大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
原文地址:
https://arxiv.org/pdf/1409.1556.pdf
VGG简介:
VGG卷积神经网络是牛津大学在2014年提出来的模型。当这个模型被提出时,由于它的简洁性和实用性,马上成为了当时最流行的卷积神经网络模型。它在图像分类和目标检测任务中都表现出非常好的结果。在2014年的ILSVRC比赛中,VGG 在Top-5中取得了92.3%的正确率。同年的冠军是googlenet。
总体描述:
是对深度神经网络深度上的一个探索,VGGNet反复堆叠3×3小型卷积核和2×2最大池化层,成功构筑16~19层深卷积神经网络。
优点:
1.简洁性:
结构简洁,整个网络都用同样大小卷积核尺寸和最大池化尺寸。
2.实用性与扩展性好:
拓展性强,迁移其他图片数据泛化性好。且VGGNet训练后模型参数官方开源。
网络结构:
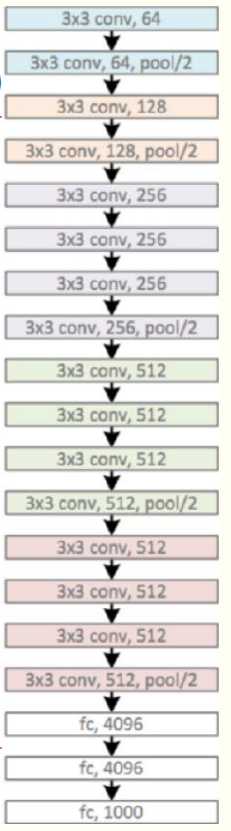

结构特点:
1.VGGNet 5段卷积,每段2~3卷积层,每段后接最大池化层缩小图片尺寸。
2.每段卷积核数量一样,越后段卷积核数量越多,64-128-256-512-512。
3.多个3×3卷积层堆叠。(2个3×3卷积层串联相当1个5×5卷积)。
网络配置总览:
为了简洁起见,不显示ReLU激活功能。
C型架构中的1*1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维(增加决策函数的非线性且不会影响到感受野的大小)。
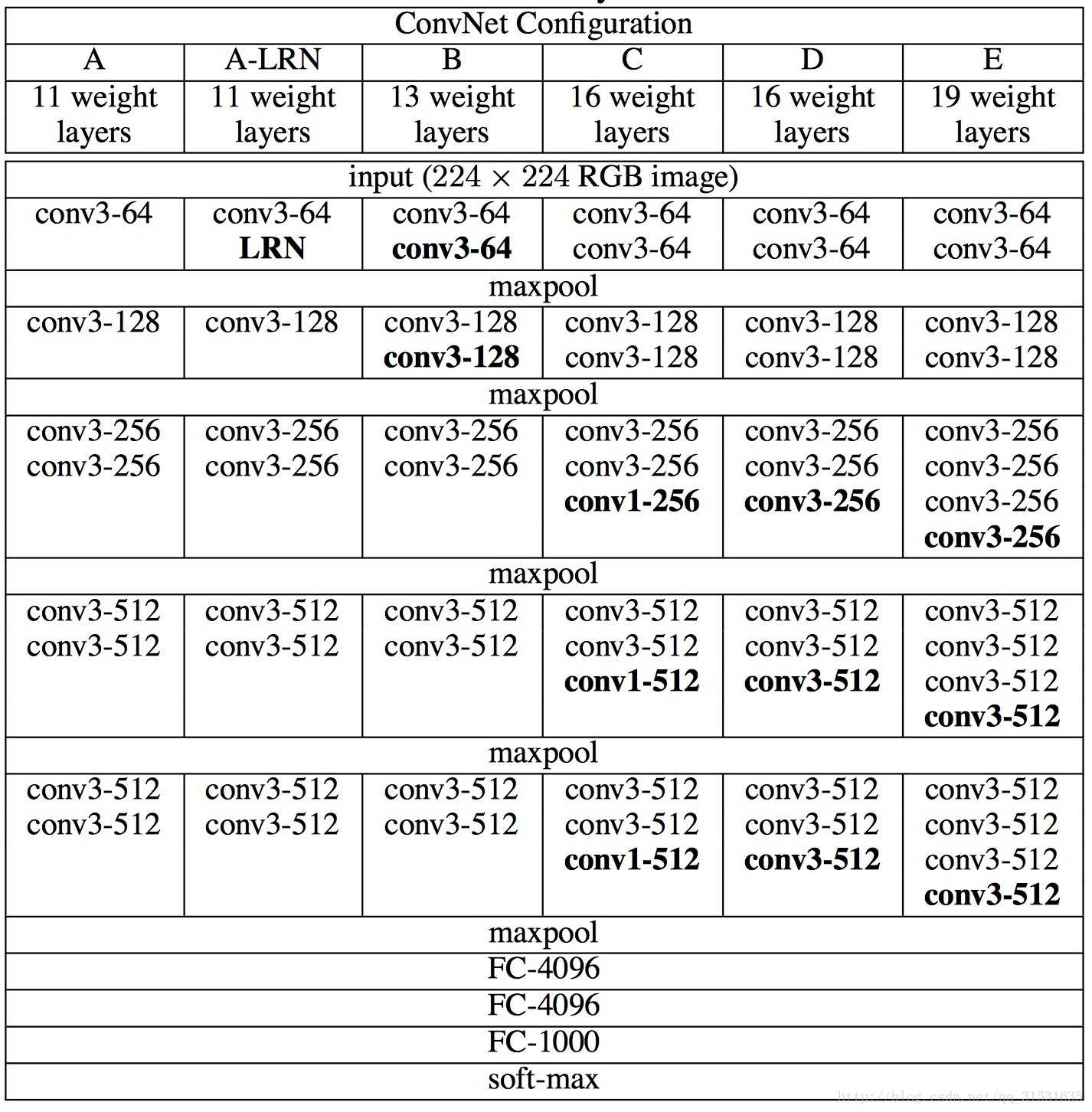
VGGNet-16网络结构总览:
6个部分,前5段卷积网络,最后一段全连接网络。
第一段卷积网络,两个卷积层,一个最大池化层。卷积核大小3×3,卷积核数量(输出通道数) 64,步长1×1,全像素扫描。
第一卷积层输入input_op尺寸224x224x3,输出尺寸224x224x64。
第二卷积层输入输出尺寸224x224x64。最大池化层2×2,输出112x112x64。
第二段卷积网络,2个卷积层,1个最大池化层。卷积输出通道数128。输出尺寸56x56x128。
第三段卷积网络,3个卷积层,1个最大池化层。卷积输出通道数256。输出尺寸28x28x256。
第四段卷积网络,3个卷积层,1个最大池化层。卷积输出通道数512。输出尺寸14x14x512。
第五段卷积网络,3个卷积层,1个最大池化层。卷积输出通道数512。输出尺寸7x7x512。输出结果每个样本,扁平化为长度7x7x512=25088一维向量。
连接4096隐含点全连接层,激活函数ReLU。连接Dropout层。
全连接层,Dropout层。
最后连接1000隐含点全连接层,Softmax 分类输出概率。输出概率最大类别。
为什么使用3*3卷积级联?
为什么最大的卷积核大小是3*3,不是更小,或者更大?
因为这是能捕捉到各个方向的最小尺寸了,如ZFNet中所说,由于第一层中往往有大量的高频和低频信息,却没有覆盖到中间的频率信息,且步长过大,容易引起大量的混叠,因此滤波器尺寸和步长要尽量小;
ZFNet的实验数据:
a):没有特征缩放裁剪的第一层特征。请注意,一个特征十分巨大。(b):来自Krizhevsky等人的第一层特征。 (c):我们的第一层功能。较小的步幅(2 vs 4)和过滤器尺寸(7×7 vs 11×11)会导致更多鲜明的特征和更少的“无用”特征。

3*3卷积核级联的好处:
1.通过多层的级联直接结合了非线性层
2.减少网络参数
3.是对7*7卷积核的一种(非线性)分解。分解之后,网络的参数减少了,但对图像信息采集的范围没有变,所以某种意义上来说是对7*7卷积核的一种正则化等效。
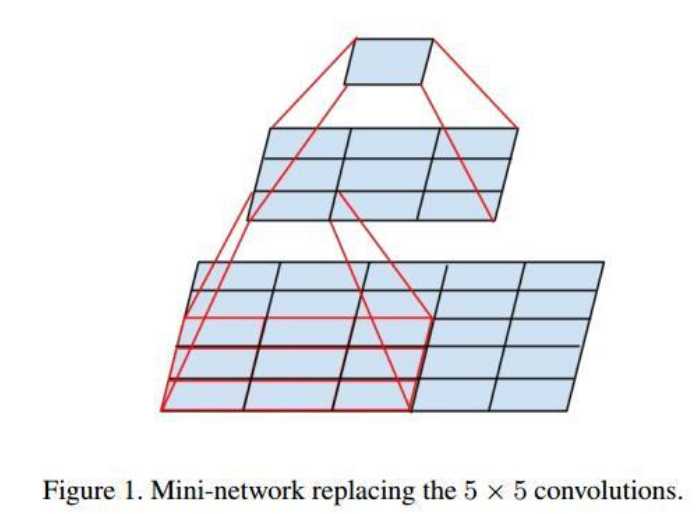
3*3卷积级联的分析(inception V3有详细的讨论):
如下图,两个3×3的卷积核相串联相当于一个5×5的卷积核
优点:
1.参数更少,5×5的参数量——>2*3*3的参数量
2.非线性表现力更强,一个激活函数和两个激活函数的区别
模型训练方法:
使用具有动量的小批量梯度下降优化多项式逻辑回归目标函数。
对于选择softmax分类器还是k个logistics分类器,取决于所有类别之间是否互斥。所有类别之间明显互斥用softmax;所有类别之间不互斥有交叉的情况下最好用k个logistics分类器。
网络收敛的更快的原因:
1.更深的网络深度和小卷积核带来的隐式正则化
2.某些层的预初始化(预训练)。(文中也提到了一种不用预训练的可替代方案)
训练图片预处理过程:
1.训练图片归一化,图像等轴重调(最短边为S)
等轴重调剪裁时的两种解决办法:
(1) 固定最小遍的尺寸为256
(2) 随机从[256,512]的确定范围内进行抽样,这样原始图片尺寸不一,有利于训练,这个方法叫做尺度抖动,有利于训练集增强。 训练时运用大量的裁剪图片有利于提升识别精确率。
2.随机剪裁(每SGD一次)
3.随机水平翻转
4.RGB颜色偏移
模型测试过程:
1.测试图片的尺寸(Q)不一定要与训练图片的尺寸(S)相同(缩放后的尺寸为Q×Q大小的图像,Q与S基本无关)。由于下面的操作可以使全卷积网络被应用在整个图像上,所以不需要在测试时对采样多个裁剪图像(直接拿Q过来用),因为它需要网络重新计算每个裁剪图像,这样效率较低。
2.测试时先将网络转化为全卷积网络,第一个全连接层转为7×7的卷积层,后两个全连接层转化为1×1的卷积层。结果得到的是一个N×N×M的结果,称其为类别分数图,其中M等于类别个数,N的大小取决于输入图像尺寸Q,计算每个类别的最终得分时,将N×N上的值求平均,此时得到1×1×M的结果,此结果即为最终类别分数,这种方法文中称为密集评估。这样替换全连接层,就相当于将全连接层应用到了整个未剪裁的图片中,而且得到一个类别的得分图,其通道数等于类别数。
3.我们还通过水平翻转图像来增强测试集,运用原始图片的softmax的后验概率以及其水平翻转的平均来获得图片的得分。
4.测试结果:
单尺度密集评估:
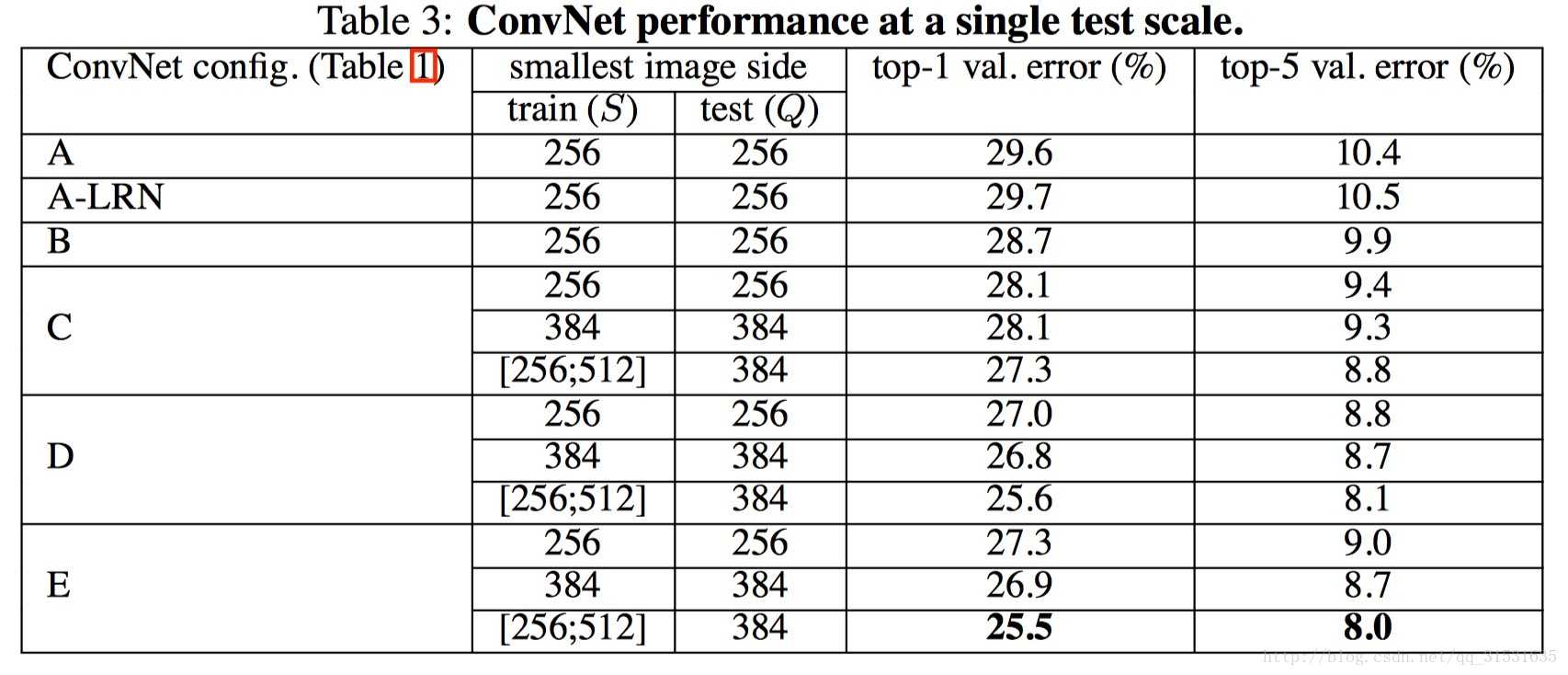
多尺度密集评估:
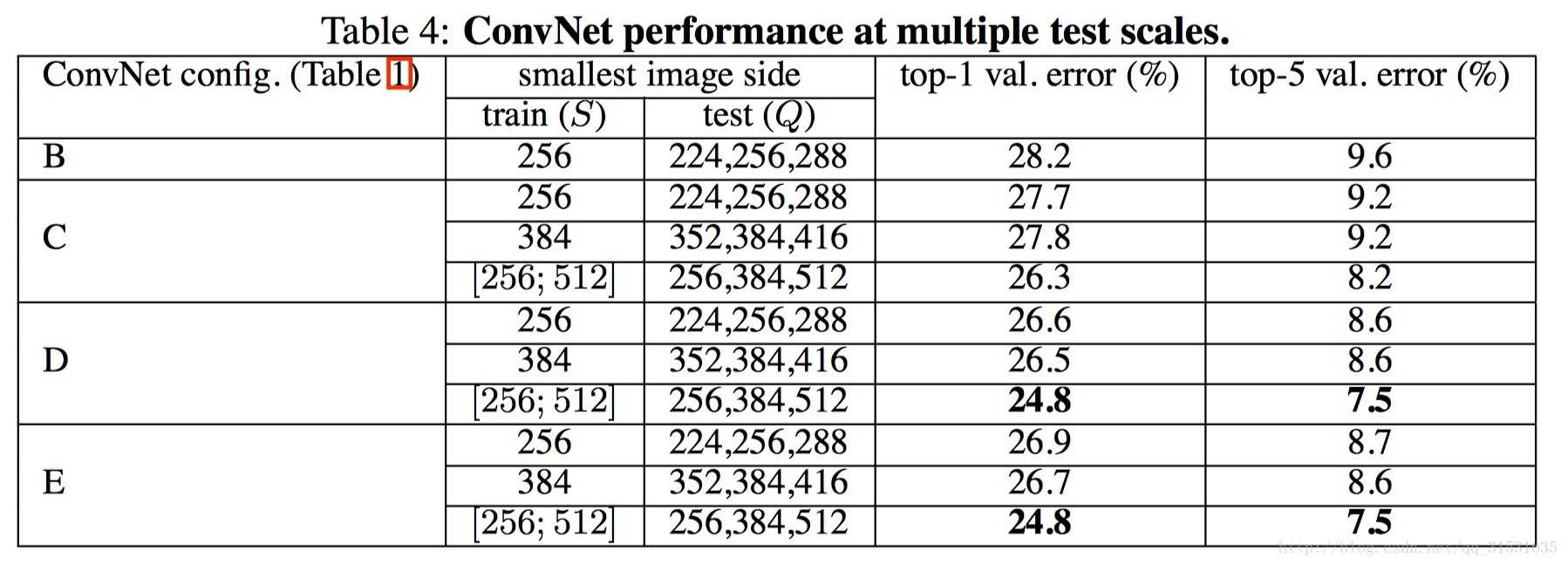
测试过程的补充:
1.上面我们放弃了测试时剪裁图像,但是我们也觉得剪裁图片有一定的效果,因为同时,如Szegedy等人(2014)所做的那样,使用大量的裁剪图像可以提高准确度。
他们成功的原因是:
1.因为与全卷积网络相比,它使输入图像的采样更精细。
2.此外,由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。
2.虽然我们认为在实践中,多裁剪图像的计算时间增加并不足以证明准确性的潜在收益(计算消耗的时间带来了准确性的提高不足以说明它对网络来说是一种增益),但作为参考,我们还在每个尺度使用50个裁剪图像(5×5规则网格,2次翻转)评估了我们的网络,在3个尺度上总共150个裁剪图像。这种测试方法,和训练过程类似,不用将网络转化为全卷积网络,是从Q×Q大小的图中随机裁剪224×224的图作为输入,文中裁剪了50个图像,而每个图像之前缩放为三个尺寸,所以每个图像的测试图像数目变为150个,最终结果就是在150个结果中取平均。
3.再加上原来的密集评估和两者的结合(即两者结果取平均,其能大大增加网络的感受野,因此捕获更多的上下文信息,实验中也发现这种方法表现最好。)
测试结果如下:
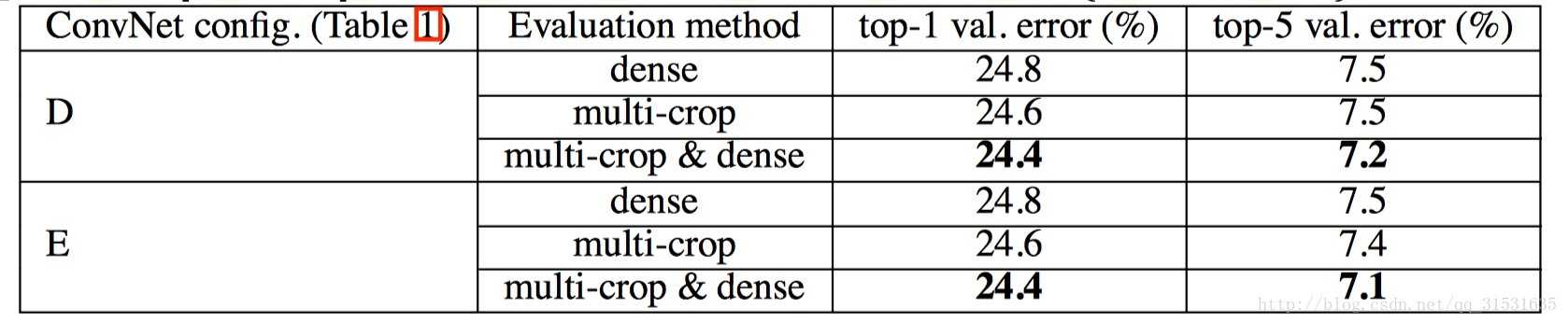
这一结果说明了两种评估方法有一定的互补性。(利用模型的互补性提高模型的性能,这也是现在比赛中参赛者所做的)
模型总结:
1.通过逐步增加网络深度来提高性能,虽然看起来有一点小暴力,没有特别多取巧的,但是确实有效,很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,alnext只有200m,googlenet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
2.虽然每一级网络逐渐变深,但是网络的参数量并没有增长很多(相对而言),这是因为参数量主要都消耗在最后3个全连接层。前面的卷积部分虽然很深,但是消耗的参数量不大,不过训练比较耗时的部分依然是卷积,因其计算量比较大。
对卷积网络深度与宽度上的思考:
1.宽度即卷积核的种类个数,在LeNet那篇文章里我们说了,权值共享可以大大减少我们的训练参数,但是由于使用了同一个卷积核,最终特征个数太少,效果也不会好,所以一般神经网络都会有多个卷积核,这里说明宽度的增加在一开始对网络的性能提升是有效的。但是,随着宽度的增加,对网络整体的性能其实是开始趋于饱和,并且有下降趋势,因为过多的特征(一个卷积核对应发现一种特征)可能对带来噪声的影响。
2.深度即卷积层的个数,对网络的性能是极其重要的,ResNet已经表明越深的深度网络性能也就越好。深度网络自然集成了低、中、高层特征。多层特征可以通过网络的堆叠的数量(深度)来丰富其表达。挑战imagenet数据集的优秀网络都是采用较深的模型。网络的深度很重要,但是否能够简单的通过增加更多的网络层次学习更好的网络?这个问题的障碍就是臭名昭著的梯度消失(爆炸)问题,这从根本上阻碍了深度模型的收敛。
欢迎大家批评指正,讨论学习~
最近在github放了两份分类的代码,分别是用Tensorflow和Pytorch实现的,主要用于深度学习入门,学习Tensorflow和Pytorch搭建网络基本的操作。打算将各网络实现一下放入这两份代码中,有兴趣可以看一看,期待和大家一起维护更新。
代码地址:
Tensorflow实现分类网络
Pytorch实现分类网络
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179459.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
