大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1、摘要
系统初期使用的是分布式微服务,但是所有业务模型都在同一个数据库实例上,数据库的压力会非常大,这时需要找出系统执行频率比较高的SQL,进行优化。这里重点描述定位问题的方法,使用的数据也都是测试环境数据。
2、统计数据
2.1、统计SQL执行次数
show GLOBAL status like ‘Com_insert%’;
show GLOBAL status like ‘Com_select%’;
show GLOBAL status like ‘Com_update%’;
show GLOBAL status like ‘Com_delete%’;
选取至少两个时间段的数据
17:57分
Com_insert1609095
Com_select169588912
Com_update69325636
Com_delete980
17:58分
Com_insert1609124
Com_select169631946
Com_update69344475
Com_delete980
18:02分
Com_insert1609421
Com_select169769311
Com_update69403962
Com_delete980
17:57 到17:58 平均每秒的次数
Com_insert0.5次/秒
Com_select717次/秒
Com_update313次/秒
Com_delete0次/秒
17:58 到18:02 平均每秒的次数
Com_insert1.2次/秒
Com_select572次/秒
Com_update247次/秒
Com_delete0次/秒
计算mysql吞吐量
基于com_%计算tps ,qps
tps= Com_insert/s + Com_update/s + Com_delete/s
qps=Com_select/s + Com_insert/s + Com_update/s + Com_delete/s
根据公式将两次统计结果的值取平均值
Tps=280
Qps=924
2.2、general_log
模拟线上环境,系统没有开启 general_log,否则会影响性能,所以select 的执行日志暂时无法统计。
2.3、慢查询日志:
https://blog.csdn.net/weixin_41715077/article/details/83116520
2.4、binlog
通过命令获取上面第一个时间段的binlog日志
mysqlbinlog –no-defaults -s –start-datetime=’2018-11-07 17:57:00′ –stop-datetime=’2018-11-07 17:58:00′ mysql-bin.000564 -r 20181107-1757-1758
binglog中有 update delete 和insert 等事务型SQL,这也是我们重点需要优化的地方。
2.4.1、统计20181107-1757-1758文件中SQL执行次数
2.4.2、统计insert
共26次 ,可以先忽略。
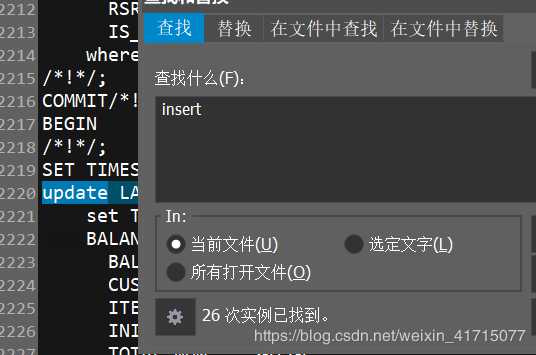

2.4.3、update
统计update次数。一分钟内共15885 次updat,平均每秒264。这个和上面统计数据基本一致。
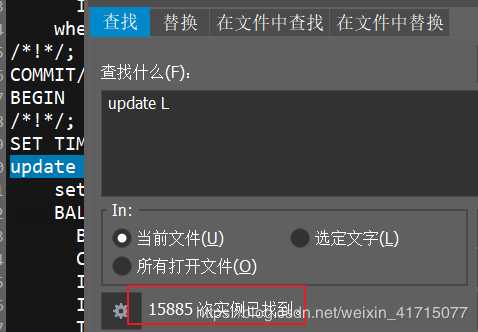
2.4.4、分析哪些SQL执行频率比较高。
发现有两条SQL的执行频率最高,找到需要优化的地方。
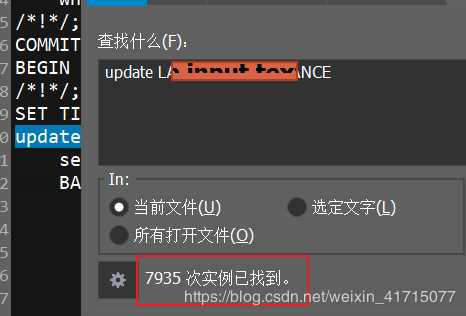
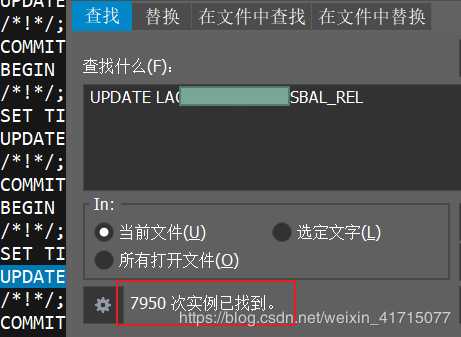
3、优化方式
先将需要Update 的数据放到redis 中,然后再定时或者根据设置数据条数的阈值来批量同步到mysql表中。比如当redis中数据超过1000时,按照上面的统计的TPS,大概是3秒钟同步一次。
但是要注意批量update的方式。使用mybatis 批量更新主要有两种方式。一种用for循环通过循环传过来的参数集合,循环出N条sql,另一种 用mysql的case when 条件判断变相的进行批量更新 。使用第一方式数据库连接必须配置:&allowMultiQueries=true
update t_customer set
user_top = #{cus.top},
user_co = #{cus.co},
user_cs = #{cus.cs},
user_cd = #{cus.cd},
user_ty = #{cus.ty}
where id = #{cus.id}
update t_customer
when id=#{us.id} then #{us.top}
when id=#{us.id} then #{us.co}
when id=#{us.id} then #{us.cs}
when id=#{us.id} then #{us.cd}
when id=#{us.id} then #{us.ty}
id in
(#{us.id})
两种方式对比,第一种方式根据主键或者唯一索引更新相对会快点,而且不容易产生死锁。第二种方式使用case when 且where条件中用in 无法利用索引,且容易产生死锁。
另外有使用spring batch 的效率可能会更高点,由于没有尝试过,这里无法判断。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180009.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
