大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
本文介绍DCache中k-v和k-k-v这2种数据类型的基本存储结构,帮助你快速理解DCache的底层实现。
存储结构
DCache底层采用哈希表存储。以MKVCache为例,使用的哈希算法在如下文件中:
MKHash.h
MKHash.cpp
DCache在内存中将数据分为索引区和数据区:
- 数据区用于存储真实的数据
- 索引区只记录索引的值和对应数据区的地址
内存中的存储结构可以参考下面这个图:
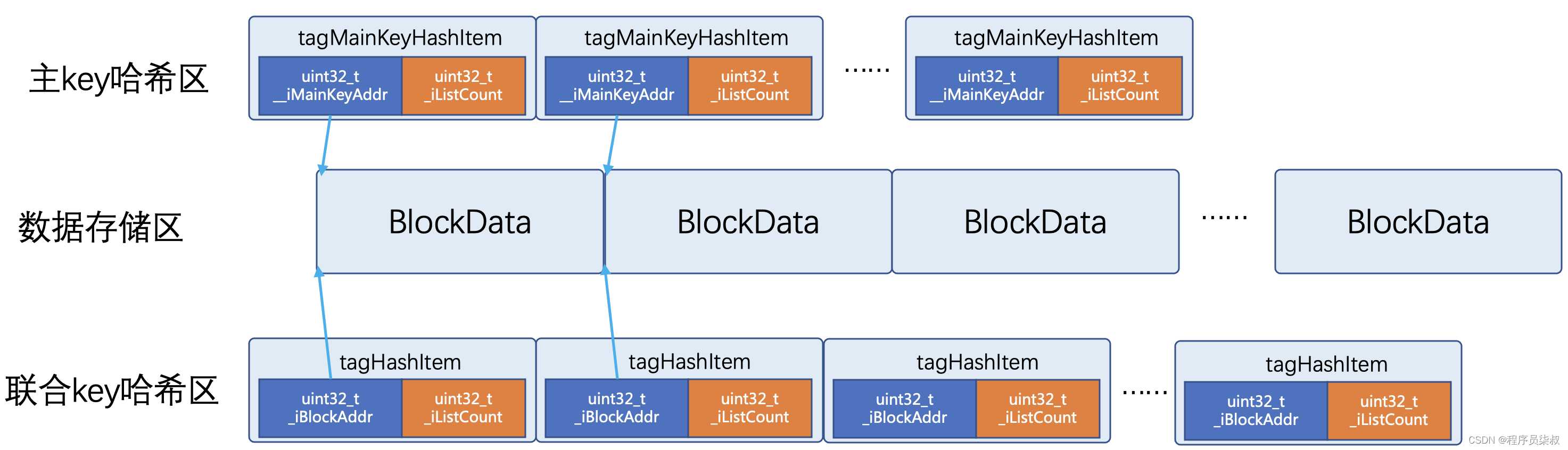

说明:
这个简图是为了便于理解才画成这样,其实际结构要复杂的多,想深入了解的同学参考源码。
哈希算法
官方文档中介绍说,DCache采用的是一致性哈希算法,实现在MKHash.cpp:
unsigned int MKHash::HashRawString(const string &key)
{
const char *ptr = key.c_str();
size_t key_length = key.length();
unsigned int value = 0;
while (key_length--)
{
value += *ptr++;
value += (value << 10);
value ^= (value >> 6);
}
value += (value << 3);
value ^= (value >> 11);
value += (value << 15);
return value == 0 ? 1 : value;
}
unsigned int MKHash::HashMK(const string &key)
{
unsigned int uHash = HashRawString(key);
return uHash;
}
unsigned int MKHash::HashMKUK(const string &key)
{
unsigned int uHash = HashRawString(key);
return uHash;
}一致性哈希的原理不在这里阐述,大家可以自行搜索,这个算法可以解决数据迁移和数据库扩缩容过程中,数据的平滑分片的问题。
DCache采用了这个算法,在数据迁移或数据库横向扩缩容时,最多只会影响到相邻的2个数据节点,而不是需要所有节点都重新分布数据。这个原理跟Redis-Cluster的实现类似。
哈希区
这里定义了2种哈希索引结构:
- 主key的索引
- 联合key的索引
在 tc_multi_hashmap_malloc.h文件中,主key的哈希结构定义:
/**
* 主key HashItem
*/
struct tagMainKeyHashItem
{
uint32_t _iMainKeyAddr; // 主key数据项的偏移地址
uint32_t _iListCount; // 相同主key hash索引下主key个数
}__attribute__((packed));_iMainKeyAddr, 主key索引到的数据偏移地址;
_iListCount, 相同hash值的主key个数。
可见,是采用链表方式处理哈希冲突的。
联合key的哈希结构定义,与主key哈希结构类似:
/**
* HashItem
*/
struct tagHashItem
{
uint32_t _iBlockAddr; //指向数据项的内存地址索引
uint32_t _iListCount; //链表个数
}__attribute__((packed));说明:
“联合key”就是二级索引,类似于我们写sql时 “where a=1 and b=2”中的第二个查询条件。
计算主key的哈希值( tc_multi_hashmap_malloc.cpp):
uint32_t TC_Multi_HashMap_Malloc::mhashIndex(const string &mk)
{
if (_mhashf)
{
return _mhashf(mk) % _hashMainKey.size();
}
else
{
// 如果没有单独指定主key hash函数,则使用联合主键的hash函数
return _hashf(mk) % _hashMainKey.size();
}
}其中,_mhashf 指向了MKHash::HashMK,即一致性哈希算法。
_hashMainKey.size(),主key哈希区元素(即 tagMainKeyHashItem)的个数,这个值是在创建内存结构时初始化好的,不会变。
计算联合key的哈希值:
uint32_t TC_Multi_HashMap_Malloc::hashIndex(const string &mk, const string &uk)
{
// mk是主key,uk是除主key外的辅key,二者加起来作为联合主键
return hashIndex(mk + uk);
}
uint32_t TC_Multi_HashMap_Malloc::hashIndex(const string& k)
{
return _hashf(k) % _hash.size();
}联合key的哈希计算方式与主key是一致的,只是key值为 主key与联合key的连接串。
现在可以把索引的图补全了:
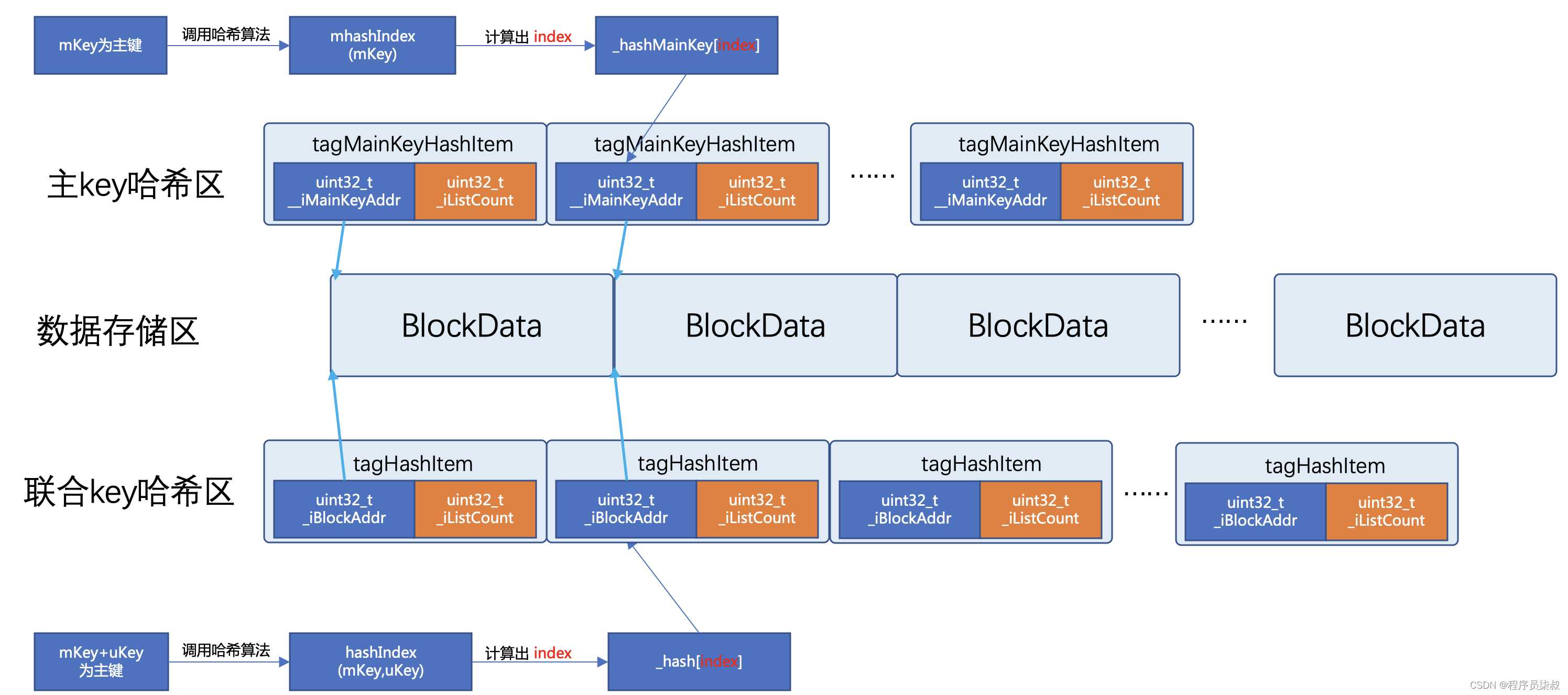
哈希冲突
前面提到DCache采用链表方式处理哈希冲突,具体如何处理的呢?感兴趣的同学可以去研究一下源码(ps:源码比较难懂,需要下功夫)。
这里我仅根据Key和Value的数据结构,大胆猜测一下:
- 写数据时,通过hash计算出key之后,会判断目标地址是否已有数据:如果已有数据,比对一下key值,key相同(说明是同一条数据)则更新;key不同(说明出现冲突),则扩展冲突链,_iListCount+1;
- 读数据时,通过hash计算出key之后,到目标地址中取数据,然后判断目标地址中数据的key是否与本次查询的key匹配:如果匹配则返回;如果不匹配则顺着冲突链进行匹配,最多匹配_iListCount次
如果有大量冲突出现时,读写效率会下降到O(n)。所以在采用DCache时,要考虑系统要支撑的数据量大小。
目前DCache的key采用的是 unsigned int类型,最多可以支撑40+亿的数据存储。那么,如果你的系统量级在千万级时,基本可以忽略哈希冲突带来的效率下降。如果是上亿甚至十亿级别,就需要实际验证冲突率(可以在控制台上输入指令查询),视情况调整哈希算法。
总结
- DCahce底层采用hash存储,读写时间复杂度是O(1);
- Set、List、k-v、k-k-row都是采用的hash存储;
- key值采用一致性哈希算法,可以平滑扩容和迁移;
- 采用链表方式处理hash冲突;
- DCache最多支持40+亿key的存储,支撑千万级用户量的系统无压力
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180071.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
