
- 我们分析得到:只要决策者1给出的分配方案 x > = 1 x>=1 x>=1,决策者2选择接受相较于选择拒绝都是帕累托最优的,所以根据子博弈完美理论,决策者2只要得到了正值的分配都会接受的,毕竟再少也是白捡的。如果获得了值为0的分配,那么无论选择接受还是拒绝,决策者2的收益都是0,也就是说该决策对于决策者2来说就是漠不关心的,如果决策者2选择接受,那么决策者1的子博弈完美就是 x = 0 x=0 x=0,如果决策者2选择拒绝,那么决策者1的子博弈完美就是 x = 1 x=1 x=1。
- 按照子博弈完美的理论,决策者2只要获得正值的分配就会接受,因此决策者1为了让自己的利益最大化选择分配1、2就可以。但事实并非如此,决策者2获得的利益分配太低的话会觉得“不公平”而拒绝,一旦拒绝两个人的收益都归0。决策者1考虑到这一点,必然不敢给决策者2只分配1的收益,大部分情况下会直接平分收益或者让自己稍微多获利一点,这样的收益期望是更大的。
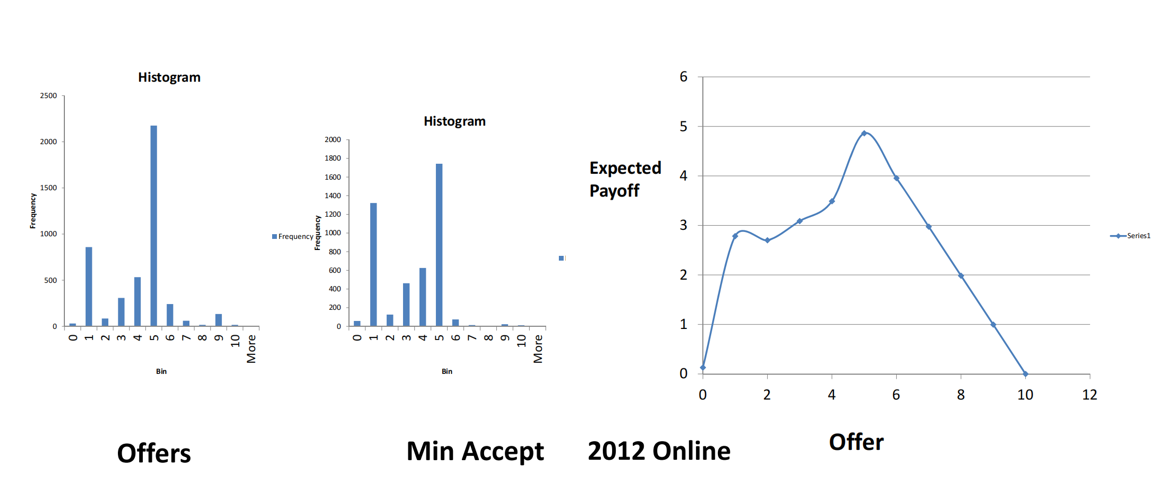
- 让我们看一下2012网络实验数据。第一张图是决策者1提供Offers的数值以及频率,可以看出大部分的决策者1很聪明知道最大化自己的期望收益选择平分,少部分贪婪的决策者1选择遵从子博弈完美理论。第二张图是决策者2可以接受的最小收益,可以看出大部分决策者2都认为要保证公平,收益达到5才可以接受,部分决策者2觉得只要收益为正就可以接受。第三张图是决策者1的收益期望,可以看出当向决策者2提供5的收益时,自己的收益也接近于5,给的太多或太少都会减小自己的期望收益。
- 最后通牒博弈中赌注的大小会不会产生影响呢?下图所示论文中做了这个实验,赌注总额分别设为 60 、 300 、 1500 60、300、1500 60、300、1500,我们来观察决策者1、2的决策情况。

实验结果发现:
赌注数额的不同对于决策者1的Offer提供决策影响不大。

赌注数额的不同对于决策者2的接受\拒绝决策影响很大,并且数额越大拒绝的比例会越小。下图展示的是Offer数值小于25%的拒绝比例。决策者2可能觉得虽然比例依然很小,但赌注数额足够大的时候,不公平也或许是可以接受,或者是不忍心拒绝的情况。

- 子博弈完美以及反向归纳方法都总结了序贯博弈中的合理性。反向归纳的结果是纳什均衡的子集。但均衡之外的路径也并不是不可到达。
4-7 Imperfect Information Extensive Form:Poker
- 之前我们学习研究的是完美信息拓展形式,从本章节开始我们学习不完美信息拓展形式。首先我们用大家熟知的扑克游戏来简单感受一下不完美信息拓展形式。
完美信息是动态博弈中的一个概念。在博弈论中特指参与人完全了解博弈历史的一种信息结构。如果参与人在采取行动时并不完全了解博弈的历史,即并不完全了解其他参与人在他决策之前的所有行动,则这样的信息结构称为不完美信息。
- 扑克游戏特点:
1.序列化博弈过程。2.只可以看到部分卡片信息。3.看到博弈过程并做出反应。4.对其他玩家的理性以及动机保有信念。5.拥有许多种手段。6.拥有许多博弈策略。7.不可能完整写出博弈树。
4-8 Impect Information Extensive Form:Definition,Strategies
- 本章节我们来看一下不完美信息拓展形式的相关定义。
- 在完美信息拓展形式的博弈树中,每位决策者在面临决策时,都已知他们自己的位置以及之前的决策路径。在不完美信息拓展形式中,每一位决策者的选择都被划分成多个等价类,每个等价类中可能包含一至多个选择节点,并且每个决策者无法从自身的决策等价类或者决策路径上的等价类中将不同决策分辨出来。
一个不完美信息博弈游戏的拓展形式由以下元组表示 ( N , A , H , Z , χ , ρ , σ , u , I ) (N,A,H,Z,\chi,\rho,\sigma,u,I) (N,A,H,Z,χ,ρ,σ,u,I),该元组是在完美信息拓展形式表示元组 ( N , A , H , Z , χ , ρ , σ , u ) (N,A,H,Z,\chi,\rho,\sigma,u) (N,A,H,Z,χ,ρ,σ,u)的基础上添加了决策等价类的集合 I I I。
其中 I = ( I 1 , . . . , I n ) I=(I_1,…,I_n) I=(I1,...,In),并且 I i = ( I i 1 , . . . , I i k i ) I_i=(I_{i1},…,I_{ik_i}) Ii=(Ii1,...,Iiki)。解释一下含义: I i I_i Ii表示决策者 i i i的等价类的集合; I i 1 I_{i1} Ii1表示决策者 i i i的第一个决策等价类,该等价类可能包含一到多个单一决策,但是等价类内部不可分辨。同一等价类内部的决策要求满足,针对同一决策者,拥有相同的动作选择集合。
- 分析如下不完美信息拓展形式的博弈树:
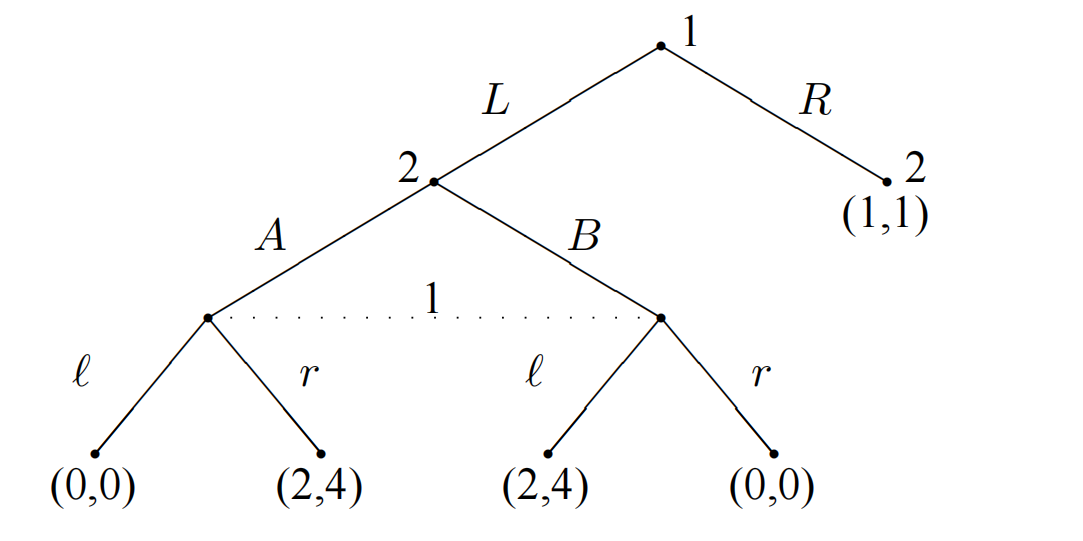
首先图中,使用虚线连接的选择节点构成一个决策等价类。统计某个决策者的等价类需要考虑该决策者的各个阶段。因此决策者1包含两个等价类,决策者2包含两个等价类。
在完美信息拓展形式中,纯策略的定义是该决策者在各个阶段所有决策可能的笛卡尔积。不完美信息拓展形式中的纯策略定义基本相同,只是将基本元素从选择节点改成了决策等价类。 - 一般形式Normal Form与拓展形式Extensive Form之间的转换
一般形式的表达方式是收益矩阵,而拓展形式的表达方式是博弈树。我们可以将任何一般形式的博弈游戏用博弈树的方式表达,只不过博弈树表达出的序列关系不起作用。我们也可以通过枚举纯策略的方式将拓展形式博弈游戏用收益矩阵表达,但会丧失掉部分时序关系。
4-9 Mixed and Behavioral Strategies
- 在不完美信息拓展形式中有两种不同的随机策略,分别是mixed strategies 混合策略、behavioral strategies 行为策略。混合策略是针对于所有纯策略的概率分布,而行为策略是指针对每一步决策的概率分布。
- 让我们观察以下博弈树:
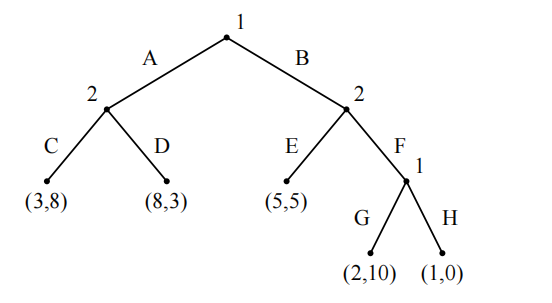
我们来举一个属于行为决策的例子:A在第一次决策时有0.5的概率选择A;在第二次决策时有0.3的概率选择G,这样就构成了决策者A的一个行为决策。
我们再来举一个属于混合策略的例子:A的纯策略为 { ( A , G ) , ( A , H ) , ( B , G ) , ( B , H ) } \{(A,G),(A,H),(B,G),(B,H)\} {
(A,G),(A,H),(B,G),(B,H)},A的纯策略分布为 { 0.6 ( A , G ) , 0.4 ( B , H ) } \{0.6(A,G),0.4(B,H)\} {
0.6(A,G),0.4(B,H)}。
并且在这场游戏中,每一个行为策略都可以转化成一个混合策略(只需要根据分步概率分布计算出纯策略的概率分布即可)。 - 不完美信息博弈中的混合策略和行为策略
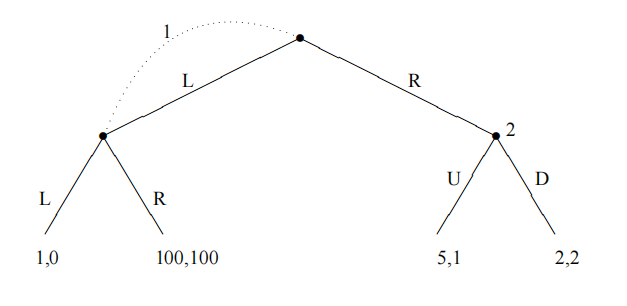
由图中虚线得知,决策者1只有一个决策等价类,该等价类包含两个选择节点,两个选择节点隶属于同一决策者并有相同的可选动作集。可以理解为决策者1同时发送了两个代理,一个代理构成一个选择节点,两个代理节点不知彼此谁先到达,拥有相同的可选动作集对于下一步来说是不可分辨的。
决策者1的纯策略为 { L , R } \{L,R\} {
L,R};决策者2的纯策略为 { U , D } \{U,D\} {
U,D}。
那么本博弈游戏中的混合策略均衡是什么呢?针对于决策者2,选择D对于选择U来说是占优的,因此决策者2一定会选择D而不是U。在基于决策者2选择D的前提下,决策者1选择L收益为1,决策者1选择R收益为2,因此最终的均衡点为 ( R , D ) (R,D) (R,D)。
那么本博弈游戏中的行为策略均衡是什么呢?针对决策者2来说,D还是相对于G占优的,因此我们设置决策者2选择 ( U , D ) (U,D) (U,D)的概率分布为 ( 0 , 1 ) (0,1) (0,1)。针对于决策者1,我们设置选择 ( L , R ) (L,R) (L,R)的概率分布为 ( p , 1 − p ) (p,1-p) (p,1−p),那么决策者1的收益为:
p 2 + 100 p ( 1 − p ) + 2 ( 1 − p ) = − 99 p 2 + 98 p + 2 p^2+100p(1-p)+2(1-p)=-99p^2+98p+2 p2+100p(1−p)+2(1−p)=−99p2+98p+2,极大值位于 p = 98 / 198 p=98/198 p=98/198
那么行为策略均衡为 ( L , R ) , ( U , D ) = ( 98 / 198 , 100 / 198 ) , ( 0 , 1 ) (L,R),(U,D)=(98/198,100/198),(0,1) (L,R),(U,D)=(98/198,100/198),(0,1)
可以看出针对于同一场博弈游戏,选择行为策略还是混合策略,所达到的均衡可能是不同的。
4-10 Incomplete Information in the Extensive Form:Beyond Subgame Perfection
- 在不完美信息博弈游戏中,由于决策者之间信息的闭塞性可能并不存在许多合理的子博弈,每个决策者并不清楚自己在博弈树中的位置。传统的推理方法比如反向归纳法并不适用于不完美信息博弈,但是我们可以拓展子博弈完美的推理过程。
- 让我们用拓展的子博弈完美理论来分析如下博弈:
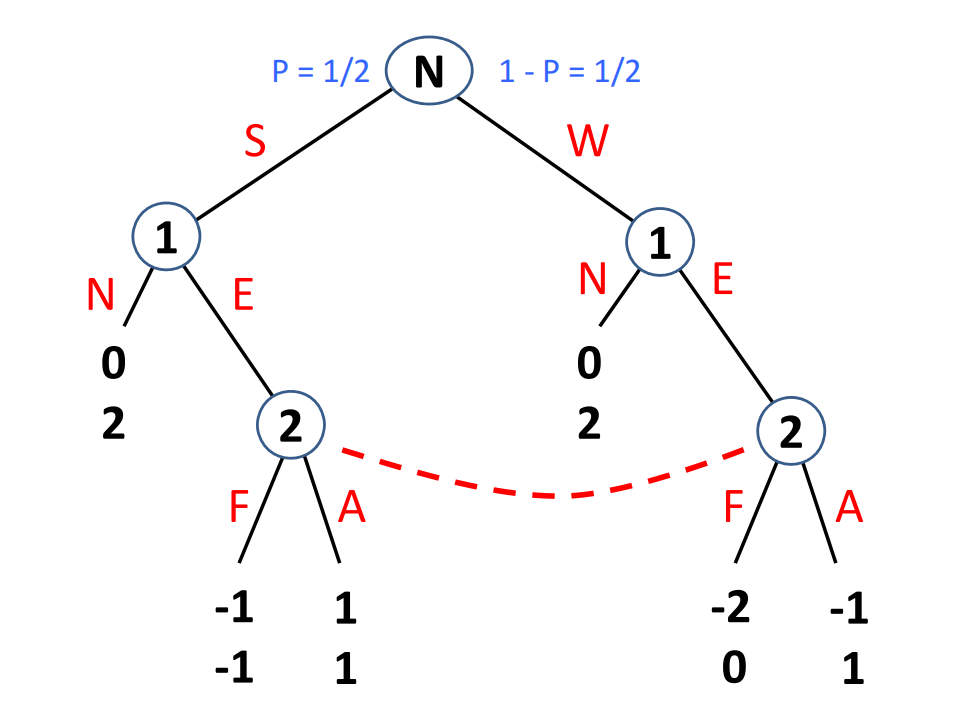
博弈游戏背景:公司1是一个市场的外来竞争者,公司2是市场内本来就存在的公司。由自然决定,公司1有一半的可能是一个实力强劲的公司,对应一半的可能是一个实力虚弱的公司。公司1选择是否进入市场,公司2选择是抗争还是顺其自然,并且根据公司1的实力性质,相同决策的收益可能不同。
传统的子博弈完美理论需要单独摘出一个子博弈来,但是该博弈树中,由于决策者2的两个选择节点由虚线连接,那么我们就无法实现任何的单独分割,最小的子博弈就是整个博弈。因此子博弈完美骑士就是整个游戏的纳什均衡。
我们终于理解如何将子博弈完美理论拓展应用到不完美信息博弈中。不完美信息博弈树中其实就是多了几条虚线,将多个选择节点连接成一个等价类,因此不完美信息中的子博弈只是划分的范围更大,子博弈内部的分析方法相同。 - 均衡概念实际上就是针对于每个决策者对于自己处于博弈树中位置的信念做了精确的建模分析。
- Sequential Equilibrium 序贯均衡、Perfect Bayesian Equilibrium完美贝叶斯均衡。
5-1 Repeated Games
- 博弈论的本质是教你如何制定规则。我们学习了本章节的重复博弈后就会对这句话有所了解。在单次博弈中,决策者只需要保证这一次的收益即可,选择背叛并没有惩罚与报复,而在重复博弈中,我们就不能只考虑眼前的利益,而要考虑多次重复博弈的总收益。重复博弈不单单是多次单次博弈的组合,正因为重复的存在使得决策选择有了极大改变。
- 油价博弈中的重复博弈思想。中东国家每次可以选择自己的开采油量。市面上油量越小,油价就会越高。某个国家选择减少开采油量,可能是为了长远考虑,继续哄抬油价;某个国家选择增加开采油量,可能是为了现实考虑,想最大化当前利益。因此油价博弈并不是一个静态的单次博弈,而是一个动态博弈,需要长远考虑,彼此协商制定规则,最大化总体利益。
5-2 Infinitely Repeated Games:Utility
- Infinitely Repeated Games 无限次重复博弈是不存在可作为最后一阶段的最后一次博弈, 这使得普通的逆推归纳法无法直接运用。
- 本章节我们来学习一下无限重复游戏中的效用定义。
- 回想一下之前一般形式与拓展形式中的效用表示方法。
我们可以用拓展形式来表达这种博弈吗?不可以,因为博弈树会无限深,看不到叶子节点。
我们可以计算所有单次效用的总和吗?不可以,因为无限不可求和计算。 - Average Reward 平均收益
Give an infinite sequence of payoffs r 1 , r 2 , . . . r_1,r_2,… r1,r2,...for player i i i,the average reward of i i i is
lim k → ∞ ∑ j = 1 k r j k \lim_{k \to \infty} \sum_{j=1}^k \frac{r_j}{k} limk→∞∑j=1kkrj。
观察上式可得,每次博弈的收益都会除以一个比例 k k k加入到总和中。随着博弈次数 k k k的增加,该次博弈的收益在收益总和中所占的比例越来越小。表明了,无线重复博弈更看重近次博弈,忽视远视博弈。
- Future Discounted Reward 未来折扣收益
Give an infinite sequence of payoffs r 1 , r 2 , . . . r_1,r_2,… r1,r2,...for player i i i and discount factor β \beta β with 0 < β < 1 0<\beta <1 0<β<1,the future discounted reward of i i i is
∑ j = 1 ∞ β j r j \sum_{j=1}^\infty \beta^jr_j ∑j=1∞βjrj。
针对该效用定义有两种理解方式。第一种理解,每次博弈所获得的效用都要乘以 β j \beta^j βj衰减,也就表明该游戏更看重近次博弈忽视远次博弈。第二种理解,代理者针对近次、远次博弈同样看重,不分轻重,只不过每次博弈游戏都有 β \beta β的概率延续到下一次,有 1 − β 1-\beta 1−β的概率终结于此。
5-3 Stochastic Games
- 本章节我们来学习一下Stochastic Games 随机博弈。随机博弈是指多个参与者参与的无线博弈,只不过并不是每次重复博弈,而是每次产生一个新的博弈状态。根据当前决策者状态以及选择的动作,决定下一阶段的博弈状态。
- 图示理解重复博弈与随机博弈。
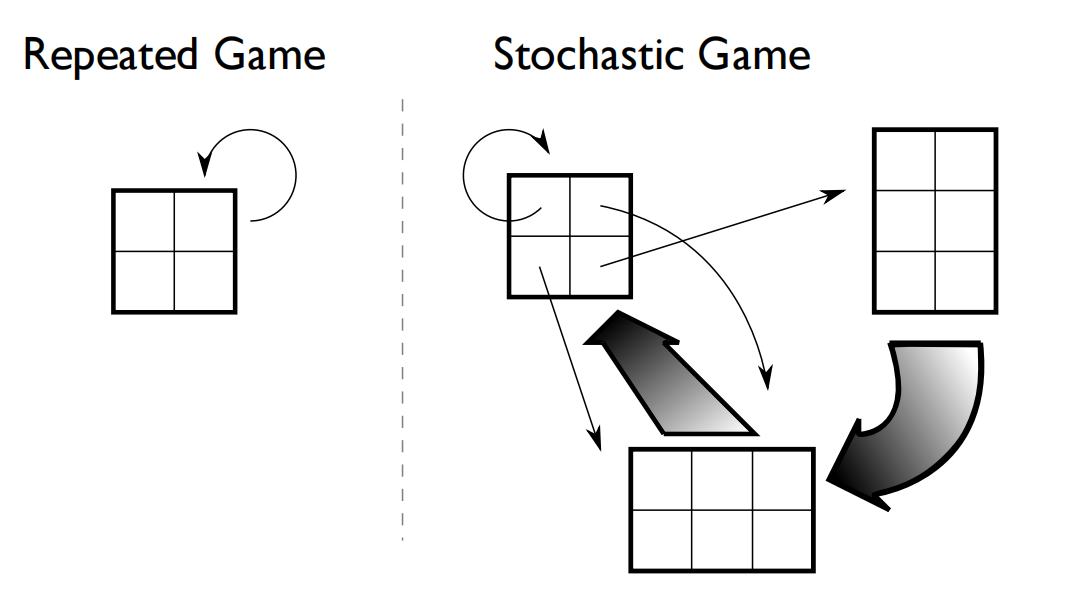
重复博弈是重复进行相同的博弈游戏,而随机博弈是在多个博弈游戏之间切换。 - 随机博弈的形式化定义
A stochastic game is a tuple( Q , N , A , P , R Q,N,A,P,R Q,N,A,P,R),where
Q Q Q is a finite set of states,有限的状态集
N N N is a finite set of n n n players,有限的决策者集合
A = A 1 × . . . × A n A=A_1\times…\times A_n A=A1×...×An,where A i A_i Ai is a finite set of actions available to player i i i,每个决策者的可能行动有限集合
P : Q × A × Q → [ 0 , 1 ] P:Q\times A \times Q \to [0,1] P:Q×A×Q→[0,1]is the transition probability function; P ( q , a , q ′ ) P(q,a,q^{‘} ) P(q,a,q′)is the probability of transitioning from state q q q to state q ′ q^{‘} q′after joint action a a a,and状态迁移概率
R = r 1 , . . . , r n R=r_1,…,r_n R=r1,...,rn,where r i : Q × A → R r_i:Q\times A\to R ri:Q×A→R is a real-valued payoff function for player i i i.决策者决策收益
- 类比于上一章节的无限重复博弈,我们也可以定义随机博弈中的limit average reward 极限平均收益与future discount reward 未来折扣收益。
5-4 Learning in Repeated Games
- 本章节会介绍重复博弈中的两种学习形式,一种是Fictitious Play 虚拟博弈,另一种是No-regret Learning 无后悔学习。总体来说,博弈论中的学习是一个涵盖广泛的课题。博弈论中的“学习”与机器学习、深度学习中的“学习”有本质的不同。
- Fictitious Play 虚拟博弈
虚拟博弈方法最初提出是为了计算纳什均衡的。虚拟的意思是指我们并不实际进行多次重复博弈的过程,而是根据策略去模拟,通过模拟计算纳什均衡。大体思路如下:每个决策者针对其他对手的策略分布都生成一个信念,虚拟博弈的每次迭代过程都根据当前信念选择自己的最优响应,然后根据其他对手的决策情况,动态更新策略分布,最后该算法会收敛于纳什均衡。
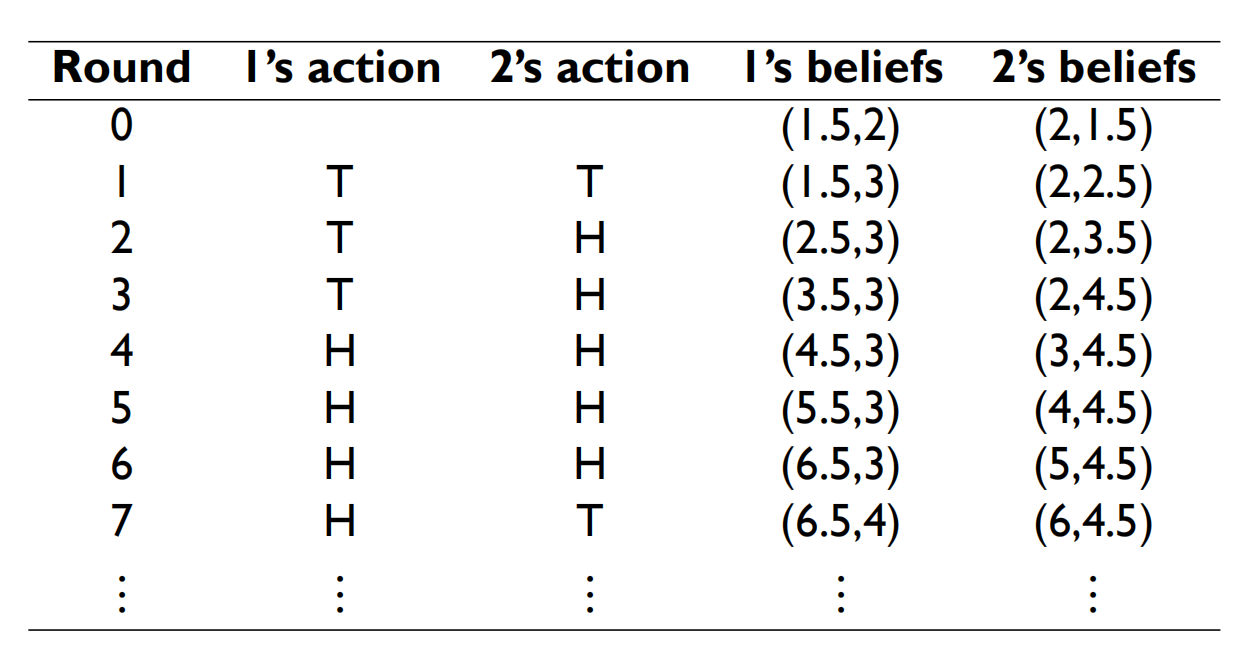
我们来仔细分析一下上图所示的例子:
游戏名称:Matching Pennies 便士配对游戏
游戏背景:玩家1、玩家2每次可以选择亮出一枚硬币的H面或者T面。如果两枚硬币是相同的面,那么玩家1获胜;如果两枚硬币是相反的面,那么玩家2获胜。
图示注解:Round是指虚拟博弈的轮数。1’s action、2’s action分别是该轮次玩家1、2针对对手历史决策做出的最优响应。1’s beliefs、2’s beliefs分别是该轮次玩家1、2针对对手策略分布的估计或者统计。
博弈过程:
第0轮:玩家1初始化自己对于玩家2的策略比重设想为(1.5,2),玩家2初始化自己对于玩家1的策略比重设想为(2,1.5)。
第1轮:玩家1根据上一轮的设想认为玩家2更大概率会出T面,为了使两面硬币同面而获利,玩家1选择出T面。玩家2根据上一轮的设想认为玩家1更大概率会出H面,为了使两面硬币反面而获利,玩家2选择出T面。然后根据该轮决策结果更新玩家1、2的设想。
。。。
第n轮:最终该算法会收敛到某一个纳什均衡。 - 虚拟博弈理论
如果每个玩家策略的经验分布在虚拟博弈中都收敛,那么最终会收敛到一个纳什均衡点。
满足以下条件之一的博弈游戏会在虚拟博弈中经验分布收敛,也就是说可以通过虚拟博弈的方法求得一个纳什均衡点:
1.该博弈是一个零和博弈。
2.该博弈是一个可通过严格占优策略主导的迭代消除法解决的博弈游戏。
3.该博弈是一个势博弈(每个个体收益的改变能够映射到一个全局函数上,这个函数叫做势函数)。
4.该博弈是一个2xn的并且拥有通用回报。
虚拟博弈的局限性:在许多博弈中如果存在多个纳什均衡,则虚拟博弈收敛的结果会由收益矩阵和初始策略有关,并不能保证收敛到“最优均衡”。 - No-regret Learning 无悔学习
首先我们来定义什么叫作后悔与无悔学习规则。
The regret an agent experiences at time t t t for not having played s s s is R t ( s ) = α t ( s ) − α t R^t(s)=\alpha^t(s)-\alpha^t Rt(s)=αt(s)−αt.
某个决策者在时间点 t t t未选择策略 s s s的后悔程度是,在时间点 t t t假设选择策略 s s s的收益减去实际的收益。
A learning rule exhibits no regret if for any pure strategy of the agent s s s it holds that P r ( [ l i m i n f R t ( s ) < = 0 ] ) = 1 Pr([lim \space infR^t(s)<=0])=1 Pr([lim infRt(s)<=0])=1
用中文解释来说就是,在时间点 t t t选择策略 s s s的后悔程度小于等于0的概率上极限为1。
具体的迭代学习方法是:
σ i t + 1 ( s ) = R t ( s ) ∑ s ′ ∈ S i R t ( s ′ ) \sigma_i^{t+1}(s)=\frac{R^t(s)}{\sum_{s^{‘}\in S_i}R^t(s^{‘})} σit+1(s)=∑s′∈SiRt(s′)Rt(s),每次迭代根据本轮不同决策选择后悔程度占总体的比例来调整下一次策略选择的概率分布。
5-5 Equilibria of Infinitely Repeated Games
- 本章节聚焦学习的是无限重复博弈中的均衡问题。
- 无限重复博弈中的纯策略是如何定义的呢?在之前学习过的一种动态博弈——完美信息博弈中,纯策略是指每个选择节点可选策略的笛卡尔积。在无限重复博弈中并没有选择节点的概念,取而代之的是一个个博弈阶段,因此纯策略可以定义为每个博弈阶段可选策略的笛卡尔积。无限重复博弈有无限个博弈阶段,因此纯策略也是无限大小的。
- 无限重复博弈中的两种博弈策略:
1.Tit-for-tat 针锋相对式。初始策略为合作,如果对手选择合作则一直选择合作。如果对手背叛,那么会在下一轮中同样选择背叛对手。但在此之后又会重新选择合作。
2.Trigger 触发器式。初始策略为合作,如果对手选择合作则一直选择合作。如果对手背叛,那么之后会一直选择背叛来惩罚对手。 - 无限重复博弈中有无限个纯策略,我们无法将其表示成收益矩阵的方式来计算寻找纳什均衡点。因此纳什均衡理论只应用于有限博弈,换句话说无限重复博弈中不存在纳什均衡。另外,无限重复博弈中有无限个纯策略,因此可能存在无限个纯策略均衡。
- Enforceable与Feasible的相关定义
Consider any n-player game G = ( N , A , u ) G=(N,A,u) G=(N,A,u) and any payoff vector r = ( r 1 , r 2 , . . , r n ) r=(r_1,r_2,..,r_n) r=(r1,r2,..,rn)在这里的 r i r_i ri我们采用的是平均收益算法(详情请见上文)
Let v i = m i n s − i ∈ S − i m a x s i ∈ S i u i ( s − i , s i ) v_i=min_{s_{-i}\in S_{-i}}max_{s_i\in S_i}u_i(s_{-i},s_i) vi=mins−i∈S−imaxsi∈Siui(s−i,si)。 v i v_i vi是 i i i的minmax值,具体是指其他决策者都尽可能损害 i i i的利益时, i i i采取决策最大化自己的利益所能获得的利益。
A payoff profile r r r is enforceable if r i > = v i r_i>=v_i ri>=vi。如果每一位决策者的实际收益都大于其minmax值,那么我们称之为enforceable。
A payoff profile r r r is feasible if there exist rational,non-negative values α a \alpha_a αasuch that for all i i i,we can express r i r_i ri as ∑ a ∈ A α a u i ( a ) \sum_{a\in A}\alpha_au_i(a) ∑a∈Aαaui(a),with ∑ a ∈ A α a = 1 \sum_{a\in A}\alpha_a=1 ∑a∈Aαa=1。如果某种收益数值可以表示为所有可能决策收益的加权和,那么我们称之为feasible。
- 无名氏定理 Folk Theorem
为什么叫Folk Theorem?就像是Folk Song民歌一样,大家广为流传但是不知道具体的出处。Folk Theorem大家都普遍认可但是不知道这条定理的来源。
1.如果收益向量 r r r是某个无限重复博弈 G G G中某个纳什均衡的收益(用平均收益算法表示),那么针对每个决策者 i i i, r i r_i ri都是enforceable的。
2.如果收益向量 r r r既是feasible又是enforceable的,那么 r r r一定是某个无限重复博弈 G G G中某个纳什均衡的收益(用平均收益算法表示)。 - Payoff in Nash → \to → enforceable
证明:我们假设某个纳什均衡的收益向量不是enforceable,存在某个决策者 i i i, r i < v i r_i<v_i ri<vi。那么根据minmax策略,决策者 i i i可以选择最佳策略将自己的收益提高到至少 v i v_i vi,这样就违背了纳什均衡的概念,存在了一种决策偏离方式使得决策者可以获得更大收益。 - Feasible and enforceable → \to → Nash
证明:总结来说就是如果收益向量 r r r既是feasible的又是enforceable的,那么无限次数重复博弈下,都会发现合作才是最优的决策方式,因此符合了纳什均衡的定义。也就是说,虽然短期来看背叛可能会获得更高的收益,但是考虑到背叛之后的惩罚以及博弈游戏是无限性质的,最终还是选择合作会带来最高的收益。因此对于长远来看,选择合作才是符合纳什均衡的。
5-6 Discounted Repeated Games
- 本章节我们学习折扣重复博弈。
- 未来是不确定的,我们通常都是被今天发生的事情所激励,间接影响明天的决策。有关今天与未来的平衡会直接影响我们今天的决策。选择背叛的代价如何?其他决策者是否关心?我又是否关心未来的利益?
- Discounted Repeated Games 折扣重复博弈 相关定义
Stage game: ( N , A , u ) (N,A,u) (N,A,u)
Discount factors: β 1 , . . . , β n , β i ∈ [ 0 , 1 ] \beta_1,…,\beta_n,\beta_i\in[0,1] β1,...,βn,βi∈[0,1](下标代表的是决策者的编号,我们这里考虑每个决策者的折扣因子都是固定的)
Payoff from a play of actions a 1 , . . . , a t , . . . : ∑ t β i t u i ( a t ) a^1,…,a^t,…:\sum_t \beta_i^tu_i(a^t) a1,...,at,...:∑tβitui(at)(下标代表决策者编号, β i t \beta_i^t βit代表第i个决策者第t个阶段折扣因子为t次方, a t a^t at代表第t个阶段采取的动作)
折扣因子的作用是使得在最终的收益计算中,越靠后的博弈轮次其重要性越来越小。也就是重复博弈更看重较早的博弈轮次。
- 重复博弈中 Histories 历史的相关定义
所谓历史,就是所有决策者在各个博弈阶段所作出的决策记录。
Histories of length t t t: H t = { h t : h t = ( a 1 , . . . , a t ) ∈ A t } H^t=\{h^t:h^t=(a^1,…,a^t)\in A^t\} Ht={
ht:ht=(a1,...,at)∈At}
All finite histories: H = ∪ t H t H=\cup_t H^t H=∪tHt
A strategy: s i : H → Δ ( A i ) s_i:H\to \Delta(A_i) si:H→Δ(Ai)
举个例子说明一下,囚徒博弈背景中。
A i = { C , D } A_i=\{C,D\} Ai={
C,D}两个决策者的候选动作都是 { C , D } \{C,D\} {
C,D}
三个博弈阶段以后的历史: ( C , C ) , ( C , D ) , ( D , D ) (C,C),(C,D),(D,D) (C,C),(C,D),(D,D)
那么第四阶段的决策就根据前三阶段的历史所决定。
- 囚徒困境中的重复博弈分析
假设我们的决策者都采用Trigger的决策方式(即一次不忠永不录用,也就是如果对方背叛则自己永远选择背叛)。我们来分析一下不同收益矩阵下,选择合作或者背叛的不同收益。
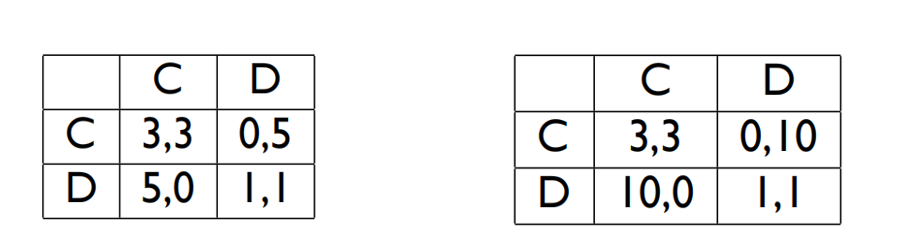
首先我们来计算左边的收益矩阵。假设在某次决策之前,双方都一直严格选择合作。
该轮次选择合作: 3 + β 3 + β 2 3 + β 3 3… = 3 1 − β ( l i m n → ∞ 1 + β + β 2 + . . . + β n = 1 1 − β ) 3+\beta3+\beta^23+\beta^33…=\frac{3}{1-\beta}(lim_{n\to \infty}1+\beta+\beta^2+…+\beta^n=\frac{1}{1-\beta}) 3+β3+β23+β33...=1−β3(limn→∞1+β+β2+...+βn=1−β1)
该轮次选择背叛: 5 + β 1 + β 2 1 + β 3 1… = 5 + β 1 1 − β 5+\beta1+\beta^21+\beta^31…=5+\beta\frac{1}{1-\beta} 5+β1+β21+β31...=5+β1−β1
上下差值: − 2 + β 2 + β 2 2 + β 3 2… = β 2 1 − β − 2 -2+\beta2+\beta^22+\beta^32…=\beta\frac{2}{1-\beta}-2 −2+β2+β22+β32...=β1−β2−2
令 β 2 1 − β − 2 > = 0 \beta\frac{2}{1-\beta}-2>=0 β1−β2−2>=0得 β > = 1 2 \beta>=\frac{1}{2} β>=21,因此只有 β \beta β大于等于1/2时该轮次选择合作得总体收益才大于选择背叛。计算右边得收益矩阵,唯一区别在于提高了“成功背叛”(即自己背叛,对方合作)时的收益,计算结果是当 β > = 7 / 9 \beta>=7/9 β>=7/9时,合作收益才大于背叛收益。
分析:折扣因子 β \beta β越接近于1,代表未来阶段的博弈基本跟当前博弈同等重要,也就是说背叛的代价更大,留给被背叛者“报复”的机会更多。右边的收益矩阵比左边的收益矩阵,其成功背叛的收益更大,大到因这一次背叛获利可能抵消未来一部分的报复失利。成功背叛的收益越大,想要让合作收益大于背叛收益,折扣因子 β \beta β就要越大。 β \beta β接近于0时,重复博弈退化为单次博弈,即后续博弈毫无作用,我们只需要关心单次博弈的收益即可,那么背叛无疑是最好选择。
5-7 A Folk Theorem for Discounted Repeated Games
- 何为博弈的正则形式与拓展形式?
与延展形式不同,正则形式不用图形来描述博弈,而是用矩阵来描述博弈。与延展形式的表述方式相比,这种方式在识别出严格优势策略和纳什均衡上更有用,但会丢失某些信息 。
纳什均衡只要求均衡战略在均衡路径的决策结上是最优的,而构成子博弈精炼纳什均衡不仅要求在均衡路径上策略是最优的,而且在非均衡路径上的决策结也是最优的。 - 有限重复博弈中的两个定理:
1.在有限重复博弈的最终阶段,决策者们一定会选择纳什均衡,因为有限重复博弈的最终阶段相当于一个单次同时博弈。
2.如果每个阶段都选择纳什均衡的话,最终会得到一个子博弈完美的纳什均衡。(但不一定是唯一的子博弈完美纳什均衡)可以根据反向归纳法分析。 - 对于惩罚策略的Trigger来说是一个纳什均衡,由于无限重复博弈的每一个子博弈都跟本体结构相同,因此只要折扣因子大于一定数值,整体的纳什均衡就是子博弈完美的纳什均衡。
- 单次博弈与有限次重复博弈都无法使得囚徒困境走出较差的均衡点,而无名氏定理证明:在无限重复博弈中存在子博弈完美的纳什均衡使得双方同时获得最大收益。比如说囚徒困境中,只要折扣因子大于一定数值,理性的决策者通过计算分析,就会在无限次重复博弈中选择合作而不是背叛。
- 证明:当折扣因子足够大(接近于1)时,Trigger惩罚策略是一个子博弈完美的纳什均衡。
- 总结来说,无名氏定理讲了这么一件事。当折扣因子足够大,也就是说未来阶段博弈足够重要,背叛的代价足够大的时候,存在子博弈完美的纳什均衡,使得理性决策者仔细计算权衡收益后,选择一直合作而不是背叛。
6-1 Bayesian Games:Taste
- 本章节我们正式开始学习贝叶斯博弈。
- 本章节举了一系列拍卖 Auctions的例子引出贝叶斯博弈。这些例子的共同点在于物品的价值是不可确定的,因此通过拍卖的形式确定价格。贝叶斯博弈就是用来建模分析这一类过程,最大的特点就是:效用函数不确定。
- 贝叶斯博弈是继正则形式博弈、拓展形式博弈之后的第三种博弈游戏表达形式。
6-2 Bayesian Games:First Definition
- 贝叶斯博弈其实就是不完美信息博弈(包括动态与静态)。
- 之前我们学习的博弈过程,博弈的决策者们都知道自己以及对手的类型,以及博弈游戏的规则收益。但是在贝叶斯博弈中,自己以及对手的类别不确定,只是有一定的先验知识,并且可以根据实际博弈情况产生后验知识修正。决策者类别不确定,博弈的游戏类别就不确定,博弈的收益矩阵就无法确定。
- 贝叶斯博弈的定义(Information Set):贝叶斯博弈是一系列博弈游戏,这些游戏独特在效用函数、共同的先验分布以及针对每一个决策者的划分结构。
A Bayesian game is a tuple ( N , G , P , I ) (N,G,P,I) (N,G,P,I) where
N N N是代理者的集合。
G G G是一系列博弈游戏的集合。每个游戏由元组 G = ( N , A , u ) G=(N,A,u) G=(N,A,u)定义,同一G中的博弈游戏仅仅是 u u u不同。也就是说拥有相同的代理者集合以及可选决策集合。
P P P是针对 G G G中每一个博弈游戏的先验概率。
I = ( I 1 , . . . , I N ) I=(I_1,…,I_N) I=(I1,...,IN)。 I I I是划分的集合。 I 1 I_1 I1代表第一个决策者对于 G G G的等价类划分,划分成多个等价类,等价类内部的游戏不可区分。
- 让我们看一个贝叶斯博弈的例子:
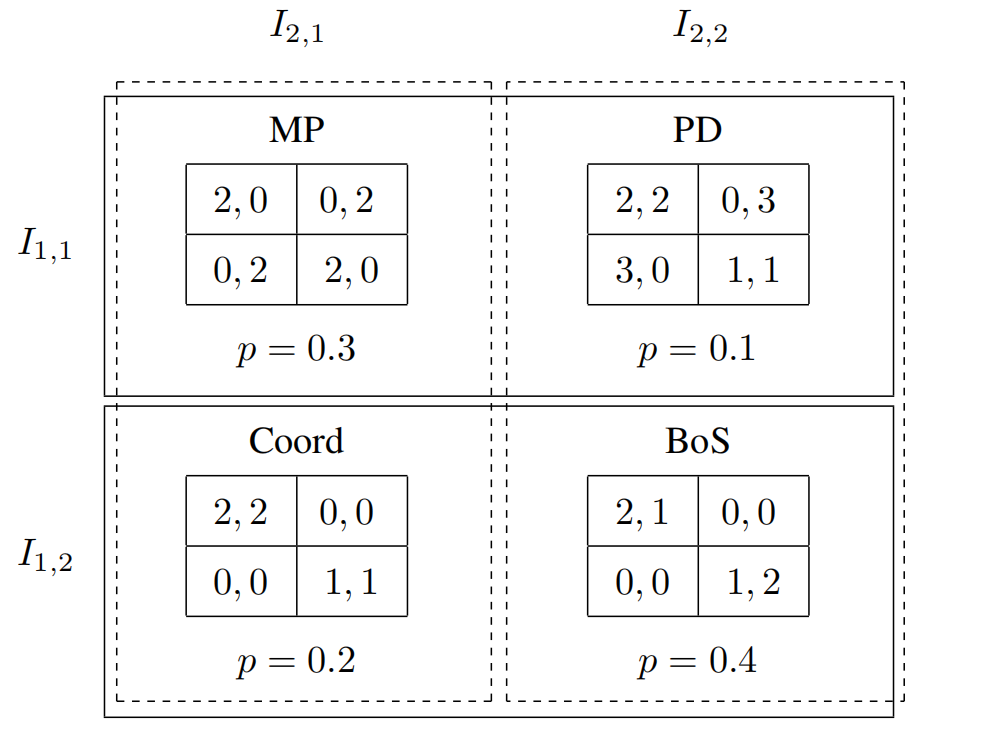
该游戏共有2个决策者,4个博弈游戏。我们来看一下该贝叶斯博弈的形式化表示:
G = { M P , P D , C o o r d , B o S } G=\{MP,PD,Coord,BoS\} G={
MP,PD,Coord,BoS}
P = { 0.3 , 0.1 , 0.2 , 0.4 } P=\{0.3,0.1,0.2,0.4\} P={
0.3,0.1,0.2,0.4}
I = { I 1 , I 2 } , I 1 = { I 1 , 1 , I 1 , 2 } = { { M P , P D } , { C o o r d , B o S } } I=\{I_1,I_2\},I_1=\{I_{1,1},I_{1,2}\}=\{\{MP,PD\},\{Coord,BoS\}\} I={
I1,I2},I1={
I1,1,I1,2}={
{
MP,PD},{
Coord,BoS}}
6-3 Bayesian Games:Second Definition
- 贝叶斯博弈的第二种定义(Epistemic Types 认知类型):
A Bayesian game is a tuple ( N , A , Θ , p , u ) (N,A,\Theta,p,u) (N,A,Θ,p,u) where
N N N是代理者的集合。
A = ( A 1 , . . . , A n ) A=(A_1,…,A_n) A=(A1,...,An), A 1 A_1 A1代表第一个决策者的可选动作集合。
Θ = ( Θ 1 , . . . , Θ n ) \Theta=(\Theta_1,…,\Theta_n) Θ=(Θ1,...,Θn),假设决策者1有三个类型 Θ 1 = ( Θ 1 , 1 , Θ 1 , 2 , Θ 1 , 3 ) \Theta_1=(\Theta_{1,1},\Theta_{1,2},\Theta_{1,3}) Θ1=(Θ1,1,Θ1,2,Θ1,3)
p : Θ → [ 0 , 1 ] p:\Theta \to [0,1] p:Θ→[0,1],每个决策者属于每种类别的先验分布
u = ( u 1 , . . . , u n ) , w h e r e u i : A × Θ → R u=(u_1,…,u_n),where \space u_i:A\times \Theta \to R u=(u1,...,un),where ui:A×Θ→R。一组动作组合+一组类别组合才能确定一组效用组合。
-
我们来看一下上一章节中贝叶斯博弈的认知类型定义形式(一组动作组合( a 1 , a 2 a_1,a_2 a1,a2)+一组类别组合( θ 1 , θ 2 \theta_1,\theta_2 θ1,θ2)才能确定一组效用组合( u 1 , u 2 u_1,u_2 u1,u2)
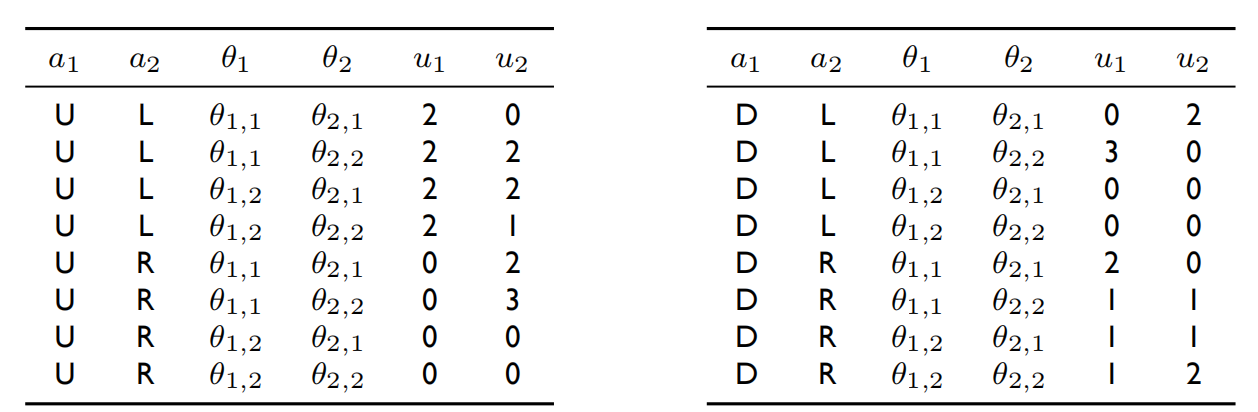
-
最后总结一下,有关贝叶斯博弈(不完美信息博弈)的两种定义方式都是为了针对效用函数的不确定性建模。第一种信息集合的定义方式,将每个决策者对博弈游戏种类的认知进行划分,而第二种认知类型的定义方式,直接对决策者的类型进行划分。实际上两种定义方式的效果相同,思路相近。(不太明白为何要设计两种定义方式)
6-4 Analyzing Bayesian Games
- 本章节我们将纳什均衡拓展到贝叶斯纳什均衡。
- 不完美信息与不完全信息的关系:
1.不完全信息指的是对各方收益函数的不了解或者说对于各方的认知类型不了解(贝叶斯博弈也成为不完全信息博弈);不完美信息指的是决策者对之前其他决策者行动情况的不了解,多存在于动态博弈中。
2.两个概念并不存在包含与被包含关系,是评价博弈的两个不相关方面,可能存在完美但不完全的博弈,也可能存在完全但不完美的博弈。
3.海萨尼转换可以将不完全信息博弈转化为一个不完美但完全信息的博弈。 - 纳什均衡拓展到贝叶斯纳什均衡
针对完全信息博弈,只需要根据决策者策略便可以求解纳什均衡。但是在贝叶斯博弈(不完全信息博弈)中,我们不仅需要根据决策者策略还需要根据决策者的认知类型来求解纳什均衡。
(一组决策组合+一组认知类型组合 → \to →一组效用组合) - 贝叶斯博弈中的策略
Given a Bayesian game ( N , A , Θ , p , u ) (N,A,\Theta,p,u) (N,A,Θ,p,u) with finite sets of players,actions,and types,strategies are defined as follows:(采用认知类型定义方式,均为有限集合)
Pure strategy: s i : Θ i → A i s_i:\Theta_i\to A_i si:Θi→Ai
Mixed strategy: s i : Θ i → Π ( A i ) s_i:\Theta_i\to \Pi(A_i) si:Θi→Π(Ai)
s i ( a i ∣ θ i ) s_i(a_i|\theta_i) si(ai∣θi):决策者 i i i类型为 θ i \theta_i θi的条件下,选择动作 a i a_i ai的概率
- 三种效用期望的定义方式
ex-ante:决策者对于任何人的认知类型都不知道。
interim:决策者只知道自己的认知类型,不知道其他决策者的认知类型。
ex-post:决策者知道所有决策者的认知类型。(退化成了完全信息博弈) - Interim expected utility Interim方式定义的效用期望
E U i ( s ∣ θ i ) = ∑ θ − i ∈ Θ − i { p ( θ − i ∣ θ i ) × ∑ a ∈ A [ Π j ∈ N s j ( a j ∣ θ j ) × u i ( a , θ i , θ − i ) ] } EU_i(s|\theta_i)=\sum_{\theta_{-i}\in \Theta_{-i}}\{p(\theta_{-i}|\theta_i) \times \sum_{a\in A}[\Pi_{j\in N}s_j(a_j|\theta_j)\times u_i(a,\theta_i,\theta_{-i})]\} EUi(s∣θi)=∑θ−i∈Θ−i{
p(θ−i∣θi)×∑a∈A[Πj∈Nsj(aj∣θj)×ui(a,θi,θ−i)]}
这个式子极其复杂,让我们来详细剖析一下。
首先从外到内一共三层循环:
1. ∑ θ − i ∈ Θ − i \sum_{\theta_{-i}\in \Theta_{-i}} ∑θ−i∈Θ−i:在确定 Θ i = θ i \Theta_i=\theta_i Θi=θi的前提下,遍历其他决策者 − i -i −i的所有认知类型组合情况 θ − i = ( θ 1 , θ 2 , . . . , θ i − 1 , θ i + 1 , . . . , θ n ) \theta_{-i}=(\theta_1,\theta_2,…,\theta_{i-1},\theta_{i+1},…,\theta_n) θ−i=(θ1,θ2,...,θi−1,θi+1,...,θn)。因此在内层循环中相当于所有决策者认知类型都已知。
2. ∑ a ∈ A \sum_{a\in A} ∑a∈A:遍历所有可能的动作组合。 a = ( a 1 , a 2 , . . . , a n ) a=(a_1,a_2,…,a_n) a=(a1,a2,...,an)。因此在内层循环,相当于所有决策者的认知类型以及动作均已知。
3. Π j ∈ N \Pi_{j\in N} Πj∈N:遍历所有的决策者,因为要计算外层循环动作组合 a a a产生的概率。
接下来我们看一看各个步骤分别求的是什么?
1. Π j ∈ N s j ( a j ∣ θ j ) \Pi_{j\in N}s_j(a_j|\theta_j) Πj∈Nsj(aj∣θj):决策者 j j j在已知类型为 θ j \theta_j θj时选择动作 a j a_j aj的概率,乘积就是外层循环策略组合 a a a的生成概率。
2. u i ( a , θ i , θ − i ) u_i(a,\theta_i,\theta_{-i}) ui(a,θi,θ−i):已知所有的认知类型以及所有人的动作选择后的效用值。
3. ∑ a ∈ A [ Π j ∈ N s j ( a j ∣ θ j ) × u i ( a , θ i , θ − i ) ] \sum_{a\in A}[\Pi_{j\in N}s_j(a_j|\theta_j)\times u_i(a,\theta_i,\theta_{-i})] ∑a∈A[Πj∈Nsj(aj∣θj)×ui(a,θi,θ−i)]:在已知所有人认知类型的前提下,所有动作组合的期望效用。
4. p ( θ − i ∣ θ i ) p(\theta_{-i}|\theta_i) p(θ−i∣θi):在已知 Θ i = θ i \Theta_i=\theta_i Θi=θi的前提下,其他决策者类型为 θ − i \theta_{-i} θ−i的概率。
5.总体:在仅仅已知自己认知类型的前提下,遍历所有混合策略组合、遍历所有其他决策者认知类型的效用期望。 - ex-ante expected utility ex-ante 方式定义的效用期望
E U i ( s ) = ∑ θ i ∈ Θ i p ( θ i ) E U i ( s ∣ θ i ) EU_i(s)=\sum_{\theta_i\in \Theta_i}p(\theta_i)EU_i(s|\theta_i) EUi(s)=∑θi∈Θip(θi)EUi(s∣θi)
ex-ante方式定义的效用期望利用了上述Interim方式定义。ex-ante不知道自己的认知类型,那就遍历自己的所有认知类型就可以了,然后算总体的期望,也就是从3层循环变成了4层循环。 - Bayes-Nash Equilibrium 贝叶斯纳什均衡
s i ∈ a r g m a x s i ′ E U i ( s i ′ , s − i ∣ θ i ) s_i\in argmax_{s_i^{‘}}EU_i(s_i^{‘},s_{-i}|\theta_i) si∈argmaxsi′EUi(si′,s−i∣θi)(Interim方式定义)
决策者 i i i的贝叶斯纳什均衡混合策略 s i s_i si就是,在其他人的混合策略 s − i s_{-i} s−i不改变的情况下,已知自己的认知类型的前提下,最大化自己的效用期望所对应的混合策略。
s i ∈ a r g m a x s i ′ E U i ( s i ′ , s − i ∣ θ i ) = a r g m a x s i ′ ∑ θ i p ( θ i ) E U ( s i ′ , s − i ∣ θ i ) s_i\in argmax_{s_i^{‘}}EU_i(s_i^{‘},s_{-i}|\theta_i)=argmax_{s_i^{‘}}\sum_{\theta_i}p(\theta_i)EU(s_i^{‘},s_{-i}|\theta_i) si∈argmaxsi′EUi(si′,s−i∣θi)=argmaxsi′∑θip(θi)EU(si′,s−i∣θi)(ex-ante方式定义)
6-5 Analyzing Bayesian Games:Another Example
- 本章节我们再通过一个例子来体会贝叶斯博弈。
- 均衡的问题归根结底还是对于动作或者策略的选择,贝叶斯纳什均衡通过构造以决策者类型概率分布为变量的函数来最大化期望效用,从而实现动作或者策略的选择。
- 我们来了解一下警长困局 Sheriff’s Dilemma
故事背景:一位警长正面对一个犯罪嫌疑人,犯罪嫌疑人可能真的是罪犯也可能只是一个无辜的平民。警长和犯罪嫌疑人需要同时决定是否对对方开枪。
情景设定:犯罪嫌疑人有 p p p的概率是一名罪犯,同时有 1 − p 1-p 1−p的概率只是个平民;警长如果对方选择开枪则会选择开枪,如果对方不开枪则倾向于不开枪;罪犯无论对方开枪与否自己都倾向于开枪;平民无论对方开枪与否自己都倾向于不开枪。
收益矩阵:
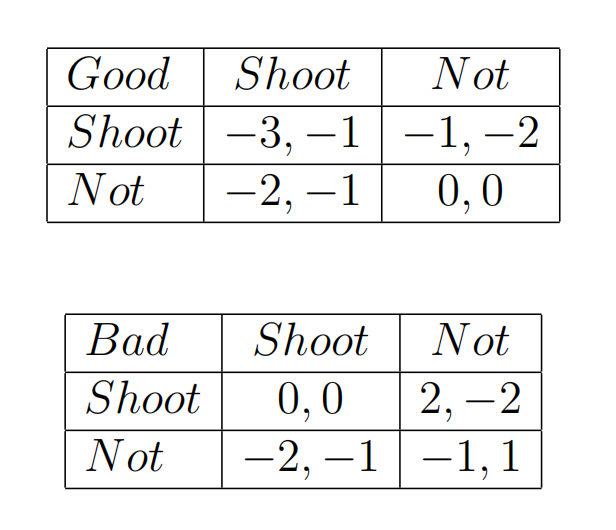
这个博弈游戏可以说是一个单向的贝叶斯博弈,对于警长来说,犯罪嫌疑人的类型不确定;而对于犯罪嫌疑人来说,警长却只有一个类型。因此我们从警长角度来分析贝叶斯纳什均衡。
因为犯罪嫌疑人类型不确定,导致在警长角度,犯罪嫌疑人选择射击或者不射击的期望收益相等。
对于警长来说,如果对方是平民(上方收益矩阵),选择不射击对于选择射击是严格占优的。对应下方收益矩阵,选择射击对于选择不射击是严格占优的。因此可以得出下式:
− 1 × ( 1 − p ) + 0 × p = 0 × ( 1 − p ) + ( − 2 ) × p , p = 1 / 3 -1\times(1-p)+0\times p=0\times(1-p)+(-2)\times p,p=1/3 −1×(1−p)+0×p=0×(1−p)+(−2)×p,p=1/3。因此当 p > 1 / 3 p>1/3 p>1/3时,警长选择不射击的期望收益更大,相反选择射击的期望收益更大。犯罪嫌疑人的类型概率分布直接影响了警长的均衡策略选择。
7-1 Coalitional Game Theory:Taste
- 本章节引出合作博弈 Coalitional Game/Cooperation Game。之前我们学习的静态博弈与动态博弈、纯策略博弈与混合策略博弈、完全信息博弈与非完全信息博弈等绝大多数都是建立在非合作博弈的基础之上的。
7-2 Coalitional Game Theory:Definitions
- 在合作博弈中,我们并不关心单个决策者的决策选择以及单个决策者的效用收益,而是一个小组的决策者共同做出决策、获得收益、分配收益。
- 可转移效用与不可转移效用:
可转移效用:每个联盟的效用值都可以用实数表示;给每个联盟分配一个单一的实数值作为效用;每个联盟的效用可以在内部重新分配。
不可转移效用:联盟获得的效用不可用实数表示;或者联盟的效用按照固定比例分配,无法实现自由分配。 - 可转移效用下的合作博弈定义:
A coalitional game with transferable utility is a pair ( N , v ) (N,v) (N,v),where
N N N is a finite set of players,indexed by i i i;决策者的集合
v : 2 N → R v:2^N\to R v:2N→R associates with each colition S ∈ N S\in N S∈N a real-valued payoff v ( S ) v(S) v(S) that the coalition’s members can distribute among themselves.We assume that v ( ∅ ) = 0 v(\emptyset)=0 v(∅)=0。为每个联盟 S S S分配一个效用值 v v v的效用函数 v ( S ) v(S) v(S),每个联盟都属于幂集 2 N 2^N 2N的子集。
- 合作博弈需要解决的两大问题:
1.合作博弈内部的联盟该如何生成?(谁和谁合作?)
该问题一般直接设置为The Grand Coalition,即所有决策者都在一个联盟里,按SuperAdditive的理念,这样的联盟收益是最大的。
2.联盟内部是如何分配效用的?(如何合作?)
为了保证效用分配的公平性与稳定性。 - SuperAdditive Games 超加博弈:
A game G = ( N , v ) G=(N,v) G=(N,v) is superadditive if for all S , T ∈ N S,T\in N S,T∈N,if S ∩ T = ∅ S\cap T=\emptyset S∩T=∅,then v ( S ∪ T ) > = v ( S ) + v ( T ) v(S\cup T)>=v(S)+v(T) v(S∪T)>=v(S)+v(T).
超加性也就是所谓的“ 1 + 1 > 2 1+1>2 1+1>2”,两个互补相交的联盟合并成一个联盟,共同的效用收益要大于两个联盟的效用和,也就是说合作带来了更大的效用。因此按道理说合作博弈中所有决策者全部合作形成一个最大的联盟,可以获得全局最大收益,这也就是所谓的The Grand Coalition。
7-3 The Shapley Value
- 上一章节我们说过,合作博弈的第二个关键性质问题就是如何公平地实现联盟内部效用分配。甚至说合作博弈的第一个关键性质问题也取决于如何公平分配效用。想要解决这个问题,我们首先要弄清楚如何定义公平。
- 本章节我们介绍其中一种公平实现效用分配的方法——The Sharply Value。
- Sharply最初的设想如下:联盟成员应该根据其边际效用获得相应的效用分配。
但实际上这个设想是十分不合理的,比如说如下情况:
我们假设一个背景,一件事情需要所有的决策者共同参与才可成功获得效用,因此 v ( N ) = 1 v(N)=1 v(N)=1and v ( S ) = 0 , i f N ≠ S v(S)=0,if N\neq S v(S)=0,ifN=S。因此针对每一个决策者 i i i, v ( N ) − v ( N / { i } ) = 1 v(N)-v(N/\{i\})=1 v(N)−v(N/{
i})=1,每个人的边际效用都是1,因此每个人对于总体的贡献都是 100 % 100\% 100%,难道给每个人都分配全部的总体效用?这也不够分啊!
因此,我们需要针对边际效用引入一个加权策略 - Shapley’s axioms Shapley定理的三条性质:
1.Symmetry
如果两个决策者 i 、 j i、j i、j加到任意一个联盟中,所带来的边际效用都是相等的,则我们称这两个决策者是Interchangeable的。对于任意两个可互换的决策者其Shapley Value相等,即 ψ i ( N , v ) = ψ j ( N , v ) \psi_i(N,v)=\psi_j(N,v) ψi(N,v)=ψj(N,v)
2.Dummy Players
如果一个决策者 i i i加到任意一个联盟中,所带来的边际效用都为0,则我们称这个决策者是dummy player,并且该决策者的Shapley Value为0,即 ψ i ( N , v ) = 0 \psi_i(N,v)=0 ψi(N,v)=0
3.Additivity
如果我们可以把某个博弈拆分成两个彼此独立的博弈,或者说可以将该博弈的效用函数拆分成两个独立的效用函数,即 ( v 1 + v 2 ) ( S ) = v 1 ( S ) + v 2 ( S ) (v_1+v_2)(S)=v_1(S)+v_2(S) (v1+v2)(S)=v1(S)+v2(S),那么每个决策者的Shapley Value也可以拆分成两部分即 ψ i ( N , v 1 + v 2 ) = ψ i ( N , v 1 ) + ψ i ( N , v 2 ) \psi_i(N,v_1+v_2)=\psi_i(N,v_1)+\psi_i(N,v_2) ψi(N,v1+v2)=ψi(N,v1)+ψi(N,v2)。 - Sharpley Value
以上三条性质,就是我们制定的“公平”规则。要想同步满足以上三条公平性质,我们只有一种效用划分方式——那就是Shapley Value。
ϕ i ( N , v ) = 1 N ! ∑ S ⊆ N / { i } ∣ S ∣ ! ( ∣ N ∣ − ∣ S ∣ − 1 ) ! [ v ( S ∪ { i } ) − v ( S ) ] \begin{aligned} \phi_i(N,v)=\frac{1}{N!}\sum_{S\subseteq N/\{i\}}|S|!(|N|-|S|-1)![v(S\cup\{i\})-v(S)] \end{aligned} ϕi(N,v)=N!1S⊆N/{
i}∑∣S∣!(∣N∣−∣S∣−1)![v(S∪{
i})−v(S)]
我们来挨个解释一下上面这个复杂又可怕的公式:
v ( S ∪ { i } ) − v ( S ) v(S\cup\{i\})-v(S) v(S∪{
i})−v(S)
是指在现有联盟 S S S的基础上引入 i i i带来的边际效用。
∑ S ⊆ N / { i } \sum_{S\subseteq N/\{i\}} S⊆N/{
i}∑
是指针对所有不包含 i i i的联盟遍历求和引入 i i i的边际效用。
∣ S ∣ ! ( ∣ N ∣ − ∣ S ∣ − 1 ) ! |S|!(|N|-|S|-1)! ∣S∣!(∣N∣−∣S∣−1)!
是引入 i i i后边际效用为 v ( S ∪ { i } ) − v ( S ) v(S\cup\{i\})-v(S) v(S∪{
i})−v(S)的情况总数(也就是在联盟 S S S中引入 i i i带来的边际效用为 v ( S ∪ { i } ) − v ( S ) v(S\cup\{i\})-v(S) v(S∪{
i})−v(S)的情况总数)。 ∣ S ∣ ! |S|! ∣S∣!是指在引入 i i i之前形成 S S S的所有可能序列总数, ( ∣ N ∣ − ∣ S ∣ − 1 ) ! (|N|-|S|-1)! (∣N∣−∣S∣−1)!是指引入 i i i后补全到 N N N的所有可能序列总数。统计所有边际效用的出现次数的目的是为了增加权重,出现次数越多的权重越大。
1 N ! \frac{1}{N!} N!1
是指所有决策者形成The Grand Coalition的所有序列可能性。
7-4 The Core
- Shapley Value定义了一种相对公平的联盟内部效用分配方法,然而这种分配方法却忽略了另外一个很重要的性质——稳定性。Shapley Value是在所有决策者一起形成The Grand Coalition的前提下制定的,但实际情况是并不是所有的合作博弈中,所有决策者都会一起构成一个大联盟,反而会出现一些“局部合作”更能体现个人的利益。
- 投票博弈
游戏背景:有 A 、 B 、 C 、 D A、B、C、D A、B、C、D四个政党一起参与某项议会议题,分别有 45 、 25 、 15 、 15 45、25、15、15 45、25、15、15的投票权。议题是是否批准$100百万的财务账单。如果最终投票结果大于 51 51 51票则投赞成票的人按对应比例瓜分财政拨款,否则所有人都无法获得财政拨款。
Shapley Value:如果假设四个人一起合作形成一个大联盟,那么由Shapley Value计算得权重: ( 50 , 16.67 , 16.67 , 16.67 ) (50,16.67,16.67,16.67) (50,16.67,16.67,16.67)。 B B B与 C , D C,D C,D票权不同,但最终分得得效用却相同,因此B不会愿意再维持这个大联盟。并且 A A A分别与 B 或 C 或 D B或C或D B或C或D形成小联盟都可以达到51票得赞成条件,这样分得的效用可比大联盟高多了。因此实际情况中,很难形成大联盟,因而无法达到应用Shapley Value的条件。 - The Core
在哪种分配方案的支持下,代理者们愿意形成The Grand Coalition?答案是,当且仅当分配方案属于该合作博弈的The Core中。The Core内的分配向量符合以下两个条件:
1.首先我们设定每种分配方案所有分配值的总和等于所有代理者一起合作形成联盟的效用值,也就是说形成The Grand Coalition时获得的收益,按之前的假设这个收益也是整个合作博弈能达成的最大收益。
∑ i = 1 n ψ i = v ( { 1 , . . . , n } ) \sum_{i=1}^n\psi_i=v(\{1,…,n\}) i=1∑nψi=v({
1,...,n})
2.将最大收益具体划分到每个代理者身上获得一个分配向量。我们要保证任意一个联盟,其内部成员被分配收益(The Grand Coalition合作下)的总和都要大于该小联盟合作的收益。也就是说,我们构想出一种针对于最大收益的分配方案,使得没有任何一个小联盟单独拆除去可以获得更大的联盟收益。(十分类似于纳什均衡的定义方式——无更大获利的偏移方案)
∑ i ∈ S ψ i > = v ( S ) \sum_{i\in S}\psi_i>=v(S) i∈S∑ψi>=v(S) - 任意一个合作博弈的The Core集,不一定非空,也不一定只有一种符合条件的分配方案。
- Simple Games
Simple Games定义:
A game G = ( N , v ) G=(N,v) G=(N,v) is simple if for all S ⊂ N , v ( S ) ∈ { 0 , 1 } S\subset N,v(S)\in \{0,1\} S⊂N,v(S)∈{
0,1}
简单博弈是指所有联盟的收益要么是0要么是1。
Veto Player定义:
A player i i i is a veto player if v ( N / { i } ) = 0 v(N/\{i\})=0 v(N/{
i})=0
拥有一票否决的代理者是指只要缺少了他,形成的任何联盟的收益都是0。
Simple Games定理:
当且仅当没有Veto Player时,该简单博弈的The Core为空。
如果有Veto Player,那么The Core中的所有分配方案都满足该条件:Nonveto Player分配到0收益。
- Convex Games定义:
A game G = ( N , v ) G=(N,v) G=(N,v) is convex if for all S , T ⊂ N , v ( S ∪ T ) > = v ( S ) + v ( T ) − v ( S ∩ T ) S,T\subset N,v(S\cup T)>=v(S)+v(T)-v(S\cap T) S,T⊂N,v(S∪T)>=v(S)+v(T)−v(S∩T)
凸博弈与我们之前学习到的凸函数等定义都比较相似。并且凸博弈的定义是之前介绍的超加性的增强定义,超加性中规定 S , T S,T S,T互不相交,凸博弈中并不要求互不相交只需要减去一遍公共部分即可。
每一个凸博弈都至少还有一个非空的核。
在每一个凸博弈中,Shapley Value在核中。
7-5 Comparng the Core and Shapley Value in an Example
- 本章节我们通过一个简单的实例来分别计算一下The Core和Shapley Value。
- 联合国安全理事会一共有15个成员,其中包括5个常任理事国,这5个常任理事国拥有一票否决权。某项议题要想通过的话,必须满足两个条件:
1.5个常任理事国都投赞成票。也就是5个常任理事国都包含在同一联盟中,拥有共同利益。
2.必须满足“半数规则”,也就是说必须有8个及8个以上的理事国投赞成票。 - 我们来简化一下情形,简化后的博弈如下:一共3名代理者,其中1名拥有一票否决权,每个提案必须有2名代理者投赞成并且无一票否决才可生效。
- The Core计算过程:
v ( S ) = 1 i f 1 ∈ S a n d # S > = 2 , v ( S ) = 0 o t h e r w i s e x 1 + x 2 > = 1 , x 1 + x 3 > = 1 , x 1 + x 2 + x 3 = 1 , x i > = 0 x 1 = 1 , x 2 = 0 , x 3 = 0 \begin{aligned} v(S)=1 \space if \space 1\in S \space and \space \#S>=2,v(S)=0\space otherwise\\ x_1+x_2>=1,x_1+x_3>=1,x_1+x_2+x_3=1,x_i>=0\\ x_1=1,x_2=0,x_3=0 \end{aligned} v(S)=1 if 1∈S and #S>=2,v(S)=0 otherwisex1+x2>=1,x1+x3>=1,x1+x2+x3=1,xi>=0x1=1,x2=0,x3=0 - Shapley Value计算过程:
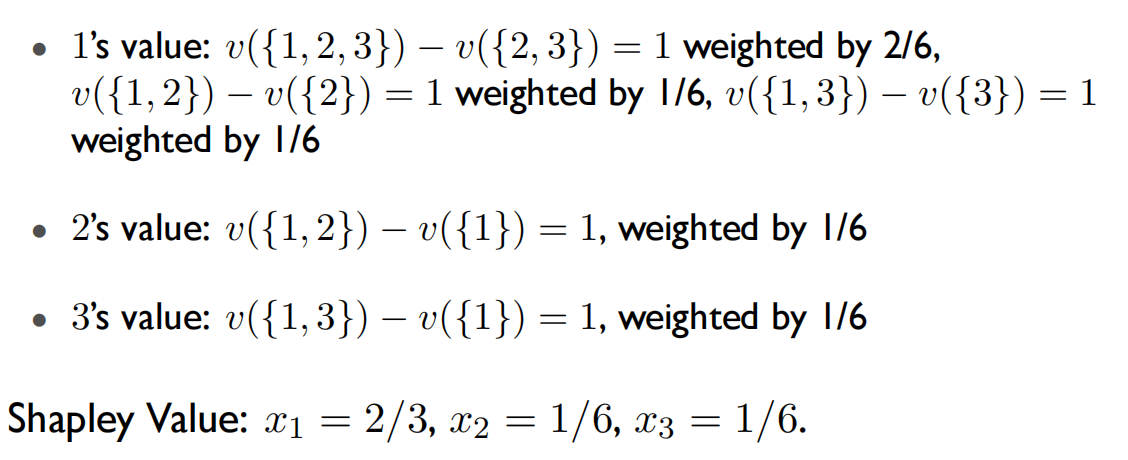
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181612.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
