大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
CRC是通信领域中用于校验数据传输正确性的最常用机制,也是Hash算法的一个典型应用,Hash一般翻译为“散列”,也可直接音译为“哈希”,就是把任意长度的输入(又叫做预映射,pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是散列值的空间通常远小于输入空间,不同的输入可能会散列成相同的输出,而不可能从散列值唯一的确定输入值。
CRC 也是一种 hash 算法!!!常见的Hash算法有:MAC,CRC,MD5/MD4,SHA等。
简单的哈希表的实现,c语言。
哈希表原理
哈希表是为了根据数据的部分内容(关键字),直接计算出存放完整数据的内存地址。
如果从链表中根据关键字查找一个元素,需要遍历才能得到这个元素的内存地址,如果链表长度很大,查找就需要更多的时间.
void* list_find_by_key(list,key)
{
for(p=list;p!=NULL; p=p->next){
if(p->key == key){
return p;
}
return p;
}
}
为了解决根据关键字快速找到元素的存放地址,哈希表应运而生。它通过某种算法(哈希函数)直接根据关键字计算出元素的存放地址,由于无需遍历,所以效率很高。
void* hash_table_find_by_key(table, key)
{
void* p = hash(key);
return p;
}当然,上面的伪代码忽略了一个重要的事实:那就是不同的关键字可能产生出同样的hash值。
hash("张三") = 23;
hash("李四") = 30;
hash("王五") = 23;这种情况称为“冲突”,为了解决这个问题,有两种方法:一是链式扩展;二是开放寻址。这里只讲第一种:链式扩展。
也就是把具有相同hash值的元素放到一起,形成一个链表。这样在插入和寻找数据的时候就需要进一步判断。
void* hash_table_find_by_key(table, key)
{
void* list = hash(key);
return list_find_by_key(list, key);
}需要注意的是,只要hash函数合适,这里的链表通常都长度不大,所以查找效率依然很高。
下图是一个哈希表运行时内存布局:
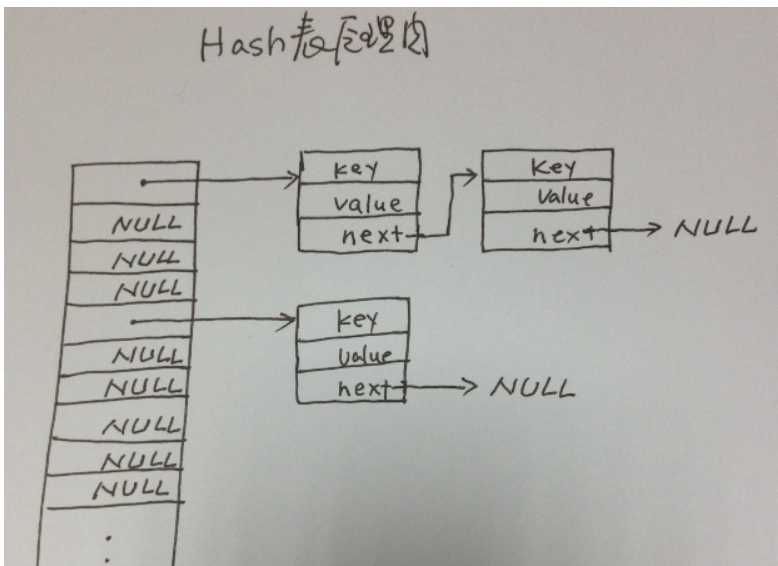

先说一下原理。
先是有一个bucket数组,也就是所谓的桶。
哈希表的特点就是数据与其在表中的位置存在相关性,也就是有关系的,通过数据应该可以计算出其位置。
这个哈希表是用于存储一些键值对(key -- value)关系的数据,其key也就是其在表中的索引,value是附带的数据。
通过散列算法,将字符串的key映射到某个桶中,这个算法是确定的,也就是说一个key必然对应一个bucket。
然后是碰撞问题,也就是说多个key对应一个索引值。举个例子:有三个key:key1,key3,key5通过散列算法keyToIndex得到的索引值都为2,也就是这三个key产生了碰撞,对于碰撞的处理,采取的是用链表连接起来,而没有进行再散列。
包含的头文件
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define BUCKETCOUNT 16哈希表和节点数据结构的定义

struct hashEntry
{
const char* key;
char* value;
struct hashEntry* next;
};
typedef struct hashEntry entry;
struct hashTable
{
entry bucket[BUCKETCOUNT]; //先默认定义16个桶
};
typedef struct hashTable table;
初始化和释放哈希表
//初始化哈希表
void initHashTable(table* t)
{
int i;
if (t == NULL)return;
for (i = 0; i < BUCKETCOUNT; ++i) {
t->bucket[i].key = NULL;
t->bucket[i].value = NULL;
t->bucket[i].next = NULL;
}
}
//释放哈希表
void freeHashTable(table* t)
{
int i;
entry* e,*ep;
if (t == NULL)return;
for (i = 0; i<BUCKETCOUNT; ++i) {
e = &(t->bucket[i]);
while (e->next != NULL) {
ep = e->next;
e->next = ep->next;
free(ep->key);
free(ep->value);
free(ep);
}
}
}
哈希散列算法
//哈希散列方法函数
int keyToIndex(const char* key)
{
int index , len , i;
if (key == NULL)return -1;
len = strlen(key);
index = (int)key[0];
for (i = 1; i<len; ++i) {
index *= 1103515245 + (int)key[i];
}
index >>= 27;
index &= (BUCKETCOUNT - 1);
return index;
}
辅助函数strDup
这是比较多余的做法,因为C标准库中string.h中有一系列这样的函数。
//在堆上分配足以保存str的内存
//并拷贝str内容到新分配位置
char* strDup(const char* str)
{
int len;
char* ret;
if (str == NULL)return NULL;
len = strlen(str);
ret = (char*)malloc(len + 1);
if (ret != NULL) {
memcpy(ret , str , len);
ret[len] = '\0';
}
return ret;
}
string.h中的相关函数
#include <string.h>
char *strdup(const char *s);
char *strndup(const char *s, size_t n);
char *strdupa(const char *s);
char *strndupa(const char *s, size_t n);
哈希表的插入和修改
这个了插入和修改是一个方法,如果key在哈希表中已经存在,那么就是修改value,否则就是插入一个节点。
//向哈希表中插入数据
int insertEntry(table* t , const char* key , const char* value)
{
int index , vlen1 , vlen2;
entry* e , *ep;
if (t == NULL || key == NULL || value == NULL) {
return -1;
}
index = keyToIndex(key);
if (t->bucket[index].key == NULL) {
t->bucket[index].key = strDup(key);
t->bucket[index].value = strDup(value);
}
else {
e = ep = &(t->bucket[index]);
while (e != NULL) { //先从已有的找
if (strcmp(e->key , key) == 0) {
//找到key所在,替换值
vlen1 = strlen(value);
vlen2 = strlen(e->value);
if (vlen1 > vlen2) {
free(e->value);
e->value = (char*)malloc(vlen1 + 1);
}
memcpy(e->value , value , vlen1 + 1);
return index; //插入完成了
}
ep = e;
e = e->next;
} // end while(e...
//没有在当前桶中找到
//创建条目加入
e = (entry*)malloc(sizeof (entry));
e->key = strDup(key);
e->value = strDup(value);
e->next = NULL;
ep->next = e;
}
return index;
}
哈希表中查找
因为这个哈希表中保存的是键值对,所以这个方法是从哈希表中查找key对应的value的。要注意,这里返回的是value的地址,不应该对其指向的数据进行修改,否则可能会有意外发生。
//在哈希表中查找key对应的value
//找到了返回value的地址,没找到返回NULL
const char* findValueByKey(const table* t , const char* key)
{
int index;
const entry* e;
if (t == NULL || key == NULL) {
return NULL;
}
index = keyToIndex(key);
e = &(t->bucket[index]);
if (e->key == NULL) return NULL;//这个桶还没有元素
while (e != NULL) {
if (0 == strcmp(key , e->key)) {
return e->value; //找到了,返回值
}
e = e->next;
}
return NULL;
}
哈希表元素的移除
这个函数用于将哈希表中key对应的节点移除,如果其不存在,那就返回NULL。如果存在,就返回这个节点的地址。注意,这里并没有释放节点,如果不需要了,应该手动释放它。
//在哈希表中查找key对应的entry
//找到了返回entry,并将其从哈希表中移除
//没找到返回NULL
entry* removeEntry(table* t , char* key)
{
int index;
entry* e,*ep; //查找的时候,把ep作为返回值
if (t == NULL || key == NULL) {
return NULL;
}
index = keyToIndex(key);
e = &(t->bucket[index]);
while (e != NULL) {
if (0 == strcmp(key , e->key)) {
//如果是桶的第一个
if (e == &(t->bucket[index])) {
//如果这个桶有两个或以上元素
//交换第一个和第二个,然后移除第二个
ep = e->next;
if (ep != NULL) {
entry tmp = *e; //做浅拷贝交换
*e = *ep;//相当于链表的头节点已经移除
*ep = tmp; //这就是移除下来的链表头节点
ep->next = NULL;
}
else {//这个桶只有第一个元素
ep = (entry*)malloc(sizeof(entry));
*ep = *e;
e->key = e->value = NULL;
e->next = NULL;
}
}
else {
//如果不是桶的第一个元素
//找到它的前一个(这是前面设计不佳导致的多余操作)
ep = &(t->bucket[index]);
while (ep->next != e)ep = ep->next;
//将e从中拿出来
ep->next = e->next;
e->next = NULL;
ep = e;
}
return ep;
}// end if(strcmp...
e = e->next;
}
return NULL;
}
哈希表打印
这个函数用于打印哈希表的内容的。
void printTable(table* t)
{
int i;
entry* e;
if (t == NULL)return;
for (i = 0; i<BUCKETCOUNT; ++i) {
printf("\nbucket[%d]:\n" , i);
e = &(t->bucket[i]);
while (e->key != NULL) {
printf("\t%s\t=\t%s\n" , e->key , e->value);
if (e->next == NULL)break;
e = e->next;
}
}
}
测试一下
用于测试的数据来自于本机相关信息。
int main()
{
table t;
initHashTable(&t);
insertEntry(&t , "电脑型号" , "华硕 X550JK 笔记本电脑");
insertEntry(&t , "操作系统" , "Windows 8.1 64位 (DirectX 11)");
insertEntry(&t , "处理器" , "英特尔 Core i7 - 4710HQ @ 2.50GHz 四核");
insertEntry(&t , "主板" , "华硕 X550JK(英特尔 Haswell)");
insertEntry(&t , "内存" , "4 GB(Hynix / Hyundai)");
insertEntry(&t , "主硬盘" , "日立 HGST HTS541010A9E680(1 TB / 5400 转 / 分)");
insertEntry(&t , "显卡" , "NVIDIA GeForce GTX 850M (2 GB / 华硕)");
insertEntry(&t , "显示器" , "奇美 CMN15C4(15.3 英寸)");
insertEntry(&t , "光驱" , "松下 DVD - RAM UJ8E2 S DVD刻录机");
insertEntry(&t , "声卡" , "Conexant SmartAudio HD @ 英特尔 Lynx Point 高保真音频");
insertEntry(&t , "网卡" , "瑞昱 RTL8168 / 8111 / 8112 Gigabit Ethernet Controller / 华硕");
insertEntry(&t , "主板型号" , "华硕 X550JK");
insertEntry(&t , "芯片组" , "英特尔 Haswell");
insertEntry(&t , "BIOS" , "X550JK.301");
insertEntry(&t , "制造日期" , "06 / 26 / 2014");
insertEntry(&t , "主人" , "就是我");
insertEntry(&t , "价格" , "六十张红色毛主席");
insertEntry(&t , "主硬盘" , "换了个120G的固态");
entry* e = removeEntry(&t , "主板型号");
if (e != NULL) {
puts("找到后要释放");
free(e->key);
free(e->value);
free(e);
e = NULL;
}
printTable(&t);
const char* keys[] = { "显示器" , "主人","没有" , "处理器" };
for (int i = 0; i < 4; ++i) {
const char* value = findValueByKey(&t , keys[i]);
if (value != NULL) {
printf("find %s\t=\t%s\n" ,keys[i], value);
}
else {
printf("not found %s\n",keys[i]);
}
}
freeHashTable(&t);
getchar();
return 0;
}—————————————————————————————————————————————-
#include <stdio.h>
#define HASH_SIZE 10
typedef struct Node{
char key[50];
char value[50];
struct Node *next;
} NODE;
typedef unsigned int uint;
NODE *node[HASH_SIZE];
/*init hash node*/
int init(NODE *node)
{
node=(NODE *)malloc(sizeof(NODE));
if(node == NULL)
return 1;
bzero(node, sizeof(NODE));
return 0;
}
/*计算哈希值*/
uint hash_index(const char *key)
{
uint hash=0;
char *p = key;
for(;*p;p++){
hash = hash*33+*p;
}
return hash%HASH_SIZE;
}
/*查找:根据哈希值得出index, 然后到对应的链表中查找*/
NODE *lookup(const char *key)
{
char *value = NULL;
uint index=0;
int i = 0;
NODE *np=NULL;
index=hash_index(key);
for(np=node[index]; np; np=np->next)
if(strcmp(np->key,key)==0)
return np;
return NULL;
}
/*插入:先查找该值是否存在,然后计算哈希值,插入对应的链表*/
uint install(const char *key, const char *value)
{
NODE *np = NULL;
np = lookup(key);
uint index = 0;
if(!np){
index=hash_index(key);
np =(NODE *)malloc(sizeof(NODE));
if(!np)
return 1;
strcpy(np->key,key);
strcpy(np->value,value);
np->next=node[index];
node[index]=np;
}
return 0;
}
int main(void)
{
/*为哈希表插入一组数据*/
char key[17] = "10.10.16.31";
char value[4] = "001";
install(key, value);
char key1[17] = "10.10.16.32";
char value1[4] = "002";
install(key1, value1);
char key2[17] = "10.10.16.33";
char value2[4] = "003";
install(key2, value2);
char key3[17] = "10.10.16.34";
char value3[4] = "004";
install(key3, value3);
char key4[17] = "10.10.16.41";
char value4[4] = "005";
install(key4, value4);
NODE *np;
/*哈希表初始化:如果不为表头赋值的话可以省略*/
int i,j;
for(i=0;i<HASH_SIZE;i++){
init(node[i]);
}
/*遍历哈希表*/
for(i=0; i<HASH_SIZE; i++)
{
if(node[i]){
printf("i:%d, key:%s, value:%s\n", i, node[i]->key, node[i]->value);
np = node[i]->next;
while(np){
printf("key:%s, value:%s\n", np->key, np->value);
np = np->next;
}
}
}
return 0;
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180146.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
