大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
讲解Scrapy框架之前,为了让读者更明白Scrapy,我会贴一些网站的图片和代码。
但是,【注意!!!】
【以下网站图片和代码仅供展示!!如果大家需要练习,请自己再找别的网站练习。】
【尤其是政府网站,千万不能碰哦!】
一、Scrapy框架原理
1、Scrapy特点
- 特点
- 是一个用Python实现的为了爬取网站数据、提取数据的应用框架
- Scrapy使用Twisted异步网络库来处理网络通讯
- 使用Scrapy框架可以高效(爬取效率和开发效率)完成数据爬取
2、Scrapy安装
- Ubuntu安装
sudo pip3 install Scrapy
- Windows安装
python -m pip install Scrapy
3、Scrapy架构图
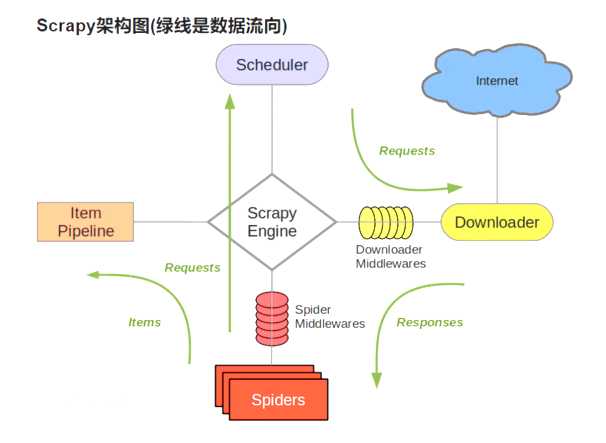

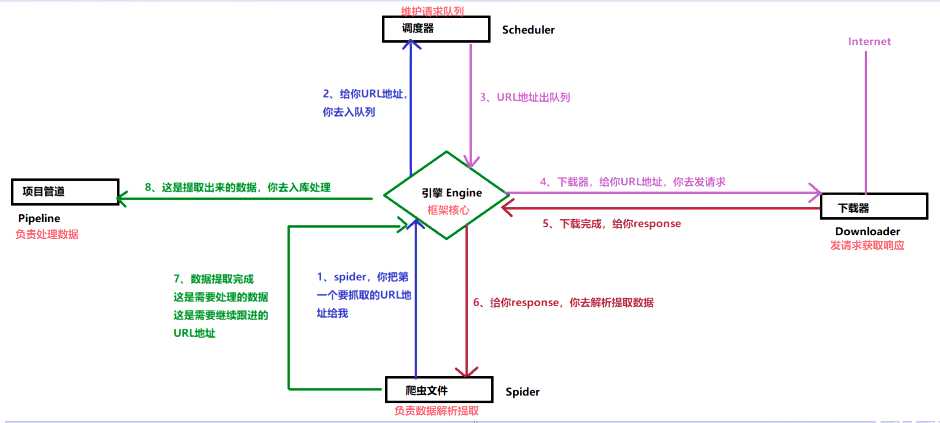
-
整理(面试中常问到的问题)
-
Scrapy架构有几个组件?他们具体的工作流程是什么?
答:Scrapy架构有5个组件:分别为
引擎、爬虫文件(负责数据解析处理的)、调度器(负责维护请求队列的)、
下载器(负责发请求得到响应对象的)、项目管道(负责数据处理的)大致的工作流程是:爬虫项目启动,引擎找到爬虫索要第一批要抓取的URL地址,交给调度器入队列,再出队列,交给下载器去下载,下载器下载完成之后,拿到response。拿到的response通过引擎交给爬虫。爬虫文件负责具体的数据解析提取,提取出来的数据交给项目管道进行处理;如果是要继续跟进的URL地址,则再次交给调度器入队列,如此循环。
-
4、Scrapy五大组件
-
五大组件及作用
- 引擎(Engine):整个框架核心
- 调度器(Scheduler):维护请求队列
- 下载器(Downloader):获取响应对象
- 爬虫文件(Spider):数据解析提取
- 项目管道(Pipeline):数据入库处理
-
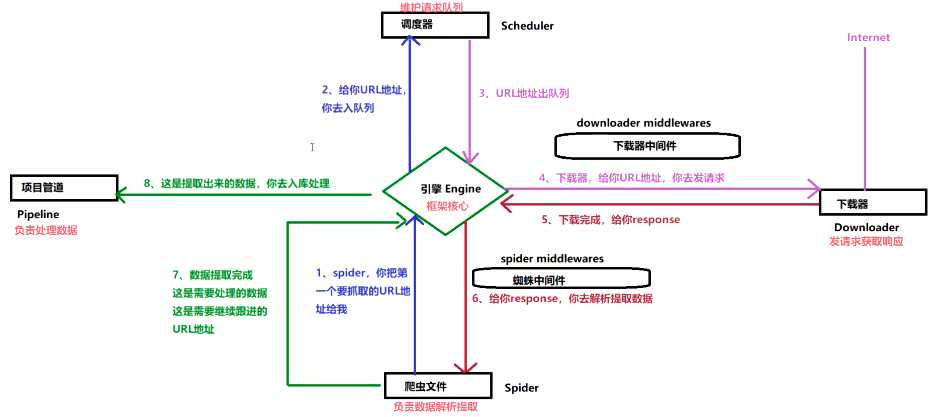
两个中间件及作用
-
下载器中间件(Downloader Middlewares)
请求对象 –> 引擎 –> 下载器,包装请求(随机代理等)
-
蜘蛛中间件(Spider Middlewares)
相应对象 –> 引擎 –> 爬虫文件,可修改响应对象属性
-
5、Scrapy工作流程
-
工作流程描述 – 爬虫项目正式启动
-
引擎向爬虫程序索要第一批要爬取的URL,交给调度器入队列
-
调度器处理请求后出队列,通过下载器中间件交给下载器去下载
-
下载器得到响应对象后,通过蜘蛛中间件交给爬虫程序
-
爬虫程序进行数据提取:
数据交给管道文件去入库处理
对于需要跟进的URL,再次交给调度器入队列,如此循环。
-
二、Scrapy创建项目
-
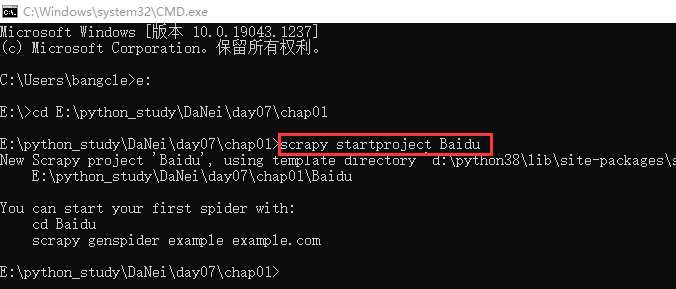
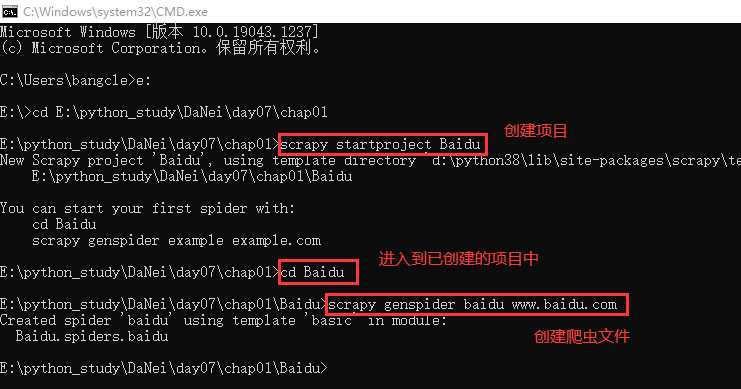
创建项目(通过命令创建项目)
- 语法:
scrapy startproject 项目结构
- 语法:
-
创建爬虫文件名
-
语法:
scrapy genspider 爬虫文件名 允许爬取的域名 -
此处创建爬虫文件名为小写的baidu,和项目名Baidu区分开。
-
-
Scrapy项目目录结构
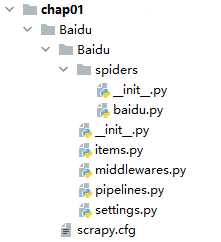
- scrapy.cfg:爬虫项目的配置文件。
- __init__.py:爬虫项目的初始化文件,用来对项目做初始化工作。
- items.py:爬虫项目的数据容器文件,用来定义要获取的数据。
- pipelines.py:爬虫项目的管道文件,用来对items中的数据进行进一步的加工处理。
- settings.py:爬虫项目的设置文件,包含了爬虫项目的设置信息。
- middlewares.py:爬虫项目的中间件文件。
三、Scrapy配置文件详解
1、项目完成步骤
- Scrapy爬虫项目完整步骤
- 新建项目和爬虫文件
- 定义要抓取的数据结构:items.py
- 完成爬虫文件数据解析提取:爬虫文件名.py
- 管道文件进行数据处理:pipelines.py
- 对项目进行全局配置:settings.py
- pycharm运行爬虫项目:run.py
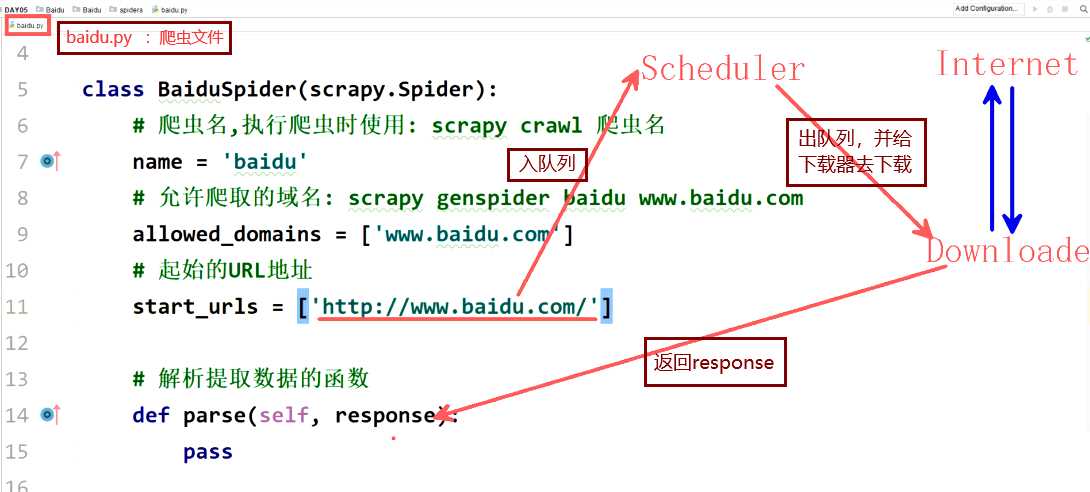
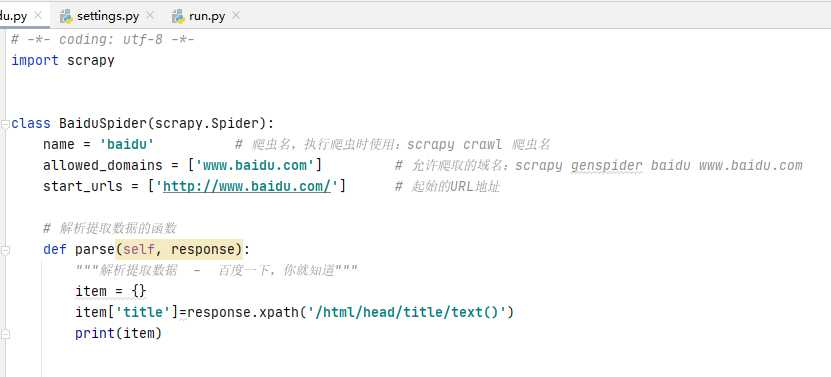
2、爬虫文件详解
-
常用配置
- name :爬虫名,当运行爬虫项目时使用
- allowed_domains :允许爬取的域名,非本域的URL地址会被过滤
- start_urls :爬虫项目启动时起始的URL地址
-
爬虫文件运行流程描述
-
爬虫项目启动,引擎找到此爬虫文件,将start_urls中URL地址拿走
交给调度器入队列,然后出队列交给下载器下载,得到response
response通过引擎又交还给了此爬虫文件,parse函数中的参数即是
-
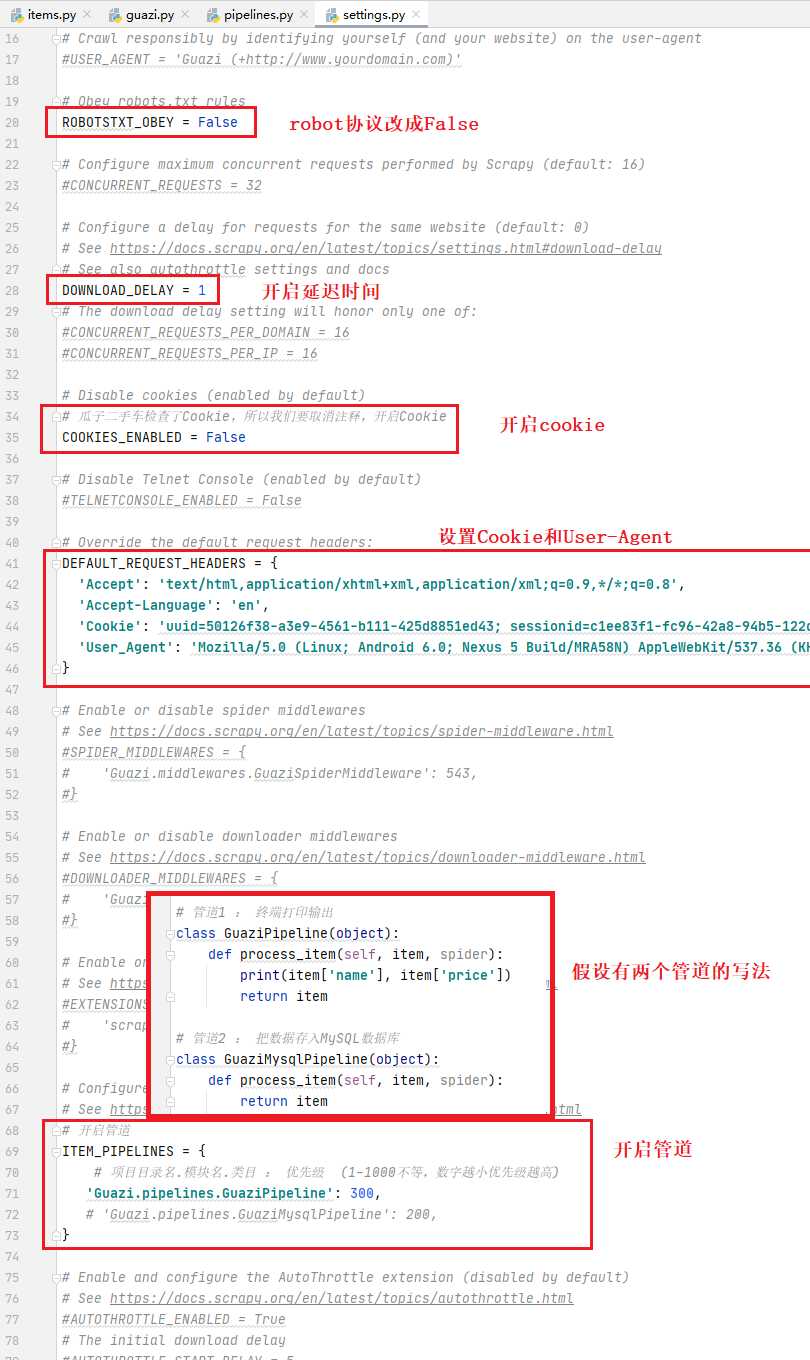
3、settings.py详解
- settings.py常用配置
- 设置User-Agent :
USER_AGENT = ' ' - 设置最大并发数(默认为16) :
CONCURRENT_REQUESTS = 32 - 下载延迟时间(每隔多久访问一个网页) :
DOWNLOAD_DELAY = 0.1 - 请求头 :
DEFAULT_REQUEST_HEADERS = { } - 设置日志级别 :
LOG_LEVEL = ' ' - 保存到日志文件 :
LOG_FILE = 'xxx.log' - 设置数据导出编码 :
FEED_EXPORT_ENCODING = ' ' - 项目管道 – 优先级1-1000,数字越小优先级越高
ITEM_PIPELINES = { '项目目录名.pipelines.类名': 优先级}
- cookie(默认禁用,取消注释 – True|False都为开启)
COOKIES_ENABLED = False
- 下载器中间件
DOWNLOADER_MIDDLEWARES = { '项目目录名.middlewares.类名': 优先级}
- 设置User-Agent :
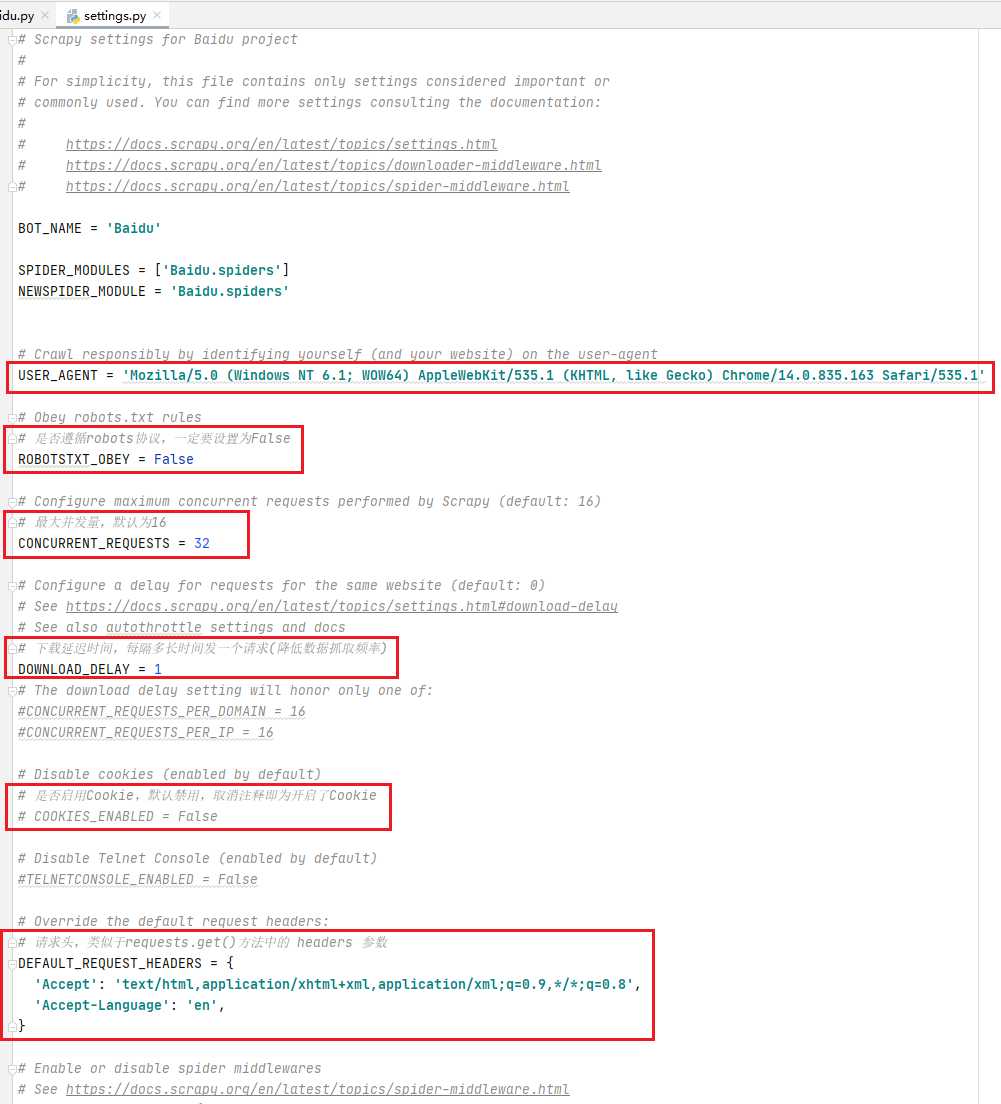
# 17行,设置USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'
# 20行,是否遵循robots协议,一定要设置为False
ROBOTSTXT_OBEY = False
# 23行,最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 28行,下载延迟时间,每隔多长时间发一个请求(降低数据抓取频率)
DOWNLOAD_DELAY = 3
# 34行,是否启用Cookie,默认禁用,取消注释即为开启了Cookie
COOKIES_ENABLED = False
# 40行,请求头,类似于requests.get()方法中的 headers 参数
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
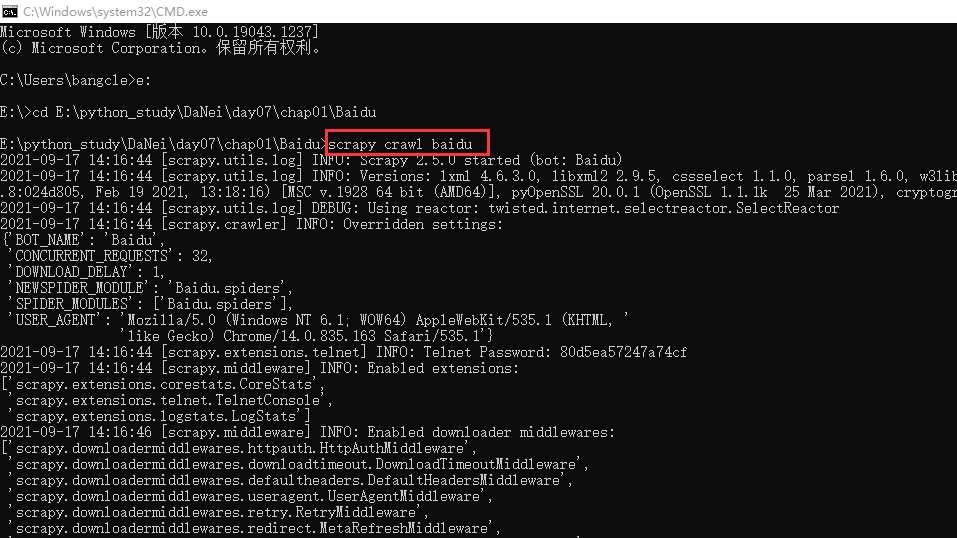
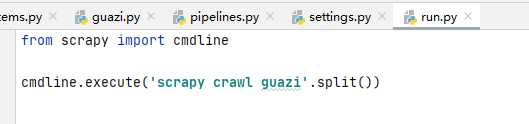
4、run.py 文件详解
- 运行爬虫的两种方式
-
在终端项目文件夹中输入
scrapy crawl 爬虫文件名
-
在pycharm中运行:
- 在最外层的Baidu项目文件中创建run.py
# 在run.py文件中 from scrapy import cmdline cmdline.execute('scrapy crawl baidu'.split())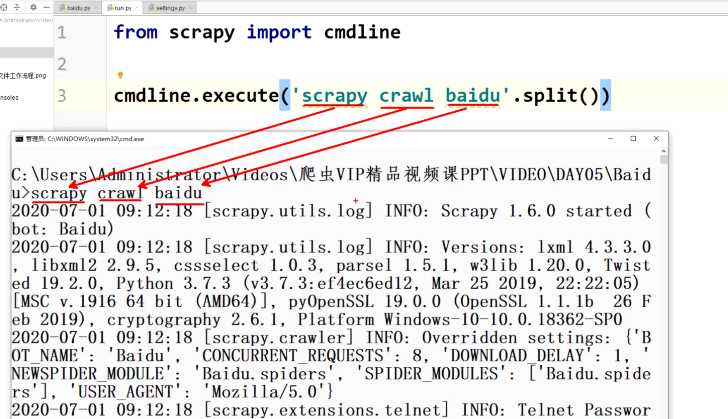
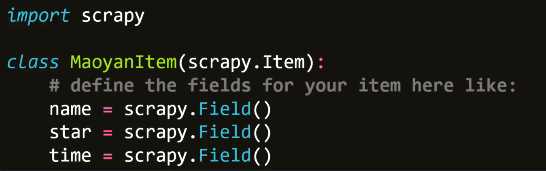
5、items.py详解
- Scrapy提供了Item类,可以自定义爬取字段
- Item类似我们常说的字典,我们需要抓取哪些字段直接在此处定义即可,当爬虫文件中对Item类进行实例化后,会有方法将数据交给管道文件处理
四、案例
-
目标
- 抓取二手车官网二手车收据(我要买车)
-
URL地址规律
- URL地址:https://…/langfang/buy/o{}/#bread
- 【网站不方便贴出来,大家要练习的话可以自行再找一个。】
- URL规律:o1 o2 o3 o4 o5 … …
-
所抓数据
- 汽车链接
- 汽车名称
- 汽车价格
-
汽车详情页链接、汽车名称、汽车价格
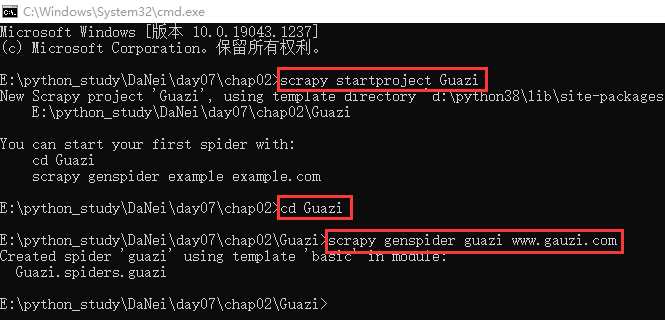
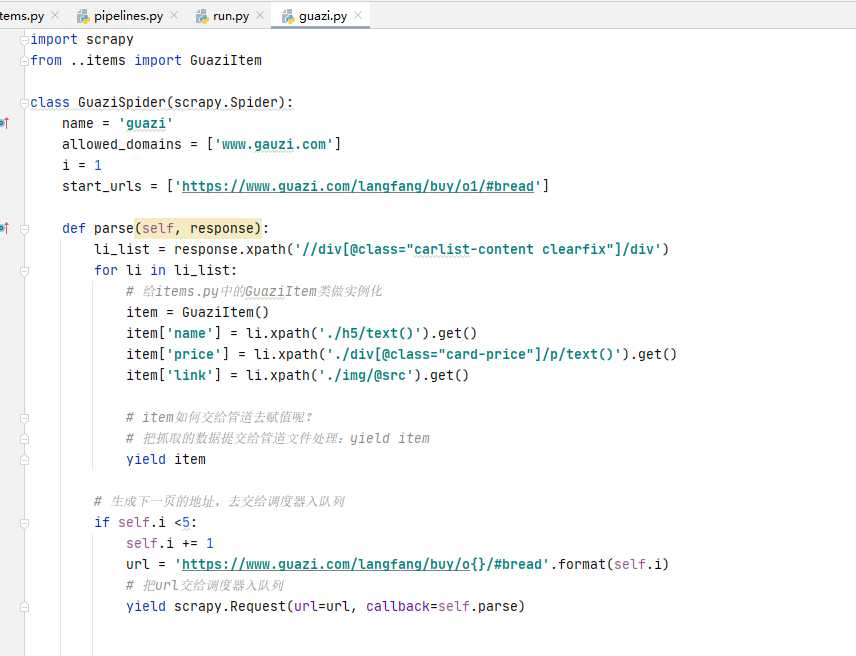
1、抓取一页数据
1.1 创建项目和爬虫文件
scrapy startproject Guazicd Guaziscrapy genspider guazi www.gauzi.com- 此处www.gauzi.com如果写错了,后面也可以直接在文件中修改
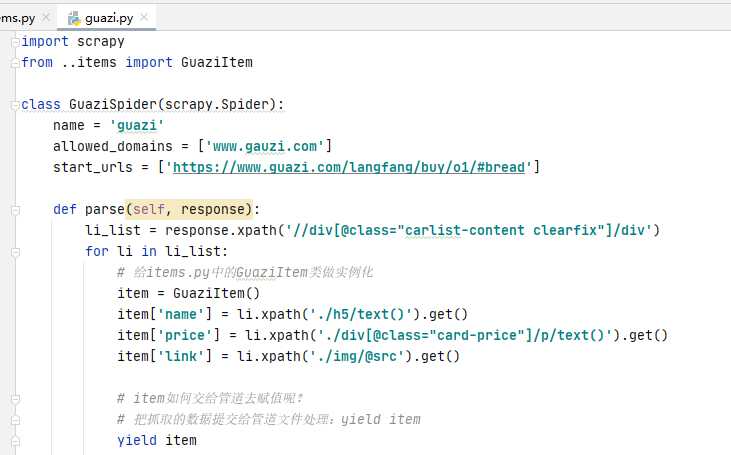
1.2 items.py文件
- 完全按照它的模板写,就是我们需要什么就创建什么
- 那么所有的value都是空值,什么时候赋值呢?等爬虫把数据抓取下来之后再赋值。

1.3 写爬虫文件
- 代码中的li_list的xpath可能写的不准确,但是大概思路是这样的。
1.4 管道:pipelines.py文件
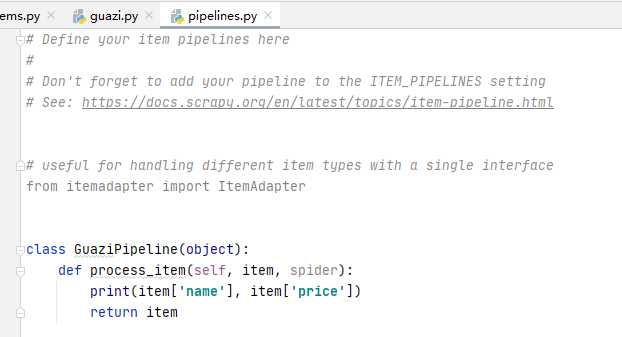
1.5 全局配置:settings.py文件
1.6 运行文件:run.py
- 在最外层的Guazi文件中创建 run.py
2、抓取多页数据
-
爬虫文件:guazi.py
-
整理

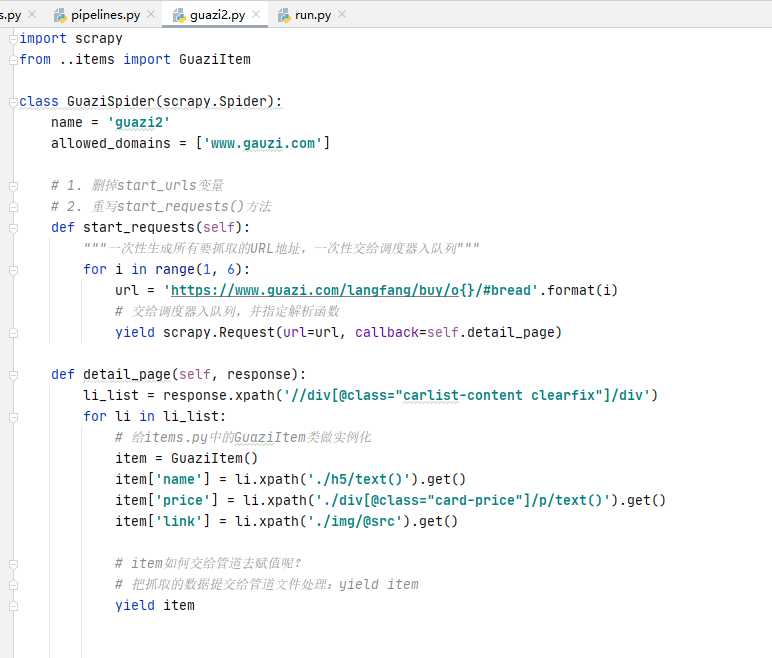
3、快捷抓取多页数据
4、总结 – 爬虫项目启动方式
-
基于start_urls启动
从爬虫文件的start_urls变量中遍历URL地址交给调度器入队列
把下载器返回的响应对象交给爬虫文件的parse()函数处理
-
重写start_requests()方法
去掉start_urls变量
def start_requests(self):
生成要爬取的URL地址,利用scrapy.Request()交给调度器
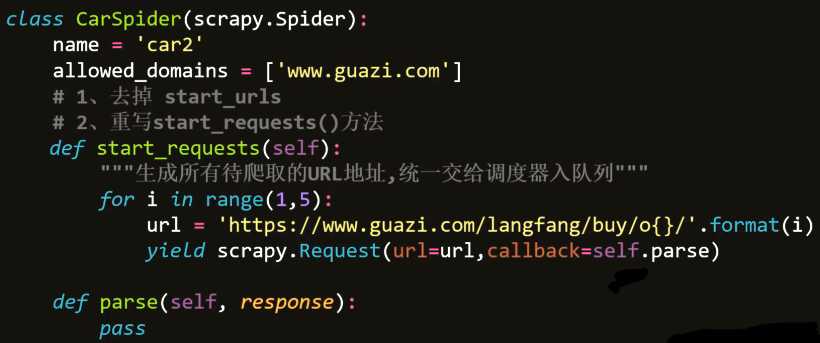
五、Scrapy数据持久化
1、管道文件详解
-
管道文件使用说明 – pipelines.py
管道文件主要用来对抓取的数据进行处理
一般一个类即为一个管道,比如创建存入MySQL、MongoDB的管道类
管道文件中 process_item()方法即为处理所抓取数据的具体方法
-
创建多个管道
如图创建了3个管道,从终端数据、存入MySQL、存入MongoDB
如果要开启这3个管道,需要在settings.py中添加对应管道

-
open_spider()方法 和 close_spider()方法
- open_spider()
- 爬虫项目启动时只执行1次,一般用于数据库连接
- process_item()
- 处理爬虫抓取的具体数据
- close_spider()
- 爬虫项目结束时只执行1次,一般用于收尾工作
- open_spider()
。:.゚ヽ(。◕‿◕。)ノ゚.:。+゚
- process_item() 函数必须要 return item
- 存在多管道时,会把此函数的返回值继续交由下一个管道继续处理

- 存在多管道时,会把此函数的返回值继续交由下一个管道继续处理
2、Scrapy数据持久化
-
Scrapy数据持久化到MySQL数据库
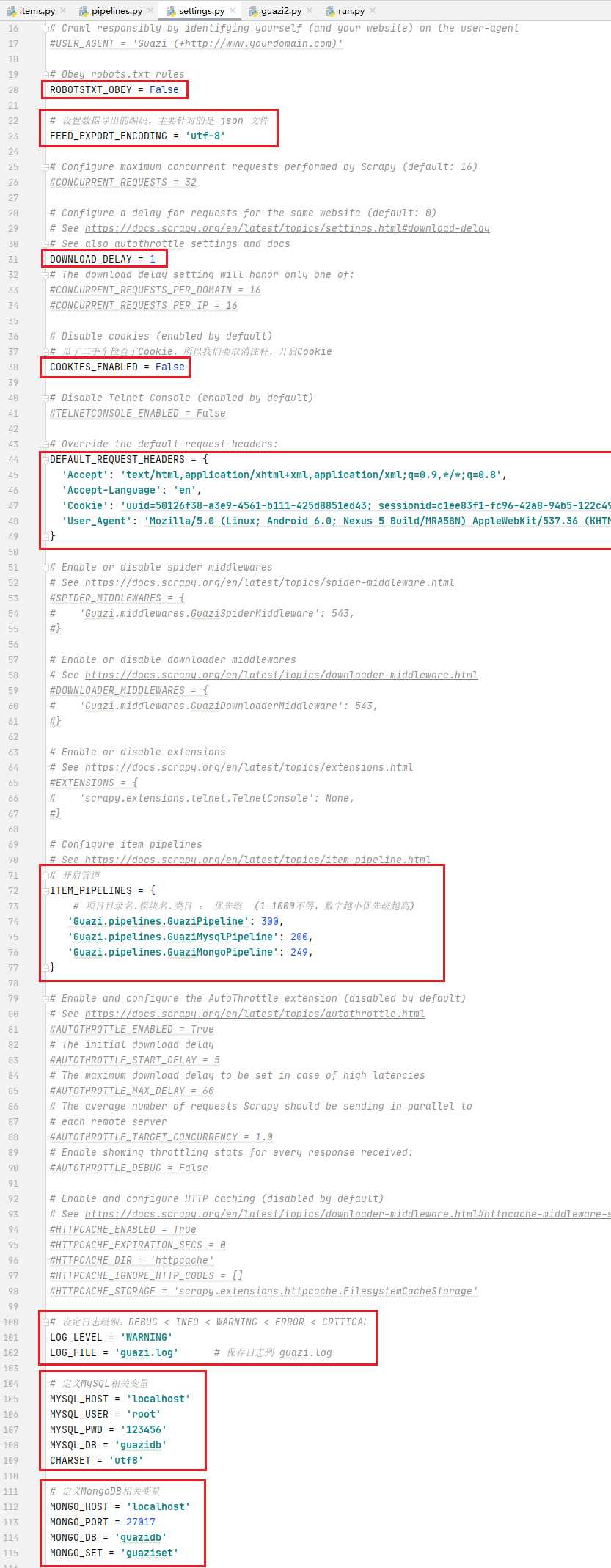
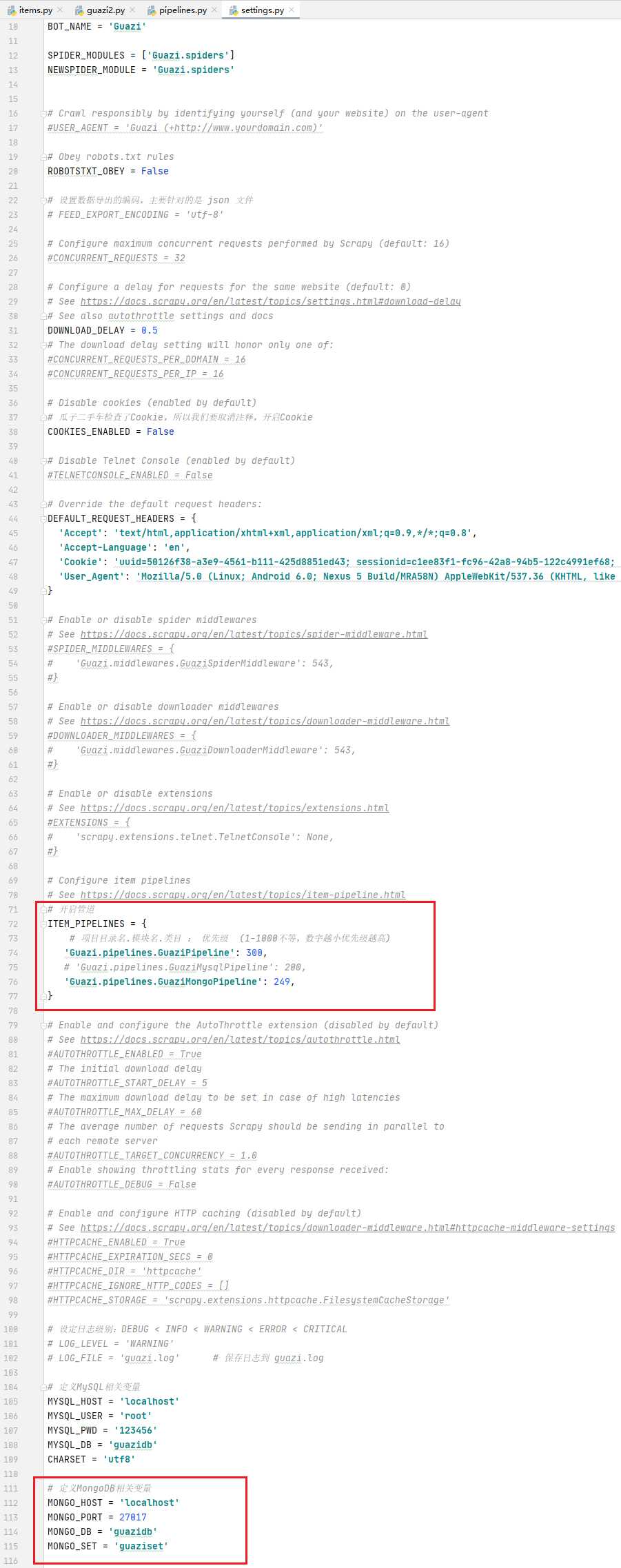
在settings.py中定义MySQL相关变量
pipelines.py中导入settings来创建数据库连接并处理数据
settings.py中添加此管道

-
Scrapy数据持久化到MongoDB数据库
在settings.py中定义MongoDB相关变量
pipelines.py中导入settings来创建数据库连接并处理数据
settings.py中添加此管道

3、将数据存入MySQL和MongoDB数据库
-
思路
settings.py 中定义相关数据库变量
pipelines.py 中处理数据
settings.py 中开启管道
-
将数据存入本地的csv文件、json文件中
scrapy crawl car -o car.csv
scrapy crawl car -o car.json -
针对json文件设置导出编码
settings.py 中添加 :
FEED_EXPORT_ENCODING = 'utf-8'
。:.゚ヽ(。◕‿◕。)ノ゚.:。+゚
-
提前建库建表
create database guazidb charset utf8; use guazidb; create table guazitab( name varchar(200), price varchar(100), link varchar(300) )charset=utf8;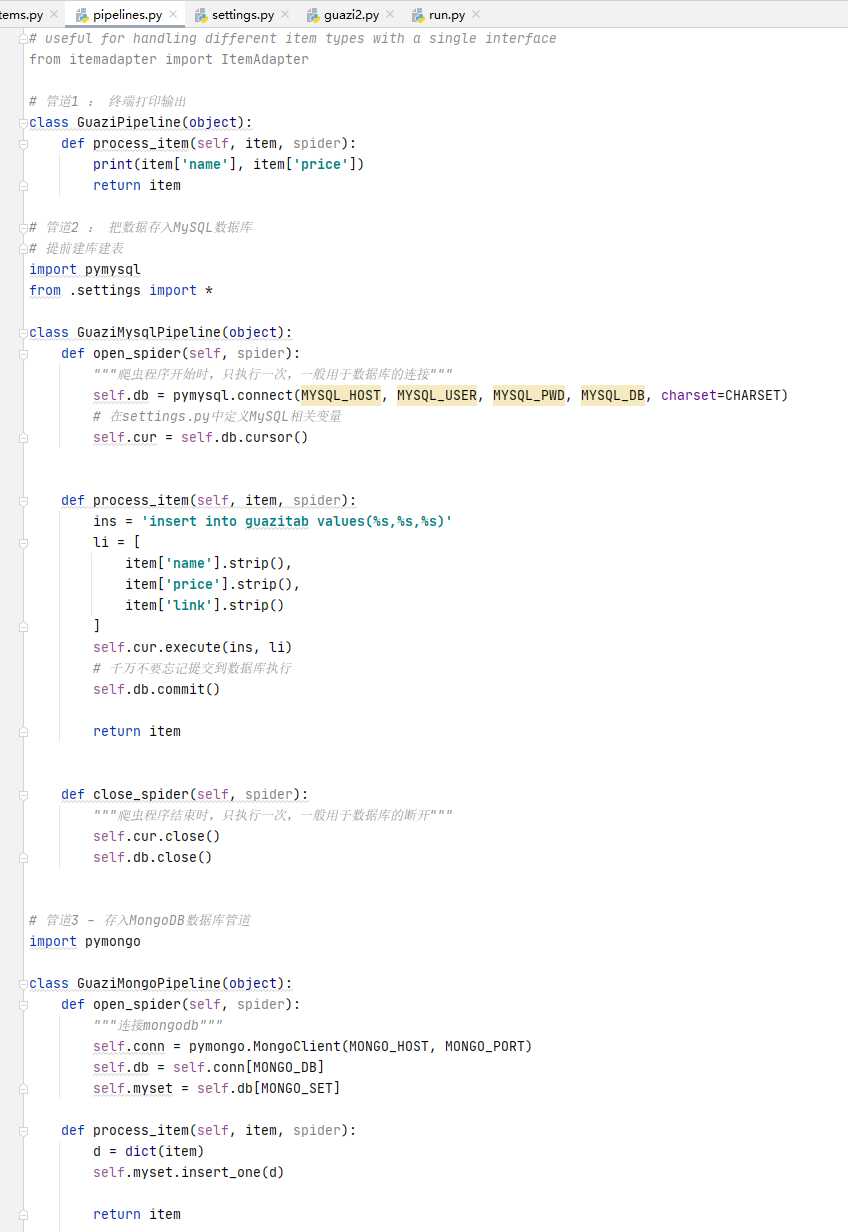

六、多级页面数据抓取
- 两级页面数据抓取
- 一级页面所抓数据(和之前一致)
- 汽车链接、汽车名称、汽车价格
- 二级页面所抓数据
- 上牌时间、行驶里程、排量、变速箱
- 一级页面所抓数据(和之前一致)
。:.゚ヽ(。◕‿◕。)ノ゚.:。+゚
- 整体思路 – 在之前scrapy项目基础上升级
- items.py中定义所有要抓取的数据结构
- guazi.py中将详情页链接继续交给调度器入队列
- pipelines.py中处理全部汽车信息的item对象
。:.゚ヽ(。◕‿◕。)ノ゚.:。+゚
-
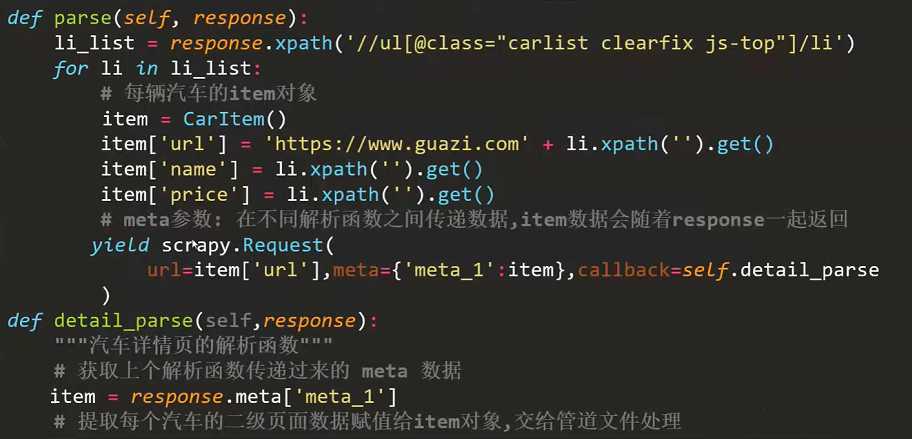
item对象如何在两级解析函数中传递 – meta参数
yield scrapy.Request( url=url,meta={ 'item':item},callback=self.xxx ) -
爬虫文件思路代码
案例操作:
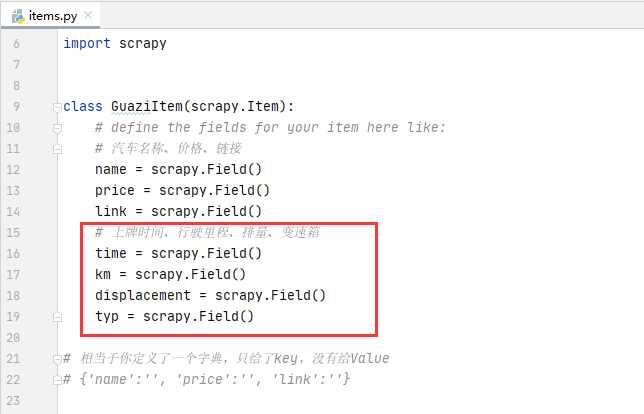
- 添加字段:item.py
# 上牌时间、行驶里程、排量、变速箱
time = scrapy.Field()
km = scrapy.Field()
displacement = scrapy.Field()
typ = scrapy.Field()
-
解析数据:guazi.py文件
import scrapy from ..items import GuaziItem class GuaziSpider(scrapy.Spider): name = 'guazi' allowed_domains = ['www.guazi.com'] # 1. 删掉start_urls变量 # 2. 重写start_requests()方法 def start_requests(self): """一次性生成所有要抓取的URL地址,一次性交给调度器入队列""" for i in range(1, 6): url = 'https://www.guazi.com/langfang/buy/o{}/#bread'.format(i) # 交给调度器入队列,并指定解析函数 yield scrapy.Request(url=url, callback=self.detail_page) def detail_page(self, response): li_list = response.xpath('//div[@class="carlist-content clearfix"]/div') for li in li_list: # 给items.py中的GuaziItem类做实例化 item = GuaziItem() item['name'] = li.xpath('./h5/text()').get() item['price'] = li.xpath('./div[@class="card-price"]/p/text()').get() item['link'] = 'https://www.guazi.com'+li.xpath('./img/@src').get() # 把每辆汽车详情页的链接交给调度器入队列 # meta参数:在不同的解析函数之间传递数据 yield scrapy.Request(url=item['link'], meta={ 'item':item}, callback=self.get_car_info) def get_car_info(self,response): '''提取每辆汽车二级页面的数据''' # meta会随着response一起回来,作为response的一个属性 item = response.meta['item'] item['time'] = response.xpath(".//li[@class='one']/text()").get().strip() item['km'] = response.xpath(".//li[@class='two']/span/text()").get().strip() item['displacement'] = response.xpath(".//li[@class='three']/span/text()").get().strip() item['typ'] = response.xpath(".//li[@class='one']/text()").get().strip() # 至此,一辆汽车的完整数据提取完成!交给管道文件处理去吧! yield item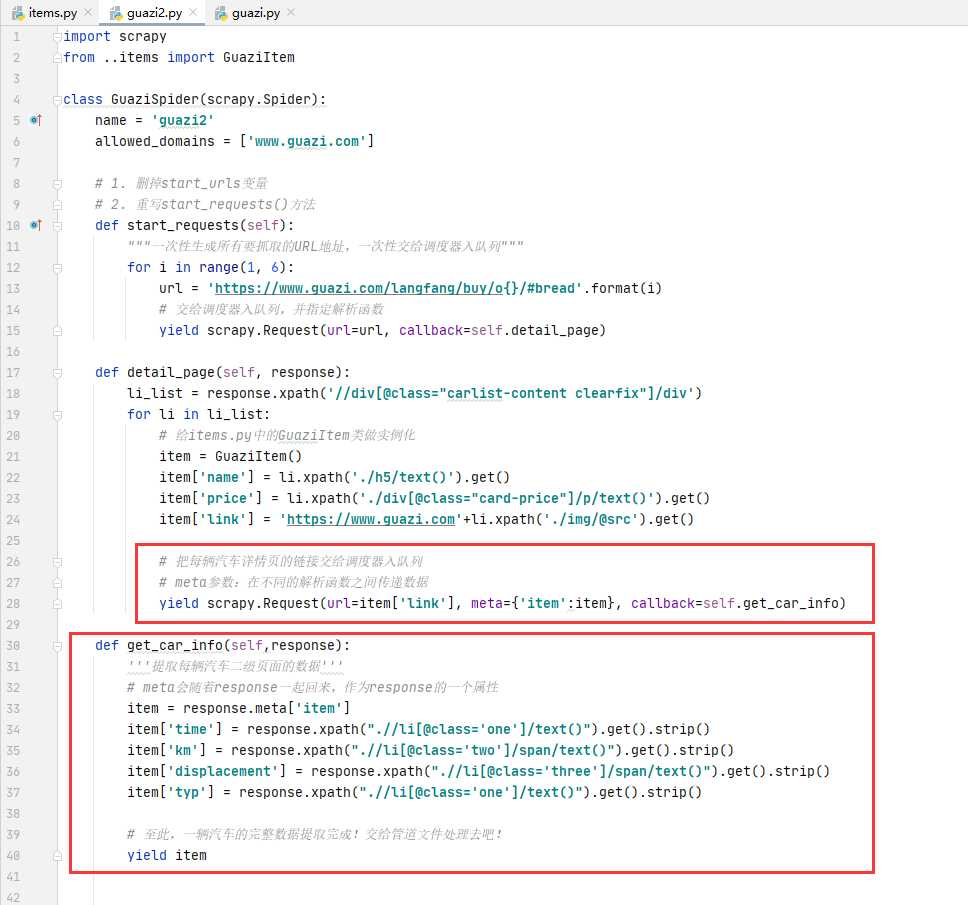
-
管道文件存储数据:pipelines.py
之前写过了,这里再回忆一下
# 管道3 - 存入MongoDB数据库管道 import pymongo class GuaziMongoPipeline(object): def open_spider(self, spider): """连接mongodb""" self.conn = pymongo.MongoClient(MONGO_HOST, MONGO_PORT) self.db = self.conn[MONGO_DB] self.myset = self.db[MONGO_SET] def process_item(self, item, spider): d = dict(item) self.myset.insert_one(d) return item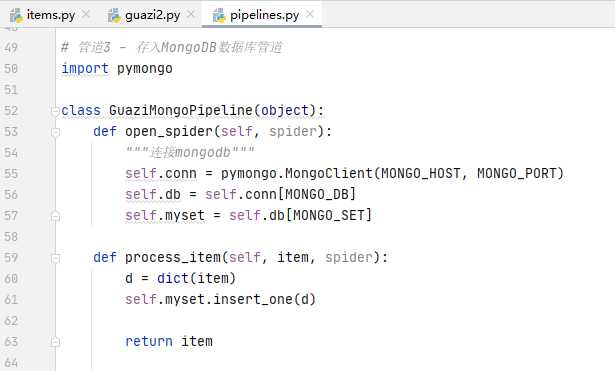
-
全局配置:settings.py
-
运行,查看mongo
> use guazidb; > show collections > db.guaziset.find().pretty()
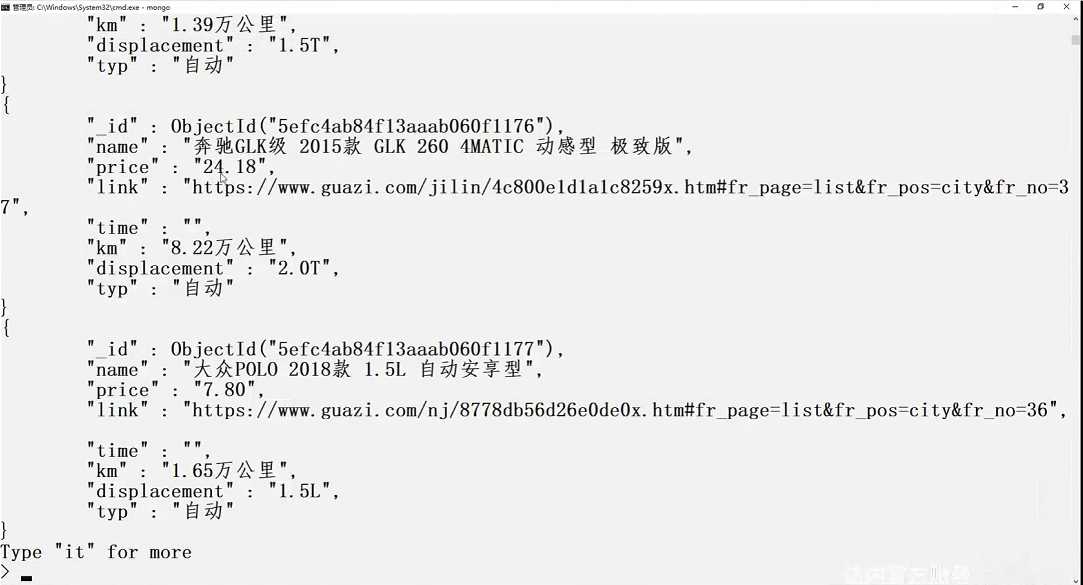
此网站设置了反爬,所以有的字段爬取不到,不过没有关系,思路懂了就行。大多数小型网站是没有这种反爬的。
知识点汇总
- 请求对象request属性及方法
- request.url : 请求URL地址
- request.headers : 请求头 – 字典
- request.meta : 解析函数间item数据传递、定义代理
- request.cookies : Cookie
- 响应对象response属性及方法
- response.url : 返回实际数据的URL地址
- response.text : 响应对象 – 字符串
- response.body : 响应对象 – 字节串
- response.encoding : 响应字符编码
- response.status : HTTP响应码
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179487.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
