大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
1.skiplist简介
Skiplist是一个用于有序元素序列快速搜索的数据结构,由美国计算机科学家William Pugh发明于1989年。他在论文《Skip lists: a probabilistic alternative to balanced trees》中详细介绍了跳表的数据结构和插入删除等操作。论文是这么介绍跳表的:
- Skip lists are a data structure that can be used in place of balanced trees.
- Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
也就是说,Skip list是一个“概率型”的数据结构,可以在很多应用场景中替代平衡树。Skip list算法与平衡树相比,有相似的渐进期望时间边界,但是它更简单,更快,使用更少的空间。 参考算法导论,跳表插入、删除、查找的复杂度均为O(logN)。
选择跳表的原因:
- 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等,但是实现细节过于复杂。
- 相比之下,跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList。目前开源软件 Redis 和 LevelDB 都有用到它。
2.skiplist核心思想
先从链表开始,如果是一个单链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次,时间复杂度为O(n)。


如果是说链表是排序的,并且结点中还存储了指向后面第二个结点的指针的话,那么在查找一个结点时,仅仅需要遍历N/2个结点即可。因此查找的时间复杂度为O(n/2)。

其实,上面基本上就是跳跃表的思想,每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,这个过程是通过一个随机函数生成器得到,这样子就构成了一个跳跃表。这就是为什么论文“Skip Lists : A Probabilistic Alternative to Balanced Trees ”中有“概率”的原因了,就是通过随机生成一个结点中指向后续结点的指针数目。随机生成的跳跃表可能如下图所示。

如果一个结点存在k个指向后续元素指针的话,那么称该结点是一个k层结点。一个跳表的层MaxLevel义为跳表中所有结点中最大的层数。跳表的所有操作均从上向下逐层进行,越上层一次next操作的跨度越大。
3.skiplist原理
skiplist的结构定义如下:
- 由多层结构组成;
- 每一层都是一个有序的链表;
- 最底层(Level 1)的链表包含所有元素;
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现;
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
为了便于描述,将跳表结构绘画成如下形式。
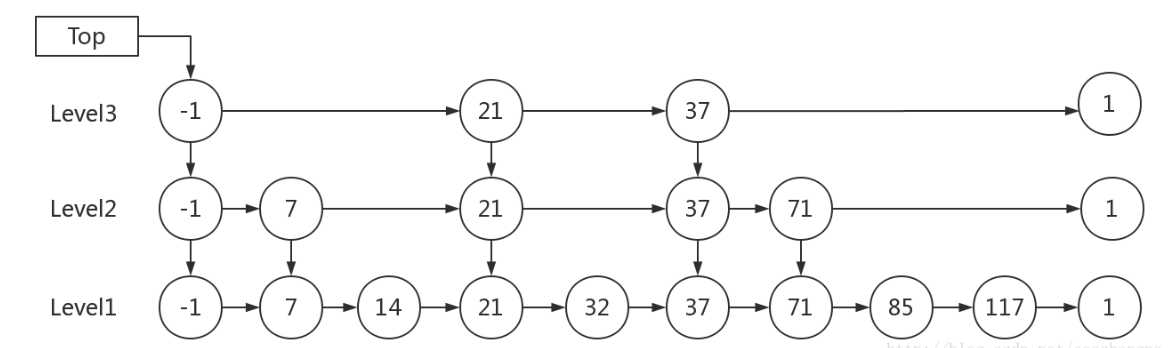
3.1 跳表的查找
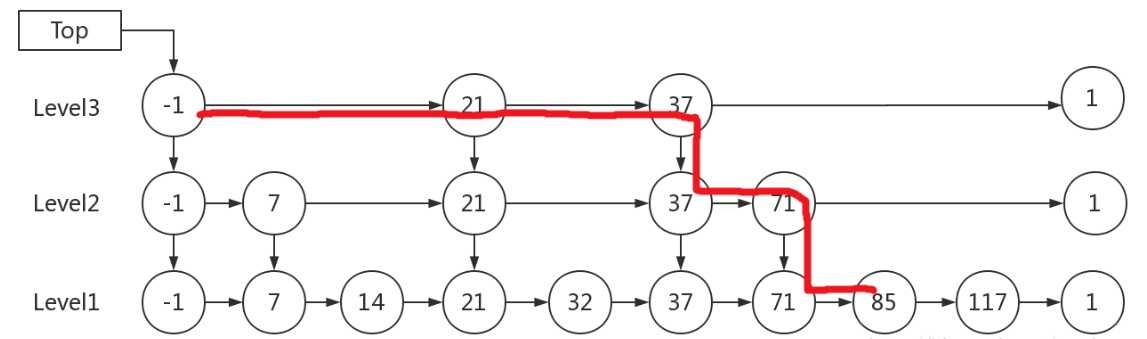
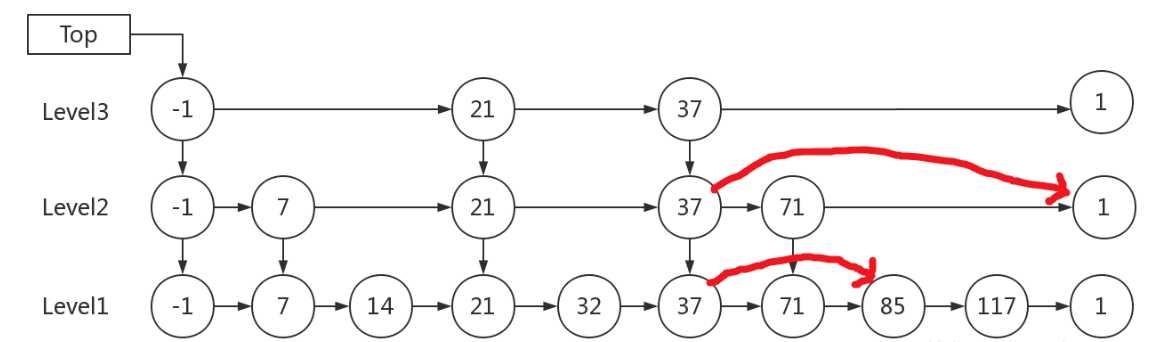
例子:查找元素 117,会经历如下几个步骤:
- 比较 21, 比 21 大,往后面找
- 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
- 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
- 比较 85, 比 85 大,从后面找
- 比较 117, 等于 117, 找到了节点。
3.2 跳表的插入
1)K小于链表的层数
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的),然后在 Level 1 … Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
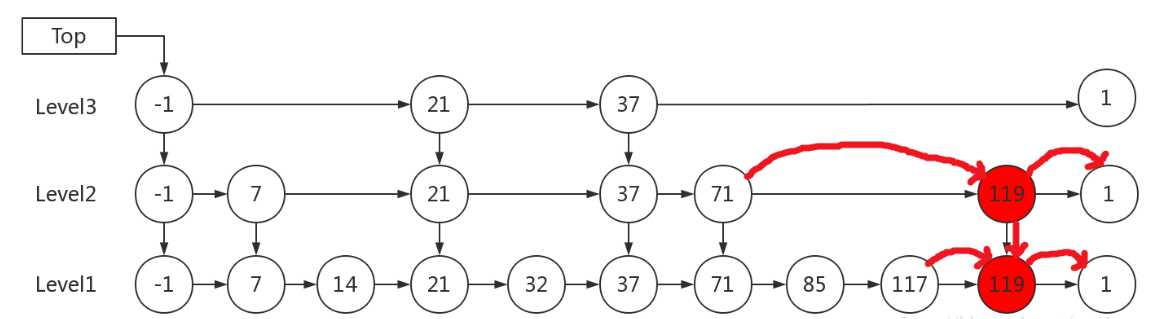
2)K大于链表的层数
如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4
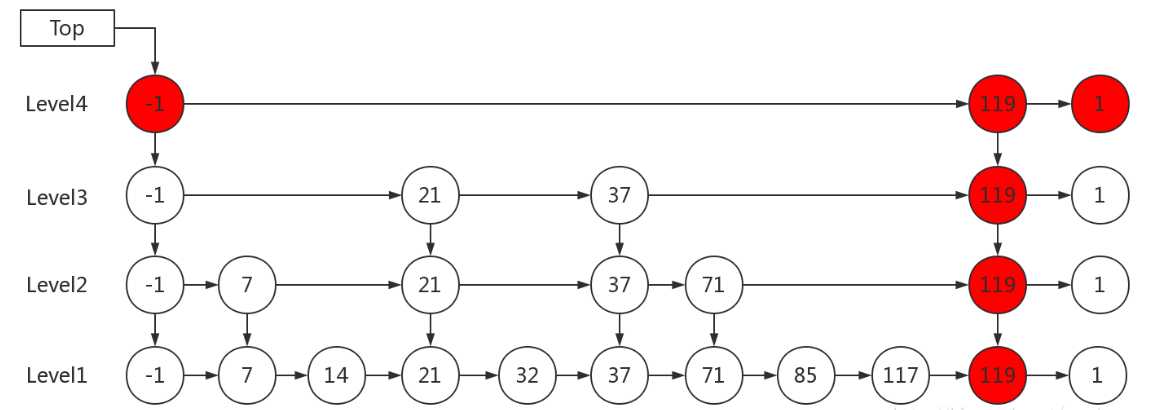
插入元素的时候,元素所占有的层数完全是随机的,通过某种随机算法产生。
3.3 跳表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
4.skiplist简单实现
增加层数的方案用的是抛硬币,即根据随机数来确定是否增加“快线”,这也是MIT公开课上给出的一个比较简单的实现方法。
头文件定义如下,使用prev,next,down,top来表示Node节点之间的指向,即前、后、下、上。
//SkipList.h
#ifndef __SKIPLIST_H__
#define __SKIPLIST_H__
#include <climits>
#include <cstdlib>
#include <ctime>
#include <cmath>
class Skiplist {
private :
struct Node {
int key;
Node * prev;
Node * next;
Node * down;
Node * top;
Node() : key(0), prev(nullptr), next(nullptr), down(nullptr), top(nullptr) {}
};
private :
Node * head;
int level;
int size;
private :
void bindNewNode(Node * x, Node * p);
void delNode(Node * x);
Node * searchNode(int key);
public :
Skiplist() : head(new Node), level(1),size(0)
{head->key = INT_MIN; srand(static_cast<int>(time(0)));}
~Skiplist() {delete head;}
void insert(int key);
void remove(int key);
bool search(int key) {return (searchNode(key) != nullptr);}
void showSkiplist();
int getLevel() {return level;}
int getSize() {return size;}
};
#endif // __SKIPLIST_H__函数实现:
//Skiplist.cpp
#include <iostream>
#include "SkipList.h"
using namespace std;
void Skiplist::bindNewNode(Node * x, Node * p) {
if (!x->next) {
x->next = p;
p->prev = x;
}
else {
p->next = x->next;
x->next->prev = p;
p->prev = x;
x->next = p;
}
}
void Skiplist::insert(int key) {
Node * p = new Node;
p->key = key;
Node * x = head;
while (1) { //find the prev node of p, which represents the right insert place
if (x->key <= key) {
if (x->next)
x = x->next;
else if (x->down)
x = x->down;
else break;
}
else if (x->prev->down)
x = x->prev->down;
else {
x = x->prev;
break;
}
}
bindNewNode(x, p);
while (rand() % 2) { //throw the coin, then judge whether it needs to be higher according to the results
Node * highp = new Node;
highp->key = key;
while (!x->top && x->prev)
x = x->prev;
if (x->top) {
x = x->top;
bindNewNode(x, highp);
highp->down = p;
p->top = highp;
}
else { //already the top, add a sentry
Node * top = new Node;
x = top;
top->key = INT_MIN;
top->down = head;
head->top = top;
head = top;
bindNewNode(top, highp);
highp->down = p;
p->top = highp;
++level;
}
p = highp;
}
++size;
}
void Skiplist::delNode(Node * x) {
if (!x->next) { //node x is the last one
if (x->prev == head && head->down) { //x is not at the bottom and x is the last one of this level
head = head->down;
head->top = nullptr;
delete x->prev;
--level;
}
else
x->prev->next = nullptr;
}
else {
x->prev->next = x->next;
x->next->prev = x->prev;
}
delete x;
}
void Skiplist::remove(int key) {
Node * x = searchNode(key);
if (x) {
while (x->down) {
Node * y = x->down;
delNode(x);
x = y;
}
delNode(x);
--size;
}
}
Skiplist::Node * Skiplist::searchNode(int key) {
Node * x = head;
while (1) { //find the prev node of p, which represents the right insert place
if (x->key == key)
return x;
else if (x->key < key) {
if (x->next)
x = x->next;
else if (x->down)
x = x->down;
else
return nullptr;
}
else if (x->prev->down)
x = x->prev->down;
else {
return nullptr;
}
}
}
void Skiplist::showSkiplist() {
Node * x = head, * y = head;
while (y) {
x = y;
while (x) {
if (x->prev != nullptr)
cout << x->key << ' ';
x = x->next;
}
cout << endl;
y = y->down;
}
}主函数和执行结果:
//main.cpp
#include "SkipList.h"
int main()
{
Skiplist* m_Skiplist = new Skiplist();
m_Skiplist->insert(7);
m_Skiplist->insert(14);
m_Skiplist->insert(21);
m_Skiplist->insert(32);
m_Skiplist->insert(37);
m_Skiplist->insert(71);
m_Skiplist->insert(85);
m_Skiplist->showSkiplist();
return 0;
}
————————————————————————————————————————————————————
使用方法,创建g++ -std=c++11 -o main main.cpp SkipList.cpp 生成main可执行文件
因为增加层数的方案用的是抛硬币,每次执行结果生成的level层数不一致,如下:
[root@192 skiplist1]# ./main
7 14 32
7 14 32 37
7 14 32 37 85
7 14 32 37 71 85
7 14 21 32 37 71 85
[root@192 skiplist1]# ./main
21
21
21
7 14 21 32 71
7 14 21 32 37 71 85
[root@192 skiplist1]# ./main
21
21
21
21
21
21 32
21 32 37
7 14 21 32 37 71 85
参考链接:https://blog.csdn.net/caoshangpa/article/details/78862339
参考链接:https://www.cnblogs.com/yxsrt/p/12249745.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179611.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
