大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
关于感知机
- ok lets go。
- 感知机是线性分类模型,划重点注意哦,是线性的分类模型。也就是说,如果你拿感知机去分类线性不可分的数据集的话,它的效果想必垂泪。
- 因为近期看到相关算法的缘故来写一片感知机的文章,主要介绍一下这是个什么东西以及它能用来干什么。
- 就我来说最考试接触到感知机是在学习神经网络的时候,神经网络中的每一个点就能看做是一个感知机。
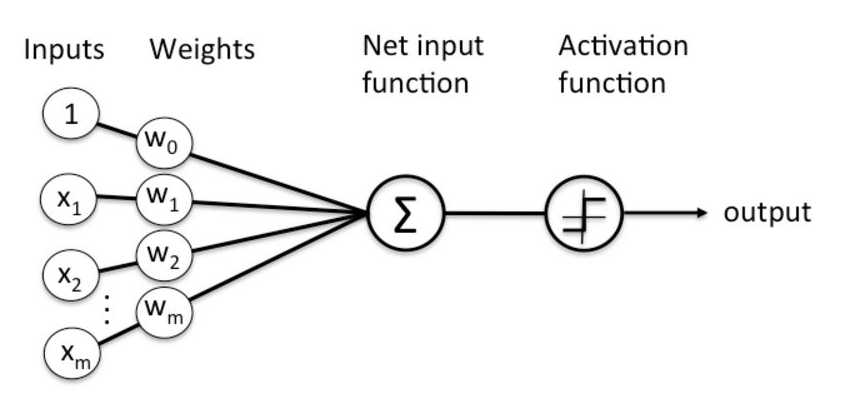

上图大概就是感知机的构造了。了解神经网络的同学肯定了解到这就是网络中的一个节点,左边是输入,肉便是输出,将左边的向量输入乘以权值向量加上偏差(图中未给出)再通过激活函数便是输出了。我们在看一下感知机的公式:
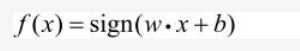
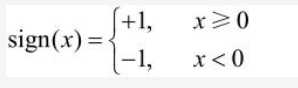
我们的公式1即可视为感知机的机理,公式二为激活函数。公式1与上图中感知机的结构相对应。
我们再来介绍下数据集,使用感知机来分类的数据集为线性可分的数据,可以被分为两类,我们将其标注为+1和-1.感知机所做的就是将数据中的特征放入到公式1当中,得出的结果若为+1,则分为类别1,结果为-1,则分为类别2.这差不多就是我们使用感知机模型的方法了,当然这是感知机模型以及训练完毕之后的用法。换而言之,我们要先训练感知机模型,使其能够达到分类我们数据的能力时再来使用它。ml中的所有学习算法几乎都具有这样的特点。
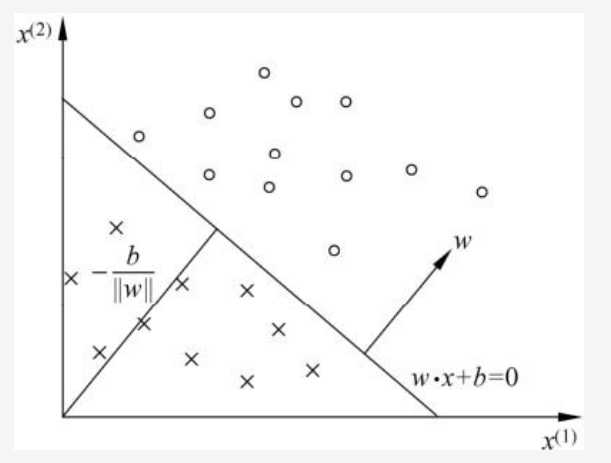
感知机所做的在上图所示的数据中可以视为划分一条线来分类数据。(在高维数据集中实则为划分一个超平面来分类数据)
ok 现在我们来看看这个模型要怎么训练。首先我们看看他需要训练的是哪些东西,是哪些参数。我们所需要训练的参数即是在公式一中的w(权重,weight)以及b(偏差,bias)。得到这两个参数之后,我们可以看到感知机就能够运作了,只需要输入数据即可。
现在我们来简单讨论如何训练这两个参数,这就是感知机算法。
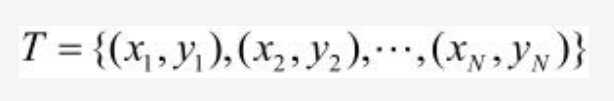
我们将这作为我们的数据,对应于上图我们的数据中的xi是两维的,相对应的w也是两维。我们需要从数据中学习如何制定w和b来使得模型对数据的分类效果达到最佳。感知机的分类思想主要可以简单的表述为通过迭代更新w和b使得被误分类的的数据点距离我们的分类超平面的距离尽可能的小。怎么来理解这句话,我们可以这样想:感知机所做的是试图找到一个超平面来完美的把数据集分割为两个类别,一个类别在超平面的一边,而另一个类别的数据则在超平面的另一边,超平面规定这两边的数据都有相对的类别,比如说超平面上方为类别一下方为类别二,那么实际使用该感知机分类完毕后处在超平面上方的数据全为类别一,下方全为类别二。感知机模型希望能找到这样一个超平面,若这样的平面被找到,分类问题(在当前数据集)便被解决了。那要如何找到这样一个平面呢?简而言之就是当我们取数据集中的一个数据点,而此数据点经过我们的感知机模型之后的输出显示他是被误分类的时候(y_pred与y_label不一致),此时他在超分类平面的一边,且是错误的一边,我们则通过修改超平面来使得该被误分类的数据点能够更接近超平面,因为它处在错误的一面,则他离超平面越近则超平面的正确性就相对而言的更高一些。这样说相信大家都能理解了。而经过不断从数据集中取出数据,判断其分类正确与否,再修正超平面的迭代过程最终就可使得该超平面接近于理想中正确完美的那个平面。下面我们来介绍这一步骤是怎样通过数学的方法实现的,当然了,简单讲讲。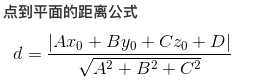
- 如上所示为点到平面的距离公式,而在我们的感知机算法中推广到更高纬时:
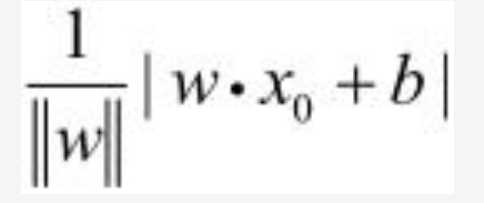
他差不多是这样的。其中||w||指的是w的l2范数(母鸡的可以先行了解)。我们所要的误分类的点距离超平面的距离则可以展示如下:
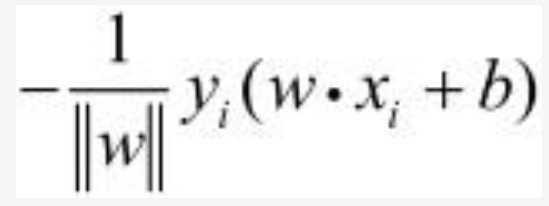
其中yi是数据集中每一个数据点的对应的正确的标签(y_label),xi是数据点的特征。就上式来说,若yi是1,而(w*xi+b)是-1,这个式子他就是大于0的,也就是说误分类的点上式值为正,相反正确分类的点的值为负(自证)。所以将所有的误分类的点代入其中便可得出所有误分类的点到超平面的距离集合,相加即是距离和,如下所示:
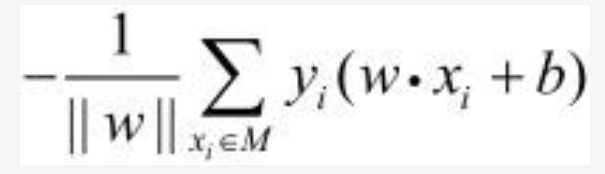
上式中输入的xi都为被误分类的点,而输出即是误分类的点距离超平面的距离之和。理论上我们只要想办法将这个式子最小化,我们的目的就达到了(该式子>=0),因为该式子输入元为误分类的店,当其值最小化(为0时),即不存在误分类的点,即是超平面完美,分类任务完成。- ok 现在介绍如何来使得这个式子最小化。(实际中为了方便我们将前面的||w||直接去掉,只看后半部分的式子)。
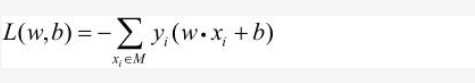
- 也就是这么个东西,这个式子可以看出是感知机模型的损失函数,也就是我们要尽力最小化的函数。
- 要最小化这个式子,我们使用的是梯度下降算法(母鸡可以自行了解一哈)。
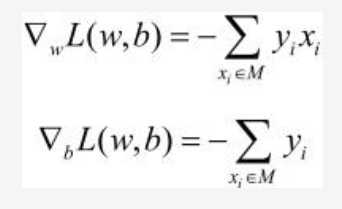
- w与b的梯度如上所示,接下来我们要做的便是迭代优化。从数据集中抽取数据点,判断其是否误分类,若不是怎接着抽下一个,若是则求其梯度,更新w与b,直到损失函数接近于最小值。
- 更新w与b如下式:
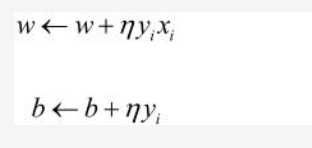
- 文章到这儿就差不多了,感知机做的事主要就是根据线性可分的数据集来构造一个超平面来分类数据,若果你看懂了那就最好,如果不懂或者有疑惑或者有啥想法探讨,可以email我:zlh9584@gmail.com
愿你前程似镜,世界和平。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179562.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
