大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
聚类分析是根据研究对象的特征,按照一定标准对研究对象进行分类的一种分析方法。
下面我们主要从下面四个方面来解说:
- 实际应用
- 理论思想
- 建立模型
- 分析结果
一、实际应用
聚类分析的目标就是在相似的基础上收集数据来分类。
聚类源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。
商业上:
聚类分析被用来发现不同的客户群,并且通过购买模式刻画不同的客户群的特征。聚类分析是细分市场的有效工具,同时也可用于研究消费者行为,寻找新的潜在市场、选择试验的市场,并作为多元分析的预处理。
生物上:
聚类分析被用来动植物分类和对基因进行分类,获取对种群固有结构的认识。
地理上:
聚类能够帮助在地球中被观察lei的数据库趋于的相似性。
保险行业上:
聚类分析通过一个高的平均消费来鉴定汽车保险单持有者的分组,同时根据住宅类型,价值,地理位置来鉴定一个城市的房产分组。
因特网上:
聚类分析被用来在网上进行文档归类来修复信息。
电子商务上:
聚类分析在电子商务中网站建设数据挖掘中也是很重要的一个方面,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好的帮助电子商务的用户了解自己的客户,向客户提供更合适的服务。
二、理论思想
聚类分析是基于数据之间的距离远近,对研究变量进行聚类分组,聚类分析事先不知道分组情况,是一种探索性分析。
聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
按照研究对象的不同,聚类分析一般分为样本聚类和变量聚类。
样本聚类又称Q型聚类,它针对实测量进行分类,将特征相近的实测量分为一类,特征差异较大的实察量分在不同的类。
变量聚类又称R型聚类,它针对变量分类,将性质相近的变量分为一类,将性质差异较大的变量分在不同的类。
聚类常见类型有系统聚类、K-means聚类和两步聚类:
系统聚类:
先将n个样品或变量看成n个分类,然后将距离接近(样品聚类)或性质接近(变量聚类)的两类合并为一类,再从n-1类中继续寻找最接近的两类合并为一类,如此继续,最终将所有类别合并为一类。
K-means聚类,又称快速聚类:
对n个数值变量参与快速聚类,则n个变量组成一个n维的空间,每个样品是空间中的一个点,最终按照事先要求聚类聚成K个类别。聚类前计算机随机产生初始的聚类中心,计算各个点到中心的距离,然后计算机迭代新的聚类中心。如果各个点到第二次聚类中心的距离比第一次小,则放弃第一次中心,留取第二次中心。接着计算机继续迭代寻找第三次聚类中心,直至各个点到前后聚类中心的距离之差为零,此时认为已经无法再进一步优化,即找到最佳的聚类中心。
两步聚类:
利用统计量作为距离进行聚类,两步聚类顾名思义分为两步,先进行预聚类,然后在预聚类基础上,根据AIC和BIC最小原则,自动判定聚类数目。两步聚类算法复杂,但软件实现起来也不复杂。
一般可以根据以下的条件选中聚类方法:
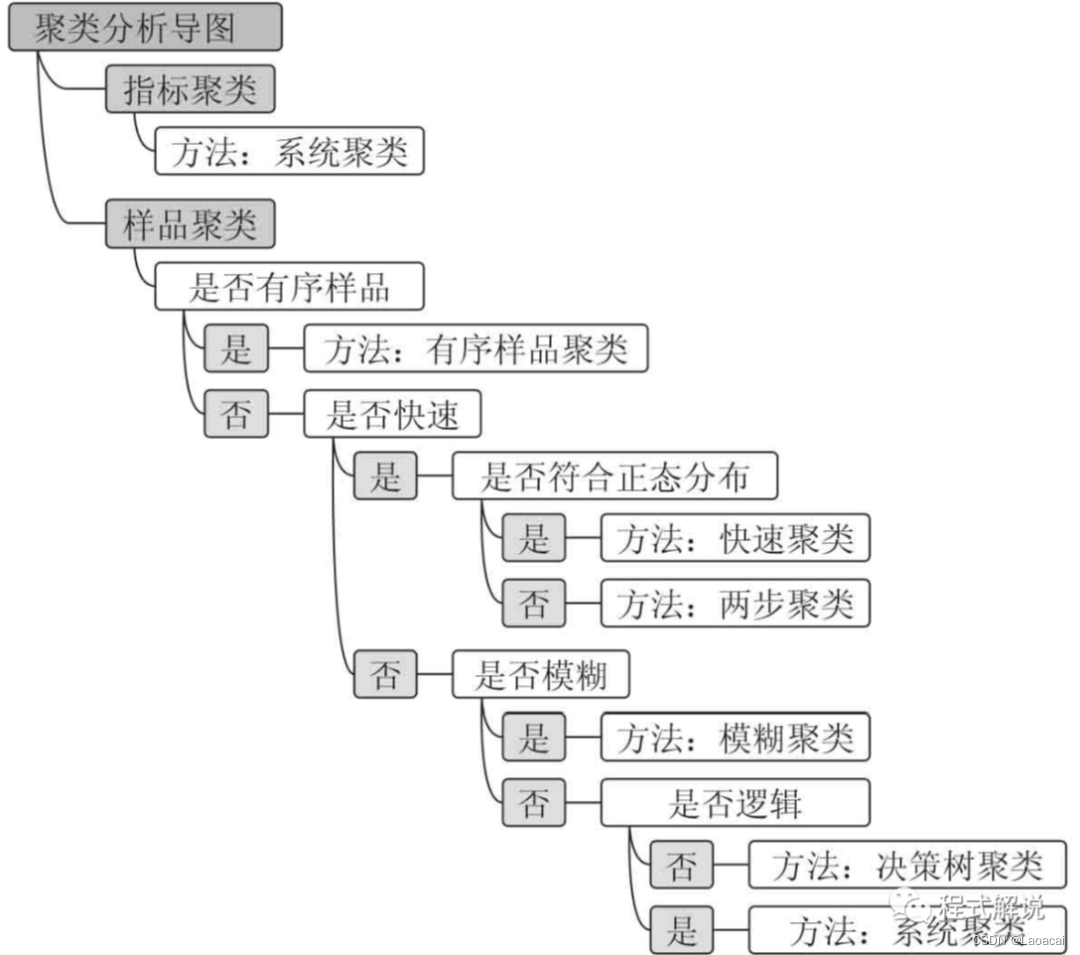

三、建立模型
模型建立的步骤:
构建模型的步骤如下:
(1)数据预处理;
(2)为衡量数据点间的相似度定义一个距离函数;
(3)聚类或分组;
(4)评估输出;
(5)优化模型。
快速聚类案例:
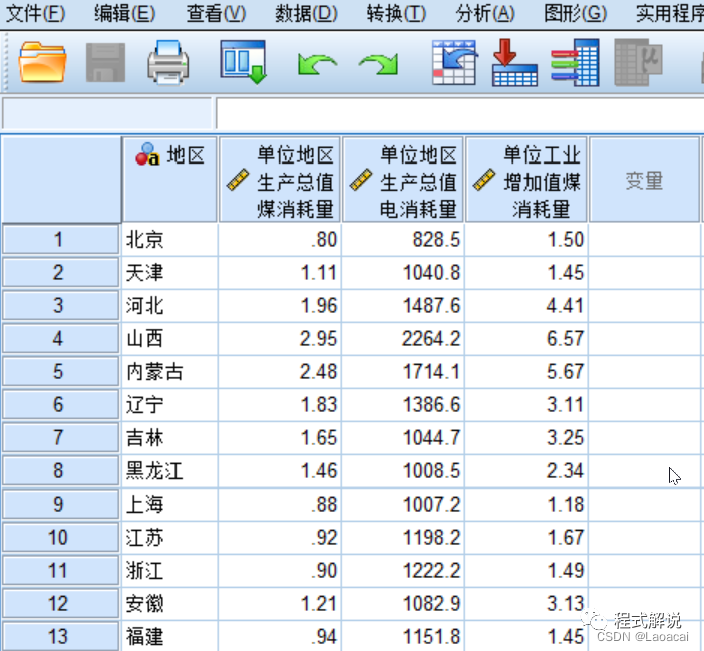
题目:以下我国2006年各地区能源消耗的情况。根据不同省市的能源消耗情况,对其进行分类,分析我国不同地区的能源消耗情况。
一、数据输入
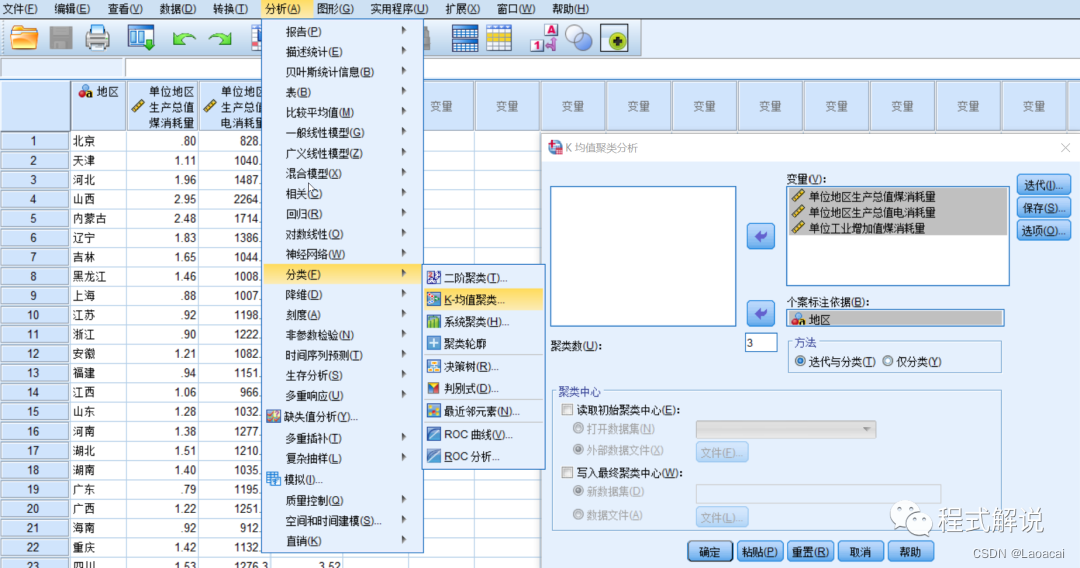
二、操作步骤1、进入SPSS,打开相关数据文件,选择“分析”|“分类 ”|“K-均值聚类”命令2、选择进行聚类分析的变量。在对话框的左侧列表框中,选择“地区”进入“个案标注依据”列表框,选择“Zscore(单位地区生产总值煤消耗量)”“Zscore(单位地区生产总值电消耗量)”“Zscore(单位工业增加值煤消耗量)”3个变量进入“变量”列表框;在“聚类数”中,输入聚类分析的类别数3
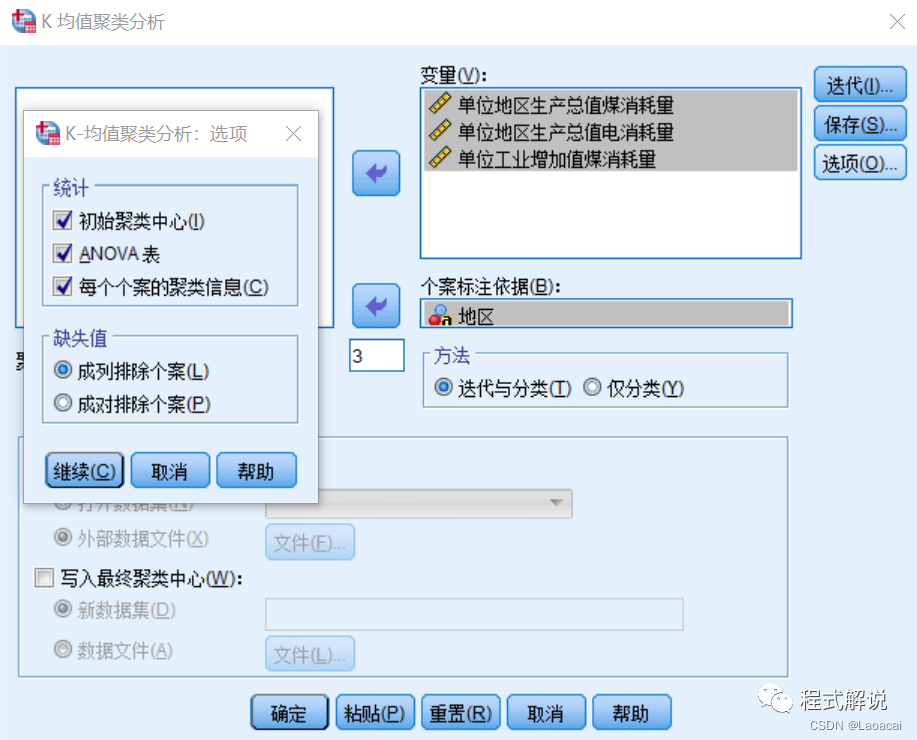
3、设置输出及缺失值处理方法。
单击“K均值聚类分析”对话框中的“选项”按钮。在“统计”选项组中,选中全部的3个复选框;“缺失值”选择默认值。
设置完毕后,单击“继续”按钮返回“K均值聚类分析”对话框。
4、其余设置采用系统默认值即可。单击“确定”按钮,等待输出结果。
四、结果分析
1、初始聚类中心可以知道初始聚类中心。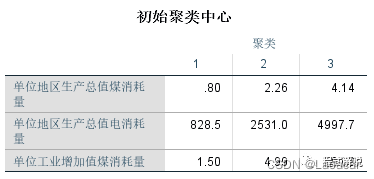
2、聚类成员分析可以知道每个地区属于哪一类,还可以知道每个地区到最终聚类中心的距离。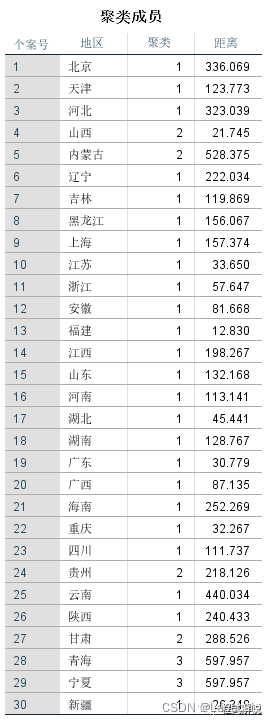
3、最终聚类中心表可以看出,3类的中心位置同初始位置相比,均发生了变化。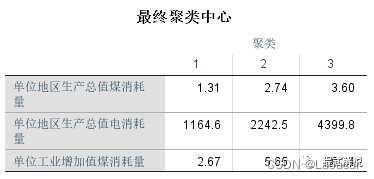
4、每个聚类中的样本数可以知道,聚类1所包含样本数最多,聚类3所包含样本数最少。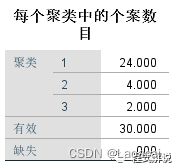
分析结论:(获取更多知识,前往gz号程式解说)
通过K中心聚类分析,可以对我国不同地区的能源消耗情况有一个基本的了解。我们可以将不同地区的能源消耗情况分成3类;其中,第一类地区包含的省市最多,有24个,其他两类包含省市较少。通过分析也可以知道每个地区属于哪一类。
参考案例数据:
【1】spss统计分析与行业应用案例详解(第四版) 杨维忠,张甜,王国平 清华大学出版社
收录于合集 #spss
13个
上一篇spss分析方法–回归分析

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180727.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
