大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
首先声明感知机的对偶形式与原始形式并没有多大的区别,运算的过程都是一样的,但通过对偶形式会事先计算好一些步骤的结果并存储到Gray矩阵中,因此可以加快一些运算速度,数据越多节省的计算次数就越多,因此比原始形式更加的优化。
首先我们介绍一下感知机的原始形式,之后与其对比。
感知机
感知机是二类分类的线性分类模型,输入为实例的特征向量,输出为实例的类别,分别去+1和-1两值。感知机对应与输入空间中将实例划分为正负两类的分离超平面,属于判别模型。感知机学习旨在求出能将训练数据划分的分离超平面,其学习算法为,基于误分类的损失函数利用随机梯度下降法对损失函数进行极小化求解出超平面。
感知机学习算法是对以下问题优化,给定一个训练数据集
T={(x1,y1),(x2,y2),(x3,y3),…,(xN)(yN)}
其中,xi∈X=R^N , yi∈Y={-1,1},i=1,2,…,N,求参数w,b,使其为以下损失函数极小化问题的解。
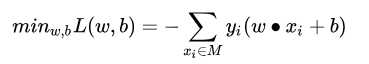

其中M为误分类点的集合。
感知机学习算法,具体采用随机梯度下降法(与梯度下降法每次迭代的是全局所有点不同,随机梯度下降每次只取一个点,虽然每次下降的方向不一定准确,但经过多次迭代,一定会接近最优值)
损失函数L(w,b)的梯度由
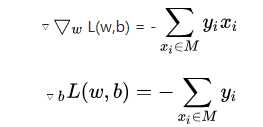
给出,其中M是固定的误分类点的集合。
随机选取一个误分类点(xi,yi),对w,b进行更新:
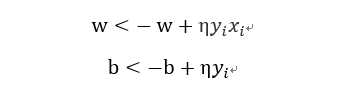
其中η(0<η<=1)是步长,统计学习中称为学习率,通过这样不断的迭代期待损失函数L(w,b)不断减小,直到为0.
总结下其基本原始算法步骤如下:
输入:训练数据集
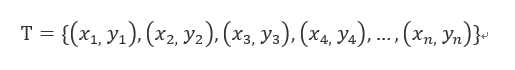
其中
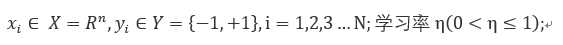
输出:w,b ; 感知机模型 f(x)=sign(w·x+b).
(1) 选取初值 w0 , b0
(2) 在训练集中选取数据(xi,yi)
(3) 如果 yi(w·xi+b)<=0
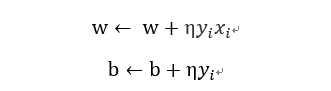
(4) 转至步骤(2),直至训练集没有误分类点.
例1(原始形式方式):
如图1训练数据集,其正实例点是 x1=(3,3)^T, x2=(4,3)^T ,负实例点是x3=(1,1)^T,求感知机模型f(x)=sign(w · x + b). 这里w=( w(1),w(2) )^T,x=( x(1),x(2) )^T
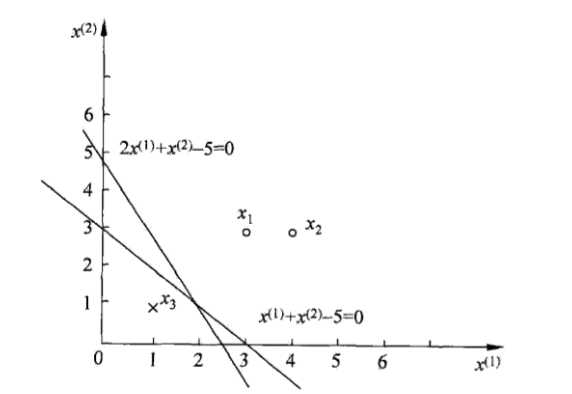 (图1)
(图1)
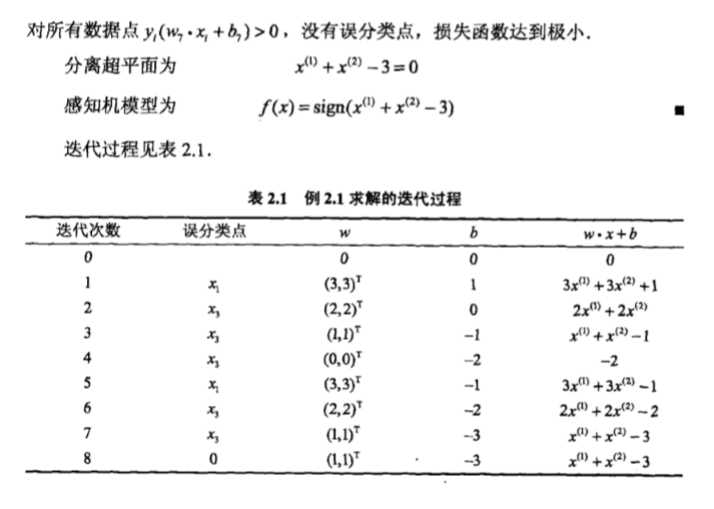
解 构造最优化问题:
求解w , b . η=1.

感知机对偶形式
对偶形式的基本想法是,将w和b表示为实例xi和标记yi的线性组合的形式,通过求解其系数而求得w和b
假设w,b初值都为0。
在原始形式中w和b通过每次对一个点的梯度下降,逐步修改w,b
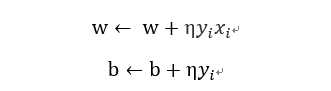
设修改n次,那么w,b关于(xi,yi)的增量分别为ni *η *yi *xi和
ni η *yi 。在学习过程中,最后学到的w,b与每个点及其个数有关。
将ai=ni*η.
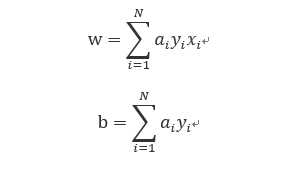
这里ni表示第i个实例点更新的次数,η为步长为1,当η=1时,表示第i个实例点由于误分而进行更新的次数。实例点更新次数越多,意味着它距离分离超平面越近,也就越难正确分类。
从这里可以看出感知机之所以有两种形式,是因为采用的随机梯度下降,随机梯度下降每次迭代的是一个点,而不是整体,因此对于迭代的点有次数的概念。
感知机对偶算法
输入:训练数据集
其中
输出:a ,b ;
感知机模型
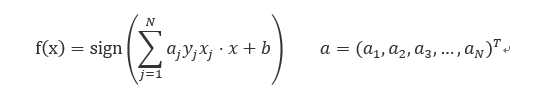
ai =ni *η 是次数
(1) a<-0 ,b<-0
(2) 在训练集中选取数据(xi , yi)
(3) 如果
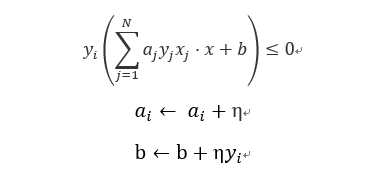
(注aj是次数*步长,yj是输出空间结果取值为{-1,1},xj是某点j的向量形式)
(4) 转至(2)指导没有误分类数据。
对偶形式中训练实例仅以内积的形式出现即(3)中的xj · x,为了方便,预先求出内积,并以矩阵形式存储,该矩阵名为Gram矩阵
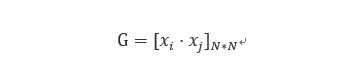
这次我们用例1的数据,通过对偶形式求解例一



迭代过程如下
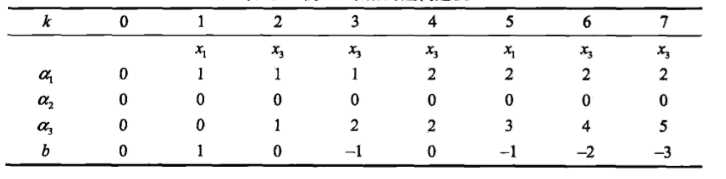
由此可以看出对偶算法与原始算法并无太大区别,运算过程一样,
毕竟原始形式中w就是aixiyi的累加和。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180035.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...