大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
首先使用训练数据训练模型,然后使用交叉验证数据挑选最佳模型,最后使用测试数据测试模型是否完好。
下面举一个训练逻辑回归模型的例子。
假设有四个模型,第一个是一次模型,然后二次,三次,四次模型。我们使用训练数据训练,并算出多项式的斜率和系数等等。
然后使用交叉验证数据计算所有这些模型的F1分数,然后选择F1得分最高的模型,最后使用测试数据确保模型效果完好。
算法的参数就是多项式的系数,但是多项式的系数就像物性参数,我们称之为超参数(Hyper-parameters)。
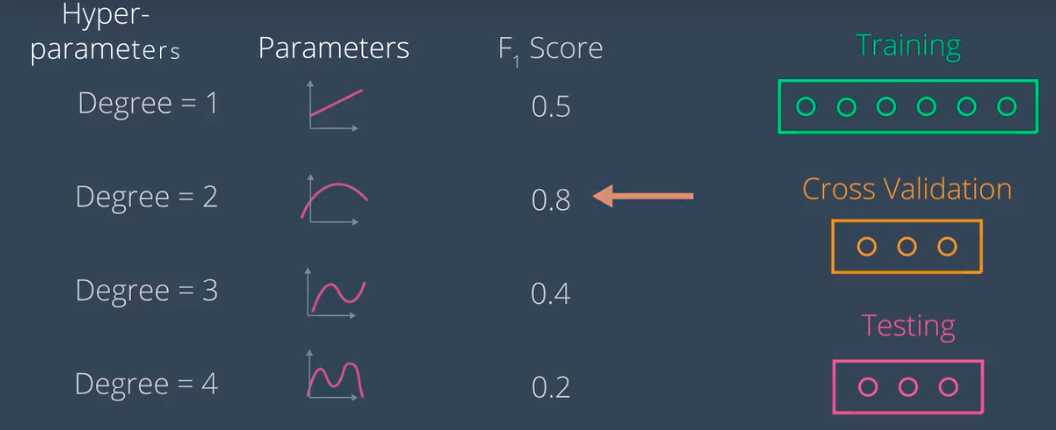

假如我们要训练决策树,此时的超参数为深度,假设深度为1,2,3,4.
参数是树叶和节点等的阈值。
训练-验证-测试.
过程如上。
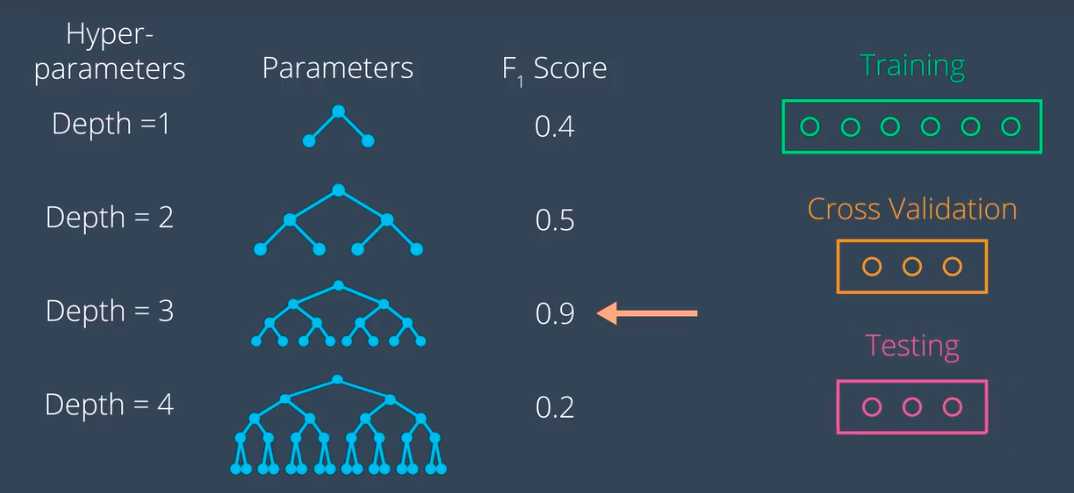

当有多个超参数时。
for example: SVM。
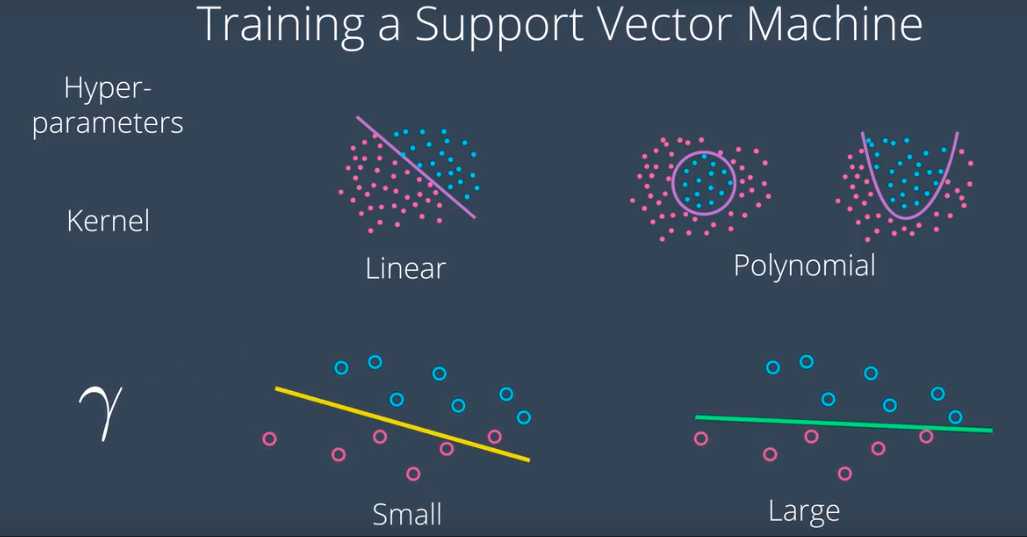
如何选择最佳内核(kernel)和伽马(gamma)组合。
我们使用网格搜索法:即制作一个表格,并列出所有可能的组合,选择最佳组合。
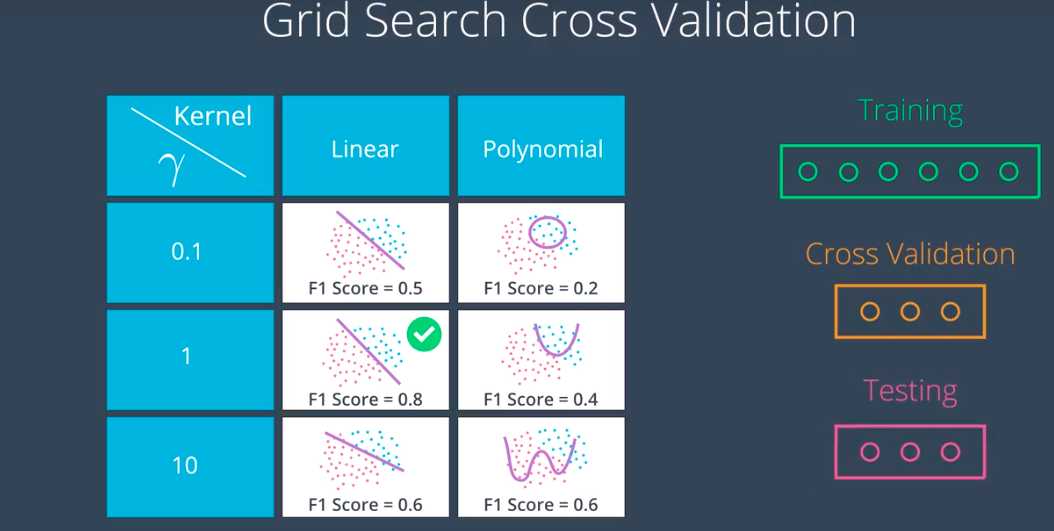
在 sklearn 中的网格搜索
在 sklearn 中的网格搜索非常简单。 我们将用一个例子来说明一下。 假设我们想要训练支持向量机,并且我们想在以下参数之间做出决定:
- kernel:
poly或rbf。 - C:0.1,1 或 10。
具体步骤如下所示:
1. 导入 GridSearchCV
from sklearn.model_selection import GridSearchCV
2.选择参数:
现在我们来选择我们想要选择的参数,并形成一个字典。 在这本字典中,键 (keys) 将是参数的名称,值 (values) 将是每个参数可能值的列表。
parameters = {'kernel':['poly', 'rbf'],'C':[0.1, 1, 10]}
3.创建一个评分机制 (scorer)
我们需要确认将使用什么指标来为每个候选模型评分。 这里,我们将使用 F1 分数。
from sklearn.metrics import make_scorer
from sklearn.metrics import f1_score
scorer = make_scorer(f1_score)4. 使用参数 (parameter) 和评分机制 (scorer) 创建一个 GridSearch 对象。 使用此对象与数据保持一致 (fit the data) 。
# Create the object.
grid_obj = GridSearchCV(clf, parameters, scoring=scorer)
# Fit the data
grid_fit = grid_obj.fit(X, y)5. 获得最佳估算器 (estimator)
best_clf = grid_fit.best_estimator_
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179714.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...