大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
https://docs.spring.io/spring/docs/5.2.5.BUILD-SNAPSHOT/spring-framework-reference/images/prototype.png本文档是对spring官方文档的解读,原文档参见Spring官方文档
,本人只是翻译和整理,由于水平有限,部分解读可能不正确,欢迎提出更好的意见和建议!网页版移步我的临时网页
1 Spring综述
1.1 jdk环境依赖
从Spring Framework 5.1开始,Spring需要JDK 8+ (Java SE 8+),并提供对JDK 11 LTS的开箱即用支持。建议将Java SE 8 update 60作为Java 8的最低补丁版本,但通常建议使用最新的补丁版本。
1.2 spring介绍
The Spring Framework is divided into modules. Applications can choose which modules they need. At the heart are the modules of the core container, including a configuration model and a dependency injection mechanism. Beyond that, the Spring Framework provides foundational support for different application architectures, including messaging, transactional data and persistence, and web.
spring分为许多模块,应用可以选择他们需要的模块。它的核心模块是core container(也就是核心容器),包括配置模块和DI依赖注入。除此之外,Spring框架还为不同的应用程序体系结构提供基础支持,包括消息传递、事务数据和持久性以及web。
1.3 Spring历史
- Spring框架的出现是为了解决早期J2EE规范的复杂性,他没有包括所有J2EE平台的规范,而是精心集成了一些特别的规范:
- Servlet API (JSR 340)
- WebSocket API (JSR 356)
- Concurrency Utilities (JSR 236)
- JSON Binding API (JSR 367)
- Bean Validation (JSR 303)
- JPA (JSR 338)
- JMS (JSR 914)
- as well as JTA/JCA setups for transaction coordination, if necessary.
- the Dependency Injection (JSR 330) and Common Annotations (JSR 250) specifications(spring同样支持依赖注入和通用注解规范)
- Spring5.0要求的最低Java版本为Java7
1.4 设计理念
在学习框架的时候,你不仅仅需要知道他是怎么使用和怎么做的,更需要了解他遵循的原则:
- Provide choice at every level. 提供每个层次的选择,Spring允许您尽可能晚地推迟设计决策。例如你可以通过配置切换持久性提供程序(可能指的是类似数据源之类的)和基础设施以及第三方api集成。
- Accommodate diverse perspectives.Spring embraces flexibility and is not opinionated about how things should be done. It supports a wide range of application needs with different perspectives.意思是spring是灵活多变的,支持广泛的应用程序需求。
- Maintain strong backward compatibility. 具有强大的向后兼容性。Spring的发展已经被小心地管理,在不同的版本之间很少有中断的变化。Spring支持精心选择的JDK版本和第三方库,以方便维护依赖于Spring的应用程序和库。
- Care about API design.关心api的设计。Spring团队投入了大量的思想和时间来开发直观的api,这些api可以支持多个版本和许多年。
- Set high standards for code quality. 为代码质量设置高标准。它是少数几个可以声明干净的代码结构且包之间没有循环依赖关系的项目之一。
2. Core 核心
IoC Container, Events, Resources, i18n, Validation, Data Binding, Type Conversion, SpEL, AOP.
IoC(控制反转)容器,事件,资源,i18n,验证,数据绑定,类型转换,表达式,面向切面编程
2.1 IoC(Inversion of Control) Container
It is a process whereby objects define their dependencies (that is, the other objects they work with) only through constructor arguments, arguments to a factory method, or properties that are set on the object instance after it is constructed or returned from a factory method. The container then injects those dependencies when it creates the bean. This process is fundamentally the inverse (hence the name, Inversion of Control) of the bean itself controlling the instantiation or location of its dependencies by using direct construction of classes or a mechanism such as the Service Locator pattern.
项目的依赖(对象)仅通过构造器参数,工厂方法参数或者通过构造器或工厂方法返回的实例对象的set方法来定义他们的依赖(属性)。容器在bean对象创建时,将依赖注入到bean对象中。这个过程通过使用类的直接构造或服务定位模式机制,从根本上反转了bean本身控制实例化或依赖的位置
- org.springframework.beans和 org.springframework.context是SpringIoC容器的基础
- BeanFactory接口提供了能够管理任何类型对象的高级配置机制。
- ApplicationContext时BeanFactory的一个子接口,他包含了:
- 更容易与AOP特性集成 Easier integration with Spring’s AOP features
- 消息资源处理 Message resource handling
- 事件发布 Event publication
- 特定于应用程序的Context(例如WebApplicationContext应用在web应用中) Application-layer specific contexts such as the
WebApplicationContextfor use in web applications.
In short, the
BeanFactoryprovides the configuration framework and basic functionality, and theApplicationContextadds more enterprise-specific functionality. TheApplicationContextis a complete superset of theBeanFactoryand is used exclusively in this chapter in descriptions of Spring’s IoC container.
所以说,BeanFactory提供了配置框架和基础功能,ApplicationContext增加了更多特定功能。ApplicationContext时BeanFactory的一个完整超集,它在本章描述Spring的IoC容器时专用。
In Spring, the objects that form the backbone of your application and that are managed by the Spring IoC container are called beans. A bean is an object that is instantiated, assembled, and otherwise managed by a Spring IoC container. Otherwise, a bean is simply one of many objects in your application. Beans, and the dependencies among them, are reflected in the configuration metadata used by a container.
在Spring中,构成应用程序主干并由Spring IoC容器管理的对象称为bean。bean是由Spring IoC容器实例化、组装和管理的对象。另外,bean只是应用程序中的众多对象之一。bean及其之间的依赖关系反映在容器使用的配置元数据中。
2.1.1 补充
- Service Locator Pattern:服务定位模式,一种设计模式。当我们希望使用JNDI查找来定位各种服务时,选择此种设计模式。这种设计模式使用了缓存技术。
- 第一次需要服务时,服务定位器在JNDI中查找并缓存服务对象。
- 再次查找相同的服务时,将在缓存中完成,提高了程序的性能
- JNDI
2.2 Container OverView 容器综述
The
org.springframework.context.ApplicationContextinterface represents the Spring IoC container and is responsible for instantiating, configuring, and assembling the beans. The container gets its instructions on what objects to instantiate, configure, and assemble by reading configuration metadata. The configuration metadata is represented in XML, Java annotations, or Java code. It lets you express the objects that compose your application and the rich interdependencies between those objects.
ApplicationContext这个接口就代表IoC容器,它负责实例化、配置和组装bean。容器通过读取配置文件的元数据来获取要实例化、配置和组装哪些对象的指令。配置文件支持xml,Java注解和纯Java代码。它允许您表达组成应用程序的对象以及这些对象之间丰富的相互依赖关系。
这个描述就是说对象的实例化,分配和管理由容器来负责,你只需要将这些信息用xml配置文件或注解或Java代码配置即可
Several implementations of the
ApplicationContextinterface are supplied with Spring. In stand-alone applications, it is common to create an instance ofClassPathXmlApplicationContextorFileSystemXmlApplicationContext. While XML has been the traditional format for defining configuration metadata, you can instruct the container to use Java annotations or code as the metadata format by providing a small amount of XML configuration to declaratively enable support for these additional metadata formats
ApplicationContext的几个实现由Spring提供,通常你需要创建 ClassPathXmlApplicationContext或FileSystemXmlApplicationContext的实例。你也可以通过配置使用Java注解结合少量的XML配置来指示容器使用Java注释或代码作为元数据格式。
In most application scenarios, explicit user code is not required to instantiate one or more instances of a Spring IoC container. For example, in a web application scenario, a simple eight (or so) lines of boilerplate web descriptor XML in the
web.xmlfile of the application typically suffices (see Convenient ApplicationContext Instantiation for Web Applications). If you use the Spring Tools for Eclipse (an Eclipse-powered development environment), you can easily create this boilerplate configuration with a few mouse clicks or keystrokes.
就是说,大多数情况下你不需要显示的代码来实例化一个容器,只需要少量的配置就足够了
The following diagram shows a high-level view of how Spring works. Your application classes are combined with configuration metadata so that, after the
ApplicationContextis created and initialized, you have a fully configured and executable system or application.
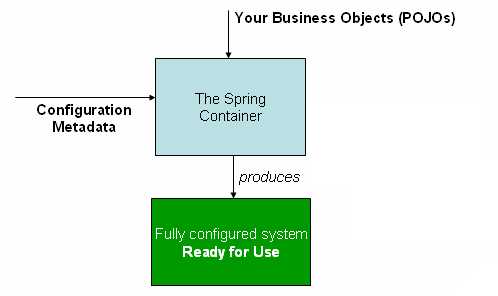

2.2.1 Configuration Metadata
- 基于注解的配置:spring2.5+
- 基于Java的配置:spring3.0+
Spring configuration consists of at least one and typically more than one bean definition that the container must manage. XML-based configuration metadata configures these beans as
elements inside a top-levelelement. Java configuration typically uses@Bean-annotated methods within a@Configurationclass.
你可以在xml配置文件中使用标签或在带有@Configuration注解的java类中使用@Bean来定义Bean
Typically, one does not configure fine-grained domain objects in the container, because it is usually the responsibility of DAOs and business logic to create and load domain objects.
通常,不会在容器中配置细粒度域对象,因为通常由DAOs和业务逻辑负责创建和加载域对象,这时可以使用Spring与AspectJ的集成来配置在IoC容器控制之外创建的对象。
基于xml配置元数据的基本结构:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="..." class="...">
<!-- collaborators and configuration for this bean go here -->
</bean>
<bean id="..." class="...">
<!-- collaborators and configuration for this bean go here -->
</bean>
<!-- more bean definitions go here -->
</beans>
- The
idattribute is a string that identifies the individual bean definition. 用来标识单个bean - The
classattribute defines the type of the bean and uses the fully qualified classname. 这个bean对应类的全限定名
2.2.2 实例化容器
ApplicationContext context = new ClassPathXmlApplicationContext("services.xml", "daos.xml");
2.2.3 组合xml配置元数据 Composing XML-based Configuration Metadata
It can be useful to have bean definitions span multiple XML files. Often, each individual XML configuration file represents a logical layer or module in your architecture.
让bean定义跨越多个XML文件可能很有用。通常,每个单独的XML配置文件表示体系结构中的逻辑层或模块。
<beans>
<import resource="services.xml"/>
<import resource="resources/messageSource.xml"/>
<import resource="/resources/themeSource.xml"/>
<bean id="bean1" class="..."/>
<bean id="bean2" class="..."/>
</beans>
It is possible, but not recommended, to reference files in parent directories using a relative “…/” path. Doing so creates a dependency on a file that is outside the current application. In particular, this reference is not recommended for
classpath:URLs (for example,classpath:../services.xml), where the runtime resolution process chooses the “nearest” classpath root and then looks into its parent directory. Classpath configuration changes may lead to the choice of a different, incorrect directory.You can always use fully qualified resource locations instead of relative paths: for example,file:C:/config/services.xmlorclasspath:/config/services.xml. However, be aware that you are coupling your application’s configuration to specific absolute locations. It is generally preferable to keep an indirection for such absolute locations — for example, through “${…}” placeholders that are resolved against JVM system properties at runtime.
此处提示最好不要使用相对路径,你可以使用绝对路径(不建议),和classpath,但是不要将配置文件耦合在系统的绝对路径,因为换了操作系统(在服务器部署)时很可能出问题。
2.2.4 Using the Container 容器的使用
The
ApplicationContextis the interface for an advanced factory capable of maintaining a registry of different beans and their dependencies. By using the methodT getBean(String name, Class requiredType), you can retrieve instances of your beans.The
ApplicationContextlets you read bean definitions and access them, as the following example shows:通过ApplicationContext接口的getBean方法获取Bean对象的实例。
ApplicationContext context = new ClassPathXmlApplicationContext("services.xml", "daos.xml");
// retrieve configured instance
PetStoreService service = context.getBean("petStore", PetStoreService.class);
// use configured instance
List<String> userList = service.getUsernameList();
2.3 Bean Overview Bean对象概述
A Spring IoC container manages one or more beans. These beans are created with the configuration metadata that you supply to the container (for example, in the form of XML “ definitions).
一个springIoC容器管理着一个或多个bean对象,这些bean对象由你提供给容器的配置元数据创建生成。
Within the container itself, these bean definitions are represented as
BeanDefinitionobjects, which contain (among other information) the following metadata:在容器内部,这些bean定义表示为BeanDefinition对象,包含着以下元数据:
- A package-qualified class name: typically, the actual implementation class of the bean being defined.(全限定类名)
- Bean behavioral configuration elements, which state how the bean should behave in the container (scope, lifecycle callbacks, and so forth).(Bean的行为配置元素,作用域,生命周期回调等)
- References to other beans that are needed for the bean to do its work. These references are also called collaborators or dependencies.(对该bean执行其工作所需的其他bean的引用。)
- Other configuration settings to set in the newly created object — for example, the size limit of the pool or the number of connections to use in a bean that manages a connection pool.(在创建bean对象时的其他配置,如连接池的最大数量)
| Property | Explained in… | |
|---|---|---|
| Class | Instantiating Beans | |
| Name | Naming Beans | |
| Scope | Bean Scopes | |
| Constructor arguments | Dependency Injection | |
| Properties | Dependency Injection | |
| Autowiring mode | Autowiring Collaborators | |
| Lazy initialization mode | Lazy-initialized Beans | |
| Initialization method | Initialization Callbacks | |
| Destruction method | Destruction Callbacks |
In addition to bean definitions that contain information on how to create a specific bean, the
ApplicationContextimplementations also permit the registration of existing objects that are created outside the container (by users). This is done by accessing the ApplicationContext’s BeanFactory through thegetBeanFactory()method, which returns the BeanFactoryDefaultListableBeanFactoryimplementation.DefaultListableBeanFactorysupports this registration through theregisterSingleton(..)andregisterBeanDefinition(..)methods. However, typical applications work solely with beans defined through regular bean definition metadata.这段话说我们可以通过ApplicationContext的getBeanFactory方法在容器之外创建对象,但是这种方法不被建议。//此处我找不到getBeanFactory这个方法。
Tip
Bean metadata and manually supplied singleton instances need to be registered as early as possible, in order for the container to properly reason about them during autowiring and other introspection steps. While overriding existing metadata and existing singleton instances is supported to some degree, the registration of new beans at runtime (concurrently with live access to the factory) is not officially supported and may lead to concurrent access exceptions, inconsistent state in the bean container, or both.
bean元数据和手动提供的单例实例需要尽早的注册,为了容器在自动装配和其他内省步骤中正确地推理它们。虽然在一定程度上支持覆盖现有元数据和现有单例实例,但是在运行时注册新bean(与对工厂的实时访问同时进行)不受官方支持,可能会导致并发访问异常,使bean容器中的不一致状态,或者两者都是。
2.3.1 Naming Beans 命名Bean
Every bean has one or more identifiers. These identifiers must be unique within the container that hosts the bean. A bean usually has only one identifier. However, if it requires more than one, the extra ones can be considered aliases.
每个bean都有一个或多个标识符。这些标识符在承载bean的容器中必须是惟一的。一个bean通常只有一个标识符。但是,如果需要多个别名,则可以将额外的别名视为别名。
In XML-based configuration metadata, you use the
idattribute, thenameattribute, or both to specify the bean identifiers. Theidattribute lets you specify exactly one id. Conventionally, these names are alphanumeric (‘myBean’, ‘someService’, etc.), but they can contain special characters as well. If you want to introduce other aliases for the bean, you can also specify them in thenameattribute, separated by a comma (,), semicolon (;), or white space.用id配置标识,这个需要使唯一的,同时你还可以使用name来配置bean的别名,并且可以配置多个,你可以用逗号分号和空格来分开多个别名。
<bean id="user" class="com.leishida.spring.User" name="u us,use;user2"/>
You are not required to supply a
nameor anidfor a bean. If you do not supply anameoridexplicitly, the container generates a unique name for that bean. However, if you want to refer to that bean by name, through the use of therefelement or a Service Locator style lookup, you must provide a name. Motivations for not supplying a name are related to using inner beans and autowiring collaborators.你也可以不为bean配置name和id属性,这样容器会为它自动分配唯一的id,但是你将无法引用它
Bean命名约定
The convention is to use the standard Java convention for instance field names when naming beans. That is, bean names start with a lowercase letter and are camel-cased from there. Examples of such names include
accountManager,accountService,userDao,loginController, and so forth.Naming beans consistently makes your configuration easier to read and understand. Also, if you use Spring AOP, it helps a lot when applying advice to a set of beans related by name.
遵循Java的命名规范,首字母小写,然后采用驼峰命名。
通过在类路径中扫描组件,Spring按照前面描述的规则为未命名的组件生成bean名称:本质上,使用简单的类名并将其初始字符转换为小写。但是,在(不寻常的)特殊情况下,如果有多个字符,并且第一个和第二个字符都是大写的,则保留原来的大小写。这些规则与java.beans.自省器.decapitalize (Spring在这里使用)定义的规则相同。
在bean定义外定义别名
<alias name="fromName" alias="toName"/>
2.3.2 Instantiating Beans 实例化Beans
If you use XML-based configuration metadata, you specify the type (or class) of object that is to be instantiated in the
classattribute of the “ element. Thisclassattribute (which, internally, is aClassproperty on aBeanDefinitioninstance) is usually mandatory. (For exceptions, see Instantiation by Using an Instance Factory Method and Bean Definition Inheritance.) You can use theClassproperty in one of two ways:
你通常必须指定class属性(因为要创建对象肯定要知道它的全类名)
你可以通过以下两种方式之一使用Class属性:
- Typically, to specify the bean class to be constructed in the case where the container itself directly creates the bean by calling its constructor reflectively, somewhat equivalent to Java code with the
newoperator.直接通过反射创建 - To specify the actual class containing the
staticfactory method that is invoked to create the object, in the less common case where the container invokes astaticfactory method on a class to create the bean. The object type returned from the invocation of thestaticfactory method may be the same class or another class entirely.通过静态工厂创建
Inner class names
If you want to configure a bean definition for a
staticnested class, you have to use the binary name of the nested class.For example, if you have a class called
SomeThingin thecom.examplepackage, and thisSomeThingclass has astaticnested class calledOtherThing, the value of theclassattribute on a bean definition would becom.example.SomeThing$OtherThing.Notice the use of the
$character in the name to separate the nested class name from the outer class name.
如果你想要配置一个静态内部类的bean,你需要这么写: packageName.OuterClassName$InnerClassName
Instantiation with a Constructor 使用构造器实例化
When you create a bean by the constructor approach, all normal classes are usable by and compatible with Spring. That is, the class being developed does not need to implement any specific interfaces or to be coded in a specific fashion. Simply specifying the bean class should suffice. However, depending on what type of IoC you use for that specific bean, you may need a default (empty) constructor.
当您通过构造函数方法创建一个bean时,所有的普通类都可以被Spring使用并与Spring兼容。也就是说,正在开发的类不需要实现任何特定的接口,也不需要以特定的方式进行编码。只需指定bean类就足够了。但是,根据您为特定bean使用的IoC类型,您可能需要一个默认(空)构造函数。
The Spring IoC container can manage virtually any class you want it to manage. It is not limited to managing true JavaBeans. Most Spring users prefer actual JavaBeans with only a default (no-argument) constructor and appropriate setters and getters modeled after the properties in the container. You can also have more exotic non-bean-style classes in your container. If, for example, you need to use a legacy connection pool that absolutely does not adhere to the JavaBean specification, Spring can manage it as well.
Spring IoC容器几乎可以管理您希望它管理的任何类。它不仅限于管理真正的javabean。大多数Spring用户更喜欢实际的javabean,它只有一个默认的(无参数的)构造函数,以及根据容器中的属性建模的适当的setter和getter方法。您还可以在容器中包含更多非bean风格的类。例如,如果您需要使用完全不符合JavaBean规范的遗留连接池,Spring也可以管理它。
With XML-based configuration metadata you can specify your bean class as follows:
<bean id="exampleBean" class="examples.ExampleBean"/>
<bean name="anotherExample" class="examples.ExampleBeanTwo"/>
有关构造器注入的细节,请移步注入依赖项[Injecting Dependencies]。
Instantiation with a Static Factory Method 使用静态工厂方法实例化
When defining a bean that you create with a static factory method, use the
classattribute to specify the class that contains thestaticfactory method and an attribute namedfactory-methodto specify the name of the factory method itself. You should be able to call this method (with optional arguments, as described later) and return a live object, which subsequently is treated as if it had been created through a constructor. One use for such a bean definition is to callstaticfactories in legacy code.在定义使用静态工厂方法创建的bean时,使用class属性指定包含静态工厂方法的类,使用factory-method属性指定工厂方法本身的名称。您应该能够调用这个方法(带有可选参数,如后面所述)并返回一个活动对象,该对象随后被视为是通过构造函数创建的。这种bean定义的一个用途是在遗留代码中调用静态工厂。
The following bean definition specifies that the bean be created by calling a factory method. The definition does not specify the type (class) of the returned object, only the class containing the factory method. In this example, the
createInstance()method must be a static method. The following example shows how to specify a factory method:下面的bean定义指定通过调用工厂方法来创建bean。定义不指定返回对象的类型(类),只指定包含工厂方法的类。在本例中,createInstance()方法必须是一个静态方法。下面的例子展示了如何指定一个工厂方法:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private int age;
}
public class UserFactory {
public static User getUser(){
return new User("工厂", 19);
}
}
<bean id="user" class="com.leishida.spring.UserFactory" factory-method="getUser"/>
public void test(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user = context.getBean("user");
System.out.println(user); //User(name=工厂, age=19)
}
Instantiation by Using an Instance Factory Method 使用实例工厂方法实例化
Similar to instantiation through a static factory method, instantiation with an instance factory method invokes a non-static method of an existing bean from the container to create a new bean. To use this mechanism, leave the
classattribute empty and, in thefactory-beanattribute, specify the name of a bean in the current (or parent or ancestor) container that contains the instance method that is to be invoked to create the object. Set the name of the factory method itself with thefactory-methodattribute. The following example shows how to configure such a bean:
与通过静态工厂方法实例化类似,使用实例工厂方法实例化将从容器中调用现有bean的非静态方法来创建新bean。要使用这种机制,将class属性保留为空,并在factory-bean属性中指定当前(或父或父)容器中bean的名称,该容器包含要调用来创建对象的实例方法。使用factory-method属性设置工厂方法本身的名称。下面的例子展示了如何配置这样一个bean:
public class InstanceUserFactory {
private static User user = new User();
public User createClientServiceInstance() {
return user;
}
}
<bean id="instanceUserFactory" class="com.leishida.spring.InstanceUserFactory"/>
<bean id="user1" factory-bean="instanceUserFactory" factory-method="createClientServiceInstance"/>
@org.junit.Test
public void test2(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user = context.getBean("user1");
System.out.println(user); //User(name=null, age=0)
}
一个工厂类也可以有多个工厂方法
TIP
In Spring documentation, “factory bean” refers to a bean that is configured in the Spring container and that creates objects through an instance or static factory method. By contrast,
FactoryBean(notice the capitalization) refers to a Spring-specificFactoryBean.意思使在spring文档里,factoryBean是你在配置里自己配置的工厂bean对象,而FactoryBean则值得是Spring的FactoryBean
2.4 Dependencies 依赖项
A typical enterprise application does not consist of a single object (or bean in the Spring parlance). Even the simplest application has a few objects that work together to present what the end-user sees as a coherent application. This next section explains how you go from defining a number of bean definitions that stand alone to a fully realized application where objects collaborate to achieve a goal.
典型的企业应用程序不包含单个对象(或Spring中的bean)。即使是最简单的应用程序也有几个对象一起工作,以呈现最终用户所看到的一致的应用程序。下一节将解释如何从定义许多独立的bean定义过渡到一个完全实现的应用程序,在这个应用程序中,对象通过协作来实现一个目标。
2.4.1 Dependency Injection 依赖注入
Dependency injection (DI) is a process whereby objects define their dependencies (that is, the other objects with which they work) only through constructor arguments, arguments to a factory method, or properties that are set on the object instance after it is constructed or returned from a factory method. The container then injects those dependencies when it creates the bean. This process is fundamentally the inverse (hence the name, Inversion of Control) of the bean itself controlling the instantiation or location of its dependencies on its own by using direct construction of classes or the Service Locator pattern.
依赖项注入(DI)是一个过程,在这个过程中,对象仅通过构造函数参数、工厂方法的参数或从工厂方法构造或返回后在对象实例上设置的属性来定义它们的依赖项(即它们与之一起工作的其他对象)。然后容器在创建bean时注入这些依赖项。这个过程基本上是bean本身的逆过程(因此称为控制反转过程),由对象自己控制实例化或者定位他的依赖,改变为通过直接使用类的构造方法或者使用服务定位模式。
Code is cleaner with the DI principle, and decoupling is more effective when objects are provided with their dependencies. The object does not look up its dependencies and does not know the location or class of the dependencies. As a result, your classes become easier to test, particularly when the dependencies are on interfaces or abstract base classes, which allow for stub or mock implementations to be used in unit tests.
使用DI原则,代码更简洁,并且当对象提供其依赖项时,解耦更有效。对象不查找其依赖项,也不知道依赖项的位置或类。结果,您的类变得更容易测试,特别是当依赖关系在接口或抽象基类上时,这允许在单元测试中使用存根或模拟实现。
DI exists in two major variants: Constructor-based dependency injection and Setter-based dependency injection.
依赖注入存在与两个主要部分:基于构造器依赖注入和基于Set方法的依赖注入
Constructor-based Dependency Injection 基于构造器的依赖注入
Constructor-based DI is accomplished by the container invoking a constructor with a number of arguments, each representing a dependency. Calling a
staticfactory method with specific arguments to construct the bean is nearly equivalent, and this discussion treats arguments to a constructor and to astaticfactory method similarly. The following example shows a class that can only be dependency-injected with constructor injection:基于构造函数的DI是通过容器调用带有许多参数的构造函数来完成的,每个参数代表一个依赖项。调用带有特定参数的静态工厂方法来构造bean几乎是等价的,本讨论将参数分别用于构造函数和静态工厂方法。下面的例子展示了一个只能依赖注入构造函数注入的类:
Bean类:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private int age;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Score {
private int English;
private int Math;
}
XML配置
<bean id="user" class="com.leishida.spring.User">
<constructor-arg name="name" value="构造器注入"/>
<constructor-arg name="age" value="18"/>
<!-- 当对象内部的属性是引用类型时,通过ref引用上面注册的score Bean -->
<constructor-arg name="score" ref="score"/>
</bean>
测试
@org.junit.Test
public void test3(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user = context.getBean("user");
System.out.println(user); //User(name=构造器注入, age=18, score=Score(English=0, Math=0))
}
通过构造器注入时可以根据参数索引,类型,名称来注入
通过索引注入
<bean id="user1" class="com.leishida.spring.User">
<constructor-arg index="0" value="索引"/>
<constructor-arg index="1" value="18"/>
<constructor-arg index="2" ref="score"/>
</bean>
通过类型注入
<bean id="user2" class="com.leishida.spring.User">
<constructor-arg type="java.lang.String" value="类型"/>
<constructor-arg type="int" value="18"/>
<constructor-arg type="com.leishida.spring.Score" ref="score"/>
</bean>
通过名称匹配上面例子已经写过,此处不再赘述
Setter-based Dependency Injection 基于Set方法的注入
Setter-based DI is accomplished by the container calling setter methods on your beans after invoking a no-argument constructor or a no-argument
staticfactory method to instantiate your bean.The following example shows a class that can only be dependency-injected by using pure setter injection. This class is conventional Java. It is a POJO that has no dependencies on container specific interfaces, base classes, or annotations.
基于setter的DI是在调用无参数构造函数或无参数静态工厂方法来实例化bean之后,通过容器调用bean上的setter方法来完成的。
下面的示例显示了一个只能通过使用纯setter注入来依赖注入的类。这个类是传统的Java。它是一个不依赖于容器特定接口、基类或注释的POJO。
使用此种方式,一定要保证类对应的属性上有相应的get方法,否则会注入失败
The
ApplicationContextsupports constructor-based and setter-based DI for the beans it manages. It also supports setter-based DI after some dependencies have already been injected through the constructor approach. You configure the dependencies in the form of aBeanDefinition, which you use in conjunction withPropertyEditorinstances to convert properties from one format to another. However, most Spring users do not work with these classes directly (that is, programmatically) but rather with XMLbeandefinitions, annotated components (that is, classes annotated with@Component,@Controller, and so forth), or@Beanmethods in Java-based@Configurationclasses. These sources are then converted internally into instances ofBeanDefinitionand used to load an entire Spring IoC container instance.ApplicationContext为它管理的bean支持基于构造函数和基于setter的DI。在通过构造函数方法注入了一些依赖项之后,它还支持基于setter的DI。您可以将依赖项配置为BeanDefinition的形式,并将其与PropertyEditor实例一起使用,以便将属性从一种格式转换为另一种格式。但是,大多数Spring用户并不直接使用这些类(也就是说,以编程的方式),而是使用XML bean定义、带注释的组件(也就是说,使用@Component、@Controller等注释的类)
Constructor-based or setter-based DI?
Since you can mix constructor-based and setter-based DI, it is a good rule of thumb to use constructors for mandatory dependencies and setter methods or configuration methods for optional dependencies. Note that use of the @Required annotation on a setter method can be used to make the property be a required dependency; however, constructor injection with programmatic validation of arguments is preferable.
The Spring team generally advocates constructor injection, as it lets you implement application components as immutable objects and ensures that required dependencies are not
null. Furthermore, constructor-injected components are always returned to the client (calling) code in a fully initialized state. As a side note, a large number of constructor arguments is a bad code smell, implying that the class likely has too many responsibilities and should be refactored to better address proper separation of concerns.Setter injection should primarily only be used for optional dependencies that can be assigned reasonable default values within the class. Otherwise, not-null checks must be performed everywhere the code uses the dependency. One benefit of setter injection is that setter methods make objects of that class amenable to reconfiguration or re-injection later. Management through JMX MBeans is therefore a compelling use case for setter injection.
Use the DI style that makes the most sense for a particular class. Sometimes, when dealing with third-party classes for which you do not have the source, the choice is made for you. For example, if a third-party class does not expose any setter methods, then constructor injection may be the only available form of DI.
那么究竟是选择基于构造器的注入还是选择基于set方式的注入呢?这里官方给出了我们建议:
- 如果你的set注入参数是必须的,那么你可以在set方法上加一个@Required注解来保证这个参数一定被注入
- 最好使用带有参数编程式验证的构造函数注入,这样可以保证你需要的参数一定被注入
- 大量的构造函数参数是一种不好的代码味道,这意味着类可能有太多的责任,应该对其进行重构,以更好地解决问题的适当分离。
- Setter注入应该主要用于可选的依赖项,这些依赖项可以在类中分配合理的默认值。
- 使用对特定类最有意义的DI样式。有时,在处理您没有源代码的第三方类时,需要为您做出选择。例如,如果第三方类没有公开任何setter方法,那么构造函数注入可能是惟一可用的DI形式。
使用set注入
<bean id="user3" class="com.leishida.spring.User">
<property name="name" value="set注入"/>
</bean>
@org.junit.Test
public void test4(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user = context.getBean("user3");
System.out.println(user); //User(name=set注入, age=0, score=null)
}
Dependency Resolution Process 依赖性解析过程
The container performs bean dependency resolution as follows:
- The
ApplicationContextis created and initialized with configuration metadata that describes all the beans. Configuration metadata can be specified by XML, Java code, or annotations. - For each bean, its dependencies are expressed in the form of properties, constructor arguments, or arguments to the static-factory method (if you use that instead of a normal constructor). These dependencies are provided to the bean, when the bean is actually created.
- Each property or constructor argument is an actual definition of the value to set, or a reference to another bean in the container.
- Each property or constructor argument that is a value is converted from its specified format to the actual type of that property or constructor argument. By default, Spring can convert a value supplied in string format to all built-in types, such as
int,long,String,boolean, and so forth.
容器执行bean依赖项解析如下:
- ApplicationContext是用描述所有bean的配置元数据创建和初始化的。配置元数据可以由XML、Java代码或注释指定。
- 对于每个bean,其依赖项都以属性、构造函数参数或静态工厂方法的参数的形式表示(如果您使用该方法而不是普通的构造函数)。这些依赖项是在bean实际创建时提供给bean的。
- 每个属性或构造函数参数都是要设置的值的实际定义,或者是对容器中另一个bean的引用。
- 值的每个属性或构造函数参数都从其指定的格式转换为该属性或构造函数参数的实际类型。默认情况下,Spring可以将以字符串格式提供的值转换为所有内置类型,如int、long、string、boolean等。
The Spring container validates the configuration of each bean as the container is created. However, the bean properties themselves are not set until the bean is actually created. Beans that are singleton-scoped and set to be pre-instantiated (the default) are created when the container is created. Scopes are defined in Bean Scopes. Otherwise, the bean is created only when it is requested. Creation of a bean potentially causes a graph of beans to be created, as the bean’s dependencies and its dependencies’ dependencies (and so on) are created and assigned. Note that resolution mismatches among those dependencies may show up late — that is, on first creation of the affected bean.
在创建容器时,Spring容器验证每个bean的配置。但是,在实际创建bean之前,不会设置bean属性本身。在创建容器时,将创建单例作用域的bean并将其设置为预实例化(默认值)。作用域是在Bean作用域中定义的。另外,仅在请求bean时才创建它。当bean的依赖项及其依赖项的依赖项(等等)被创建和分配时,bean的创建可能会创建一个bean图。注意解决依赖项延迟出现的不匹配问题,第一次创建将影响Bean。不是很懂最后一句
Circular dependencies
If you use predominantly constructor injection, it is possible to create an unresolvable circular dependency scenario.
For example: Class A requires an instance of class B through constructor injection, and class B requires an instance of class A through constructor injection. If you configure beans for classes A and B to be injected into each other, the Spring IoC container detects this circular reference at runtime, and throws a BeanCurrentlyInCreationException.
One possible solution is to edit the source code of some classes to be configured by setters rather than constructors. Alternatively, avoid constructor injection and use setter injection only. In other words, although it is not recommended, you can configure circular dependencies with setter injection.
Unlike the typical case (with no circular dependencies), a circular dependency between bean A and bean B forces one of the beans to be injected into the other prior to being fully initialized itself (a classic chicken-and-egg scenario).
循环依赖
如果主要使用构造函数注入,可能会创建无法解析的循环依赖场景。
例如:类A需要一个类B通过构造函数注入的实例,而类B需要一个类A通过构造函数注入的实例。如果您将bean配置为类A和B相互注入,Spring IoC容器将在运行时检测这个循环引用,并抛出一个BeanCurrentlyInCreationException异常。
一种可能的解决方案是编辑某些类的源代码,由setter注入而不是构造函数来注入。另外,避免构造函数注入,只使用setter注入。换句话说,尽管不建议这样做,但您可以使用setter注入配置循环依赖项。
与典型的情况(没有循环依赖关系)不同,bean A和bean B之间的循环依赖关系迫使一个bean在完全初始化之前被注入到另一个bean中(典型的先有鸡还是先有蛋的场景)。
下面来模拟一下循环依赖
首先两个JavaBean:
@AllArgsConstructor
public class Checken {
private Egg egg;
}
@AllArgsConstructor
public class Egg {
private Checken checken;
}
然后再xml中配置:
<!-- 循环依赖 -->
<bean id="checken" class="com.leishida.spring.Checken">
<constructor-arg name="egg" ref="egg"/>
</bean>
<bean id="egg" class="com.leishida.spring.Egg">
<constructor-arg name="checken" ref="checken"/>
</bean>
然后测试一下:
@org.junit.Test
public void test5(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object checken = context.getBean("checken");
Object egg = context.getBean("egg");
System.out.println(checken +" "+ egg);
/** * org.springframework.beans.factory.BeanCreationException: * Error creating bean with name 'checken' defined in class path resource * [applicationContext.xml]: Cannot resolve reference to bean 'egg' while setting constructor argument; * nested exception is org.springframework.beans.factory.BeanCreationException: * Error creating bean with name 'egg' defined in class path resource [applicationContext.xml]: * Cannot resolve reference to bean 'checken' while setting constructor argument; * nested exception is org.springframework.beans.factory.BeanCurrentlyInCreationException: * Error creating bean with name 'checken': Requested bean is currently in creation: * Is there an unresolvable circular reference? */
}
现在我们将注入方式改为set注入看看能不能解决问题:
<bean id="egg" class="com.leishida.spring.Egg">
<property name="checken" ref="checken"/>
</bean>
<bean id="checken" class="com.leishida.spring.Checken">
<property name="egg" ref="egg"/>
</bean>
<!-- 注意对应的无参构造器和set方法,如果没有会报错-->
@org.junit.Test
public void test6() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object checken = context.getBean("checken");
Object egg = context.getBean("egg");
System.out.println(checken + " " + egg); //Checken(egg=com.leishida.spring.Egg@c8e4bb0) com.leishida.spring.Egg@c8e4bb0
}
You can generally trust Spring to do the right thing. It detects configuration problems, such as references to non-existent beans and circular dependencies, at container load-time. Spring sets properties and resolves dependencies as late as possible, when the bean is actually created. This means that a Spring container that has loaded correctly can later generate an exception when you request an object if there is a problem creating that object or one of its dependencies — for example, the bean throws an exception as a result of a missing or invalid property. This potentially delayed visibility of some configuration issues is why
ApplicationContextimplementations by default pre-instantiate singleton beans. At the cost of some upfront time and memory to create these beans before they are actually needed, you discover configuration issues when theApplicationContextis created, not later. You can still override this default behavior so that singleton beans initialize lazily, rather than being pre-instantiated.
你通常可以相信spring总会做正确的事情。他会在容器的加载阶段检测配置问题,例如引用了不存在的Bean对象和循环依赖。在Bean对象真正的创建时,它会尽可能晚的设置属性和解决依赖。这意味着,如果在创建对象或其依赖项时出现问题,则在请求对象时,已正确加载的Spring容器稍后可以生成异常——例如,由于缺少或无效的属性,bean会抛出异常。一些配置问题的潜在延迟可见性是ApplicationContext实现默认预实例化单例bean的原因。(如果是多例对象,那么所有请求非法的bean都会同时抛出异常),在实际需要这些bean之前花费一些前期时间和内存来创建它们,您将在创建ApplicationContext时发现配置问题,而不是稍后。(也就是说,你在实例化ApplicationContext的时候,它就会创建所有配置的bean,并及时发现他们的问题)您仍然可以覆盖这个默认行为,这样单例bean就可以延迟初始化,而不是预先实例化。(ApplicationContext在创建bean对象时的模式时立即加载,但你可以通过修改配置,让它变为懒加载)
If no circular dependencies exist, when one or more collaborating beans are being injected into a dependent bean, each collaborating bean is totally configured prior to being injected into the dependent bean. This means that, if bean A has a dependency on bean B, the Spring IoC container completely configures bean B prior to invoking the setter method on bean A. In other words, the bean is instantiated (if it is not a pre-instantiated singleton), its dependencies are set, and the relevant lifecycle methods (such as a configured init method or the InitializingBean callback method) are invoked.
如果不存在循环依赖项,那么当一个或多个协作bean被注入一个依赖bean时,每个协作bean在被注入依赖bean之前都要完全配置好。这意味着,如果beanA依赖bean B, Spring IoC容器会优先完全配置beanB,然后再调用beanA的setter方法。换句话说,bean实例化(如果它不是一个单例预先实例化),他的依赖项就被设置,相关的生命周期方法(如InitializingBean init方法或配置回调方法)调用。
2.4.2. Dependencies and Configuration in Detail 依赖配置的细节
这一部分具体讲解了属性注入的具体方法:
Straight Values 直接的值
P标签的使用:
再使用p命名空间时,需要首先导入约束:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" <!-- p命名空间约束 -->
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="score" class="com.leishida.spring.Score"></bean>
<bean id="user4" class="com.leishida.spring.User" p:name="P标签导入" p:age="18" p:score-ref="score"/>
</beans>
**The idref element ** idref元素
The idref element is simply an error-proof way to pass the id (a string value – not a reference) of another bean in the container to a or element. The following example shows how to use it:
idref元素只是将容器中另一个bean的id(字符串值,而不是引用)传递给或元素。
<bean id="user4" class="com.leishida.spring.User" p:name="P标签导入" p:age="18" p:score-ref="score"/>
<bean id="user5" class="com.leishida.spring.User">
<property name="name">
<idref bean="user4"/>
</property>
</bean>
结果:
@org.junit.Test
public void test7() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user5 = context.getBean("user5");
System.out.println(user5); //User(name=user4, age=0, score=null)
}
可以看到,上面的xml配置和下面的是等同的效果:
<bean id="user5" class="com.leishida.spring.User">
<property name="name" value="user4"/>
</bean>
那它为啥要整个idref。。神经病么,显然不是:
The first form is preferable to the second, because using the
idreftag lets the container validate at deployment time that the referenced, named bean actually exists. In the second variation, no validation is performed on the value that is passed to thetargetNameproperty of theclientbean. Typos are only discovered (with most likely fatal results) when theclientbean is actually instantiated. If theclientbean is a prototype bean, this typo and the resulting exception may only be discovered long after the container is deployed.
官方说,第一种方式比第二种方式更为可取,为什么呢:因为idref标签让容器再部署时校验这个引用,命名的这个bean事实上时存在的。而第二种方式中对name属性的值不执行任何验证,只有在实际实例化客户端bean时才会发现拼写错误(很可能导致致命的结果)。如果客户机bean是原型多例的,则此类型错误和由此产生的异常可能只有在部署容器之后很久才会被发现。
A common place (at least in versions earlier than Spring 2.0) where the element brings value is in the configuration of [AOP interceptors](https://docs.spring.io/spring/docs/5.2.5.BUILD-SNAPSHOT/spring-framework-reference/core.html#aop-pfb-1) in a `ProxyFactoryBean` bean definition. Using elements when you specify the interceptor names prevents you from misspelling an interceptor ID.
官方还列出了idref的使用场景,那就是在ProxyFactoryBean bean定义中的AOP拦截器配置中。在指定拦截器名称时使用元素可以防止对拦截器ID的拼写错误。
References to Other Beans (Collaborators) 对其他bean的引用(协作者)
引用其他bean最常用的方式就是通过标签,这个标签允许在同一个容器或父容器中创建对任何bean的引用,他们可以不在同一个xml配置文件之中。你可以使用与引用的bean的相同id或name来指定。
Specifying the target bean through the parent attribute creates a reference to a bean that is in a parent container of the current container. The value of the parent attribute may be the same as either the id attribute of the target bean or one of the values in the name attribute of the target bean. The target bean must be in a parent container of the current one. You should use this bean reference variant mainly when you have a hierarchy of containers and you want to wrap an existing bean in a parent container with a proxy that has the same name as the parent bean. The following pair of listings shows how to use the parent attribute:
这里还有一堆关于父容器的说明:通过parent属性指定目标bean将创建对当前容器的父容器中的bean的引用。父属性的值可以与目标bean的id属性相同,也可以与目标bean的name属性中的一个值相同。目标bean必须位于当前bean的父容器中。您应该主要在容器层次结构中使用此bean引用变体,并且希望将现有的bean与具有与父bean相同名称的代理包装在父容器中。
<!-- in the parent context -->
<bean id="accountService" class="com.something.SimpleAccountService">
<!-- insert dependencies as required as here -->
</bean>
==========================================================================
<!-- in the child (descendant) context -->
<bean id="accountService" <!-- bean name is the same as the parent bean -->
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target">
<ref parent="accountService"/> <!-- notice how we refer to the parent bean -->
</property>
<!-- insert other configuration and dependencies as required here -->
</bean>
这个部分因为没有具体使用到,所以不清楚他的作用
Inner Beans
<!-- inner bean-->
<bean id="user6" class="com.leishida.spring.User">
<property name="score">
<bean class="com.leishida.spring.Score">
<property name="english" value="100"/>
<property name="math" value="90"/>
</bean>
</property>
</bean>
@org.junit.Test
public void test8() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object user6 = context.getBean("user6");
System.out.println(user6); //User(name=null, age=0, score=Score(English=100, Math=90))
}
An inner bean definition does not require a defined ID or name. If specified, the container does not use such a value as an identifier. The container also ignores the scope flag on creation, because inner beans are always anonymous and are always created with the outer bean. It is not possible to access inner beans independently or to inject them into collaborating beans other than into the enclosing bean.
内部bean定义不需要已定义的ID或名称。如果指定,容器将不使用此类值作为标识符。容器还会忽略创建时的范围标志,因为内部bean始终是匿名的,并且始终使用外部bean创建。不可能独立地访问内部bean,也不可能将它们注入到协作的bean中,而不是注入到封闭的bean中。
As a corner case, it is possible to receive destruction callbacks from a custom scope — for example, for a request-scoped inner bean contained within a singleton bean. The creation of the inner bean instance is tied to its containing bean, but destruction callbacks let it participate in the request scope’s lifecycle. This is not a common scenario. Inner beans typically simply share their containing bean’s scope.
作为一种特殊情况,可以从自定义范围接收销毁回调—例如,对于单例bean中包含的请求范围的内部bean。内部bean实例的创建被绑定到它所包含的bean,但是销毁回调让它参与请求作用域的生命周期。这不是一个常见的场景。内部bean通常只是简单地共享其包含bean的范围。
Collections 集合
、、
Java类:
@Data
@NoArgsConstructor
public class ComplexObject {
private Properties email;
private List list;
private Map map;
private Set set;
}
<bean id="complexObject" class="com.leishida.spring.ComplexObject">
<!-- props 类型-->
<property name="email">
<props>
<prop key="email">123456@qq.com</prop>
</props>
</property>
<property name="list">
<list>
<value>list类型</value>
<ref bean="user6"></ref>
</list>
</property>
<property name="map">
<map>
<entry key="entry" value="this is entry"></entry>
<entry key="ref" value-ref="user6"></entry>
</map>
</property>
<property name="set">
<set>
<value>this is a set</value>
<ref bean="user6"></ref>
</set>
</property>
</bean>
<bean id="user6" class="com.leishida.spring.User">
<property name="score">
<bean class="com.leishida.spring.Score">
<property name="english" value="100"/>
<property name="math" value="90"/>
</bean>
</property>
</bean>
测试:
@org.junit.Test
public void test9() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object complexObject = context.getBean("complexObject");
System.out.println(complexObject);
//ComplexObject(email={email=123456@qq.com}, list=[list类型, User(name=null, age=0, score=Score(English=100, Math=90))], map={entry=this is entry, ref=User(name=null, age=0, score=Score(English=100, Math=90))}, set=[this is a set, User(name=null, age=0, score=Score(English=100, Math=90))])
}
The value of a map key or value, or a set value, can also be any of the following elements:
Map的key或value或者set的value可以是一下任何一种元素:
bean | ref | idref | list | set | map | props | value | null
Collection Merging 集合合并
The Spring container also supports merging collections. An application developer can define a parent ,
Spring容器还支持合并集合。应用程序开发人员可以定义父元素、
下面我们来看下具体例子:
首先是父类,其中定义了三种集合类型的成员:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ParentList {
private List list;
private Map map;
private Set set;
}
<bean id="parentList" class="com.leishida.spring2.ParentList">
<property name="list">
<list>
<value>parent1</value>
<value>parent2</value>
<value>wait for merge</value>
</list>
</property>
<property name="map">
<map>
<entry key="parent-map" value="parent-map"/>
<entry key="map-wait-merge" value="wait-merge"/>
</map>
</property>
<property name="set">
<set>
<value>parent-set</value>
<value>set-wait-merge</value>
</set>
</property>
</bean>
<bean id="sonList" parent="parentList">
<property name="list">
<list merge="true">
<value>son-list</value>
<value>wait for merge</value>
</list>
</property>
<property name="map">
<map merge="true">
<entry key="map-wait-merge" value="son-map-wait-merge"/>
<entry key="son-map" value="son-map"/>
</map>
</property>
<property name="set">
<set merge="true">
<value>set-wait-merge</value>
<value>son-set</value>
</set>
</property>
</bean>
测试结果:
@org.junit.Test
public void testMerge(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object sonList = context.getBean("sonList");
System.out.println(sonList);
/** * ParentList(list=[parent1, parent2, wait for merge, son-list, wait for merge], * map={parent-map=parent-map, map-wait-merge=son-map-wait-merge, son-map=son-map}, * set=[parent-set, set-wait-merge, son-set]) */
}
从上面的结果不难看出来merge的结果,就是将子类和父类的元素合并,同时子类可以覆盖父类的值(map里的map-wait-merge)可以通过设置merge属性来决定是否进行合并
<list merge="default">
<value>son-list</value>
<value>wait for merge</value>
</list>
子属性集合的值集继承父的所有属性元素,而子值的值覆盖父集合中的值。
This merging behavior applies similarly to the ,, and collection types. In the specific case of the element, the semantics associated with the List collection type (that is, the notion of an ordered collection of values) is maintained. The parent’s values precede all of the child list’s values. In the case of the Map, Set, and Properties collection types, no ordering exists. Hence, no ordering semantics are in effect for the collection types that underlie the associated Map, Set, and Properties implementation types that the container uses internally.
这种合并行为同样适用于、
Limitations of Collection Merging 集合合并的限制
You cannot merge different collection types (such as a Map and a List). If you do attempt to do so, an appropriate Exception is thrown. The merge attribute must be specified on the lower, inherited, child definition. Specifying the merge attribute on a parent collection definition is redundant and does not result in the desired merging.
您不能合并不同的集合类型(例如映射和列表)。如果您确实尝试这样做,将抛出一个适当的异常。merge属性必须子Bean定义上指定。在父集合定义上指定merge属性是冗余的,并且不会导致所需的合并。
Strongly-typed collection 泛型集合
With the introduction of generic types in Java 5, you can use strongly typed collections. That is, it is possible to declare a Collection type such that it can only contain (for example) String elements. If you use Spring to dependency-inject a strongly-typed Collection into a bean, you can take advantage of Spring’s type-conversion support such that the elements of your strongly-typed Collection instances are converted to the appropriate type prior to being added to the Collection. The following Java class and bean definition show how to do so:
通过在Java 5中引入泛型类型,您可以使用强类型集合。也就是说,可以声明一个集合类型,使它只能包含(例如)字符串元素。如果您使用Spring来依赖地将强类型集合注入到bean中,则可以利用Spring的类型转换支持,以便在将强类型集合实例的元素添加到集合之前将其转换为适当的类型。下面的Java类和bean定义说明了如何做到这一点:
public class SomeClass {
private Map<String, Float> accounts;
public void setAccounts(Map<String, Float> accounts) {
this.accounts = accounts;
}
}
<beans>
<bean id="something" class="x.y.SomeClass">
<property name="accounts">
<map>
<entry key="one" value="9.99"/>
<entry key="two" value="2.75"/>
<entry key="six" value="3.99"/>
</map>
</property>
</bean>
</beans>
When the accounts property of the something bean is prepared for injection, the generics information about the element type of the strongly-typed Map is available by reflection. Thus, Spring’s type conversion infrastructure recognizes the various value elements as being of type Float, and the string values (9.99, 2.75, and 3.99) are converted into an actual Float type.
当something bean的accounts属性准备注入时,强类型映射<String, Float>的元素类型的泛型信息可通过反射获得。因此,Spring的类型转换基础结构将各种值元素识别为Float类型,并将字符串值(9.99、2.75和3.99)转换为实际的Float类型。
Null and Empty String Values Null和空字符串注入
Spring treats empty arguments for properties and the like as empty Strings. The following XML-based configuration metadata snippet sets the email property to the empty String value (“”).
Spring将属性的空参数等作为空字符串处理。以下基于xml的配置元数据片段将email属性设置为空字符串值(“”)。
<bean class="ExampleBean">
<property name="email" value=""/>
</bean>
The <null/> element handles null values. The following listing shows an example:
<bean class="ExampleBean">
<property name="email">
<null/>
</property>
</bean>
XML Shortcut with the p-namespace P命名空间
The p-namespace lets you use the bean element’s attributes (instead of nested “ elements) to describe your property values collaborating beans, or both.
Spring supports extensible configuration formats with namespaces, which are based on an XML Schema definition. The beans configuration format discussed in this chapter is defined in an XML Schema document. However, the p-namespace is not defined in an XSD file and exists only in the core of Spring.
p-namespace允许您使用bean元素的属性(而不是嵌套的元素)来描述协作bean的属性值,或者两者都使用。
Spring支持带有名称空间的可扩展配置格式,这些名称空间基于XML模式定义。本章讨论的bean配置格式是在XML模式文档中定义的。但是,p-namespace并没有在XSD文件中定义,它只存在于Spring的核心中。
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean name="classic" class="com.example.ExampleBean">
<property name="email" value="someone@somewhere.com"/>
</bean>
<bean name="p-namespace" class="com.example.ExampleBean" p:email="someone@somewhere.com"/>
</beans>
The example shows an attribute in the p-namespace called email in the bean definition. This tells Spring to include a property declaration. As previously mentioned, the p-namespace does not have a schema definition, so you can set the name of the attribute to the property name.
该示例显示了bean定义中名为email的p-namespace属性。这告诉Spring包含一个属性声明。如前所述,p-namespace没有模式定义,因此可以将属性名设置为属性名。p:属性名=””
下面展示了引用其他bean的实例:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean name="john-classic" class="com.example.Person">
<property name="name" value="John Doe"/>
<property name="spouse" ref="jane"/>
</bean>
<bean name="john-modern" class="com.example.Person" p:name="John Doe" p:spouse-ref="jane"/>
<bean name="jane" class="com.example.Person">
<property name="name" value="Jane Doe"/>
</bean>
</beans>
This example includes not only a property value using the p-namespace but also uses a special format to declare property references. Whereas the first bean definition uses “ to create a reference from bean john to bean jane, the second bean definition uses p:spouse-ref="jane" as an attribute to do the exact same thing. In this case, spouse is the property name, whereas the -ref part indicates that this is not a straight value but rather a reference to another bean.
这个示例不仅包含一个使用p-namespace的属性值,而且还使用一种特殊格式来声明属性引用。第一个bean定义使用来创建一个从bean john到bean jane的引用,而第二个bean定义使用p:spouse-ref=”jane”作为一个属性来完成完全相同的工作。在本例中,spouse是属性名,而-ref部分指出这不是一个直接的值,而是对另一个bean的引用。
The p-namespace is not as flexible as the standard XML format. For example, the format for declaring property references clashes with properties that end in Ref, whereas the standard XML format does not. We recommend that you choose your approach carefully and communicate this to your team members to avoid producing XML documents that use all three approaches at the same time.
p-namespace不如标准XML格式灵活。例如,声明属性引用的格式与以Ref结尾的属性冲突,而标准XML格式则不冲突。我们建议您仔细选择您的方法,并将其传达给您的团队成员,以避免生成同时使用这三种方法的XML文档。
XML Shortcut with the c-namespace c命名空间
Similar to the [XML Shortcut with the p-namespace], the c-namespace, introduced in Spring 3.1, allows inlined attributes for configuring the constructor arguments rather then nested constructor-arg elements.
与p-namespace的XML快捷方式类似,在Spring 3.1中引入的c-namespace允许配置构造函数参数的内联属性,而不是嵌套的构造函数-参数元素。
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="beanTwo" class="x.y.ThingTwo"/>
<bean id="beanThree" class="x.y.ThingThree"/>
<!-- traditional declaration with optional argument names -->
<bean id="beanOne" class="x.y.ThingOne">
<constructor-arg name="thingTwo" ref="beanTwo"/>
<constructor-arg name="thingThree" ref="beanThree"/>
<constructor-arg name="email" value="something@somewhere.com"/>
</bean>
<!-- c-namespace declaration with argument names -->
<bean id="beanOne" class="x.y.ThingOne" c:thingTwo-ref="beanTwo" c:thingThree-ref="beanThree" c:email="something@somewhere.com"/>
</beans>
The c: namespace uses the same conventions as the p: one (a trailing -ref for bean references) for setting the constructor arguments by their names. Similarly, it needs to be declared in the XML file even though it is not defined in an XSD schema (it exists inside the Spring core).
For the rare cases where the constructor argument names are not available (usually if the bytecode was compiled without debugging information), you can use fallback to the argument indexes, as follows:
c: namespace使用与p: namespace相同的约定(bean引用的尾随-ref)来根据构造函数参数的名称设置参数。类似地,即使没有在XSD模式中定义它(它存在于Spring核心中),也需要在XML文件中声明它。
对于构造函数参数名不可用的罕见情况(通常是在编译字节码时没有调试信息的情况下),可以使用回退到参数索引,如下所示:
<!-- c-namespace index declaration -->
<bean id="beanOne" class="x.y.ThingOne" c:_0-ref="beanTwo" c:_1-ref="beanThree" c:_2="something@somewhere.com"/>
Due to the XML grammar, the index notation requires the presence of the leading _, as XML attribute names cannot start with a number (even though some IDEs allow it). A corresponding index notation is also available for <constructor-arg> elements but not commonly used since the plain order of declaration is usually sufficient there.
由于XML语法的原因,索引表示法要求前面有_,因为XML属性名不能以数字开头(尽管一些ide允许这样做)。对于元素也可以使用相应的索引表示法,但不常用,因为在这里声明的简单顺序通常就足够了。
In practice, the constructor resolution mechanism is quite efficient in matching arguments, so unless you really need to, we recommend using the name notation through-out your configuration.
在实践中,构造函数解析机制在匹配参数方面非常有效,因此,除非确实需要,否则我们建议在整个配置过程中使用名称符号。
Compound Property Names 复合属性名
You can use compound or nested property names when you set bean properties, as long as all components of the path except the final property name are not null. Consider the following bean definition:
在设置bean属性时,可以使用复合或嵌套属性名,只要路径的所有组件(最后的属性名除外)都不为空。
<bean id="something" class="things.ThingOne">
<property name="fred.bob.sammy" value="123" />
</bean>
The something bean has a fred property, which has a bob property, which has a sammy property, and that final sammy property is being set to a value of 123. In order for this to work, the fred property of something and the bob property of fred must not be null after the bean is constructed. Otherwise, a NullPointerException is thrown.
something bean有一个fred属性,它有一个bob属性,它有一个sammy属性,而最后那个sammy属性的值被设置为123。为了使其工作,在构造bean之后,fred的属性和fred的bob属性不能为空。否则,将抛出NullPointerException。
2.4.3 Using depends-on 使用depends-on
If a bean is a dependency of another bean, that usually means that one bean is set as a property of another. Typically you accomplish this with the “ element in XML-based configuration metadata. However, sometimes dependencies between beans are less direct. An example is when a static initializer in a class needs to be triggered, such as for database driver registration. The depends-on attribute can explicitly force one or more beans to be initialized before the bean using this element is initialized. The following example uses the depends-on attribute to express a dependency on a single bean:
如果一个bean是另一个bean的依赖项,这通常意味着将一个bean设置为另一个bean的属性。通常使用基于xml的配置元数据中的元素来完成此任务。然而,有时候bean之间的依赖关系不那么直接。例如,当需要触发类中的静态初始化器时,例如注册数据库驱动程序时。**依赖属性可以显式地强制在使用此元素的bean初始化之前对一个或多个bean进行初始化。**下面的示例使用depends-on属性来表示对单个对象的依赖关系
<bean id="beanOne" class="ExampleBean" depends-on="manager"/>
<bean id="manager" class="ManagerBean" />
To express a dependency on multiple beans, supply a list of bean names as the value of the depends-on attribute (commas, whitespace, and semicolons are valid delimiters):
为了表示对多个bean的依赖,提供一个bean名称列表作为依赖属性的值(逗号、空格和分号都是有效的分隔符):
<bean id="beanOne" class="ExampleBean" depends-on="manager,accountDao">
<property name="manager" ref="manager" />
</bean>
<bean id="manager" class="ManagerBean" />
<bean id="accountDao" class="x.y.jdbc.JdbcAccountDao" />
The depends-on attribute can specify both an initialization-time dependency and, in the case of singleton beans only, a corresponding destruction-time dependency. Dependent beans that define a depends-on relationship with a given bean are destroyed first, prior to the given bean itself being destroyed. Thus, depends-on can also control shutdown order.
depends-on属性可以指定一个初始化阶段的依赖项和在单例情况下相应的销毁阶段的依赖。与给定bean定义依赖关系的依赖bean在给定bean本身被销毁之前首先被销毁,因此这个属性也可以控制销毁顺序。
2.4.4 Lazy-initialized Beans Bean的懒加载
By default, ApplicationContext implementations eagerly create and configure all singleton beans as part of the initialization process. Generally, this pre-instantiation is desirable, because errors in the configuration or surrounding environment are discovered immediately, as opposed to hours or even days later. When this behavior is not desirable, you can prevent pre-instantiation of a singleton bean by marking the bean definition as being lazy-initialized. A lazy-initialized bean tells the IoC container to create a bean instance when it is first requested, rather than at startup.
默认情况下,ApplicationContext实现将创建和配置所有的单例bean作为初始化过程的一部分。通常,这种预实例化是可取的,因为配置或周围环境中的错误会立即被发现,而不是几小时甚至几天之后。当此行为不可取时,您可以通过将bean定义标记为延迟初始化来防止单例bean的预实例化。延迟初始化的bean告诉IoC容器在第一次请求时创建bean实例,而不是在启动时。
也就是说默认的Bean的加载方式是立即加载,你可以通过设置lazy-init属性来让他在使用时才加载。
<bean id="lazy" class="com.something.ExpensiveToCreateBean" lazy-init="true"/>
<bean name="not.lazy" class="com.something.AnotherBean"/>
When the preceding configuration is consumed by an ApplicationContext, the lazy bean is not eagerly pre-instantiated when the ApplicationContext starts, whereas the not.lazy bean is eagerly pre-instantiated.
当前面的配置被ApplicationContext使用时,当ApplicationContext启动时,被设置为懒加载的bean不会被立即实例化,而下面的not.lazy则会被立即实例化。
However, when a lazy-initialized bean is a dependency of a singleton bean that is not lazy-initialized, the ApplicationContext creates the lazy-initialized bean at startup, because it must satisfy the singleton’s dependencies. The lazy-initialized bean is injected into a singleton bean elsewhere that is not lazy-initialized.
然而,当延迟初始化的bean是未延迟初始化的单例bean的依赖项时,ApplicationContext在启动时创建延迟初始化的bean,因为它必须满足单例的依赖项。延迟初始化的bean被注入到一个没有延迟初始化的单例bean中。
就是说如果一个懒加载的bean是一个立即加载的bean的依赖项,那么这个懒加载的Bean会在容器创建时被初始化,这很容易理解
You can also control lazy-initialization at the container level by using the default-lazy-init attribute on the <beans> element, a the following example shows:
您还可以使用元素上的default-lazy-init属性来控制容器级别的延迟初始化,如下面的示例所示:
<beans default-lazy-init="true">
<!-- no beans will be pre-instantiated... -->
</beans>
2.4.5 Autowiring Collaborators 自动装配
The Spring container can autowire relationships between collaborating beans. You can let Spring resolve collaborators (other beans) automatically for your bean by inspecting the contents of the ApplicationContext. Autowiring has the following advantages:
- Autowiring can significantly reduce the need to specify properties or constructor arguments. (Other mechanisms such as a bean template [discussed elsewhere in this chapter]are also valuable in this regard.)
- Autowiring can update a configuration as your objects evolve. For example, if you need to add a dependency to a class, that dependency can be satisfied automatically without you needing to modify the configuration. Thus autowiring can be especially useful during development, without negating the option of switching to explicit wiring when the code base becomes more stable.
Spring容器可以自动创建协作bean之间的关系。通过检查ApplicationContext的内容,您可以让Spring为您的bean自动解析协作者(其他bean)。自动装配有以下优点:
- 自动装配可以大大减少指定属性或构造函数参数的需要。在这方面,本章其他地方讨论的其他机制(如bean模板)也很有价值
- 自动装配可以随着对象的修改更新配置。例如,如果需要向类添加依赖项,则可以自动满足该依赖项,而不需要修改配置。因此,自动装配在开发过程中特别有用,当代码库变得更加稳定时,自动装配可以避免切换到显式连接的选项。
When using XML-based configuration metadata (see Dependency Injection), you can specify the autowire mode for a bean definition with the autowire attribute of the “ element. The autowiring functionality has four modes. You specify autowiring per bean and can thus choose which ones to autowire. The following table describes the four autowiring modes:
在使用基于xml的配置元数据(请参阅依赖项注入)时,可以使用元素的autowire属性为bean定义指定autowire模式。自动装配功能有四种模式。您可以为每个bean指定自动装配,因此可以选择自动装配哪些bean。下表描述了四种自动装配模式:
| Mode | Explanation |
|---|---|
no |
(Default) No autowiring. Bean references must be defined by ref elements. Changing the default setting is not recommended for larger deployments, because specifying collaborators explicitly gives greater control and clarity. To some extent, it documents the structure of a system. |
byName |
Autowiring by property name. Spring looks for a bean with the same name as the property that needs to be autowired. For example, if a bean definition is set to autowire by name and it contains a master property (that is, it has a setMaster(..) method), Spring looks for a bean definition named master and uses it to set the property. |
byType |
Lets a property be autowired if exactly one bean of the property type exists in the container. If more than one exists, a fatal exception is thrown, which indicates that you may not use byType autowiring for that bean. If there are no matching beans, nothing happens (the property is not set). |
constructor |
Analogous to byType but applies to constructor arguments. If there is not exactly one bean of the constructor argument type in the container, a fatal error is raised. |
| 模式 | 解释 |
|---|---|
no |
默认值,不适用自动装配,Bean的引用必须通过ref定义,对于较大的部署,不建议更改默认设置,因为显式地指定协作者可以提供更好的控制和清晰度。在某种程度上,它记录了一个系统的结构。 |
byName |
根据属性名字自动装配,Spring寻找与需要自动装配的属性同名的bean。例如,如果一个bean定义被按名称设置为自动装配,并且它包含一个master属性(也就是说,它有一个setMaster(…)方法),Spring会查找一个名为master的bean定义并使用它来设置属性。 |
byType |
如果容器中恰好存在该属性类型的一个bean,则允许自动获取该属性。如果存在多个类型相同的bean,则抛出一个致命异常,这表明您不能为该bean使用byType自动装配。如果没有匹配的bean,则什么也不会发生(属性没有设置)。 |
constructor |
类似于byType,但适用于构造函数参数。如果容器中没有一个构造函数参数类型的bean,则会引发致命错误。 |
With byType or constructor autowiring mode, you can wire arrays and typed collections. In such cases, all autowire candidates within the container that match the expected type are provided to satisfy the dependency. You can autowire strongly-typed Map instances if the expected key type is String. An autowired Map instance’s values consist of all bean instances that match the expected type, and the Map instance’s keys contain the corresponding bean names.
使用byType或构造函数自动装配模式,您可以连接数组和类型化集合。在这种情况下,将提供容器中与预期类型匹配的所有autowire候选对象,以满足依赖性。如果期望的键类型是String,则可以自动装配强类型map实例。自动装配map实例的value由所有匹配期望类型的bean实例组成,而map实例的key包含相应的bean名称。
Limitations and Disadvantages of Autowiring 自动装配的局限性和缺点
Autowiring works best when it is used consistently across a project. If autowiring is not used in general, it might be confusing to developers to use it to wire only one or two bean definitions.
自动装配在跨项目一致使用时效果最好。如果通常不使用自动装配,那么开发人员使用它来连接一个或两个bean定义可能会感到困惑。
Consider the limitations and disadvantages of autowiring:
- Explicit dependencies in
propertyandconstructor-argsettings always override autowiring. You cannot autowire simple properties such as primitives,Strings, andClasses(and arrays of such simple properties). This limitation is by-design. - Autowiring is less exact than explicit wiring. Although, as noted in the earlier table, Spring is careful to avoid guessing in case of ambiguity that might have unexpected results. The relationships between your Spring-managed objects are no longer documented explicitly.
- Wiring information may not be available to tools that may generate documentation from a Spring container.
- Multiple bean definitions within the container may match the type specified by the setter method or constructor argument to be autowired. For arrays, collections, or
Mapinstances, this is not necessarily a problem. However, for dependencies that expect a single value, this ambiguity is not arbitrarily resolved. If no unique bean definition is available, an exception is thrown.
考虑自动装配的限制和缺点:
- 属性和构造参数设置中的显式依赖项总是覆盖自动装配。您不能自动生成简单的属性,如原语、字符串和类(以及这些简单属性的数组)。这种限制是由设计造成的。
- 自动装配不如直接注入精确。尽管如前面的表中所述,Spring小心地避免猜测,以免产生可能产生意外结果的歧义。被spring管理对象不会被精确地记录下来。
- 连接信息可能对从Spring容器生成文档的工具不可用。(啥意思)
- 容器中的多个bean定义可能与要自动装配的setter方法或构造函数参数指定的类型相匹配。对于数组、集合或映射实例,这不一定是个问题。然而,对于期望单个值的依赖项,这种模糊性不是任意解决的。如果没有唯一的bean定义可用,则抛出异常。
In the latter scenario, you have several options:
- Abandon autowiring in favor of explicit wiring.
- Avoid autowiring for a bean definition by setting its
autowire-candidateattributes tofalse, as described in the next section. - Designate a single bean definition as the primary candidate by setting the
primaryattribute of its “ element totrue. - Implement the more fine-grained control available with annotation-based configuration, as described in Annotation-based Container Configuration.
在后一种情况下,你有几个选择:
- 放弃自动装配,使用直接注入
- 通过将bean定义的autowire-candidate属性设置为false来避免自动装配。
- 通过将其元素的primary属性设置为true,将单个bean定义指定为主候选。
- 实现基于注释的配置提供的更细粒度的控制,如基于注释的容器配置中所述。
Excluding a Bean from Autowiring 从自动装配中排除一个Bean
On a per-bean basis, you can exclude a bean from autowiring. In Spring’s XML format, set the autowire-candidate attribute of the “ element to false. The container makes that specific bean definition unavailable to the autowiring infrastructure (including annotation style configurations such as [`@Autowired]
在每个bean的基础上,可以将bean排除在自动装配之外。在Spring的XML格式中,将元素的autowire-candidate属性设置为false。容器使特定的bean定义对自动装配基础设施(包括诸如@Autowired之类的注释样式配置)不可用。
The autowire-candidate attribute is designed to only affect type-based autowiring. It does not affect explicit references by name, which get resolved even if the specified bean is not marked as an autowire candidate. As a consequence, autowiring by name nevertheless injects a bean if the name matches.
utowire-candidate属性被设计为只影响基于类型的自动装配。它不会影响按名称显示的引用,即使指定的bean没有标记为autowire候选bean,也会解析这些引用。因此,如果名字匹配,自动装配仍然会注入一个bean。
You can also limit autowire candidates based on pattern-matching against bean names. The top-level <beans/> element accepts one or more patterns within its default-autowire-candidates attribute. For example, to limit autowire candidate status to any bean whose name ends with Repository, provide a value of *Repository. To provide multiple patterns, define them in a comma-separated list. An explicit value of true or false for a bean definition’s autowire-candidate attribute always takes precedence. For such beans, the pattern matching rules do not apply.
您还可以根据bean名称的正则匹配来限制自动装配候选对象。顶级元素在其default-autowire-candidate属性中接受一个或多个正则表达式。例如,要将autowire候选状态限制为名称以Repository结尾的任何bean,请提供一个值*Repository。要提供多个模式,请在逗号分隔的列表中定义它们。bean定义的autowire-candidate属性的显式值true或false总是优先考虑。对于这样的bean,不适用正则匹配规则。
These techniques are useful for beans that you never want to be injected into other beans by autowiring. It does not mean that an excluded bean cannot itself be configured by using autowiring. Rather, the bean itself is not a candidate for autowiring other beans.
这些技术对于那些您不希望通过自动装配将其注入到其他bean中的bean非常有用。这并不意味着被排除的bean本身不能被用来自动装配,相反,它本身不是其他bean自动装配的一个候选者。(这里有点糊涂了)
2.4.6 Method Injection 方法注入
In most application scenarios, most beans in the container are singletons. When a singleton bean needs to collaborate with another singleton bean or a non-singleton bean needs to collaborate with another non-singleton bean, you typically handle the dependency by defining one bean as a property of the other. A problem arises when the bean lifecycles are different. Suppose singleton bean A needs to use non-singleton (prototype) bean B, perhaps on each method invocation on A. The container creates the singleton bean A only once, and thus only gets one opportunity to set the properties. The container cannot provide bean A with a new instance of bean B every time one is needed.
在大多数应用程序场景中,容器中的大多数bean都是单例的。当一个单例bean需要与另一个单例bean协作,或者一个非单例bean需要与另一个非单例bean协作时,通常通过将一个bean定义为另一个bean的属性来处理依赖性。当bean的生命周期不同时,就会出现问题。假设单例bean A需要使用非单例(原型)bean B,可能是在A的每个方法调用上。容器只创建一次单例bean A,因此只有一次机会来设置属性。容器不能每次需要bean B的新实例时都向bean A提供一个。
A solution is to forego some inversion of control. You can [make bean A aware of the container]by implementing the ApplicationContextAware interface, and by making a getBean("B") call to the container ask for (a typically new) bean B instance every time bean A needs it. The following example shows this approach:
解决的办法是放弃一些控制反转。您可以通过实现applicationcontextAware接口,并在每次bean A需要时调用容器的getBean(“B”)来请求(通常是一个新的)bean B实例,从而使bean A知道容器。下面的例子展示了这种方法:
public class CommandManager implements ApplicationContextAware {
private ApplicationContext applicationContext;
public Object process(Map commandState) {
// grab a new instance of the appropriate Command
Command command = createCommand();
// set the state on the (hopefully brand new) Command instance
command.setState(commandState);
return command.execute();
}
protected Command createCommand() {
// notice the Spring API dependency!
//在每次需要的时候从容器中获取
return this.applicationContext.getBean("command", Command.class);
}
public void setApplicationContext(
ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}
The preceding is not desirable, because the business code is aware of and coupled to the Spring Framework. Method Injection, a somewhat advanced feature of the Spring IoC container, lets you handle this use case cleanly.
刚才的方法是不可取的,因为业务代码与Spring框架耦合在了一起。方法注入是Spring IoC容器的一个比较高级的特性,它允许您干净地处理这个用例,这会在后面讲解。
Lookup Method Injection 查找方法注入
Lookup method injection is the ability of the container to override methods on container-managed beans and return the lookup result for another named bean in the container. The lookup typically involves a prototype bean, as in the scenario described in the preceding section. The Spring Framework implements this method injection by using bytecode generation from the CGLIB library to dynamically generate a subclass that overrides the method.
查找方法注入是容器覆盖容器管理bean上的方法并返回容器中另一个命名bean的查找结果的能力。查找通常涉及到一个原型(多例)bean,如前一节描述的场景所示。Spring框架通过使用来自CGLIB库的字节码生成来动态生成一个子类,并重写这个方法,从而实现了这种方法注入。
-
For this dynamic subclassing to work, the class that the Spring bean container subclasses cannot be
final, and the method to be overridden cannot befinal, either. -
Unit-testing a class that has an
abstractmethod requires you to subclass the class yourself and to supply a stub implementation of theabstractmethod. -
Concrete methods are also necessary for component scanning, which requires concrete classes to pick up.
-
A further key limitation is that lookup methods do not work with factory methods and in particular not with
@Beanmethods in configuration classes, since, in that case, the container is not in charge of creating the instance and therefore cannot create a runtime-generated subclass on the fly. -
想要使用这种动态生成子类的方式,子类的父类不能是final修饰的,并且重写的方法也不饿能是final修饰的
-
对具有抽象方法的类进行单元测试需要您自己对该类进行子类化,并提供抽象方法的存根实现。
-
组件扫描也需要具体的方法,这需要具体的类来获取。
-
进一步的关键限制是,查找方法不能与工厂方法一起工作,特别是不能与配置类中的@Bean方法一起工作,因为在这种情况下,容器不负责创建实例,因此不能动态地创建运行时生成的子类。
关于以上的内容还待进一步理解和消化
In the case of the CommandManager class in the previous code snippet, the Spring container dynamically overrides the implementation of the createCommand() method. The CommandManager class does not have any Spring dependencies, as the reworked example shows:
在前面代码片段中的CommandManager类的情况下,Spring容器动态地覆盖createCommand()方法的实现。CommandManager类没有任何Spring依赖项,正如重新处理的示例所示:
public abstract class CommandManager {
public Object process(Object commandState) {
// grab a new instance of the appropriate Command interface
Command command = createCommand();
// set the state on the (hopefully brand new) Command instance
command.setState(commandState);
return command.execute();
}
// okay... but where is the implementation of this method?
protected abstract Command createCommand();
}
In the client class that contains the method to be injected (the CommandManager in this case), the method to be injected requires a signature of the following form:
在包含要注入的方法的client类中(本例中的CommandManager),要注入的方法需要以下形式的定义:
<public|protected> [abstract] <return-type> theMethodName(no-arguments);
If the method is abstract, the dynamically-generated subclass implements the method. Otherwise, the dynamically-generated subclass overrides the concrete method defined in the original class. Consider the following example:
如果方法是抽象的,则动态生成的子类实现该方法。否则,动态生成的子类将覆盖在原始类中定义的具体方法。考虑下面的例子:
<!-- a stateful bean deployed as a prototype (non-singleton) -->
<bean id="myCommand" class="fiona.apple.AsyncCommand" scope="prototype">
<!-- inject dependencies here as required -->
</bean>
<!-- commandProcessor uses statefulCommandHelper -->
<bean id="commandManager" class="fiona.apple.CommandManager">
<lookup-method name="createCommand" bean="myCommand"/>
</bean>
The bean identified as commandManager calls its own createCommand() method whenever it needs a new instance of the myCommand bean. You must be careful to deploy the myCommand bean as a prototype if that is actually what is needed. If it is a singleton, the same instance of the myCommand bean is returned each time.
Alternatively, within the annotation-based component model, you can declare a lookup method through the @Lookup annotation, as the following example shows:
标识为commandManager的bean在需要myCommand bean的新实例时调用自己的createCommand()方法。如果实际需要的话,您必须小心地将myCommand bean部署为原型。如果它是单例的,那么每次都会返回相同的myCommand bean实例。
或者,在基于注释的组件模型中,您可以通过@Lookup注释声明一个查找方法,如下面的示例所示:
public abstract class CommandManager {
public Object process(Object commandState) {
Command command = createCommand();
command.setState(commandState);
return command.execute();
}
@Lookup("myCommand")
protected abstract Command createCommand();
}
Or, more idiomatically, you can rely on the target bean getting resolved against the declared return type of the lookup method:
或者,更具体地说,您可以依赖于根据声明的查找方法返回类型解析目标bean:
public abstract class CommandManager {
public Object process(Object commandState) {
MyCommand command = createCommand();
command.setState(commandState);
return command.execute();
}
@Lookup
protected abstract MyCommand createCommand();
}
Note that you should typically declare such annotated lookup methods with a concrete stub implementation, in order for them to be compatible with Spring’s component scanning rules where abstract classes get ignored by default. This limitation does not apply to explicitly registered or explicitly imported bean classes.
请注意,您通常应该使用具体的存根实现来声明此类带注释的查找方法,以便使它们与Spring的组件扫描规则兼容,其中抽象类在缺省情况下被忽略。此限制不适用于显式注册或显式导入的bean类。
Another way of accessing differently scoped target beans is an ObjectFactory/ Provider injection point. See [Scoped Beans as Dependencies].
You may also find the ServiceLocatorFactoryBean (in the org.springframework.beans.factory.config package) to be useful.
访问范围不同的目标bean的另一种方法是ObjectFactory/ Provider注入点。将作用域bean视为依赖项。
您还可以在org.springframe .bean .factory中找到ServiceLocatorFactoryBean。配置包)是有用的。
Arbitrary Method Replacement 任意的方法替换
A less useful form of method injection than lookup method injection is the ability to replace arbitrary methods in a managed bean with another method implementation. You can safely skip the rest of this section until you actually need this functionality.
与查找方法注入相比,一种不太有用的方法注入形式是能够用另一种方法实现替换托管bean中的任意方法。您可以安全地跳过本节的其余部分,直到您真正需要此功能为止。
With XML-based configuration metadata, you can use the replaced-method element to replace an existing method implementation with another, for a deployed bean. Consider the following class, which has a method called computeValue that we want to override:
对于基于xml的配置元数据,您可以使用replace -method元素将已部署bean的现有方法实现替换为其他方法实现。考虑下面的类,它有一个我们想要重写的叫做computeValue的方法:
public class MyValueCalculator {
public String computeValue(String input) {
// some real code...
}
// some other methods...
}
A class that implements the org.springframework.beans.factory.support.MethodReplacer interface provides the new method definition, as the following example shows:
一个实现了org.springframework.beans.factory.support.MethodReplacer接口的类提供了新方法的定义,如接下来的例子:
/** * meant to be used to override the existing computeValue(String) * implementation in MyValueCalculator */
public class ReplacementComputeValue implements MethodReplacer {
public Object reimplement(Object o, Method m, Object[] args) throws Throwable {
// get the input value, work with it, and return a computed result
String input = (String) args[0];
...
return ...;
}
}
The bean definition to deploy the original class and specify the method override would resemble the following example:
部署原始类并指定方法覆盖的bean定义,如以下示例:
<bean id="myValueCalculator" class="x.y.z.MyValueCalculator">
<!-- arbitrary method replacement -->
<replaced-method name="computeValue" replacer="replacementComputeValue">
<arg-type>String</arg-type>
</replaced-method>
</bean>
<bean id="replacementComputeValue" class="a.b.c.ReplacementComputeValue"/>
You can use one or more <arg-type> elements within the <replaced-method> element to indicate the method signature of the method being overridden. The signature for the arguments is necessary only if the method is overloaded and multiple variants exist within the class. For convenience, the type string for an argument may be a substring of the fully qualified type name. For example, the following all match java.lang.String:
您可以在< replacedmethod />元素中使用一个或多个< argtype />元素来指示被覆盖的方法的方法签名。只有在方法重载且类中存在多个变量时,才需要对参数进行签名。为了方便起见,参数的类型字符串可以是全限定类名的子字符串。例如,以下所有都匹配java.lang.String:
java.lang.String
String
Str
Because the number of arguments is often enough to distinguish between each possible choice, this shortcut can save a lot of typing, by letting you type only the shortest string that matches an argument type.
因为参数的数量通常足以区分每种可能的选择,所以这个快捷方式可以节省大量的输入,因为它允许您只输入与参数类型匹配的最短字符串。
2.5 Bean Scopes Bean的作用域
When you create a bean definition, you create a recipe for creating actual instances of the class defined by that bean definition. The idea that a bean definition is a recipe is important, because it means that, as with a class, you can create many object instances from a single recipe.
当您创建一个bean定义时,您将定义一个由该bean定义的类的实际实例化的方法。bean定义是菜谱的想法很重要,因为它意味着,与类一样,您可以从一个菜谱创建多个对象实例。
You can control not only the various dependencies and configuration values that are to be plugged into an object that is created from a particular bean definition but also control the scope of the objects created from a particular bean definition. This approach is powerful and flexible, because you can choose the scope of the objects you create through configuration instead of having to bake in the scope of an object at the Java class level. Beans can be defined to be deployed in one of a number of scopes. The Spring Framework supports six scopes, four of which are available only if you use a web-aware ApplicationContext. You can also create [a custom scope.]
您不仅可以控制要插入到由特定bean定义创建的对象中的各种依赖项和配置值,还可以控制由特定bean定义创建的对象的范围。这种方法强大而灵活,因为您可以选择通过配置创建的对象的范围,而不必在Java类级别上考虑对象的范围。可以将bean定义为部署在多种作用域中的一种。Spring框架支持6种作用域,其中4种只有在您使用web框架时才可用
| Scope | Description |
|---|---|
| singleton | (Default) Scopes a single bean definition to a single object instance for each Spring IoC container. |
| prototype | Scopes a single bean definition to any number of object instances. |
| request | Scopes a single bean definition to the lifecycle of a single HTTP request. That is, each HTTP request has its own instance of a bean created off the back of a single bean definition. Only valid in the context of a web-aware Spring ApplicationContext. |
| session | Scopes a single bean definition to the lifecycle of an HTTP Session. Only valid in the context of a web-aware Spring ApplicationContext. |
| application | Scopes a single bean definition to the lifecycle of a ServletContext. Only valid in the context of a web-aware Spring ApplicationContext. |
| websocket | Scopes a single bean definition to the lifecycle of a WebSocket. Only valid in the context of a web-aware Spring ApplicationContext. |
| Scope | Description |
|---|---|
| singleton | (默认)为每个Spring IoC容器创建单个实例。单例作用域 |
| prototype | 多例作用域,为每个请求创建一个新的bean实例 |
| request | 单个HTTP请求的生命周期。也就是说,每个HTTP请求都有自己的bean实例,这些实例是在单个bean定义的基础上创建的。仅在可感知web的Spring应用程序上下文中有效。 |
| session | HTTPSession的生命周期。仅在可感知web的Spring应用程序上下文中有效。 |
| application | ServletContext的生命周期。仅在可感知web的Spring应用程序上下文中有效。 |
| websocket | websocket的生命周期。仅在可感知web的Spring应用程序上下文中有效。 |
2.5.1 The Singleton Scope 单例作用域
Only one shared instance of a singleton bean is managed, and all requests for beans with an ID or IDs that match that bean definition result in that one specific bean instance being returned by the Spring container.
To put it another way, when you define a bean definition and it is scoped as a singleton, the Spring IoC container creates exactly one instance of the object defined by that bean definition. This single instance is stored in a cache of such singleton beans, and all subsequent requests and references for that named bean return the cached object. The following image shows how the singleton scope works:
只管理一个单例bean的一个共享实例,所有对具有与该bean定义匹配的ID或ID的bean的请求都会导致Spring容器返回该特定bean实例。
换句话说,当您定义一个bean定义并将其定义为一个单例对象时,Spring IoC容器将仅创建该bean定义定义的对象的一个实例。此单一实例存储在此类单例bean的缓存中,该指定bean的所有后续请求和引用都将返回缓存的对象。下图显示了单例范围的工作方式:
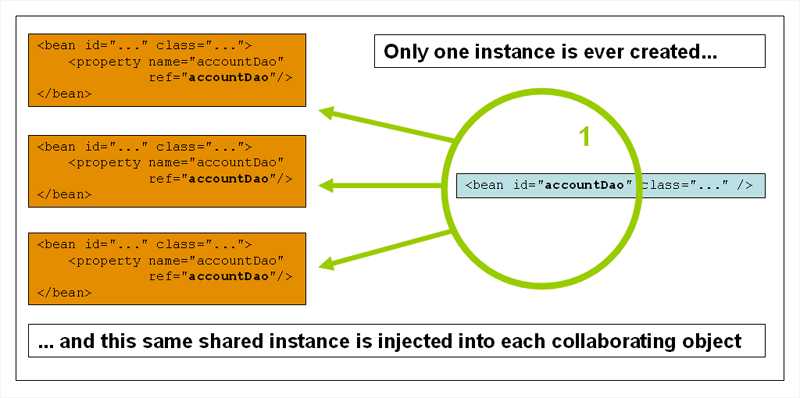
Spring’s concept of a singleton bean differs from the singleton pattern as defined in the Gang of Four (GoF) patterns book. The GoF singleton hard-codes the scope of an object such that one and only one instance of a particular class is created per ClassLoader. The scope of the Spring singleton is best described as being per-container and per-bean. This means that, if you define one bean for a particular class in a single Spring container, the Spring container creates one and only one instance of the class defined by that bean definition. The singleton scope is the default scope in Spring. To define a bean as a singleton in XML, you can define a bean as shown in the following example:
Spring的单例bean概念与GoF(GoF)设计模式书中定义的单例模式不同。单例模式对对象的作用域进行硬编码,这样每个类装入器只能创建一个特定类的实例。Spring单例的范围最好描述为每个容器和每个bean。这意味着,如果您在单个Spring容器中为特定类定义一个bean,那么Spring容器将创建由该bean定义定义的类的一个且仅一个实例。单例范围是Spring的默认范围。要在XML中将bean定义为单例,您可以定义一个bean,如下面的例子所示:
<bean id="accountService" class="com.something.DefaultAccountService"/>
<!-- the following is equivalent, though redundant (singleton scope is the default) -->
<bean id="accountService" class="com.something.DefaultAccountService" scope="singleton"/>
2.5.2The Prototype Scope 原型范围(多例)
The non-singleton prototype scope of bean deployment results in the creation of a new bean instance every time a request for that specific bean is made. That is, the bean is injected into another bean or you request it through a getBean() method call on the container. As a rule, you should use the prototype scope for all stateful beans and the singleton scope for stateless beans.
bean部署的非单例原型范围导致在每次发出对特定bean的请求时都会创建一个新的bean实例。也就是说,bean被注入到另一个bean中,或者您通过容器上的getBean()方法调用请求它。通常,您应该为所有有状态bean使用原型范围,为无状态bean使用单例范围。
下图说明了Spring原型的作用域:
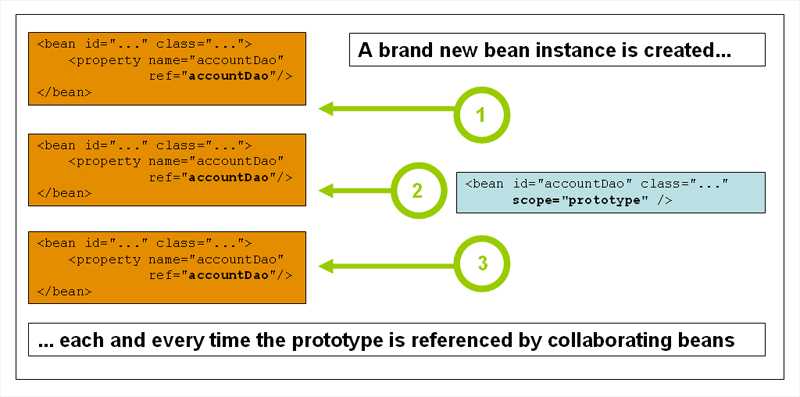
(A data access object (DAO) is not typically configured as a prototype, because a typical DAO does not hold any conversational state. It was easier for us to reuse the core of the singleton diagram.)
The following example defines a bean as a prototype in XML:
数据访问对象(DAO)通常不配置为原型,因为典型的DAO不包含任何会话状态。我们更容易重用单例图的核心。)
下面的例子在XML中将bean定义为原型:
<bean id="accountService" class="com.something.DefaultAccountService" scope="prototype"/>
In contrast to the other scopes, Spring does not manage the complete lifecycle of a prototype bean. The container instantiates, configures, and otherwise assembles a prototype object and hands it to the client, with no further record of that prototype instance. Thus, although initialization lifecycle callback methods are called on all objects regardless of scope, in the case of prototypes, configured destruction lifecycle callbacks are not called. The client code must clean up prototype-scoped objects and release expensive resources that the prototype beans hold. To get the Spring container to release resources held by prototype-scoped beans, try using a custom [bean post-processor], which holds a reference to beans that need to be cleaned up.
In some respects, the Spring container’s role in regard to a prototype-scoped bean is a replacement for the Java new operator. All lifecycle management past that point must be handled by the client. (For details on the lifecycle of a bean in the Spring container, see [Lifecycle Callbacks])
与其他作用域不同,Spring不管理原型bean的完整生命周期。容器实例化、配置或以其他方式组装原型对象并将其交给客户端,而不需要该原型实例的进一步记录。因此,尽管初始化生命周期回调方法在所有对象上都被调用,而与范围无关,但是在原型的情况下,配置的销毁生命周期回调不会被调用。客户机代码必须清理原型作用域的对象,并释放原型bean持有的昂贵资源。为了让Spring容器释放原型作用域bean所持有的资源,可以尝试使用一个自定义bean后处理器,它持有一个需要清理的bean引用。
在某些方面,Spring容器在原型作用域bean方面的角色可以替代Java new操作符。所有超过那个点的生命周期管理都必须由客户端处理。(有关Spring容器中bean生命周期的详细信息,请参阅生命周期回调。)
2.5.3 Singleton Beans with Prototype-bean Dependencies单例Bean依赖原型Bean
When you use singleton-scoped beans with dependencies on prototype beans, be aware that dependencies are resolved at instantiation time. Thus, if you dependency-inject a prototype-scoped bean into a singleton-scoped bean, a new prototype bean is instantiated and then dependency-injected into the singleton bean. The prototype instance is the sole instance that is ever supplied to the singleton-scoped bean.
当您使用依赖于原型bean的单例作用域bean时,请注意依赖项是在实例化时解析的。因此,如果您依赖地将一个原型作用域的bean注入到一个单例作用域的bean中,那么一个新的原型bean将被实例化,然后依赖注入到单例bean中。prototype实例是惟一提供给单例作用域bean的实例。
However, suppose you want the singleton-scoped bean to acquire a new instance of the prototype-scoped bean repeatedly at runtime. You cannot dependency-inject a prototype-scoped bean into your singleton bean, because that injection occurs only once, when the Spring container instantiates the singleton bean and resolves and injects its dependencies. If you need a new instance of a prototype bean at runtime more than once, see [Method Injection]
但是,假设您希望单例作用域bean在运行时重复获取原型作用域bean的新实例。您不能依赖地将一个原型作用域的bean注入到您的单例bean中,因为这种注入只发生一次,当Spring容器实例化单例bean并解析和注入它的依赖项时。如果您需要在运行时多次使用原型bean的新实例,请参阅方法注入
2.5.4 Request, Session, Application, and WebSocket Scopes
The request, session, application, and websocket scopes are available only if you use a web-aware Spring ApplicationContext implementation (such as XmlWebApplicationContext). If you use these scopes with regular Spring IoC containers, such as the ClassPathXmlApplicationContext, an IllegalStateException that complains about an unknown bean scope is thrown.
只有在使用web感知的Spring ApplicationContext实现(如XmlWebApplicationContext)时,请求、会话、应用程序和websocket作用域才可用。如果您将这些作用域与常规的Spring IoC容器(如ClassPathXmlApplicationContext)一起使用,则会抛出一个IllegalStateException,它会报错一个未知的bean作用域。
Initial Web Configuration 初始化web配置
To support the scoping of beans at the request, session, application, and websocket levels (web-scoped beans), some minor initial configuration is required before you define your beans. (This initial setup is not required for the standard scopes: singleton and prototype.)
How you accomplish this initial setup depends on your particular Servlet environment.
If you access scoped beans within Spring Web MVC, in effect, within a request that is processed by the Spring DispatcherServlet, no special setup is necessary. DispatcherServlet already exposes all relevant state.
为了在请求、会话、应用程序和websocket级别(web范围的bean)上支持bean的作用域,需要在定义bean之前进行一些小的初始配置。(标准范围:单例和原型不需要这个初始设置。)
如何完成这个初始设置取决于特定的Servlet环境。
如果您在Spring Web MVC中访问作用域bean,实际上,在由Spring DispatcherServlet处理的请求中,不需要特殊的设置。DispatcherServlet已经公开了所有相关状态。
If you use a Servlet 2.5 web container, with requests processed outside of Spring’s DispatcherServlet (for example, when using JSF or Struts), you need to register the org.springframework.web.context.request.RequestContextListener ServletRequestListener. For Servlet 3.0+, this can be done programmatically by using the WebApplicationInitializer interface. Alternatively, or for older containers, add the following declaration to your web application’s web.xml file:
如果您使用Servlet 2.5 web容器,并在Spring的DispatcherServlet之外处理请求(例如,在使用JSF或Struts时),那么您需要注册org.springframework.web.context.request.RequestContextListener 的ServletRequestListener。对于Servlet 3.0+,这可以通过使用WebApplicationInitializer接口以编程方式实现。或者,对于较旧的容器,将以下声明添加到web应用程序的web.xml文件中:
<web-app>
...
<listener>
<listener-class>
org.springframework.web.context.request.RequestContextListener
</listener-class>
</listener>
...
</web-app>
Alternatively, if there are issues with your listener setup, consider using Spring’s RequestContextFilter. The filter mapping depends on the surrounding web application configuration, so you have to change it as appropriate. The following listing shows the filter part of a web application:
另外,如果侦听器设置有问题,可以考虑使用Spring的RequestContextFilter。筛选器映射依赖于周围的web应用程序配置,因此您必须对其进行适当的更改。下面的清单显示了web应用程序的过滤部分:
<web-app>
...
<filter>
<filter-name>requestContextFilter</filter-name>
<filter-class>org.springframework.web.filter.RequestContextFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>requestContextFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
...
</web-app>
DispatcherServlet, RequestContextListener, and RequestContextFilter all do exactly the same thing, namely bind the HTTP request object to the Thread that is servicing that request. This makes beans that are request- and session-scoped available further down the call chain.
DispatcherServlet、RequestContextListener和RequestContextFilter都做完全相同的事情,即将HTTP请求对象绑定到服务该请求的线程。这使得在request和session范围内的bean可以在调用链的更底层使用。
Request scope
请考虑以下bean定义的XML配置:
<bean id="loginAction" class="com.something.LoginAction" scope="request"/>
The Spring container creates a new instance of the LoginAction bean by using the loginAction bean definition for each and every HTTP request. That is, the loginAction bean is scoped at the HTTP request level. You can change the internal state of the instance that is created as much as you want, because other instances created from the same loginAction bean definition do not see these changes in state. They are particular to an individual request. When the request completes processing, the bean that is scoped to the request is discarded.
通过为每个HTTP请求使用LoginAction bean时,Spring容器创建了LoginAction bean的新实例。也就是说,loginAction bean的作用域在HTTP请求级别。您可以随意更改创建的实例的内部状态,因为从相同的loginAction bean定义创建的其他实例在状态中看不到这些更改。它们是特定于个人请求的。当请求完成处理时,作用域为request的bean被丢弃。
When using annotation-driven components or Java configuration, the @RequestScope annotation can be used to assign a component to the request scope. The following example shows how to do so:
在使用注释驱动的组件或Java配置时,可以使用@RequestScope注释将组件分配给请求范围。下面的例子演示了如何做到这一点:
@RequestScope
@Component
public class LoginAction {
// ...
}
Session Scope
Consider the following XML configuration for a bean definition:
<bean id="userPreferences" class="com.something.UserPreferences" scope="session"/>
The Spring container creates a new instance of the UserPreferences bean by using the userPreferences bean definition for the lifetime of a single HTTP Session. In other words, the userPreferences bean is effectively scoped at the HTTP Session level. As with request-scoped beans, you can change the internal state of the instance that is created as much as you want, knowing that other HTTP Session instances that are also using instances created from the same userPreferences bean definition do not see these changes in state, because they are particular to an individual HTTP Session. When the HTTP Session is eventually discarded, the bean that is scoped to that particular HTTP Session is also discarded.
通过为单个HTTP会话的生命周期使用UserPreferences bean定义,Spring容器创建了UserPreferences bean的一个新实例。换句话说,userPreferences bean有效地限定在HTTP会话级别的范围内。与请求范围内bean一样,你可以改变内部状态的实例创建尽可能多的你想要的,知道其他HTTP会话实例也使用相同的实例创建userPreferences bean定义看不到这些变化状态,因为他们是特定于一个单独的HTTP会话.当HTTPSession最终被销毁时,作用域为该特定HTTP会话的bean也被销毁。
When using annotation-driven components or Java configuration, you can use the @SessionScope annotation to assign a component to the session scope.
用Java注解实现:
@SessionScope
@Component
public class UserPreferences {
// ...
}
Application Scope
<bean id="appPreferences" class="com.something.AppPreferences" scope="application"/>
@ApplicationScope
@Component
public class AppPreferences {
// ...
}
The Spring container creates a new instance of the AppPreferences bean by using the appPreferences bean definition once for the entire web application. That is, the appPreferences bean is scoped at the ServletContext level and stored as a regular ServletContext attribute. This is somewhat similar to a Spring singleton bean but differs in two important ways: It is a singleton per ServletContext, not per Spring ‘ApplicationContext’ (for which there may be several in any given web application), and it is actually exposed and therefore visible as a ServletContext attribute.
通过为整个web应用程序使用一次AppPreferences bean定义,Spring容器创建了AppPreferences bean的一个新实例。也就是说,appPreferences bean的作用域在ServletContext级别,并存储为一个常规的ServletContext属性。这有点类似于单例bean,但在两个重要方面不同:他为每个ServletContext创建同一个实例,并不是每个spring的容器(在任何给定的web应用程序中都可能有多个),它实际上是暴露,因此可见ServletContext属性。
Scoped Beans as Dependencies
The Spring IoC container manages not only the instantiation of your objects (beans), but also the wiring up of collaborators (or dependencies). If you want to inject (for example) an HTTP request-scoped bean into another bean of a longer-lived scope, you may choose to inject an AOP proxy in place of the scoped bean. That is, you need to inject a proxy object that exposes the same public interface as the scoped object but that can also retrieve the real target object from the relevant scope (such as an HTTP request) and delegate method calls onto the real object.
Spring IoC容器不仅管理对象(bean)的实例化,还管理协作者(或依赖项)的连接。如果您想将(例如)一个HTTP Request作用域的bean注入到另一个更长的作用域的bean中,您可以选择注入一个AOP代理来代替作用域的bean。也就是说,您需要注入一个代理对象,它与作用域对象公开相同的公共接口,但也可以从相关作用域(如HTTP请求)检索实际目标对象,并将方法调用委托给实际对象。
You may also use <aop:scoped-proxy> between beans that are scoped as singleton, with the reference then going through an intermediate proxy that is serializable and therefore able to re-obtain the target singleton bean on deserialization.
When declaring <aop:scoped-proxy/> against a bean of scope prototype, every method call on the shared proxy leads to the creation of a new target instance to which the call is then being forwarded.
Also, scoped proxies are not the only way to access beans from shorter scopes in a lifecycle-safe fashion. You may also declare your injection point (that is, the constructor or setter argument or autowired field) as ObjectFactory<MyTargetBean>, allowing for a getObject() call to retrieve the current instance on demand every time it is needed — without holding on to the instance or storing it separately.
As an extended variant, you may declare ObjectProvider<MyTargetBean>, which delivers several additional access variants, including getIfAvailable and getIfUnique.
The JSR-330 variant of this is called Provider and is used with a Provider<MyTargetBean> declaration and a corresponding get() call for every retrieval attempt. See here for more details on JSR-330 overall.
你也可以在定义为单例的bean之间使用aop:scope-proxy/,然后引用通过一个可序列化的中间代理,因此能够在反序列化时重新获得目标单例bean。
当对范围原型的bean声明aop:scoped-proxy/时,共享代理上的每个方法调用都会导致创建一个新的目标实例,然后将调用转发给该实例。
而且,作用域代理不是以生命周期安全的方式从较短的作用域访问bean的惟一方法。你也可以声明你的注射点(也就是构造函数或setter参数或autowired的字段)作为ObjectFactory < MyTargetBean >,允许getObject()调用来检索当前实例对需求每次需要——没有分别持有实例或存储它。
作为扩展的变体,您可以声明ObjectProvider,它提供了几个额外的访问变体,包括getIfAvailable和getIfUnique。
该方法的JSR-330变体称为Provider,它与Provider声明一起使用,并在每次检索尝试时调用相应的get()调用。有关JSR-330的更多细节,请参见这里。
The configuration in the following example is only one line, but it is important to understand the “why” as well as the “how” behind it:
下面例子中的配置只有一行,但是理解它背后的“为什么”和“如何”是很重要的:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- an HTTP Session-scoped bean exposed as a proxy -->
<bean id="userPreferences" class="com.something.UserPreferences" scope="session">
<!-- instructs the container to proxy the surrounding bean -->
<aop:scoped-proxy/>
</bean>
<!-- a singleton-scoped bean injected with a proxy to the above bean -->
<bean id="userService" class="com.something.SimpleUserService">
<!-- a reference to the proxied userPreferences bean -->
<property name="userPreferences" ref="userPreferences"/>
</bean>
</beans>
To create such a proxy, you insert a child <aop:scoped-proxy/> element into a scoped bean definition (see Choosing the Type of Proxy to Create and XML Schema-based configuration). Why do definitions of beans scoped at the request, session and custom-scope levels require the <aop:scoped-proxy/> element? Consider the following singleton bean definition and contrast it with what you need to define for the aforementioned scopes (note that the following userPreferences bean definition as it stands is incomplete):
要创建这样的代理,需要将一个子aop:scoped-proxy/元素插入到有作用域的bean定义中(参见选择要创建的代理类型和基于XML模式的配置)。为什么在请求、会话和自定义范围级别定义作用域的bean需要aop:作用域代理/元素?考虑一下下面的单例bean定义,并将它与您需要为前面提到的作用域定义的内容进行对比(请注意,下面的userPreferences bean定义是不完整的):
<bean id="userPreferences" class="com.something.UserPreferences" scope="session"/>
<bean id="userManager" class="com.something.UserManager">
<property name="userPreferences" ref="userPreferences"/>
</bean>
In the preceding example, the singleton bean (userManager) is injected with a reference to the HTTP Session-scoped bean (userPreferences). The salient point here is that the userManager bean is a singleton: it is instantiated exactly once per container, and its dependencies (in this case only one, the userPreferences bean) are also injected only once. This means that the userManager bean operates only on the exact same userPreferences object (that is, the one with which it was originally injected.
在前面的示例中,单例bean (userManager)被注入了对HTTP会话范围的bean的引用(userPreferences)。这里的要点是userManager bean是单例的:它仅针对每个容器实例化一次,并且它的依赖项(在本例中只有一个,即userPreferences bean)也只注入一次。这意味着userManager bean只对完全相同的userPreferences对象(即它最初被注入的对象)进行操作。
This is not the behavior you want when injecting a shorter-lived scoped bean into a longer-lived scoped bean (for example, injecting an HTTP Session-scoped collaborating bean as a dependency into singleton bean). Rather, you need a single userManager object, and, for the lifetime of an HTTP Session, you need a userPreferences object that is specific to the HTTP Session. Thus, the container creates an object that exposes the exact same public interface as the UserPreferences class (ideally an object that is a UserPreferences instance), which can fetch the real UserPreferences object from the scoping mechanism (HTTP request, Session, and so forth). The container injects this proxy object into the userManager bean, which is unaware that this UserPreferences reference is a proxy. In this example, when a UserManager instance invokes a method on the dependency-injected UserPreferences object, it is actually invoking a method on the proxy. The proxy then fetches the real UserPreferences object from (in this case) the HTTP Session and delegates the method invocation onto the retrieved real UserPreferences object.
这不是您在将一个较短的作用域bean注入到一个较长的作用域bean时想要的行为(例如,将一个HTTP会话作用域的协作bean作为依赖项注入到单例bean中)。相反,您需要一个单一的userManager对象,并且对于HTTP会话的生存期,您需要一个特定于HTTP会话的userPreferences对象。因此,容器创建一个对象,该对象公开与UserPreferences类完全相同的公共接口(理想情况下是UserPreferences实例的对象),该对象可以从作用域机制(HTTP请求、会话,等等)获取真正的UserPreferences对象。容器将此代理对象注入userManager bean,该bean不知道此UserPreferences引用是代理。在本例中,当UserManager实例调用依赖注入的UserPreferences对象上的方法时,它实际上是在调用代理上的方法。然后代理从HTTP会话(在本例中)获取实际的UserPreferences对象,并将方法调用委托给检索到的实际UserPreferences对象。
Thus, you need the following (correct and complete) configuration when injecting request- and session-scoped beans into collaborating objects, as the following example shows:
因此,在将请求和会话范围的bean注入到协作对象中时,您需要以下(正确和完整的)配置,如下面的示例所示:
<bean id="userPreferences" class="com.something.UserPreferences" scope="session">
<aop:scoped-proxy/>
</bean>
<bean id="userManager" class="com.something.UserManager">
<property name="userPreferences" ref="userPreferences"/>
</bean>
Choosing the Type of Proxy to Create 选择代理创建的类型
By default, when the Spring container creates a proxy for a bean that is marked up with the “ element, a CGLIB-based class proxy is created.
默认情况下,当Spring容器为用aop:scoped-proxy/元素标记的bean创建代理时,将创建一个基于cglib的类代理。
CGLIB proxies intercept only public method calls! Do not call non-public methods on such a proxy. They are not delegated to the actual scoped target object.
CGLIB代理只拦截公共方法调用!不要在这样的代理上调用非公共方法。它们没有被委托给实际作用域的目标对象。
Alternatively, you can configure the Spring container to create standard JDK interface-based proxies for such scoped beans, by specifying false for the value of the proxy-target-class attribute of the “ element. Using JDK interface-based proxies means that you do not need additional libraries in your application classpath to affect such proxying. However, it also means that the class of the scoped bean must implement at least one interface and that all collaborators into which the scoped bean is injected must reference the bean through one of its interfaces. The following example shows a proxy based on an interface:
或者,您可以配置Spring容器,为这种作用域bean创建标准的基于JDK接口的代理,方法是为aop:作用域代理/元素的proxy-target-class属性的值指定false。使用基于JDK接口的代理意味着您不需要在应用程序类路径中添加其他库来影响这种代理。但是,这也意味着作用域bean的类必须实现至少一个接口,并且所有注入作用域bean的协作者必须通过它的一个接口引用bean。
<!-- DefaultUserPreferences implements the UserPreferences interface -->
<bean id="userPreferences" class="com.stuff.DefaultUserPreferences" scope="session">
<aop:scoped-proxy proxy-target-class="false"/>
</bean>
<bean id="userManager" class="com.stuff.UserManager">
<property name="userPreferences" ref="userPreferences"/>
</bean>
For more detailed information about choosing class-based or interface-based proxying, see [Proxying Mechanisms]
有关选择基于类或基于接口的代理的详细信息,请参阅代理机制
2.5.5 Custom Scopes 自定义作用域
The bean scoping mechanism is extensible. You can define your own scopes or even redefine existing scopes, although the latter is considered bad practice and you cannot override the built-in singleton and prototype scopes.
bean作用域机制是可扩展的。您可以定义自己的作用域,甚至可以重新定义现有的作用域,尽管后者被认为是不好的实践,并且您不能覆盖内置的单例和原型作用域。
Creating a Custom Scope 创建自定义作用域
To integrate your custom scopes into the Spring container, you need to implement the org.springframework.beans.factory.config.Scope interface, which is described in this section. For an idea of how to implement your own scopes, see the Scope implementations that are supplied with the Spring Framework itself and the Scope javadoc, which explains the methods you need to implement in more detail.
要将您的自定义范围集成到Spring容器中,您需要实现org.springframework.bean.factory.config.Scope接口,将在本节中描述。要了解如何实现您自己的作用域,请参阅Spring框架本身提供的作用域实现和作用域javadoc,这将更详细地解释您需要实现的方法。
The Scope interface has four methods to get objects from the scope, remove them from the scope, and let them be destroyed.
The session scope implementation, for example, returns the session-scoped bean (if it does not exist, the method returns a new instance of the bean, after having bound it to the session for future reference). The following method returns the object from the underlying scope:
作用域接口有四种方法来从作用域获取对象,从作用域删除对象,然后销毁对象。
例如,会话范围实现将返回会话范围的bean(如果该bean不存在,则该方法将在将其绑定到会话以供将来引用后返回该bean的新实例)。下面的方法从底层范围返回对象:
Object get(String name, ObjectFactory<?> objectFactory)
The session scope implementation, for example, removes the session-scoped bean from the underlying session. The object should be returned, but you can return null if the object with the specified name is not found. The following method removes the object from the underlying scope:
例如,会话范围实现从基础会话中删除会话范围的bean。应该返回该对象,但是如果没有找到具有指定名称的对象,则可以返回null。下面的方法将对象从底层范围中移除:
Object remove(String name)
The following method registers the callbacks the scope should execute when it is destroyed or when the specified object in the scope is destroyed:
以下方法注册当范围被销毁或范围内的指定对象被销毁时应该执行的回调:
void registerDestructionCallback(String name, Runnable destructionCallback)
See the javadoc or a Spring scope implementation for more information on destruction callbacks.
The following method obtains the conversation identifier for the underlying scope:
有关销毁回调的更多信息,请参阅javadoc或Spring作用域实现。
下面的方法获取底层作用域的对话标识符:
String getConversationId()
This identifier is different for each scope. For a session scoped implementation, this identifier can be the session identifier.
这个标识符对于每个范围都是不同的。对于会话范围的实现,此标识符可以是会话标识符。
Using a Custom Scope 使用自定义作用域
After you write and test one or more custom Scope implementations, you need to make the Spring container aware of your new scopes. The following method is the central method to register a new Scope with the Spring container:
在编写和测试一个或多个自定义范围实现之后,您需要让Spring容器知道您的新范围。下面的方法是向Spring容器注册新范围的中心方法:
void registerScope(String scopeName, Scope scope);
This method is declared on the ConfigurableBeanFactory interface, which is available through the BeanFactory property on most of the concrete ApplicationContext implementations that ship with Spring.
The first argument to the registerScope(..) method is the unique name associated with a scope. Examples of such names in the Spring container itself are singleton and prototype. The second argument to the registerScope(..) method is an actual instance of the custom Scope implementation that you wish to register and use.
Suppose that you write your custom Scope implementation, and then register it as shown in the next example.
此方法在ConfigurableBeanFactory接口上声明,该接口可通过Spring附带的大多数具体ApplicationContext实现上的BeanFactory属性获得。
registerScope(…)方法的第一个参数是与范围关联的惟一名称。Spring容器中此类名称的例子有singleton和prototype。registerScope(…)方法的第二个参数是您希望注册和使用的自定义范围实现的实际实例。
假设您编写了自定义范围实现,然后在下一个示例中注册它。
The next example uses SimpleThreadScope, which is included with Spring but is not registered by default. The instructions would be the same for your own custom Scope implementations.
下一个示例使用SimpleThreadScope,它包含在Spring中,但默认情况下不注册。对于您自己的自定义范围实现,指令将是相同的。
Scope threadScope = new SimpleThreadScope();
beanFactory.registerScope("thread", threadScope);
You can then create bean definitions that adhere to the scoping rules of your custom Scope, as follows:
然后,您可以创建遵循自定义作用域的作用域规则的bean定义,如下所示:
<bean id="..." class="..." scope="thread">
With a custom Scope implementation, you are not limited to programmatic registration of the scope. You can also do the Scope registration declaratively, by using the CustomScopeConfigurer class, as the following example shows:
使用自定义范围实现,您不局限于范围的程序性注册。您还可以通过使用CustomScopeConfigurer类声明性地进行范围注册,如下面的示例所示:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd">
<bean class="org.springframework.beans.factory.config.CustomScopeConfigurer">
<property name="scopes">
<map>
<entry key="thread">
<bean class="org.springframework.context.support.SimpleThreadScope"/>
</entry>
</map>
</property>
</bean>
<bean id="thing2" class="x.y.Thing2" scope="thread">
<property name="name" value="Rick"/>
<aop:scoped-proxy/>
</bean>
<bean id="thing1" class="x.y.Thing1">
<property name="thing2" ref="thing2"/>
</bean>
</beans>
When you place <aop:scoped-proxy/> in a FactoryBean implementation, it is the factory bean itself that is scoped, not the object returned from getObject().
在FactoryBean实现中放置aop:scoped-proxy/时,受作用域限制的是工厂bean本身,而不是从getObject()返回的对象。
2.7 Bean Definition Inheritance Bean定义继承
A bean definition can contain a lot of configuration information, including constructor arguments, property values, and container-specific information, such as the initialization method, a static factory method name, and so on. A child bean definition inherits configuration data from a parent definition. The child definition can override some values or add others as needed. Using parent and child bean definitions can save a lot of typing. Effectively, this is a form of templating.
bean定义可以包含很多配置信息,包括构造函数参数、属性值和特定于容器的信息,比如初始化方法、静态工厂方法名等等。子bean定义从父定义继承配置数据。子定义可以根据需要覆盖某些值或添加其他值。使用父bean和子bean定义可以节省大量输入。实际上,这是模板的一种形式。
If you work with an ApplicationContext interface programmatically, child bean definitions are represented by the ChildBeanDefinition class. Most users do not work with them on this level. Instead, they configure bean definitions declaratively in a class such as the ClassPathXmlApplicationContext. When you use XML-based configuration metadata, you can indicate a child bean definition by using the parent attribute, specifying the parent bean as the value of this attribute. The following example shows how to do so:
如果您以编程方式使用ApplicationContext接口,则子bean定义由ChildBeanDefinition类表示。大多数用户在这个级别上不使用它们。相反,它们在类(如ClassPathXmlApplicationContext)中声明式地配置bean定义。当您使用基于xml的配置元数据时,您可以通过使用父属性来指示子bean定义,并将父bean指定为该属性的值。下面的例子演示了如何做到这一点:
<bean id="inheritedTestBean" abstract="true" class="org.springframework.beans.TestBean">
<property name="name" value="parent"/>
<property name="age" value="1"/>
</bean>
<bean id="inheritsWithDifferentClass" class="org.springframework.beans.DerivedTestBean" parent="inheritedTestBean" init-method="initialize"> <!-- Note the parent attribute.-->
<property name="name" value="override"/>
<!-- the age property value of 1 will be inherited from parent -->
</bean>
A child bean definition uses the bean class from the parent definition if none is specified but can also override it. In the latter case, the child bean class must be compatible with the parent (that is, it must accept the parent’s property values).
如果没有指定任何bean,则子bean定义使用来自父定义的bean类,但也可以覆盖它。在后一种情况下,子bean类必须与父类兼容(也就是说,它必须接受父类的属性值)。
A child bean definition inherits scope, constructor argument values, property values, and method overrides from the parent, with the option to add new values. Any scope, initialization method, destroy method, or static factory method settings that you specify override the corresponding parent settings.
子bean定义继承父bean的作用域、构造函数参数值、属性值和方法覆盖,并具有添加新值的选项。您指定的任何范围、初始化方法、销毁方法或静态工厂方法设置都将覆盖相应的父设置。
The remaining settings are always taken from the child definition: depends on, autowire mode, dependency check, singleton, and lazy init.
其余的设置总是取自子定义:依赖、自动装配模式、依赖项检查、单例和惰性初始化。
The preceding example explicitly marks the parent bean definition as abstract by using the abstract attribute. If the parent definition does not specify a class, explicitly marking the parent bean definition as abstract is required, as the following example shows:
前面的示例通过使用抽象属性显式地将父bean定义标记为抽象。如果父定义没有指定类,则需要显式地将父bean定义标记为抽象,如下面的示例所示:
<bean id="inheritedTestBeanWithoutClass" abstract="true">
<property name="name" value="parent"/>
<property name="age" value="1"/>
</bean>
<bean id="inheritsWithClass" class="org.springframework.beans.DerivedTestBean" parent="inheritedTestBeanWithoutClass" init-method="initialize">
<property name="name" value="override"/>
<!-- age will inherit the value of 1 from the parent bean definition-->
</bean>
我自己的例子:
@NoArgsConstructor
@AllArgsConstructor
@Data
public class ParentClass {
private String name;
private int age;
}
public class SonClass extends ParentClass {
}
<bean id="parentClass" class="com.leishida.spring.ParentClass">
<property name="name" value="parent"/>
<property name="age" value="35"/>
</bean>
<bean id="sonClass" class="com.leishida.spring.SonClass" parent="parentClass">
<property name="name" value="override"/>
</bean>
@org.junit.Test
public void test10(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object son = context.getBean("sonClass");
System.out.println(son);
// ParentClass(name=override, age=35)
}
可以通过parent来继承父Bean的属性,同时也支持重写,如果父Bean没有具体指定类,需要加abstract,子类Bean继承父Bean时使用parent标签说明
The parent bean cannot be instantiated on its own because it is incomplete, and it is also explicitly marked as abstract. When a definition is abstract, it is usable only as a pure template bean definition that serves as a parent definition for child definitions. Trying to use such an abstract parent bean on its own, by referring to it as a ref property of another bean or doing an explicit getBean() call with the parent bean ID returns an error. Similarly, the container’s internal preInstantiateSingletons() method ignores bean definitions that are defined as abstract.
父bean不能单独实例化,因为它是不完整的,而且它也被显式地标记为抽象的。当定义是抽象的时,它只能作为作为子定义的父定义的纯模板bean定义使用。尝试单独使用这样一个抽象的父bean,方法是将它引用为另一个bean的ref属性,或者使用父bean ID执行显式的getBean()调用,这会返回一个错误。类似地,容器的内部preInstantiateSingletons()方法忽略定义为抽象的bean定义。
我们现在给刚才的父Bean加上”abstract=true”试试实例化父bean
@org.junit.Test
public void test10(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Object son = context.getBean("sonClass");
System.out.println(son);
// ParentClass(name=override, age=35)
Object parent = context.getBean("parentClass");
System.out.println(parent); //org.springframework.beans.factory.BeanIsAbstractException:
}
ApplicationContext pre-instantiates all singletons by default. Therefore, it is important (at least for singleton beans) that if you have a (parent) bean definition which you intend to use only as a template, and this definition specifies a class, you must make sure to set the abstract attribute to true, otherwise the application context will actually (attempt to) pre-instantiate the abstract bean.
默认情况下,ApplicationContext会预先实例化所有的单例对象。因此,它是重要的(至少对单例bean),如果你有一个(父)bean定义你只打算使用作为模板,这个定义指定了一个类,您必须确保设置抽象属性为true,否则应用程序上下文会(试图)pre-instantiate抽象的bean。
2.8 Container Extension Points 容器扩展点
Typically, an application developer does not need to subclass ApplicationContext implementation classes. Instead, the Spring IoC container can be extended by plugging in implementations of special integration interfaces. The next few sections describe these integration interfaces.
通常,应用程序开发人员不需要继承ApplicationContext实现类。相反,可以通过插入特殊集成接口的实现来扩展Spring IoC容器。接下来的几节将描述这些集成接口。
2.8.1 Customizing Beans by Using a BeanPostProcessor(后置处理器) 通过BeanPostProcessor自定义Bean
The BeanPostProcessor interface defines callback methods that you can implement to provide your own (or override the container’s default) instantiation logic, dependency resolution logic, and so forth. If you want to implement some custom logic after the Spring container finishes instantiating, configuring, and initializing a bean, you can plug in one or more custom BeanPostProcessor implementations.
BeanPostProcessor接口定义了回调方法,您可以实现这些回调方法来提供您自己的(或覆盖容器的默认)实例化逻辑、依赖项解析逻辑等等。如果希望在Spring容器完成实例化、配置和初始化bean之后实现一些自定义逻辑,可以插入一个或多个自定义BeanPostProcessor实现。
You can configure multiple BeanPostProcessor instances, and you can control the order in which these BeanPostProcessor instances execute by setting the order property. You can set this property only if the BeanPostProcessor implements the Ordered interface. If you write your own BeanPostProcessor, you should consider implementing the Ordered interface, too. For further details, see the javadoc of the BeanPostProcessor and Ordered interfaces. See also the note on programmatic registration of BeanPostProcessor instances.
您可以配置多个BeanPostProcessor实例,并且可以通过设置order属性来控制这些BeanPostProcessor实例的执行顺序。只有在BeanPostProcessor实现有序接口时才能设置此属性。如果您编写自己的BeanPostProcessor,您也应该考虑实现有序接口。有关详细信息,请参见BeanPostProcessor和有序接口的javadoc。请参阅关于BeanPostProcessor实例的程序性注册的说明。
BeanPostProcessor instances operate on bean (or object) instances. That is, the Spring IoC container instantiates a bean instance and then BeanPostProcessor instances do their work.
BeanPostProcessor instances are scoped per-container. This is relevant only if you use container hierarchies. If you define a BeanPostProcessor in one container, it post-processes only the beans in that container. In other words, beans that are defined in one container are not post-processed by a BeanPostProcessor defined in another container, even if both containers are part of the same hierarchy.
To change the actual bean definition (that is, the blueprint that defines the bean), you instead need to use a BeanFactoryPostProcessor, as described in Customizing Configuration Metadata with a BeanFactoryPostProcessor.
BeanPostProcessor实例操作bean(或对象)实例。也就是说,Spring IoC容器实例化一个bean实例,然后BeanPostProcessor实例执行它们的工作。
BeanPostProcessor实例的作用域是每个容器。这仅在使用容器层次结构时才相关。如果您在一个容器中定义一个BeanPostProcessor,那么它只对该容器中的bean进行后处理。换句话说,在一个容器中定义的bean不会由在另一个容器中定义的BeanPostProcessor进行后处理,即使两个容器都是相同层次结构的一部分。
要更改实际的bean定义(即定义bean的蓝图),您需要使用BeanFactoryPostProcessor,如用BeanFactoryPostProcessor自定义配置元数据中所述。
The org.springframework.beans.factory.config.BeanPostProcessor interface consists of exactly two callback methods. When such a class is registered as a post-processor with the container, for each bean instance that is created by the container, the post-processor gets a callback from the container both before container initialization methods (such as InitializingBean.afterPropertiesSet() or any declared init method) are called, and after any bean initialization callbacks. The post-processor can take any action with the bean instance, including ignoring the callback completely. A bean post-processor typically checks for callback interfaces, or it may wrap a bean with a proxy. Some Spring AOP infrastructure classes are implemented as bean post-processors in order to provide proxy-wrapping logic.
org.springframework.beans.factory.config.BeanPostProcessor接口正好由两个回调方法组成。当这样一个类注册为post-processor的容器,每个容器创建bean实例,后处理器从容器之前得到一个回调容器初始化方法(如InitializingBean.afterPropertiesSet()或任何宣布init方法),任何bean初始化后回调。后处理器可以对bean实例采取任何操作,包括完全忽略回调。bean后处理器通常检查回调接口,或者使用代理包装bean。为了提供代理包装逻辑,一些Spring AOP基础设施类被实现为bean后处理器。
An ApplicationContext automatically detects any beans that are defined in the configuration metadata that implements the BeanPostProcessor interface. The ApplicationContext registers these beans as post-processors so that they can be called later, upon bean creation. Bean post-processors can be deployed in the container in the same fashion as any other beans.
ApplicationContext自动检测在实现BeanPostProcessor接口的配置元数据中定义的任何bean。ApplicationContext将这些bean注册为后处理器,以便以后在创建bean时调用它们。Bean后置处理器可以与任何其他Bean以相同的方式部署在容器中。
Note that, when declaring a BeanPostProcessor by using an @Bean factory method on a configuration class, the return type of the factory method should be the implementation class itself or at least the org.springframework.beans.factory.config.BeanPostProcessor interface, clearly indicating the post-processor nature of that bean. Otherwise, the ApplicationContext cannot autodetect it by type before fully creating it. Since a BeanPostProcessor needs to be instantiated early in order to apply to the initialization of other beans in the context, this early type detection is critical.
注意,当在配置类上使用@Bean工厂方法声明BeanPostProcessor时,工厂方法的返回类型应该是实现类本身,或者至少是org.springframework.bean .factory.config.BeanPostProcessor接口,清楚地指示该bean的后处理器特性。否则,ApplicationContext不能在完全创建它之前通过类型自动检测它。由于为了应用于context中其他bean的初始化,需要尽早实例化BeanPostProcessor,所以这种早期类型检测非常重要。
Programmatically registering BeanPostProcessor instances
While the recommended approach for BeanPostProcessor registration is through ApplicationContext auto-detection (as described earlier), you can register them programmatically against a ConfigurableBeanFactory by using the addBeanPostProcessor method. This can be useful when you need to evaluate conditional logic before registration or even for copying bean post processors across contexts in a hierarchy. Note, however, that BeanPostProcessor instances added programmatically do not respect the Ordered interface. Here, it is the order of registration that dictates the order of execution. Note also that BeanPostProcessor instances registered programmatically are always processed before those registered through auto-detection, regardless of any explicit ordering.
以编程方式注册BeanPostProcessor实例
虽然推荐的BeanPostProcessor注册方法是通过ApplicationContext自动检测(如前所述),但是您可以通过使用addBeanPostProcessor方法以编程方式针对ConfigurableBeanFactory注册它们。当您需要在注册之前计算条件逻辑,甚至在层次结构的context中复制bean post处理器时,这可能很有用。但是,请注意,以编程方式添加的BeanPostProcessor实例并不遵循有序接口。在这里,注册的顺序决定了执行的顺序。还要注意,以编程方式注册的BeanPostProcessor实例总是在通过自动检测注册的实例之前处理,而不考虑任何显式的顺序。
BeanPostProcessor instances and AOP auto-proxying
Classes that implement the BeanPostProcessor interface are special and are treated differently by the container. All BeanPostProcessor instances and beans that they directly reference are instantiated on startup, as part of the special startup phase of the ApplicationContext. Next, all BeanPostProcessor instances are registered in a sorted fashion and applied to all further beans in the container. Because AOP auto-proxying is implemented as a BeanPostProcessor itself, neither BeanPostProcessor instances nor the beans they directly reference are eligible for auto-proxying and, thus, do not have aspects woven into them.
For any such bean, you should see an informational log message: Bean someBean is not eligible for getting processed by all BeanPostProcessor interfaces (for example: not eligible for auto-proxying).
If you have beans wired into your BeanPostProcessor by using autowiring or @Resource (which may fall back to autowiring), Spring might access unexpected beans when searching for type-matching dependency candidates and, therefore, make them ineligible for auto-proxying or other kinds of bean post-processing. For example, if you have a dependency annotated with @Resource where the field or setter name does not directly correspond to the declared name of a bean and no name attribute is used, Spring accesses other beans for matching them by type.
BeanPostProcessor实例和AOP自动代理
实现BeanPostProcessor接口的类是特殊的,容器以不同的方式对待它们。它们直接引用的所有BeanPostProcessor实例和bean在启动时实例化,作为ApplicationContext的特殊启动阶段的一部分。接下来,以排序的方式注册所有BeanPostProcessor实例,并将其应用于容器中所有后续的bean。因为AOP自动代理是作为一个BeanPostProcessor本身来实现的,所以无论是BeanPostProcessor实例还是它们直接引用的bean都不适合自动代理,因此,没有将方面编织到它们之中。
对于任何这样的bean,您应该看到一条信息日志消息:bean someBean不适合被所有BeanPostProcessor接口处理(例如:不适合自动代理)。
如果通过使用autowiring或@Resource(可能会回到autowiring)将bean连接到BeanPostProcessor中,Spring可能会在搜索类型匹配依赖项候选项时访问意外的bean,因此,使它们不适合自动代理或其他类型的bean后处理。例如,如果您有一个带有@Resource注释的依赖项,其中字段或setter名称与bean的声明名称不直接对应,并且没有使用name属性,那么Spring将访问其他bean,以便根据类型匹配它们。
Example: Hello World, BeanPostProcessor-style
This first example illustrates basic usage. The example shows a custom BeanPostProcessor implementation that invokes the toString() method of each bean as it is created by the container and prints the resulting string to the system console.
第一个例子演示了基本用法。该示例显示了一个自定义BeanPostProcessor实现,该实现在容器创建每个bean时调用toString()方法,并将结果字符串打印到系统控制台。
The following listing shows the custom BeanPostProcessor implementation class definition:
下面的清单显示了自定义BeanPostProcessor实现类定义:
package scripting;
import org.springframework.beans.factory.config.BeanPostProcessor;
public class InstantiationTracingBeanPostProcessor implements BeanPostProcessor {
// simply return the instantiated bean as-is
public Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean; // we could potentially return any object reference here...
}
public Object postProcessAfterInitialization(Object bean, String beanName) {
System.out.println("Bean '" + beanName + "' created : " + bean.toString());
return bean;
}
}
The following beans element uses the InstantiationTracingBeanPostProcessor:
下面的bean元素使用了InstantiationTracingBeanPostProcessor:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:lang="http://www.springframework.org/schema/lang" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/lang https://www.springframework.org/schema/lang/spring-lang.xsd">
<lang:groovy id="messenger" script-source="classpath:org/springframework/scripting/groovy/Messenger.groovy">
<lang:property name="message" value="Fiona Apple Is Just So Dreamy."/>
</lang:groovy>
<!-- when the above bean (messenger) is instantiated, this custom BeanPostProcessor implementation will output the fact to the system console 在实例化上述bean (messenger)时,执行此自定义 BeanPostProcessor实现将把事实输出到系统控制台 -->
<bean class="scripting.InstantiationTracingBeanPostProcessor"/>
</beans>
Notice how the InstantiationTracingBeanPostProcessor is merely defined. It does not even have a name, and, because it is a bean, it can be dependency-injected as you would any other bean. (The preceding configuration also defines a bean that is backed by a Groovy script. The Spring dynamic language support is detailed in the chapter entitled Dynamic Language Support.)
注意,InstantiationTracingBeanPostProcessor是如何定义的。它甚至没有名称,因为它是一个bean,所以可以像其他bean一样依赖注入。(前面的配置还定义了一个由Groovy脚本支持的bean。有关Spring动态语言支持的详细信息,请参阅“动态语言支持”一章。
因为对动态语言groovy不懂,所以上面的配置不是很明白
The following Java application runs the preceding code and configuration:
以下Java应用程序运行上述代码和配置:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.scripting.Messenger;
public final class Boot {
public static void main(final String[] args) throws Exception {
ApplicationContext ctx = new ClassPathXmlApplicationContext("scripting/beans.xml");
Messenger messenger = ctx.getBean("messenger", Messenger.class);
System.out.println(messenger);
}
/** Bean 'messenger' created : org.springframework.scripting.groovy.GroovyMessenger@272961 org.springframework.scripting.groovy.GroovyMessenger@272961 */
}
这里我又用传统方式实现了一下这个功能,这个方法就是在对象创建好返回之前对Bean进行的一些操作,AOP就是基于此:
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
public class PostProcessor implements BeanPostProcessor {
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("Bean '" + beanName + "' created : " + bean.toString());
return bean;
}
}
定义了一个实体类:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Message {
private String name;
}
XML配置:
<bean class="com.leishida.spring3.PostProcessor"/>
<bean id="message" class="com.leishida.spring3.Message">
<property name="name" value="Bean:message"/>
</bean>
测试:
@org.junit.Test
public void test(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext2.xml");
Object message = context.getBean("message");
System.out.println(message);
/** * Bean 'message' created : Message(name=Bean:message) * Message(name=Bean:message) */
}
Example: The RequiredAnnotationBeanPostProcessor
Using callback interfaces or annotations in conjunction with a custom BeanPostProcessor implementation is a common means of extending the Spring IoC container. An example is Spring’s RequiredAnnotationBeanPostProcessor — a BeanPostProcessor implementation that ships with the Spring distribution and that ensures that JavaBean properties on beans that are marked with an (arbitrary) annotation are actually (configured to be) dependency-injected with a value.
将回调接口或注释与自定义BeanPostProcessor实现结合使用是扩展Spring IoC容器的常见方法。一个例子是Spring的RequiredAnnotationBeanPostProcessor——这是一个随Spring发行版一起发布的BeanPostProcessor实现,它确保使用(任意)注释标记的bean上的JavaBean属性实际上(配置为)被注入了一个值。
2.8.2 Customizing Configuration Metadata with a BeanFactoryPostProcessor使用BeanFactoryPostProcessor自定义配置元数据
The next extension point that we look at is the org.springframework.beans.factory.config.BeanFactoryPostProcessor. The semantics of this interface are similar to those of the BeanPostProcessor, with one major difference: BeanFactoryPostProcessor operates on the bean configuration metadata. That is, the Spring IoC container lets a BeanFactoryPostProcessor read the configuration metadata and potentially change it before the container instantiates any beans other than BeanFactoryPostProcessor instances.
我们查看的下一个扩展点是org.springframe .bean .factory.config. beanfactorypostprocessor。此接口的语义与BeanPostProcessor的语义相似,但有一个主要区别:BeanFactoryPostProcessor操作bean配置元数据。也就是说,Spring IoC容器允许BeanFactoryPostProcessor读取配置元数据,并可能在容器实例化除BeanFactoryPostProcessor实例之外的任何bean之前更改它。
You can configure multiple BeanFactoryPostProcessor instances, and you can control the order in which these BeanFactoryPostProcessor instances run by setting the order property. However, you can only set this property if the BeanFactoryPostProcessor implements the Ordered interface. If you write your own BeanFactoryPostProcessor, you should consider implementing the Ordered interface, too. See the javadoc of the [BeanFactoryPostProcessor]and [Ordered] interfaces for more details.
您可以配置多个BeanFactoryPostProcessor实例,并且可以通过设置order属性来控制这些BeanFactoryPostProcessor实例的运行顺序。但是,只有在BeanFactoryPostProcessor实现order接口时才能设置此属性。如果您编写自己的BeanFactoryPostProcessor,您也应该考虑实现order接口。有关更多细节,请参见BeanFactoryPostProcessor和有序接口的javadoc。
If you want to change the actual bean instances (that is, the objects that are created from the configuration metadata), then you instead need to use a BeanPostProcessor (described earlier in Customizing Beans by Using a BeanPostProcessor). While it is technically possible to work with bean instances within a BeanFactoryPostProcessor (for example, by using BeanFactory.getBean()), doing so causes premature bean instantiation, violating the standard container lifecycle. This may cause negative side effects, such as bypassing bean post processing.Also, BeanFactoryPostProcessor instances are scoped per-container. This is only relevant if you use container hierarchies. If you define a BeanFactoryPostProcessor in one container, it is applied only to the bean definitions in that container. Bean definitions in one container are not post-processed by BeanFactoryPostProcessor instances in another container, even if both containers are part of the same hierarchy.
如果您想要更改实际的bean实例(即,从配置元数据创建的对象),那么您需要使用BeanPostProcessor(在前面通过使用BeanPostProcessor定制bean中描述过)。虽然在BeanFactoryPostProcessor中使用bean实例在技术上是可行的(例如,通过使用BeanFactory.getBean()),这样做会导致过早的bean实例化,违反标准容器生命周期。这可能会导致负面的副作用,比如绕过bean的后处理。
另外,BeanFactoryPostProcessor实例的作用域是每个容器。这仅在使用容器层次结构时才相关。如果您在一个容器中定义一个BeanFactoryPostProcessor,那么它只应用于该容器中的bean定义。一个容器中的Bean定义不会由另一个容器中的BeanFactoryPostProcessor实例进行后处理,即使两个容器都是相同层次结构的一部分。
A bean factory post-processor is automatically executed when it is declared inside an ApplicationContext, in order to apply changes to the configuration metadata that define the container. Spring includes a number of predefined bean factory post-processors, such as PropertyOverrideConfigurer and PropertySourcesPlaceholderConfigurer. You can also use a custom BeanFactoryPostProcessor — for example, to register custom property editors.
当在ApplicationContext中声明bean工厂后处理器时,它将自动执行,以便将更改应用于定义容器的配置元数据。Spring包含许多预定义的bean工厂后处理程序,如PropertyOverrideConfigurer和PropertySourcesPlaceholderConfigurer。您还可以使用自定义BeanFactoryPostProcessor:例如,注册自定义属性编辑器。
An ApplicationContext automatically detects any beans that are deployed into it that implement the BeanFactoryPostProcessor interface. It uses these beans as bean factory post-processors, at the appropriate time. You can deploy these post-processor beans as you would any other bean.
ApplicationContext自动检测部署到其中的实现BeanFactoryPostProcessor接口的任何bean。它在适当的时候使用这些bean作为bean factory的后处理器。您可以像部署任何其他bean一样部署这些后处理器bean。
As with BeanPostProcessors , you typically do not want to configure BeanFactoryPostProcessors for lazy initialization. If no other bean references a Bean(Factory)PostProcessor, that post-processor will not get instantiated at all. Thus, marking it for lazy initialization will be ignored, and the Bean(Factory)PostProcessor will be instantiated eagerly even if you set the default-lazy-init attribute to true on the declaration of your <beans/> element.
与beanpostprocessor一样,您通常不希望将beanfactorypostprocessor配置为延迟初始化。如果没有其他bean引用bean(工厂)后处理器,则根本不会实例化后处理器。因此,将其标记为延迟初始化将被忽略,即使您在元素的声明中将default-lazy-init属性设置为true, Bean(工厂)后处理器也将被急切地实例化。
Example: The Class Name Substitution PropertySourcesPlaceholderConfigurer 例如:类名替换PropertySourcesPlaceholderConfigurer
You can use the PropertySourcesPlaceholderConfigurer to externalize property values from a bean definition in a separate file by using the standard Java Properties format. Doing so enables the person deploying an application to customize environment-specific properties, such as database URLs and passwords, without the complexity or risk of modifying the main XML definition file or files for the container.
通过使用标准的Java属性格式,您可以使用PropertySourcesPlaceholderConfigurer将属性值从bean定义外部化到一个单独的文件中。这样做使部署应用程序的人员能够自定义特定于环境的属性,如数据库url和密码,而不需要修改主XML定义文件或容器文件的复杂性或风险。
Consider the following XML-based configuration metadata fragment, where a DataSource with placeholder values is defined:
考虑以下基于xml的配置元数据片段,其中定义了一个具有占位符值的数据源:
<bean class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer">
<property name="locations" value="classpath:com/something/jdbc.properties"/>
</bean>
<bean id="dataSource" destroy-method="close" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="${jdbc.driverClassName}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
The example shows properties configured from an external Properties file. At runtime, a PropertySourcesPlaceholderConfigurer is applied to the metadata that replaces some properties of the DataSource. The values to replace are specified as placeholders of the form ${property-name}, which follows the Ant and log4j and JSP EL style.
该示例显示了从外部属性文件配置的属性。在运行时,PropertySourcesPlaceholderConfigurer应用于替换数据源的某些属性的元数据。要替换的值被指定为表单${property-name}的占位符,它遵循Ant和log4j以及JSP EL样式。
The actual values come from another file in the standard Java Properties format:
实际值来自另一个标准Java属性格式的文件:
jdbc.driverClassName=org.hsqldb.jdbcDriver
jdbc.url=jdbc:hsqldb:hsql://production:9002
jdbc.username=sa
jdbc.password=root
Therefore, the ${jdbc.username} string is replaced at runtime with the value, ‘sa’, and the same applies for other placeholder values that match keys in the properties file. The PropertySourcesPlaceholderConfigurer checks for placeholders in most properties and attributes of a bean definition. Furthermore, you can customize the placeholder prefix and suffix.
因此,$ {jdbc。用户名}字符串在运行时被替换为值’sa’,相同的情况也适用于其他与属性文件中的键匹配的占位符值。PropertySourcesPlaceholderConfigurer检查bean定义的大多数属性和属性中的占位符。此外,您还可以自定义占位符前缀和后缀。
With the context namespace introduced in Spring 2.5, you can configure property placeholders with a dedicated configuration element. You can provide one or more locations as a comma-separated list in the location attribute, as the following example shows:
通过Spring 2.5中引入的context命名空间,您可以使用专用的配置元素来配置属性占位符。您可以在location属性中以逗号分隔的列表的形式提供一个或多个位置,如下面的示例所示:
<context:property-placeholder location="classpath:com/something/jdbc.properties"/>
The PropertySourcesPlaceholderConfigurer not only looks for properties in the Properties file you specify. By default, if it cannot find a property in the specified properties files, it checks against Spring Environment properties and regular Java System properties.
PropertySourcesPlaceholderConfigurer不仅在您指定的属性文件中查找属性。默认情况下,如果在指定的属性文件中找不到属性,它会检查Spring环境属性和常规Java系统属性。
You can use the PropertySourcesPlaceholderConfigurer to substitute class names, which is sometimes useful when you have to pick a particular implementation class at runtime. The following example shows how to do so:
您可以使用PropertySourcesPlaceholderConfigurer来替换类名,这在您必须在运行时选择特定的实现类时非常有用。下面的例子演示了如何做到这一点:
<bean class="org.springframework.beans.factory.config.PropertySourcesPlaceholderConfigurer">
<property name="locations">
<value>classpath:com/something/strategy.properties</value>
</property>
<property name="properties">
<value>custom.strategy.class=com.something.DefaultStrategy</value>
</property>
</bean>
<bean id="serviceStrategy" class="${custom.strategy.class}"/>
If the class cannot be resolved at runtime to a valid class, resolution of the bean fails when it is about to be created, which is during the preInstantiateSingletons() phase of an ApplicationContext for a non-lazy-init bean.
如果在运行时不能将类解析为有效的类,则在即将创建bean时,也就是在非lazy-init bean的ApplicationContext的
preInstantiateSingletons()阶段,bean的解析将失败。
Example: The PropertyOverrideConfigurer 属性重写配置
The PropertyOverrideConfigurer, another bean factory post-processor, resembles the PropertySourcesPlaceholderConfigurer, but unlike the latter, the original definitions can have default values or no values at all for bean properties. If an overriding Properties file does not have an entry for a certain bean property, the default context definition is used.
Note that the bean definition is not aware of being overridden, so it is not immediately obvious from the XML definition file that the override configurer is being used. In case of multiple PropertyOverrideConfigurer instances that define different values for the same bean property, the last one wins, due to the overriding mechanism.
另一个bean工厂后处理器PropertyOverrideConfigurer类似于PropertySourcesPlaceholderConfigurer,但与后者不同,原始定义可以有缺省值,也可以没有bean属性的值。如果覆盖的属性文件没有某个bean属性的条目,则使用默认的context定义。
注意,bean定义不知道被覆盖,所以从XML定义文件中不能立即看出使用了覆盖配置程序。如果有多个PropertyOverrideConfigurer实例为同一个bean属性定义不同的值,由于覆盖机制,最后一个实例胜出。
Properties file configuration lines take the following format:
属性文件配置行采用以下格式:
beanName.property=value
The following listing shows an example of the format:
下面的清单显示了该格式的一个示例:
dataSource.driverClassName=com.mysql.jdbc.Driver
dataSource.url=jdbc:mysql:mydb
This example file can be used with a container definition that contains a bean called dataSource that has driver and url properties.
此示例文件可与容器定义一起使用,容器定义包含一个名为dataSource的bean,该bean具有驱动程序和url属性。
Compound property names are also supported, as long as every component of the path except the final property being overridden is already non-null (presumably initialized by the constructors). In the following example, the sammy property of the bob property of the fred property of the tom bean is set to the scalar value 123:
也支持复合属性名,只要路径的每个组件(被覆盖的最后一个属性除外)都是非空的(可能是由构造函数初始化的)。在下面的例子中,tom bean的fred属性的bob属性的sammy属性被设置为标量值123:
tom.fred.bob.sammy=123
Specified override values are always literal values. They are not translated into bean references. This convention also applies when the original value in the XML bean definition specifies a bean reference.
指定的重写值总是文字值。它们不会被转换成bean引用。当XML bean定义中的原始值指定一个bean引用时,也适用这种约定。
With the context namespace introduced in Spring 2.5, it is possible to configure property overriding with a dedicated configuration element, as the following example shows:
通过在Spring 2.5中引入上下文命名空间,可以使用专用的配置元素配置属性覆盖,如下面的示例所示:
<context:property-override location="classpath:override.properties"/>
2.8.3 Customizing Instantiation Logic with a FactoryBean 使用FactoryBean自定义实例化逻辑
You can implement the org.springframework.beans.factory.FactoryBean interface for objects that are themselves factories.
The FactoryBean interface is a point of pluggability into the Spring IoC container’s instantiation logic. If you have complex initialization code that is better expressed in Java as opposed to a (potentially) verbose amount of XML, you can create your own FactoryBean, write the complex initialization inside that class, and then plug your custom FactoryBean into the container.
您可以实现org.springframe .bean .factory.FactoryBean接口用于本身就是工厂的对象。
FactoryBean接口是一个可插入Spring IoC容器实例化逻辑的点。如果您有复杂的初始化代码,用Java表示比(可能的)冗长的XML更好,那么您可以创建自己的FactoryBean,在该类中编写复杂的初始化,然后将定制的FactoryBean插入容器中。
The FactoryBean interface provides three methods:
Object getObject(): Returns an instance of the object this factory creates. The instance can possibly be shared, depending on whether this factory returns singletons or prototypes.boolean isSingleton(): Returnstrueif thisFactoryBeanreturns singletons orfalseotherwise.Class getObjectType(): Returns the object type returned by thegetObject()method ornullif the type is not known in advance.
FactoryBean接口提供了三种方法:
Object getObject(): 返回工厂创建的对象的实例。实例可以共享,这取决于这个工厂返回的是单例还是原型boolean isSingleton():如果这个FactoryBean返回单例,则返回true,否则返回false。Class getObjectType(): 返回getObject()方法返回的对象类型,如果类型事先不知道,则返回null。
The FactoryBean concept and interface is used in a number of places within the Spring Framework. More than 50 implementations of the FactoryBean interface ship with Spring itself.
When you need to ask a container for an actual FactoryBean instance itself instead of the bean it produces, preface the bean’s id with the ampersand symbol (&) when calling the getBean() method of the ApplicationContext. So, for a given FactoryBean with an id of myBean, invoking getBean("myBean") on the container returns the product of the FactoryBean, whereas invoking getBean("&myBean") returns the FactoryBean instance itself.
FactoryBean的概念和接口在Spring框架的许多地方都有使用。FactoryBean接口的50多个实现都附带了Spring本身。
当您需要向容器请求实际的FactoryBean实例本身而不是它所生成的bean时,在调用ApplicationContext的getBean()方法时,在bean的id前面加上与符号(&)。因此,对于id为myBean的给定FactoryBean,在容器上调用getBean(“myBean”)将返回FactoryBean的产品,而调用getBean(“&myBean”)将返回FactoryBean实例本身。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179883.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
