大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
0.引言
什么都先不说,先看下面这个引入的例子:
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
本人JDK版本1.8,输出结果为:
true
true再将上面的例子加上一行代码:
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin"); 再运行,结果为:
false
false是不是感觉莫名其妙,新定义的str2好像和str1没有半毛钱的关系,怎么会影响到有关str1的输出结果呢?其实这都是intern()方法搞的鬼!看完这篇文章,你就会明白。o(∩_∩)o
说实话我本来想总结一篇Android内存泄漏的文章的,查阅了很多资料,发现不得不从Java的OOM讲起,讲Java的OOM又不得不讲Java的虚拟机架构。如果不了解JVM的同学可以查看此篇 JVM——Java虚拟机架构。(这篇文章已经被我修改过N多次了,个人感觉还是挺全面清晰的,每次看都会有新的理解。)
在JVM架构一文中也有介绍,在JVM运行时数据区中的方法区有一个常量池,但是发现在JDK1.6以后常量池被放置在了堆空间,因此常量池位置的不同影响到了String的intern()方法的表现。深入了解后发现还是值得写下来记录一下的。
1.为什么要介绍intern()方法
intern()方法设计的初衷,就是重用String对象,以节省内存消耗。这么说可能有点抽象,那么就用例子来证明。
static final int MAX = 100000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
//为长度为10的Integer数组随机赋值
Integer[] sample = new Integer[10];
Random random = new Random(1000);
for (int i = 0; i < sample.length; i++) {
sample[i] = random.nextInt();
}
//记录程序开始时间
long t = System.currentTimeMillis();
//使用/不使用intern方法为10万个String赋值,值来自于Integer数组的10个数
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(sample[i % sample.length]));
//arr[i] = new String(String.valueOf(sample[i % sample.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}这个例子也比较简单,就是为了证明使用intern()比不使用intern()消耗的内存更少。
先定义一个长度为10的Integer数组,并随机为其赋值,在通过for循环为长度为10万的String对象依次赋值,这些值都来自于Integer数组。两种情况分别运行,可通过Window —> Preferences –> Java –> Installed JREs设置JVM启动参数为-agentlib:hprof=heap=dump,format=b,将程序运行完后的hprof置于工程目录下。再通过MAT插件查看该hprof文件。
两次实验结果如下:

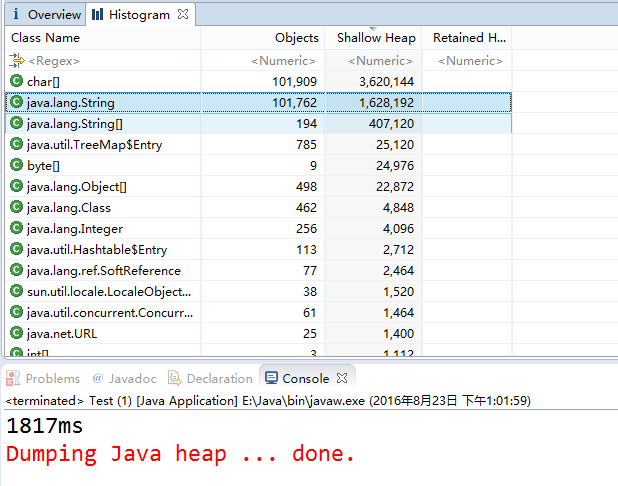
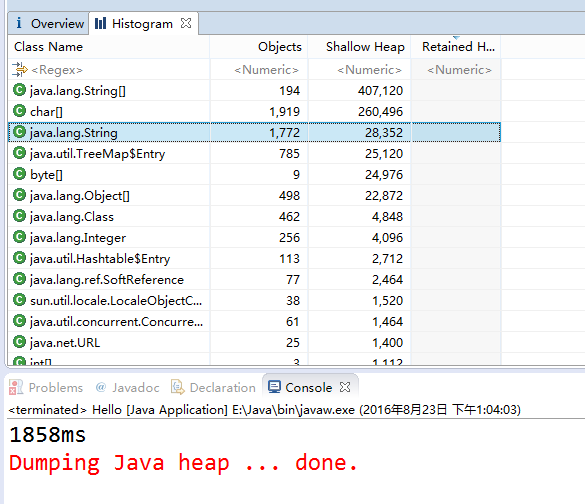
从运行结果来看,不使用intern()的情况下,程序生成了101762个String对象,而使用了intern()方法时,程序仅生成了1772个String对象。自然也证明了intern()节省内存的结论。
细心的同学会发现使用了intern()方法后程序运行时间有所增加。这是因为程序中每次都是用了new String后又进行intern()操作的耗时时间,但是不使用intern()占用内存空间导致GC的时间是要远远大于这点时间的。
2.深入认识intern()方法
JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);输出结果为:
JDK1.6以及以下:false false
JDK1.7以及以上:false true
再分别调整上面代码2.3行、7.8行的顺序:
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
输出结果为:
JDK1.6以及以下:false false
JDK1.7以及以上:false false下面依据上面代码对intern()方法进行分析:
2.1 JDK1.6
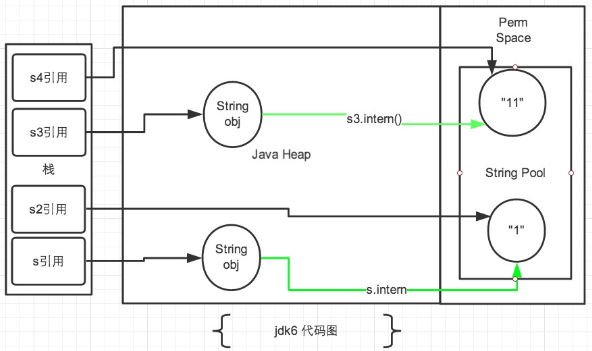
在JDK1.6中所有的输出结果都是 false,因为JDK1.6以及以前版本中,常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。如果不清楚String类的“==”和equals()的区别可以查看我的这篇博文Java面试——从Java堆、栈角度比较equals和==的区别。
intern()方法在JDK1.6中的作用是:比如String s = new String(“SEU_Calvin”),再调用s.intern(),此时返回值还是字符串“SEU_Calvin“,表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在“SEU_Calvin”这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把“SEU_Calvin”添加到字符串池中,然后再返回它的引用。然而在JDK1.7中却不是这样的,后面会讨论。
2.2 JDK1.7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。先看第一段代码的情况:
再把第一段代码贴一下便于查看:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
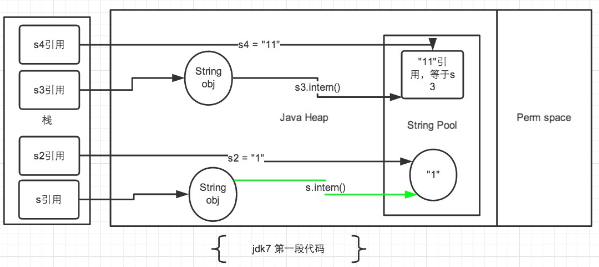
System.out.println(s3 == s4);String s = newString(“1”),生成了常量池中的“1” 和堆空间中的字符串对象。
s.intern(),这一行的作用是s对象去常量池中寻找后发现“1”已经存在于常量池中了。
String s2 = “1”,这行代码是生成一个s2的引用指向常量池中的“1”对象。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String(“1”) + newString(“1”),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为”11″)。注意此时常量池中是没有 “11”对象的。
s3.intern(),这一行代码,是将 s3中的“11”字符串放入 String 常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个 “11” 的对象。
但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向 s3 引用的对象,也就是说s3.intern() ==s3会返回true。
String s4 = “11”, 这一行代码会直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。因此s3 == s4返回了true。
下面继续分析第二段代码:
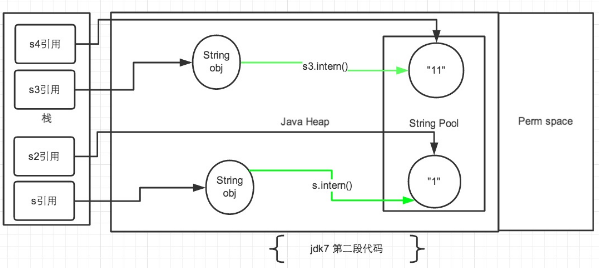
再把第二段代码贴一下便于查看:
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);String s = newString(“1”),生成了常量池中的“1” 和堆空间中的字符串对象。
String s2 = “1”,这行代码是生成一个s2的引用指向常量池中的“1”对象,但是发现已经存在了,那么就直接指向了它。
s.intern(),这一行在这里就没什么实际作用了。因为”1″已经存在了。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String(“1”) + newString(“1”),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为”11″)。注意此时常量池中是没有 “11”对象的。
String s4 = “11”, 这一行代码会直接去生成常量池中的”11″。
s3.intern(),这一行在这里就没什么实际作用了。因为”11″已经存在了。
结果就是 s3 和 s4 的引用地址明显不同。因此返回了false。
3 总结
终于要做Ending了。现在再来看一下开篇给的引入例子,是不是就很清晰了呢。
String str1 = new String("SEU") + new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
str1.intern() == str1就是上面例子中的情况,str1.intern()发现常量池中不存在“SEUCalvin”,因此指向了str1。 “SEUCalvin”在常量池中创建时,也就直接指向了str1了。两个都返回true就理所当然啦。
那么第二段代码呢:
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin"); 也很简单啦,str2先在常量池中创建了“SEUCalvin”,那么str1.intern()当然就直接指向了str2,你可以去验证它们两个是返回的true。后面的”SEUCalvin”也一样指向str2。所以谁都不搭理在堆空间中的str1了,所以都返回了false。
好了,本篇对intern的作用以及在JDK1.6和1.7中的实现原理的介绍就到此为止了。希望能给你带来帮助。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180980.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
