大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Spring Cloud Eureka 原理分析
1 简介
在微服务架构下,服务端环境通常包含多个服务,同时每个服务也是一个无状态的多实例集群。这些服务和实例一般都是会动态变化的,可能会因为意外的故障或者人为的重启发版等原因,这些服务和实例的信息和数量随时会发生改变。因此微服务环境下需要一个服务注册中心来集中管理集群中各个服务实例的状态,这样服务的调用方就可以动态地从服务注册中心获取到当前可用的服务实例来发起调用。
Eureka 就是服务发现中心的一种。Eureka 一开始是由 Netflix 开源的用于服务注册的组件,之后 Spring Cloud 对其进行封装和集成,添加到了 Spring Cloud 微服务生态。
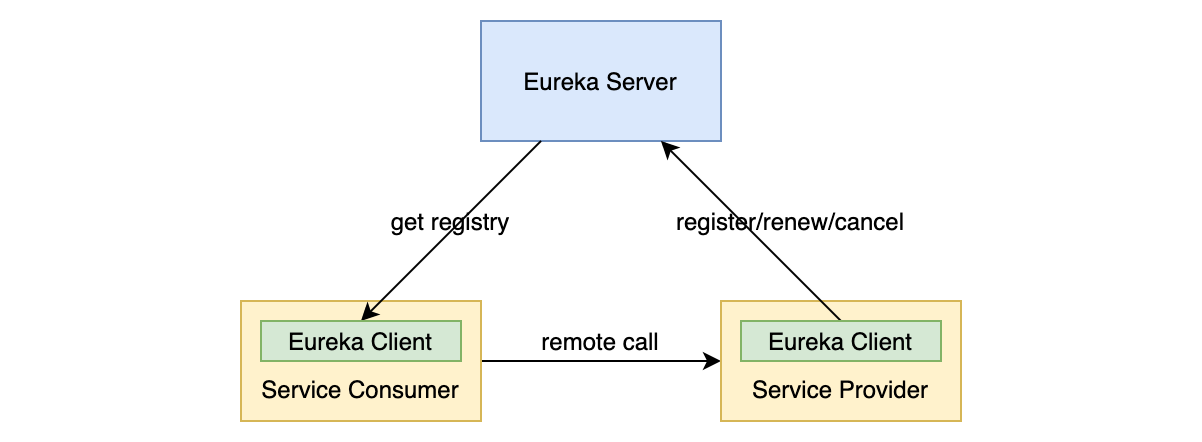
2 架构
Eureka 由 Eureka Server 和 Eureka Client 两部分组成。
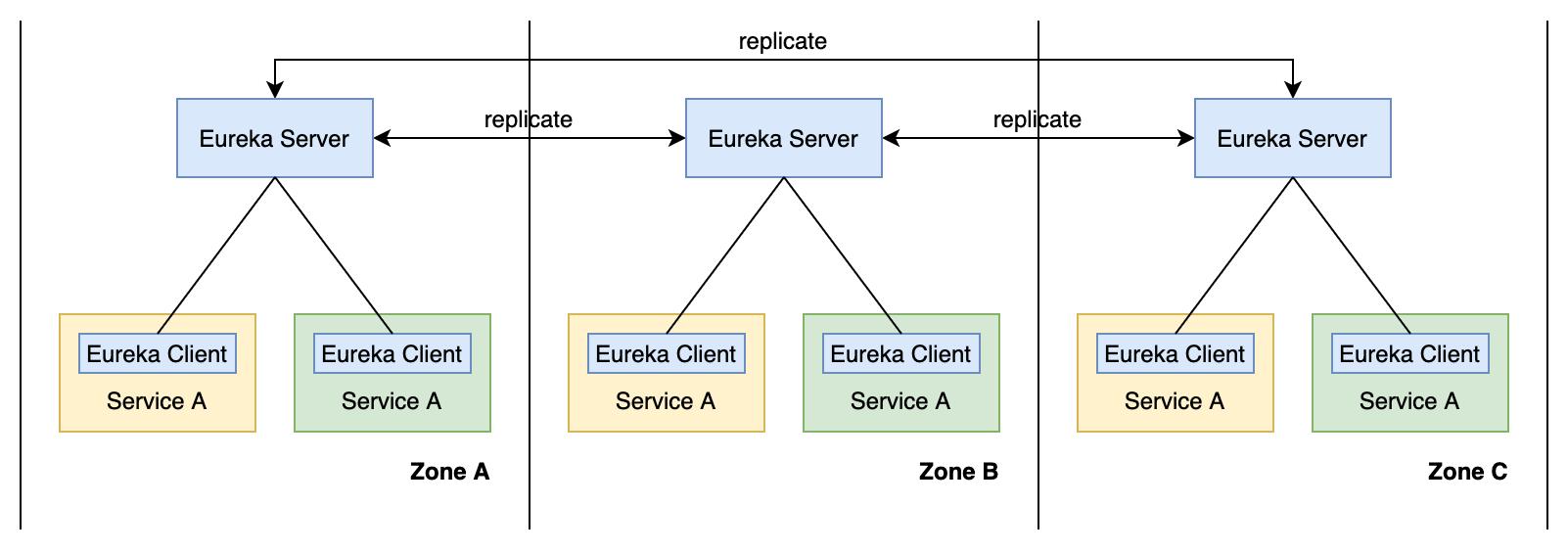
- Server 是服务注册中心,负责维护集群中的服务实例信息和状态,以及给 Client 返回服务列表。在分布式环境下一般会多实例部署来达到高可用,比如在多个可用区上均部署 Eureka Server。
- Client 是一个嵌入到业务服务的模块,负责与 Server 交互,包括发送注册请求、维持心跳、拉取服务列表等。
引入了服务发现中心后,需要为其他应用提供服务的应用在启动时需要先通过 Eureka Client 向 Eureka Server 发送注册请求,把自己的服务信息注册到 Eureka Server 上,同时需要定期发送心跳。
在应用下线时发送取消注册请求,把自身从 Eureka Server 的服务列表里删除。在多实例部署的情况下,Eureka Client 需要根据一定的策略选择一个目标 Server 进行通讯,这个过程在后面会详细介绍。
而服务的调用方在发起调用时需要先从 Eureka Server 获取服务实例列表,然后可以根据客户端的负载均衡策略选择一个实例,然后再向该实例发起调用请求。
下面基于 spring-cloud-starter-eureka 版本 1.3.2.RELEASE 的代码,分别介绍一下 Eureka Server 和 Eureka Client 两者的工作原理。
3 服务端原理
Eureka Server 负责管理整个集群服务实例信息,有新实例注册时需要为其创建和管理对应的 Lease ,同时还负责把 Lease 的变更同步给集群中其他的 Eureka Server,以保证集群中所有的 Eureka Server 节点的服务列表最终一致。Eureka Server 会把这些 Lease 维护在一个 PeerAwareInstanceRegistry 里,当有 Eureka Client 需要获取服务列表时,需要从中获取这些 Lease 信息返回。
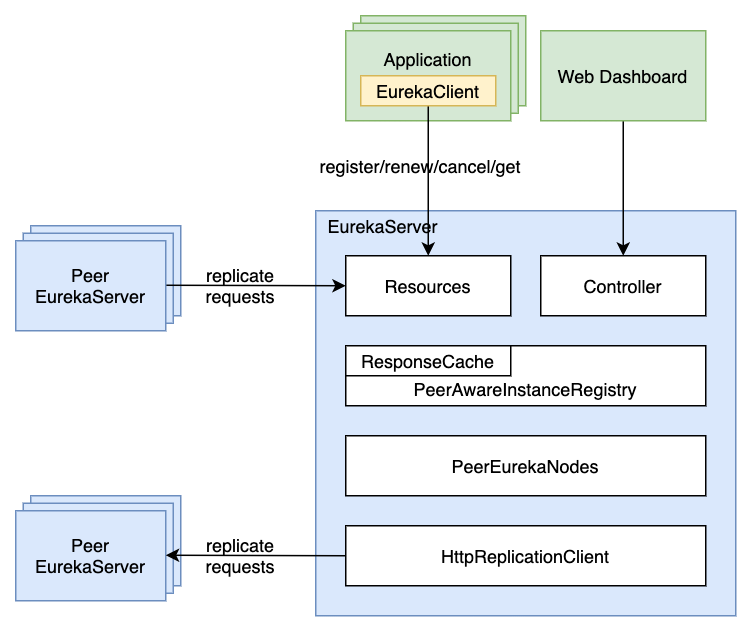
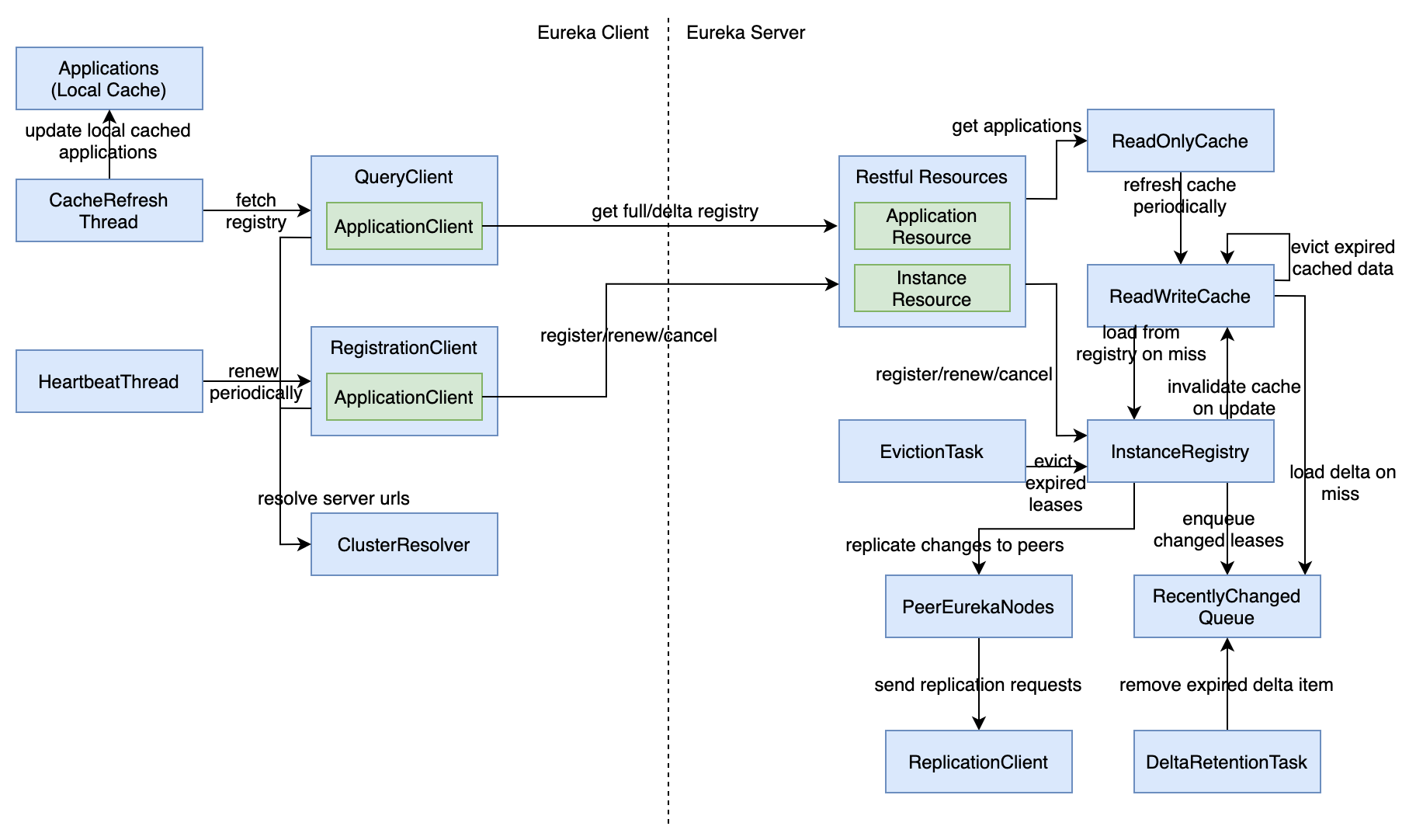
Eureka Server 几个关键模块的关系如下图。这里面最核心的是 PeerAwareInstanceRegistry ,它记录了当前注册过的所有服务实例的信息和状态。
Resources:这部分对外暴露了一系列的 Restful 接口。Eureka Client 的注册、心跳、获取服务列表等操作都需要调用这些接口。另外,其他的 Server 在同步 Registry 时也需要调用这些接口。Controller:这里提供了几个 web 接口,主要用在 Eureka Server 本身的 Dashboard 页面, 从页面上可以查看到当前注册了的服务,以及每个服务下各个实例的状态。PeerAwareInstanceRegistry:这里面记录了当前注册了的服务实例。当这些注册信息发生变化时,PeerAwareInstanceRegistry还要负责把这些变化同步到其他的 Server。PeerEurekaNodes:这里维护了集群里所有 Eureka Server 节点的信息,PeerAwareInstanceRegistry在同步时需要从这里获取其他 Server 的信息。同时它还负责定时检查配置来发现是否有 Eureka Server 节点新增或删除。HttpReplicationClient:这是PeerAwareInstanceRegistry向其他 Server 同步时发送请求的 http client。
3.1 Lease
服务向 Eureka Server 注册时,Eureka Server 会为其创建一个 Lease 。这些 Lease 是维护在上面说到的 PeerAwareInstanceRegistry 里的,它维护了一个 Map 结构
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry;
这是一个双重 Map,记录每个服务下有哪些实例,以及每个实例对应的 Lease 。 Lease 里记录了对应实例的注册时间和上次更新时间。
public class Lease<T> {
// ...
private long evictionTimestamp;
private long registrationTimestamp;
private long serviceUpTimestamp;
private volatile long lastUpdateTimestamp;
private long duration;
// ...
}
一个实例注册时会在 registry 里添加一个 Lease ,发送心跳时会更新 Lease 的时间,Lease 的有效期默认是 90 秒。有效期内未更新的 Lease 会被认为过期。
PeerAwareInstanceRegistry 会定时执行一个 EvictionTask ,将过期的 Lease 删除。EvictionTask 的默认执行周期是 60 秒,可以通过配置项修改。
eureka.server.evictionIntervalTimerInMs=60 * 1000
3.2 服务注册列表增量变更
PeerAwareInstanceRegistry 记录了所有服务实例的状态,当 Eureka Client 获取服务列表时可以遍历这个列表返回。但是一般情况下,集群中短期内发生变化的实例数量不会太多,尤其是当集群比较大的时候,每次刷新服务列表时都全量返回其实并不必要。因此 Eureka Server 除了提供全量获取服务的接口,还提供了获取近期出现变更的服务实例的接口。
Eureka Server 实现增量的方式每次在更新服务列表后,都把有变更的实例 Lease 记录在一个队列里(包括实例新增,实例删除,实例的状态变更的情况)
private ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue;
和这个队列相关的关键配置是
eureka.server.retentionTimeInMSInDeltaQueue=3 * 60 * 1000
eureka.server.deltaRetentionTimerIntervalInMs=30 * 1000
retentionTimeInMSInDeltaQueue 表示队列里的元素保留时间,默认是 3 分钟。 deltaRetentionTimerIntervalInMs 表示检查删除队列里过期元素的时间间隔。也就是说,我们可以近似认为最近 3 分钟内(实际上最久可能是最近 3 分 30 秒内),新增的实例、删除的实例以及状态发生变化的实例对应的 Lease 都会保留在这个队列里。
当 Eureka Client 以增量的方式请求获取服务列表时,Eureka Server 会把这个列表里的元素对应的 Lease 返回给 Eureka Client。这里有个问题是,Eureka Client 获取的增量服务列表是有可能包含重复信息,Eureka 要求由客户端处理这种重复的情况。
具体的 Eureka Client 获取服务列表的方式会在后面分析客户端原理时详细说明。
3.3 Response 缓存
Eureka Server 的接口支持以 JSON 和 XML 的格式返回数据,还支持对数据压缩。Eureka Client 在获取服务列表时,Eureka Server 会把服务实例信息按请求的格式序列化和压缩后返回。当集群里 Eureka Client 比较多时,如果每次返回响应时都去做序列化和压缩,那么就会浪费资源在重复的操作上。Eureka Server 对响应做了缓存,这样在处理 Eureka Client 请求时就可以直接从缓存获得已经序列化完成和压缩完成的数据返回了。
Eureka Server 的缓存分为两层,它们之间的关系如下图。

ReadOnlyCache 顾名思义是只读的,它会定期从 ReadWriteCache 读取数据来刷新自己的数据。刷新的周期可以通过配置控制,默认是 30 秒。
eureka.server.responseCacheUpdateIntervalMs=30 * 1000
ReadWriteCache 并不会定期刷新自身的数据,只会在出现 cache miss 时再从 Registry 获取对应的数据。ReadWriteCache 缓存的数据失效的情况有两种。 一是当 Registry 发生变更时会调用 invalidate 方法使 ReadWriteCache 对应的数据失效,二是缓存的数据超时自动过期失效。过期时间默认是 180 秒,可以通过配置修改。
eureka.server.responseCacheAutoExpirationInSeconds=180
默认情况下 Eureka Client 获取服务的请求会从 ReadOnlyCache 返回。因为 ReadOnlyCache 是定时刷新的,所以有可能拿到的结果并不是最新的。ReadOnlyCache 可以通过配置关闭。
eureka.server.useReadOnlyResponseCache=false
不使用 ReadOnlyCache 时响应从 ReadWriteCache 返回。因为 ReadWriteCache 不会自动定时刷新,所以出现 cache miss 的请求会需要相对更长的时间才能返回。
3.4 自我保护模式
自我保护模式的作用是防止当出现网络分隔,服务虽然正常运行但无法与 Eureka Server 保持心跳的情况下,Eureka Server 把这些服务实例当作过期实例而删除。如下图,服务本身是正常的,但服务发送心跳的网络发生异常。如果没有自我保护模式,那么这些服务实例会被过期删除,此时服务调用方将无法从 Eureka Server 获取到这些服务。
前面的介绍有提到过,**过期的 Lease 会被 EvictionTask 删除。EvictionTask 执行时会先判断 Eureka Server 当前是否处于自我保护模式。**在自我保护模式下,EvictionTask 不会删除过期的实例,但新的实例依旧可以正常注册。
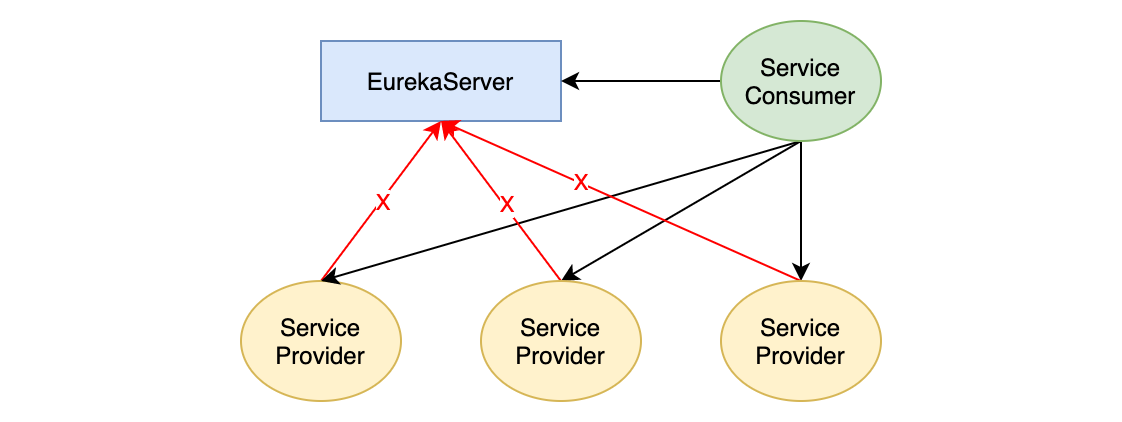
自我保护模式的触发条件是当 Eureka Server 最近一分钟实际收到的心跳数低于最少心跳数阈值。
public boolean isLeaseExpirationEnabled() {
if (!isSelfPreservationModeEnabled()) {
return true;
}
return numberOfRenewsPerMinThreshold > 0 && getNumOfRenewsInLastMin() > numberOfRenewsPerMinThreshold;
}
其中 numberOfRenewsPerMinThreshold 是通过当前已注册的实例数目算出来的。
this.numberOfRenewsPerMinThreshold = (int) ((count * 2) * serverConfig.getRenewalPercentThreshold());
count 指的是当前注册的实例数目, count * 2 即理想情况下每分钟应收到的心跳数(心跳间隔 30 秒), renewalPercentThreshold 是最低心跳数阈值百分比,默认值是 0.85。也就是说,默认情况下,当最近一分钟的收到的心跳次数低于应该收到的心跳次数的 85% 时,就会进入自我保护,此时过期的实例不会被删除,直到心跳次数恢复到 85% 以上。
心跳次数阈值百分比可以通过配置设置。
eureka.server.renewalPercentThreshold=0.85
另外可以通过配置把自我保护模式关闭,关闭后无论收到多少次心跳,过期的实例都会被删除。
eureka.server.enableSelfPreservation=false
3.5 一致性和可用性
Eureka Server 集群的节点没有主从之分,每个节点都可以同时处理读写请求。虽然节点收到的写请求会同步到其他节点,但是没有采用任何措施(比如一致性协议)保证写请求同步到其节点。因此 Eureka Server 并不能保证数据的强一致,只能保证当集群稳定时,各个节点的数据最终会达到一致,但在这之前,不同节点返回的数据可能不一样。
牺牲数据一致性换来的是集群更高的可用性。CP 系统一般要求集群至少有过半数的节点存活,才能保证正常处理读写请求。而 Eureka Server 集群只需要至少有一个节点存活,就能够正常提供服务,虽然此时集群返回的数据不一定准确。
因此,Eureka Server 集群是一个 AP 系统。作为一个服务注册中心,这意味着当集群发生极端异常时,与其为了保证服务列表的一致性而使服务注册不可用,它选择尽可能保证服务发现功能可用而牺牲服务注册列表的准确性。
4 客户端原理
Eureka Client 封装了与 Eureka Server 进行各种交互的代码逻辑。集群中的服务需要引入 Eureka Client,并通过 Eureka Client 与 Eureka Server 进行交互。Eureka Client 的主要职责包括
- 服务启动时注册服务
- 定时发送心跳来更新
Lease - 服务下线时取消注册
- 获取和定时更新已注册的服务列表
如果一个服务只调用其他服务,但自身不提供服务,那么可以通过配置控制不注册自身实例
eureka.client.registerWithEureka=false
相反,如果一个服务只提供服务,但不需要调用其他服务,那么可以配置不获取服务列表
eureka.client.fetchRegistry=false
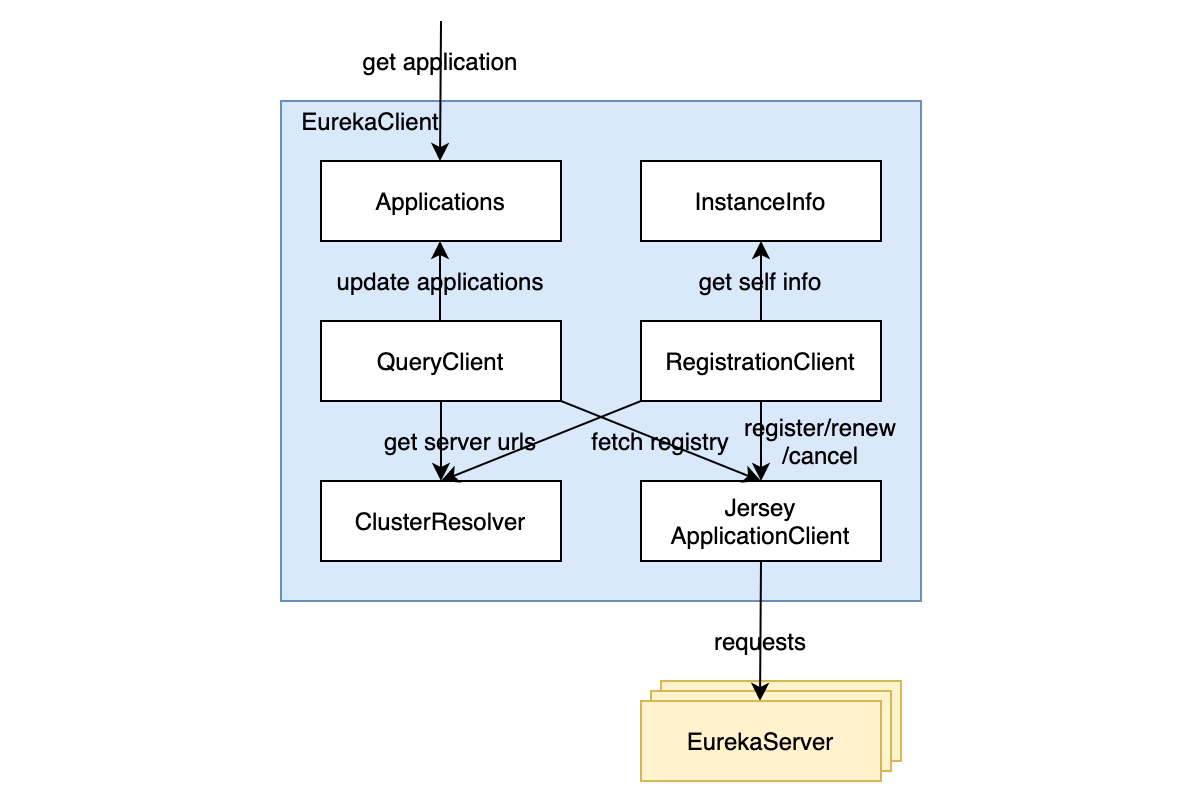
上图是 Eureka Client 的内部结构。
Applications:保存了从 Eureka Server 获取到的服务信息,相当于 Eureka Client 端的服务列表缓存。InstanceInfo:维护了自身服务实例的信息,注册和心跳时需要用到。QueryClient:负责从 Eureka Server 获取已注册的服务,并且更新Applications。RegistrationClient:负责在服务启动时发送注册请求,然后定期发送心跳,最后在服务下线之前取消注册。ClusterResolver:QueryClient和RegistrationClient在发送请求前需要先知道 Eureka Server 的地址,ClusterResolver可以根据不同的策略和实现返回 Eureka Server 地址列表以供选择。JerseyApplicationClient:是真正发送网络请求的 Http client,QueryClient和RegistrationClient获取到 Eureka Server 地址后会创建一个JerseyApplicationClient和该 Eureka Server 通讯。
4.1 获取 Server 地址
Eureka Client 在和 Eureka Server 通讯之前,需要先获得 Eureka Server 的地址。如果 Eureka Server 是多实例部署的,那么还需要对这些地址做优先级排序,然后 Eureka Client 在发起调用时会按顺序调用,失败时再尝试下一个 Eureka Server。
Eureka Server 的地址由 ClusterResolver 提供。它暴露了一个接口用来返回 Eureka Server 地址列表。
public interface ClusterResolver<T extends EurekaEndpoint> {
// ...
List<T> getClusterEndpoints();
}
默认情况使用的是 ConfigClusterResolver ,从配置文件里获取 Eureka Server 地址。
ConfigClusterResolver 会被 ZoneAffinityClusterResolver 代理,ZoneAffinityClusterResolver 会进一步根据是否和实例本身处于同一个可用区,把 Eureka Server 地址分成两部分,然后在随机排列后,按同区在前,不同区在后的顺序返回 Eureka Server 地址列表。
后续 Eureka Client 在发送请求时会以这个列表的顺序作为优先级选择 Eureka Server。这样做可以让 Eureka Client 优先和同区的 Eureka Server 交互。随机化能让 Eureka Server 负载尽量平均。
4.2 构造 EurekaHttpClient
在知道如何获取 Eureka Server 地址列表之后,Eureka Client 还需要创建 EurekaHttpClient 对象来发起 http 请求。
Eureka Client 在初始化时需要创建两个 EurekaHttpClient, 分别是 QueryClient 和 RegistrationClient 。QueryClient 主要负责发送获取服务列表请求,RegistrationClient 负责发送注册、心跳等请求。
从类图来看,EurekaHttpClient 使用装饰者模式。
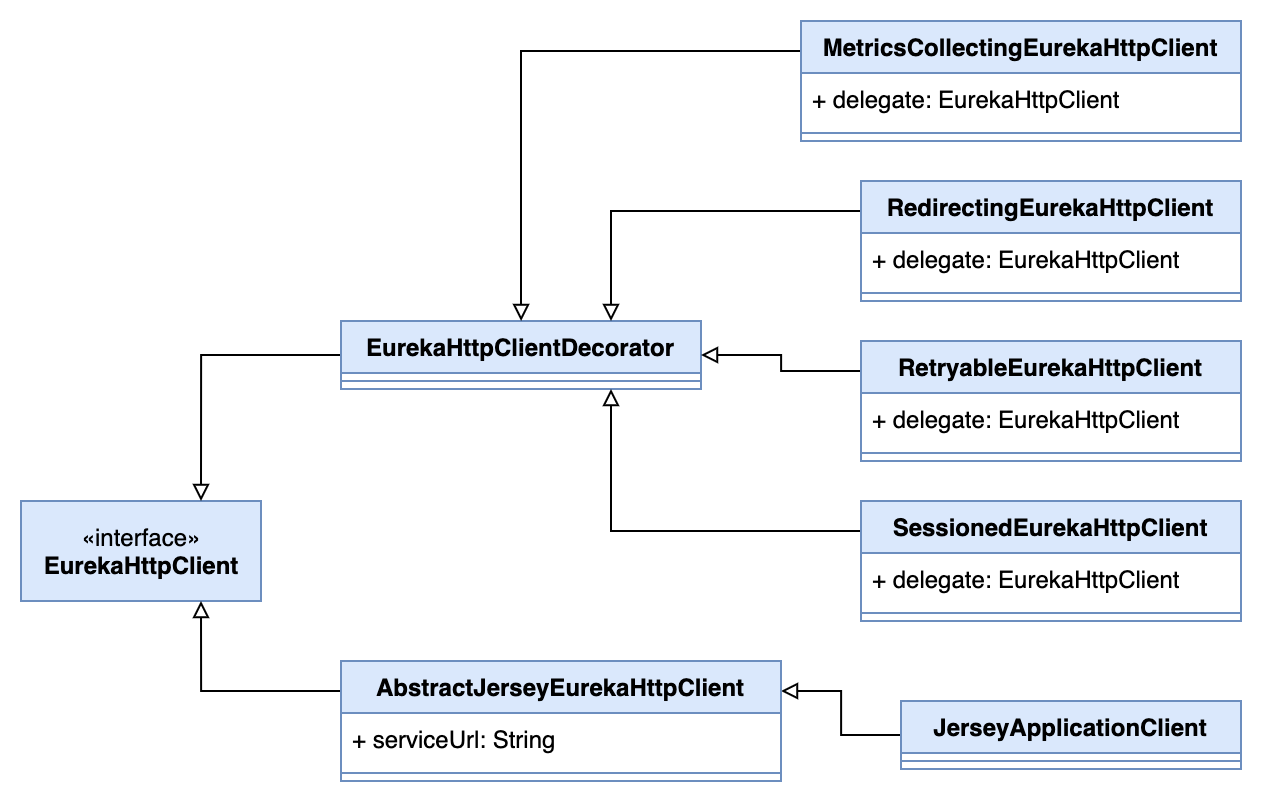
JerseyApplicationClient 是最终负责发送请求的实现,在其之上做了装饰。最后生成的 client 结构如下图。QueryClient 和 RegistrationClient 生成 client 的方式是一样的,只是在使用时调用的接口不同。QueryClient 只使用了和获取服务相关的接口,而 RegistrationClient 需要调用注册、心跳等接口。

JerseyApplicationClient 创建时需要一个 Eureka Server 的 Url,它只会向该 Eureka Server 发送请求。在 JerseyApplicationClient 之外套了多个装饰类。
-
MetricsCollectingEurekaHttpClient用于对请求和响应做统计,比如请求用时,响应返回码统计等。 -
RedirectingEurekaHttpClient主要处理了重定向。当请求返回 302 时,RedirectingEurekaHttpClient会根据返回的重定向地址创建新的JerseyApplicationClient,然后重试请求。 -
RetryableEurekaHttpClient实现了重试的逻辑。同时维护了一个quarantineSet,执行请求返回失败的 Eureka Server 会被加入其中,然后再寻找下一个可用的 Eureka Server 重试请求。quarantineSet有大小阈值,当超过阈值时,里面的 Eureka Server 会被释放出来,下次重试请求时会再次尝试这些 Eureka Server。这个阈值可以通过配置设置。eureka.client.transport.retryableClientQuarantineRefreshPercentage=0.66默认情况下,当
quarantineSet里包括超过三分之二的 Eureka Server 时,quarantineSet会被重置,之前在里面的 Eureka Server 会被重新当作可用的。RetryableEurekaHttpClient整体的工作流程图如下。其中的currentHttpClient指的是被RetryableEurekaHttpClient装饰的对象。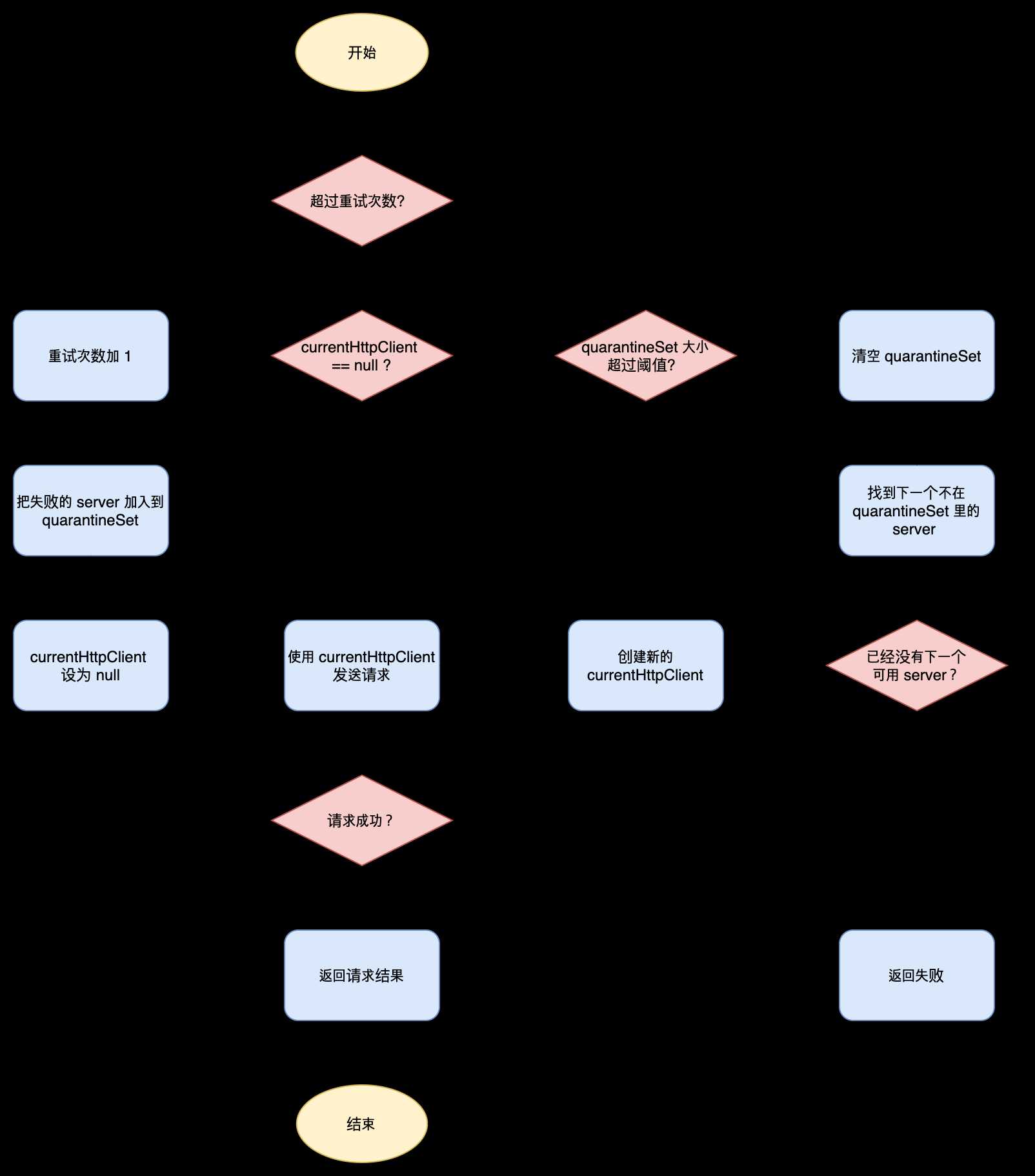

-
SessionedEurekaHttpClient装饰了RetryableEurekaHttpClient并为其创建一个 session。当 session 时间过后,RetryableEurekaHttpClient会被重新创建。这样做的目的是为了使集群中 Eureka Server 节点的负载尽量平均。假设现在集群里添加了一个新的 Eureka Server 节点,如果创建新 的 client,那么除非发生异常切换,否则现有的 Eureka Client 还是会把请求发到老的 Eureka Server 节点,而新的节点不会收到请求。
SessionedEurekaHttpClient在当前 session 结束创建新 session 时给了 Eureka Client 重新选择 Eureka Server 的机会,能让集群里的 Eureka Client 尽量连接到不同的 Eureka Server。session 的时长可以通过配置设置。
eureka.client.transport.sessionedClientReconnectIntervalSeconds=20 * 60最终使用的 session 时长会在这个配置值的基础上加上一个随机值,这个随机值的区间是
[-sessionDuration / 2, sessionDuration / 2]也就是说默认情况下 session 的时长范围是 10 到 30 分钟。
4.3 获取服务列表
服务调用方在调用其他服务时需要先从 Eureka Server 获取服务列表,但这一过程不需要每次发起调用时都重复。Eureka Client 会在本地维护一份服务列表的缓存,并负责和 Eureka Server 同步来更新缓存。
Eureka Client 在启动会先从 Eureka Server 获取全量的服务列表,并保存到本地。随后 Eureka Client 还要定时获取服务列表来更新本地缓存。更新缓存的时间间隔可以通过配置设置,默认是 30 秒。
eureka.client.registryFetchIntervalSeconds=30
由于正常情况下集群中大部分的服务实例信息不会发生变化,所以没有必要每次在更新时都全量拉取服务列表。Eureka Client 在更新服务列表缓存时会优先使用增量更新的方式。
前面介绍服务端原理的时候有介绍过 Eureka Server 会维护一个 recentlyChangedQueue ,里面保存最近一段时间有发生变化的实例,这些信息会在 recentlyChangedQueue 保留一段时间,过期后删除。Eureka Server 返回增量变化信息其实就是读取的 recentlyChangedQueue 的内容。因此使用增量更新的方式需要处理两个问题。
- 如果 Eureka Client 因为某些原因(比如网络异常)长时间没能获取到增量变更,那么
recentlyChangedQueue里的内容会被删除,被删除的信息后续 Eureka Client 就再也不能从增量接口获取到了, Eureka Client 本地的缓存因此会丢失更新。此时 Eureka Client 需要重新全量获取服务列表以保持和 Eureka Server 的数据一致。 - Eureka Client 前后两次获取到的增量信息内容是有可能重复的,Eureka Client 要能处理这种重复的响应。
先看一下 Eureka Client 获取服务列表相关的流程。
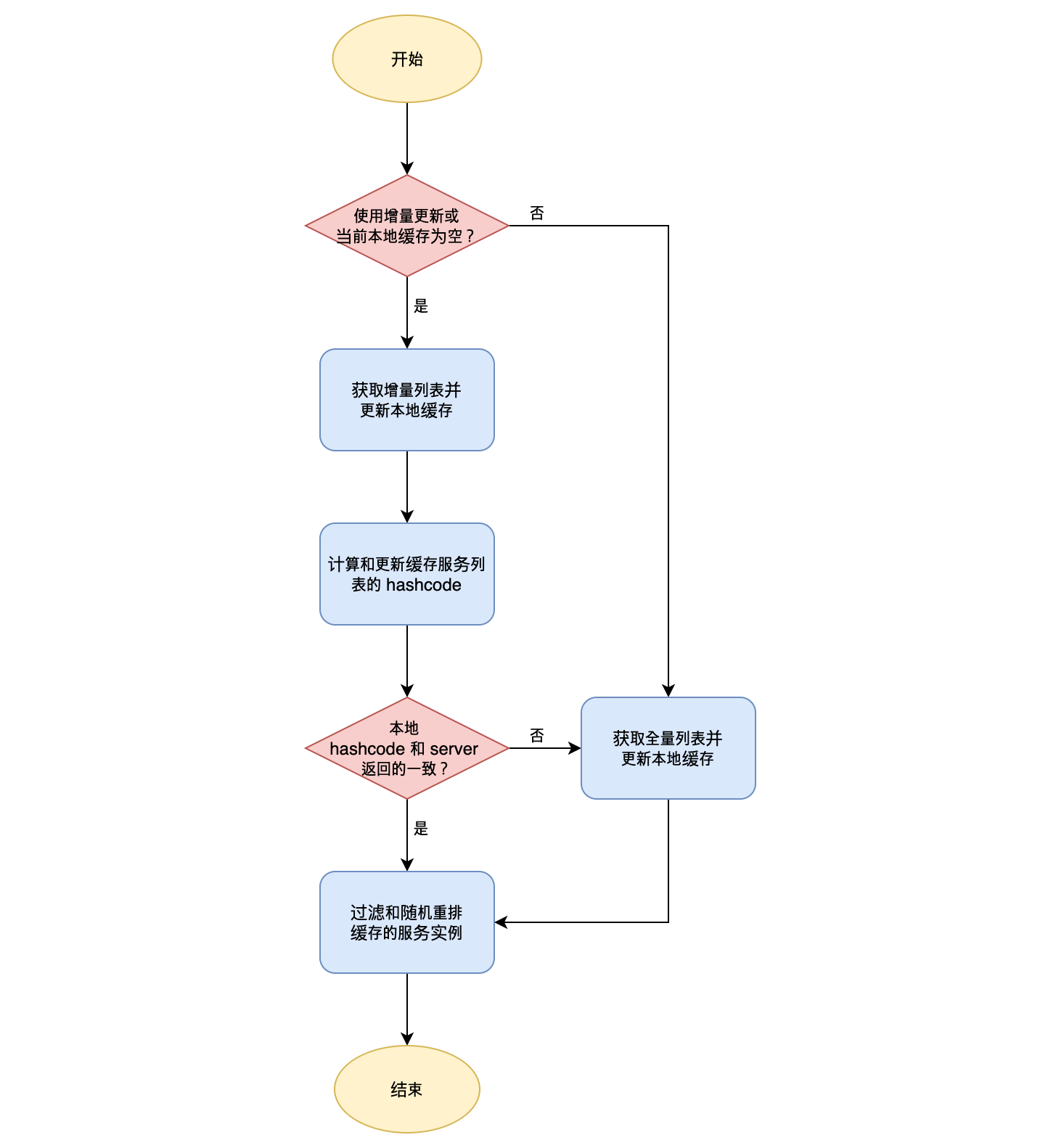
如果本地缓存为空或者说增量拉取模式关闭,那么会直接获取全量的服务列表。通过配置可以控制是否使用增量拉取模式。
eureka.client.disableDelta=false
Eureka Server 在返回增量信息时还会同时返回 Eureka Server 服务列表的 hashcode 。Eureka Client 更新完本地缓存之后也会计算本地的 hashcode 并和 Eureka Server 返回的比较。如果两者不同,那么说明本地缓存的数据和 Eureka Server 出现差异了,此时 Eureka Client 会再发起全量获取服务列表的请求,以保证本地缓存和 Eureka Server 的一致。这样就解决了第一个问题。另外,每次更新完本地缓存后还会对服务实例列表做随机重排,这样做是为了避免不同的 Eureka Client 都优先使用相同的实例。
Eureka Server 的 recentlyChangedQueue 记录的 Lease 里除了记录实例信息,还标记了增量类型。增量类型有三种: ADDED , MODIFIED, DELETED。分别表示实例的新增、状态变更和删除。Eureka Client 在更新本地缓存时需要根据不同的增量类型做不同的操作。
ADDED有实例新增时,Eureka Client 需要先根据实例 ID 判断本地缓存是否有该实例。如果没有那么直接添加,如果已经有了那就用新返回的实例信息更新缓存。MODIFIED有实例更新时的操作和实例新增类似,即根据实例 ID 查找本地缓存,无则新增,有则更新。DELETED有实例被删除时,Eureka Client 只需要从本地缓存里把 ID 相同的实例删除即可。
因为每个服务实例都有唯一的实例 ID 标识,Eureka Client 的这些操作可以做到幂等的。因此就算增量接口返回相同的数据,Eureka Client 也能够正确处理。
在集群稳定的情况下,Eureka Client 使用增量的方式更新缓存可以节省带宽和加快更新效率,一般情况下都建议使用增量更新。
最后 Eureka 整体核心模块的交互过程如下图。
5 其他方案
除了 Eureka 之外,还有一些比较常见的可以用于服务发现的方案。
- Zookeeper/etcd:这两者本身都是一个分布式 K/V 存储系统,但是可以用来作为服务注册中心。两者在写入数据之前都会由分布式一致性算法(Zab/Raft)来保证数据一致性,是 CP 系统。
- Consul/Nacos:这两者都是专门用来做服务发现的,并且除了服务发现之外还提供其他功能,比如配置管理等。其中 Consul 也是一个 CP 系统,而 Nacos 可由用户选择 AP 或 CP 模式。
与这些方案相比,Eureka 首先是一个专门为了做服务注册中心而开发的系统,Eureka 没有其他如配置管理等功能。
其次,Eureka 是一个 AP 系统,它不保证数据的强一致,只通过简单的数据同步来保证最终一致性。从可用性角度来看,Eureka 的可用性比其他 CP 系统的可用性更强。我们认为在服务发现的场景下,Eureka 牺牲数据一致性来保证更高的可用性的决定是合理的。
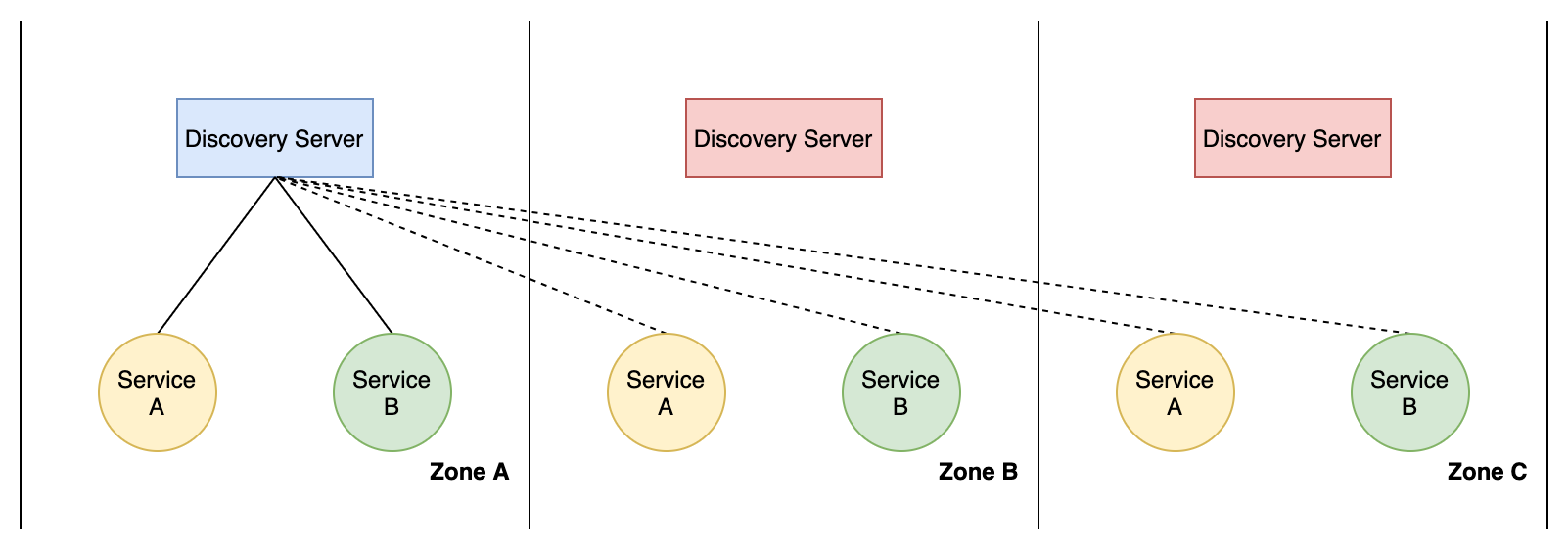
为了对比两种系统在异常发生时的行为,考虑下面场景。假设我们有三个可用区,每个可用区都有一个服务发现中心的节点。

当发生网络分隔,可用区 C 和 A、B 都无法连接时,如果这个服务发现中心是 CP 的(如 Zookeeper),那么可用区 C 的节点将会拒绝写请求。此时 C 区的新实例将无法注册,最终会导致 C 区的其他实例无法调用新实例,尽管 C 区此时各个服务都是正常的。
如果使用的是 Eureka,那么这种情况下 C 区的实例相互之间依然能正常调用,因为 Eureka Server 集群就算没能连上大多数节点也能正常处理读写请求。
另一种极端情况是当超过半数的节点故障时,CP 系统也会无法处理写请求,新实例无法注册。但 Eureka Server 集群只要还有一个节点存活,就能正常提供服务,配合 Eureka Client 的重试机制,最终所有 Eureka Client 都会切换到存活的 Eureka Server 上,集群的服务发现功能依然正常。
当然,AP 系统也会有自己的缺点。Eureka Client 获取到的服务列表并不一定是准确的,有可能包含一些已经不再可用的实例,也可能会少了新注册的实例。包含不可用实例的问题可以通过调用方重试来尝试解决,而少新实例的问题也只会造成现有实例的负载暂时变高。这些问题一般情况下都不如上面的场景造成的影响大。
6 总结
本文介绍了服务注册中心 Eureka 的工作原理,分别从 Eureka Server 和 Eureka Client 两方面详细分析了两者的主要模块和功能。作为一个 AP 系统,Eureka 在 server 和 client 端均采用了缓存,server 端的数据同步也不保证一致性,因此和其他 CP 系统方案相比,Eureka 在发生异常的情况下牺牲了数据一致性,但提高了可用性。
本文链接: https://blog.fintopia.tech/607d1e7ece7094706059f124/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180098.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
