大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
转载请标明出处floater的csdn blog,http://blog.csdn.net/flaoter
Linux SPI驱动分为核心层,控制器驱动层和设备驱动层。核心层是Linux的SPI核心部分,提供了核心数据结构的定义,总线、设备和驱动的注册、注销管理等,提供与上层的统一接口。linux将I2C、SPI、USB等总线驱动隔离成控制器驱动和设备驱动,使两者相对独立。
本文以qcom的spi控制器为例,对spi控制器驱动进行解析。kernel代码版本是3.18。
1 控制器设备注册
控制器的设备注册在kernel启动阶段的dt解析过程中完成,注册控制器设备为platform_device。dts中描述如下:
spi_6: spi@757a000 {
/* BLSP1 QUP6 */
compatible = "qcom,spi-qup-v2";
#address-cells = <1>;
#size-cells = <0>;
reg-names = "spi_physical", "spi_bam_physical";
reg = <0x0757a000 0x600>,
<0x07544000 0x2b000>;
interrupt-names = "spi_irq", "spi_bam_irq";
interrupts = <0 100 0>, <0 238 0>;
spi-max-frequency = <19200000>;
qcom,infinite-mode = <0>;
qcom,rt-priority;
qcom,use-bam;
qcom,ver-reg-exists;
qcom,bam-consumer-pipe-index = <22>;
qcom,bam-producer-pipe-index = <23>;
qcom,master-id = <86>;
qcom,use-pinctrl;
pinctrl-names = "spi_default", "spi_sleep";
pinctrl-0 = <&spi_6_active>;
pinctrl-1 = <&spi_6_sleep>;
clock-names = "iface_clk", "core_clk";
clocks = <&clock_gcc clk_gcc_blsp1_ahb_clk>,
<&clock_gcc clk_gcc_blsp1_qup6_spi_apps_clk>;
};
2 控制器驱动注册
控制器设计者一般都会自定义一个数据结构用于描述控制器基本信息,不同设计厂商的数据结构成员不同,但肯定与自身控制器的使用密切相关的内容,比如内存基地址,clock,中断号,端口fifo大小等。linux驱动与设备是一对多的关系,在spi_master设备注册时,控制器的结构体信息会提供给spi_master作为私有数据。
struct spi_qup {
void __iomem *base; //controller基址,操作controller寄存器时使用
struct device *dev;
struct clk *cclk; /* core clock */
struct clk *iclk; /* interface clock */
int irq;
spinlock_t lock;
int in_fifo_sz;
int out_fifo_sz;
int in_blk_sz;
int out_blk_sz;
struct spi_transfer *xfer;
struct completion done;
int error;
int w_size; /* bytes per SPI word */
int tx_bytes;
int rx_bytes;
int qup_v1;
};
除了platform_device的控制器设备注册外,spi控制器还需要注册spi_bus_type的spi_master设备作为spi master,此数据接口是控制器驱动的核心数据结构。
struct spi_master {
struct device dev;
struct list_head list;
/* other than negative (== assign one dynamically), bus_num is fully
* board-specific. usually that simplifies to being SOC-specific.
* example: one SOC has three SPI controllers, numbered 0..2,
* and one board's schematics might show it using SPI-2. software
* would normally use bus_num=2 for that controller.
*/
s16 bus_num;
/* chipselects will be integral to many controllers; some others
* might use board-specific GPIOs.
*/
u16 num_chipselect;
/* some SPI controllers pose alignment requirements on DMAable
* buffers; let protocol drivers know about these requirements.
*/
u16 dma_alignment;
/* spi_device.mode flags understood by this controller driver */
u16 mode_bits;
/* bitmask of supported bits_per_word for transfers */
u32 bits_per_word_mask;
#define SPI_BPW_MASK(bits) BIT((bits) - 1)
#define SPI_BIT_MASK(bits) (((bits) == 32) ? ~0U : (BIT(bits) - 1))
#define SPI_BPW_RANGE_MASK(min, max) (SPI_BIT_MASK(max) - SPI_BIT_MASK(min - 1))
/* limits on transfer speed */
u32 min_speed_hz;
u32 max_speed_hz;
/* other constraints relevant to this driver */
u16 flags;
#define SPI_MASTER_HALF_DUPLEX BIT(0) /* can't do full duplex */
#define SPI_MASTER_NO_RX BIT(1) /* can't do buffer read */
#define SPI_MASTER_NO_TX BIT(2) /* can't do buffer write */
#define SPI_MASTER_MUST_RX BIT(3) /* requires rx */
#define SPI_MASTER_MUST_TX BIT(4) /* requires tx */
/* lock and mutex for SPI bus locking */
spinlock_t bus_lock_spinlock;
struct mutex bus_lock_mutex;
/* flag indicating that the SPI bus is locked for exclusive use */
bool bus_lock_flag;
/* Setup mode and clock, etc (spi driver may call many times).
*
* IMPORTANT: this may be called when transfers to another
* device are active. DO NOT UPDATE SHARED REGISTERS in ways
* which could break those transfers.
*/
int (*setup)(struct spi_device *spi);
/* bidirectional bulk transfers
*
* + The transfer() method may not sleep; its main role is
* just to add the message to the queue.
* + For now there's no remove-from-queue operation, or
* any other request management
* + To a given spi_device, message queueing is pure fifo
*
* + The master's main job is to process its message queue,
* selecting a chip then transferring data
* + If there are multiple spi_device children, the i/o queue
* arbitration algorithm is unspecified (round robin, fifo,
* priority, reservations, preemption, etc)
*
* + Chipselect stays active during the entire message
* (unless modified by spi_transfer.cs_change != 0).
* + The message transfers use clock and SPI mode parameters
* previously established by setup() for this device
*/
int (*transfer)(struct spi_device *spi,
struct spi_message *mesg);
/* called on release() to free memory provided by spi_master */
void (*cleanup)(struct spi_device *spi);
/*
* Used to enable core support for DMA handling, if can_dma()
* exists and returns true then the transfer will be mapped
* prior to transfer_one() being called. The driver should
* not modify or store xfer and dma_tx and dma_rx must be set
* while the device is prepared.
*/
bool (*can_dma)(struct spi_master *master,
struct spi_device *spi,
struct spi_transfer *xfer);
/*
* These hooks are for drivers that want to use the generic
* master transfer queueing mechanism. If these are used, the
* transfer() function above must NOT be specified by the driver.
* Over time we expect SPI drivers to be phased over to this API.
*/
bool queued;
struct kthread_worker kworker;
struct task_struct *kworker_task; //worker对应的task,task一直遍历执行添加到worker中list等待的work
struct kthread_work pump_messages; //待添加到worker的work
spinlock_t queue_lock;
struct list_head queue;
struct spi_message *cur_msg;
bool busy;
bool running;
bool rt;
bool auto_runtime_pm;
bool cur_msg_prepared;
bool cur_msg_mapped;
struct completion xfer_completion;
size_t max_dma_len;
int (*prepare_transfer_hardware)(struct spi_master *master);
int (*transfer_one_message)(struct spi_master *master,
struct spi_message *mesg);
int (*unprepare_transfer_hardware)(struct spi_master *master);
int (*prepare_message)(struct spi_master *master,
struct spi_message *message);
int (*unprepare_message)(struct spi_master *master,
struct spi_message *message);
/*
* These hooks are for drivers that use a generic implementation
* of transfer_one_message() provied by the core.
*/
void (*set_cs)(struct spi_device *spi, bool enable);
int (*transfer_one)(struct spi_master *master, struct spi_device *spi,
struct spi_transfer *transfer);
/* gpio chip select */
int *cs_gpios;
/* DMA channels for use with core dmaengine helpers */
struct dma_chan *dma_tx;
struct dma_chan *dma_rx;
/* dummy data for full duplex devices */
void *dummy_rx;
void *dummy_tx;
};
spi控制器是platform_device,注册的驱动是plaform_driver。它的probe依赖于dts中设备的compatible属性与驱动中of_device_id的比对结果,一致的情况下,probe会被加载执行。
spi_qup.c
static const struct of_device_id spi_qup_dt_match[] = {
{ .compatible = "qcom,spi-qup-v1.1.1", },
{ .compatible = "qcom,spi-qup-v2.1.1", },
{ .compatible = "qcom,spi-qup-v2.2.1", },
{ }
};
MODULE_DEVICE_TABLE(of, spi_qup_dt_match);
static struct platform_driver spi_qup_driver = {
.driver = {
.name = "spi_qup",
.owner = THIS_MODULE,
.pm = &spi_qup_dev_pm_ops,
.of_match_table = spi_qup_dt_match,
},
.probe = spi_qup_probe,
.remove = spi_qup_remove,
};
module_platform_driver(spi_qup_driver);
probe函数的工作大体包括,
- 解析dts,对控制器结构体spi_qup填充,设置控制器工作状态,注册中断等与厂商控制器自身相关
- spi_master结构体填充,注册spi_master设备
spi_qup.c
static int spi_qup_probe(struct platform_device *pdev)
{
struct spi_master *master;
struct clk *iclk, *cclk;
struct spi_qup *controller;
struct resource *res;
struct device *dev;
void __iomem *base;
u32 max_freq, iomode, num_cs;
int ret, irq, size;
dev = &pdev->dev;
res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
base = devm_ioremap_resource(dev, res);
if (IS_ERR(base))
return PTR_ERR(base);
irq = platform_get_irq(pdev, 0);
if (irq < 0)
return irq;
cclk = devm_clk_get(dev, "core");
if (IS_ERR(cclk))
return PTR_ERR(cclk);
iclk = devm_clk_get(dev, "iface");
if (IS_ERR(iclk))
return PTR_ERR(iclk);
/* This is optional parameter */
if (of_property_read_u32(dev->of_node, "spi-max-frequency", &max_freq))
max_freq = SPI_MAX_RATE;
if (!max_freq || max_freq > SPI_MAX_RATE) {
dev_err(dev, "invalid clock frequency %d\n", max_freq);
return -ENXIO;
}
ret = clk_prepare_enable(cclk);
if (ret) {
dev_err(dev, "cannot enable core clock\n");
return ret;
}
ret = clk_prepare_enable(iclk);
if (ret) {
clk_disable_unprepare(cclk);
dev_err(dev, "cannot enable iface clock\n");
return ret;
}
master = spi_alloc_master(dev, sizeof(struct spi_qup));
if (!master) {
clk_disable_unprepare(cclk);
clk_disable_unprepare(iclk);
dev_err(dev, "cannot allocate master\n");
return -ENOMEM;
}
/* use num-cs unless not present or out of range */
if (of_property_read_u32(dev->of_node, "num-cs", &num_cs) ||
num_cs > SPI_NUM_CHIPSELECTS)
master->num_chipselect = SPI_NUM_CHIPSELECTS;
else
master->num_chipselect = num_cs;
master->bus_num = pdev->id;
master->mode_bits = SPI_CPOL | SPI_CPHA | SPI_CS_HIGH | SPI_LOOP;
master->bits_per_word_mask = SPI_BPW_RANGE_MASK(4, 32);
master->max_speed_hz = max_freq;
master->transfer_one = spi_qup_transfer_one;
master->dev.of_node = pdev->dev.of_node;
master->auto_runtime_pm = true;
platform_set_drvdata(pdev, master); //pdev->dev->dradata = master
controller = spi_master_get_devdata(master); //master->dev->drvdata = controller
controller->dev = dev;
controller->base = base;
controller->iclk = iclk;
controller->cclk = cclk;
controller->irq = irq;
/* set v1 flag if device is version 1 */
if (of_device_is_compatible(dev->of_node, "qcom,spi-qup-v1.1.1"))
controller->qup_v1 = 1;
spin_lock_init(&controller->lock);
init_completion(&controller->done);
iomode = readl_relaxed(base + QUP_IO_M_MODES);
size = QUP_IO_M_OUTPUT_BLOCK_SIZE(iomode);
if (size)
controller->out_blk_sz = size * 16;
else
controller->out_blk_sz = 4;
size = QUP_IO_M_INPUT_BLOCK_SIZE(iomode);
if (size)
controller->in_blk_sz = size * 16;
else
controller->in_blk_sz = 4;
size = QUP_IO_M_OUTPUT_FIFO_SIZE(iomode);
controller->out_fifo_sz = controller->out_blk_sz * (2 << size);
size = QUP_IO_M_INPUT_FIFO_SIZE(iomode);
controller->in_fifo_sz = controller->in_blk_sz * (2 << size);
dev_info(dev, "IN:block:%d, fifo:%d, OUT:block:%d, fifo:%d\n",
controller->in_blk_sz, controller->in_fifo_sz,
controller->out_blk_sz, controller->out_fifo_sz);
writel_relaxed(1, base + QUP_SW_RESET);
ret = spi_qup_set_state(controller, QUP_STATE_RESET);
if (ret) {
dev_err(dev, "cannot set RESET state\n");
goto error;
}
writel_relaxed(0, base + QUP_OPERATIONAL);
writel_relaxed(0, base + QUP_IO_M_MODES);
if (!controller->qup_v1)
writel_relaxed(0, base + QUP_OPERATIONAL_MASK);
writel_relaxed(SPI_ERROR_CLK_UNDER_RUN | SPI_ERROR_CLK_OVER_RUN,
base + SPI_ERROR_FLAGS_EN);
/* if earlier version of the QUP, disable INPUT_OVERRUN */
if (controller->qup_v1)
writel_relaxed(QUP_ERROR_OUTPUT_OVER_RUN |
QUP_ERROR_INPUT_UNDER_RUN | QUP_ERROR_OUTPUT_UNDER_RUN,
base + QUP_ERROR_FLAGS_EN);
writel_relaxed(0, base + SPI_CONFIG);
writel_relaxed(SPI_IO_C_NO_TRI_STATE, base + SPI_IO_CONTROL);
ret = devm_request_irq(dev, irq, spi_qup_qup_irq,
IRQF_TRIGGER_HIGH, pdev->name, controller);
if (ret)
goto error;
pm_runtime_set_autosuspend_delay(dev, MSEC_PER_SEC);
pm_runtime_use_autosuspend(dev);
pm_runtime_set_active(dev);
pm_runtime_enable(dev);
ret = devm_spi_register_master(dev, master); //spi_register_master, 注册spi_master设备
if (ret)
goto disable_pm;
return 0;
disable_pm:
pm_runtime_disable(&pdev->dev);
error:
clk_disable_unprepare(cclk);
clk_disable_unprepare(iclk);
spi_master_put(master);
return ret;
}
spi_master注册函数展开如下:
spi.c
int devm_spi_register_master(struct device *dev, struct spi_master *master)
{
struct spi_master **ptr;
int ret;
ptr = devres_alloc(devm_spi_unregister, sizeof(*ptr), GFP_KERNEL);
if (!ptr)
return -ENOMEM;
ret = spi_register_master(master);
if (!ret) {
*ptr = master;
devres_add(dev, ptr);
} else {
devres_free(ptr);
}
return ret;
}
int spi_register_master(struct spi_master *master)
{
static atomic_t dyn_bus_id = ATOMIC_INIT((1<<15) - 1);
struct device *dev = master->dev.parent;
struct boardinfo *bi;
int status = -ENODEV;
int dynamic = 0;
if (!dev)
return -ENODEV;
status = of_spi_register_master(master);
if (status)
return status;
/* even if it's just one always-selected device, there must
* be at least one chipselect
*/
if (master->num_chipselect == 0)
return -EINVAL;
if ((master->bus_num < 0) && master->dev.of_node)
master->bus_num = of_alias_get_id(master->dev.of_node, "spi");
/* convention: dynamically assigned bus IDs count down from the max */
if (master->bus_num < 0) {
/* FIXME switch to an IDR based scheme, something like
* I2C now uses, so we can't run out of "dynamic" IDs
*/
master->bus_num = atomic_dec_return(&dyn_bus_id);
dynamic = 1;
}
spin_lock_init(&master->bus_lock_spinlock);
mutex_init(&master->bus_lock_mutex);
master->bus_lock_flag = 0;
init_completion(&master->xfer_completion);
if (!master->max_dma_len)
master->max_dma_len = INT_MAX;
/* register the device, then userspace will see it.
* registration fails if the bus ID is in use.
*/
dev_set_name(&master->dev, "spi%u", master->bus_num);
status = device_add(&master->dev); //设备注册
if (status < 0)
goto done;
dev_dbg(dev, "registered master %s%s\n", dev_name(&master->dev),
dynamic ? " (dynamic)" : "");
/* If we're using a queued driver, start the queue */
if (master->transfer)
dev_info(dev, "master is unqueued, this is deprecated\n");
else {
status = spi_master_initialize_queue(master); //队列,工作线程初始化
if (status) {
device_del(&master->dev);
goto done;
}
}
mutex_lock(&board_lock);
list_add_tail(&master->list, &spi_master_list); //将spi_master加入spi_master_list
list_for_each_entry(bi, &board_list, list)
spi_match_master_to_boardinfo(master, &bi->board_info); //扫描board_list,对已经在list中的此master对应的slave设备进行注册
mutex_unlock(&board_lock);
/* Register devices from the device tree and ACPI */
of_register_spi_devices(master); //对dt中声明的此master对应的slave设备进行注册
acpi_register_spi_devices(master);
done:
return status;
}
至此,通过device_add函数,spi_master注册到内核。
3 总线传输
spi的总线传输分为同步传输和异步传输,同步传输较简单适合有少量数据的传输,异步传输较复杂,适合对大量数据的传输。本节对异步传输进行解释。总线传输涉及到几个重要的结构体,队列,内核工作线程和厂商的总线传输实现几个方面。
3.1 数据结构
transfer使用的几个链表数据结构的关系如下,它们是spi_mater, spi_message和spi_transfer。
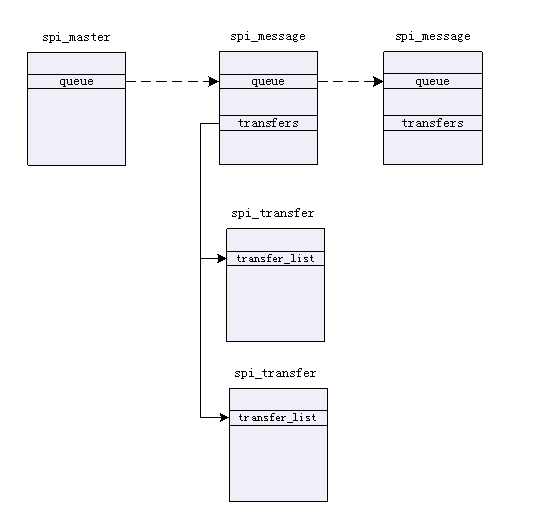

3.2 队列&内核工作线程
spi的总线传输是以spi_master->transfer进行实际的传输的。在实际传输之前要对结构体,队列,工作线程进行初始化。它们的初始化是在spi_master注册函数spi_register_master中调用 spi_master_initialize_queue实现的。spi_master_initialize_queue 实现spi_master成员函数transfer, transfer_one_message,queue和内核工作线程初始化。 spi.c
static int spi_master_initialize_queue(struct spi_master *master)
{
int ret;
master->transfer = spi_queued_transfer; //msater->transfer初始化
if (!master->transfer_one_message)
master->transfer_one_message = spi_transfer_one_message; //master->transfer_one_message初始化
/* Initialize and start queue */
ret = spi_init_queue(master); //master->queue和master->kworker初始化
if (ret) {
dev_err(&master->dev, "problem initializing queue\n");
goto err_init_queue;
}
master->queued = true;
ret = spi_start_queue(master);
if (ret) {
dev_err(&master->dev, "problem starting queue\n");
goto err_start_queue;
}
return 0;
}
transfer函数只是将上层传来的spi_message挂到一个链表上,然后就返回了,发送的调度是以kthread_worker和kthread_work机制实现的。worker通过创建一个内核线程,来串行执行kthread_work调用queue去排队的func。spi_init_queue实现了队列和工作线程的初始化。
spi.c
static int spi_init_queue(struct spi_master *master)
{
INIT_LIST_HEAD(&master->queue);
spin_lock_init(&master->queue_lock);
...
init_kthread_worker(&master->kworker); //初始化worker
master->kworker_task = kthread_run(kthread_worker_fn,
&master->kworker, "%s",
dev_name(&master->dev)); //worker线程的函数是kthread_worker_fn
if (IS_ERR(master->kworker_task)) {
dev_err(&master->dev, "failed to create message pump task\n");
return -ENOMEM;
}
init_kthread_work(&master->pump_messages, spi_pump_messages); //初始化work,定义work->func
}
transfer函数进行了入队操作,实现如下:
spi.c
static int spi_queued_transfer(struct spi_device *spi, struct spi_message *msg)
{
...
list_add_tail(&msg->queue, &master->queue);
if (!master->busy)
queue_kthread_work(&master->kworker, &master->pump_messages); //将work添加到worker的list中
...
}
kthread_worker中真正的func函数spi_pump_message实现了出队操作:
spi.c
static void spi_pump_messages(struct kthread_work *work)
{
struct spi_master *master =
container_of(work, struct spi_master, pump_messages);
...
/* Extract head of queue */
master->cur_msg =
list_first_entry(&master->queue, struct spi_message, queue); //从队列头取得spi_message
list_del_init(&master->cur_msg->queue);
...
if (!was_busy && master->prepare_transfer_hardware) { //未实现,pass
ret = master->prepare_transfer_hardware(master);
if (ret) {
dev_err(&master->dev,
"failed to prepare transfer hardware\n");
if (master->auto_runtime_pm)
pm_runtime_put(master->dev.parent);
return;
}
}
trace_spi_message_start(master->cur_msg);
if (master->prepare_message) { //未实现,pass
ret = master->prepare_message(master, master->cur_msg);
if (ret) {
dev_err(&master->dev,
"failed to prepare message: %d\n", ret);
master->cur_msg->status = ret;
spi_finalize_current_message(master);
return;
}
master->cur_msg_prepared = true;
}
ret = spi_map_msg(master, master->cur_msg); //未实现,pass
if (ret) {
master->cur_msg->status = ret;
spi_finalize_current_message(master);
return;
}
ret = master->transfer_one_message(master, master->cur_msg);
if (ret) {
dev_err(&master->dev,
"failed to transfer one message from queue\n");
return;
}
}
transfer_one_message实现如下,扫描msg->transfers为列表头的队列,调用master->transfer_one进行发送。transfer_one_message的发送数据结构是struct spi_message,transfer的发送数据结构是spi_transfer。
spi.c
static int spi_transfer_one_message(struct spi_master *master,
struct spi_message *msg)
{
struct spi_transfer *xfer;
bool keep_cs = false;
int ret = 0;
int ms = 1;
spi_set_cs(msg->spi, true);
list_for_each_entry(xfer, &msg->transfers, transfer_list) {
trace_spi_transfer_start(msg, xfer);
if (xfer->tx_buf || xfer->rx_buf) {
reinit_completion(&master->xfer_completion);
ret = master->transfer_one(master, msg->spi, xfer);
if (ret < 0) {
dev_err(&msg->spi->dev,
"SPI transfer failed: %d\n", ret);
goto out;
}
if (ret > 0) {
ret = 0;
ms = xfer->len * 8 * 1000 / xfer->speed_hz;
ms += ms + 100; /* some tolerance */
ms = wait_for_completion_timeout(&master->xfer_completion,
msecs_to_jiffies(ms));
}
if (ms == 0) {
dev_err(&msg->spi->dev,
"SPI transfer timed out\n");
msg->status = -ETIMEDOUT;
}
} else {
if (xfer->len)
dev_err(&msg->spi->dev,
"Bufferless transfer has length %u\n",
xfer->len);
}
trace_spi_transfer_stop(msg, xfer);
if (msg->status != -EINPROGRESS)
goto out;
if (xfer->delay_usecs)
udelay(xfer->delay_usecs);
if (xfer->cs_change) {
if (list_is_last(&xfer->transfer_list,
&msg->transfers)) {
keep_cs = true;
} else {
spi_set_cs(msg->spi, false);
udelay(10);
spi_set_cs(msg->spi, true);
}
}
msg->actual_length += xfer->len;
}
out:
if (ret != 0 || !keep_cs)
spi_set_cs(msg->spi, false);
if (msg->status == -EINPROGRESS)
msg->status = ret;
spi_finalize_current_message(master);
return ret;
}
spi_transfer在spi-qup.c的probe函数中已经进行了赋值,因此最终的transfer依赖于控制器厂商的实现。
异步传输函数spi_async是以spi_async—-> __spi_async—->master->transfer关系调用transfer函数的。
3.3 厂商的总线传输
控制器驱动注册函数中进行了传输函数的赋值。
master->transfer_one = spi_qup_transfer_one;
spi_qup_transfer_one的实现如下,涉及到控制器状态机的控制和向fifo写数据等寄存器操作。如果对此函数感兴趣可以查看qcom的spec。
spi_qup.c
static int spi_qup_transfer_one(struct spi_master *master,
struct spi_device *spi,
struct spi_transfer *xfer)
{
struct spi_qup *controller = spi_master_get_devdata(master);
unsigned long timeout, flags;
int ret = -EIO;
ret = spi_qup_io_config(spi, xfer);
if (ret)
return ret;
timeout = DIV_ROUND_UP(xfer->speed_hz, MSEC_PER_SEC);
timeout = DIV_ROUND_UP(xfer->len * 8, timeout);
timeout = 100 * msecs_to_jiffies(timeout);
reinit_completion(&controller->done);
spin_lock_irqsave(&controller->lock, flags);
controller->xfer = xfer;
controller->error = 0;
controller->rx_bytes = 0;
controller->tx_bytes = 0;
spin_unlock_irqrestore(&controller->lock, flags);
if (spi_qup_set_state(controller, QUP_STATE_RUN)) {
dev_warn(controller->dev, "cannot set RUN state\n");
goto exit;
}
if (spi_qup_set_state(controller, QUP_STATE_PAUSE)) {
dev_warn(controller->dev, "cannot set PAUSE state\n");
goto exit;
}
spi_qup_fifo_write(controller, xfer);
if (spi_qup_set_state(controller, QUP_STATE_RUN)) {
dev_warn(controller->dev, "cannot set EXECUTE state\n");
goto exit;
}
if (!wait_for_completion_timeout(&controller->done, timeout))
ret = -ETIMEDOUT;
exit:
spi_qup_set_state(controller, QUP_STATE_RESET);
spin_lock_irqsave(&controller->lock, flags);
controller->xfer = NULL;
if (!ret)
ret = controller->error;
spin_unlock_irqrestore(&controller->lock, flags);
return ret;
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180537.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
