大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Hadoop的架构
在其核心,Hadoop主要有两个层次,即:
- 加工/计算层(MapReduce)
- 存储层(Hadoop分布式文件系统)
除了上面提到的两个核心组件,Hadoop的框架还包括以下两个模块:
- Hadoop通用:这是Java库和其他Hadoop组件所需的实用工具
- Hadoop YARN :这是作业调度和集群资源管理的框架
Hadoop Streaming 是一个实用程序,它允许用户使用任何可执行文件(例如shell实用程序)作为映射器和/或reducer创建和运行作业。
HDFS:
HDFS遵循主从架构,它具有以下元素。
1、名称节点 -Namenode
名称节点是包含GNU/Linux操作系统和软件名称节点的普通硬件。它是一个可以在商品硬件上运行的软件。具有名称节点系统作为主服务器,它执行以下任务:
– 管理文件系统命名空间。
– 规范客户端对文件的访问。
– 它也执行文件系统操作,如重命名,关闭和打开的文件和目录。
2、数据节点 – Datanode
Datanode具有GNU/Linux操作系统和软件Datanode的普通硬件。对于集群中的每个节点(普通硬件/系统),有一个数据节点。这些节点管理数据存储在它们的系统。
– 数据节点上的文件系统执行的读写操作,根据客户的请求。
– 还根据名称节点的指令执行操作,如块的创建,删除和复制。
3、块 -block
一般用户数据存储在HDFS文件。在一个文件系统中的文件将被划分为一个或多个段和/或存储在个人数据的节点。这些文件段被称为块。换句话说,数据的HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但它可以增加按需要在HDFS配置来改变
HDFS常用命令
- 运行jar包:hadoop jar /Users/kexin/work/projects/Hadoop/target/hadoop-0.0.1-SNAPSHOT.jar com.kexin.hadoop.units.WordCount /test/test.txt /project/wordcount/output
- 文件系统操作:hadoop fs -cat|ls|mkdir
- 上传文件:hadoop dfs -put ./testdata.txt /testdata
- 递归删除目录及文件:hadoop fs -rmr /testdata
- 删除文件:hadoop fs -rm /testdata.txt
MapReduce
教程:
– https://www.cnblogs.com/huxinga/p/6939896.html
– http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v2.0
MapReduce计划分三个阶段执行,即映射阶段,shuffle阶段,并减少阶段。
涉及到的角色:
1、客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
2、JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
3、TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障,我会在后面的mapreduce的相关问题里讲到这个问题的)
4、Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
-
map阶段:映射或映射器的工作是处理输入数据。一般输入数据以存储在HDFS的文件或目录的形式,输入文件被传递到映射器功能线路,映射器处理该数据,并创建数据的若干小块。
-
reduce阶段:这个阶段是Shuffle阶段和Reduce阶段的组合。减速器的工作是处理该来自映射器中的数据。处理之后,它产生一组新的输出,这将被存储在HDFS。
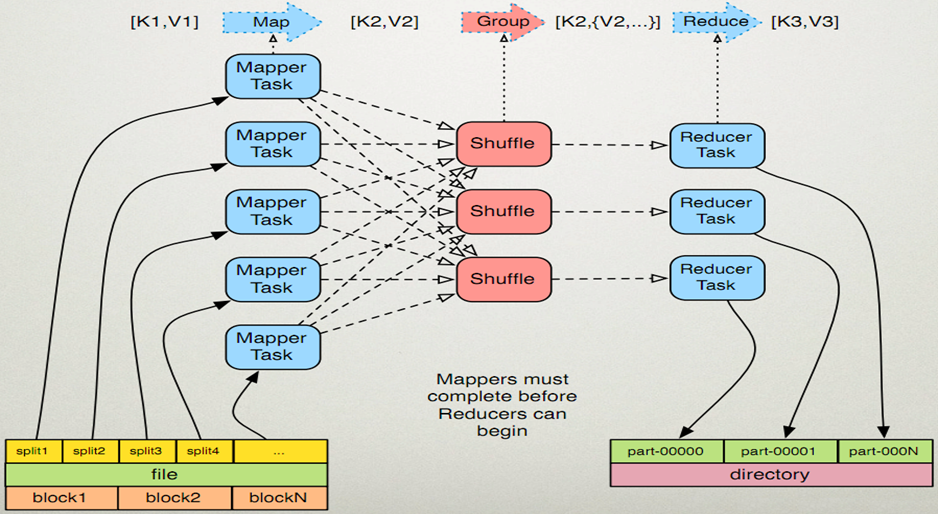

在一个MapReduce工作过程中:
1、由Hadoop发送Map和Reduce任务到集群的相应服务器
2、框架管理数据传递,例如发出任务的所有节点之间的集群周围的详细信息,验证任务完成,和复制数据
3、大部分的计算发生在与在本地磁盘上,可以减少网络通信量数据的节点
4、给定的任务完成后,将收集并减少了数据,以一个合适的结果发送回Hadoop服务器
应用程序通常实现Mapper和Reducer接口以提供map和reduce方法:
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}在idea中远程调试程序
System.setProperty("hadoop.home.dir", "/Users/kexin/work/app/hadoop/hadoop-2.6.5");
Configuration conf = new Configuration();
String uri = "hdfs://localhost:9000";
Job job = null;
try {
job = Job.getInstance(conf);
} catch (IOException e) {
e.printStackTrace();
}
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileSystem fs = FileSystem.get(URI.create(uri), conf);
try {
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/test/test.txt"));
Path outpath = new Path("hdfs://localhost:9000/project/wordcount/output");
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
try {
job.submit();
} catch (ClassNotFoundException | IOException | InterruptedException e) {
e.printStackTrace();
}在idea中本地调试程序
System.setProperty("hadoop.home.dir", "/Users/kexin/work/app/hadoop/hadoop-2.6.5");
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(WordCount.class);
job.setJobName("word count");
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/Users/kexin/work/projects/Hadoop/src/main/resources/input"));
Path outpath = new Path("/Users/kexin/work/projects/Hadoop/src/main/resources/output");
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}1、映射器
映射器将输入k/v对映射到一组中间k/v对。转换后的中间记录不需要与输入记录的类型相同。给定的输入对可以映射到零个或多个输出对。通过调用context.write(WritableComparable,Writable)来收集输出对。
Hadoop MapReduce框架为作业的InputFormat生成的每个InputSplit生成一个map任务。
总的来说,映射器实现通过Job.setMapperClass(Class)方法传递给作业。然后,框架为InputSplit中的每个k/v对调用该任务的map。
映射的数量通常由输入的总大小驱动,即输入文件的块总数。也可以使用Configuration.set(MRJobConfig.NUM_MAPS,int)来设置映射数量。
随后将与给定输出键关联的所有中间值按框架分组,并传递给Reducer以确定最终输出。用户可以通过Job.setGroupingComparatorClass(Class)指定Comparator来控制分组。
对Mapper输出进行排序,然后根据Reducer进行分区。分区总数与作业的reduce任务数相同。用户可以通过实现自定义分区程序来控制哪些键(以及记录)转到哪个Reducer。
用户可以选择通过Job.setCombinerClass(Class)指定组合器来执行中间输出的本地聚合,比如合并重复的key,这有助于减少从Mapper传输到Reducer的数据量。
2、Reducer
Reducer有3个主要阶段:shuffle,sort和reduce
1、shuffle
Reducer的输入是映射器的排序输出。在此阶段,框架通过HTTP获取所有映射器的输出的相关分区
2、sort
框架在此阶段按键(因为不同的映射器可能输出相同的键)对Reducer输入进行分组。在获取map输出结果时,shuffle和sort阶段同时进行。
如果要求对中间密钥进行分组的等价规则与在减少之前对密钥进行分组的等价规则不同,则可以通过Job.setSortComparatorClass(Class)指定比较器。由于Job.setGroupingComparatorClass(Class)可用于控制中间键的分组方式,因此可以结合使用这些键来模拟值的二级排序。
3、reduce
在此阶段,为分组输入中的每个
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181010.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
