大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 后台也应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。
它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持.
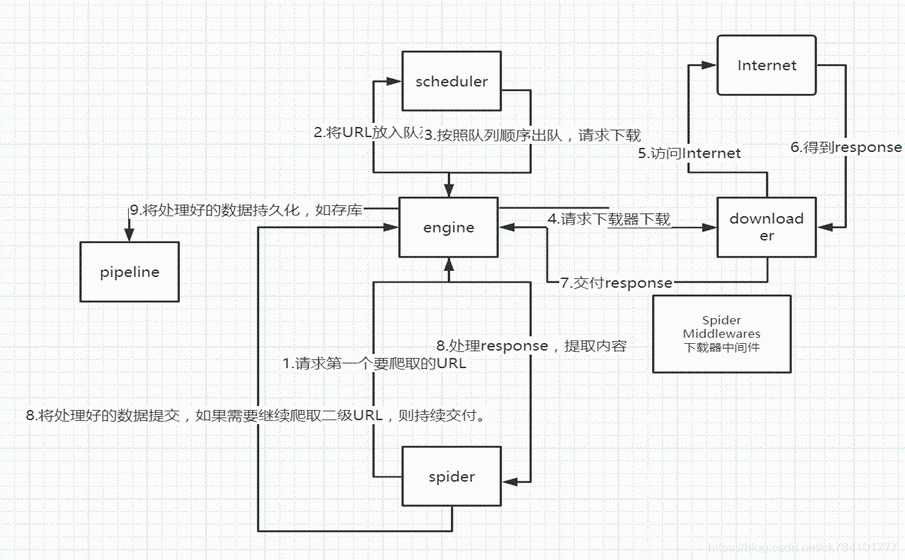
二、Scrapy五大基本构成:
Scrapy框架组件
调度器
下载器
爬虫
实体管道
Scrapy引擎
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
三、整体架构图

四、Scrapy安装以及生成项目
1Scrapy安装
Microsoft Windows [版本 10.0.19043.1586]
(c) Microsoft Corporation。保留所有权利。
C:\WINDOWS\system32>python -m pip install --upgrade pip
C:\WINDOWS\system32>pip install wheel
C:\WINDOWS\system32>pip install lxml
C:\WINDOWS\system32>pip install twisted
C:\WINDOWS\system32>pip install pywin32
C:\WINDOWS\system32>pip install scrapy
2生成项目
scrapy startproject 项目名
scrapy genspider 爬虫名 域名
scrapy crawl 爬虫名
Microsoft Windows [版本 10.0.19043.1586]
(c) Microsoft Corporation。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
New Scrapy project 'TXmovies', using template directory 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project', created in:
C:\WINDOWS\system32\TXmovies
You can start your first spider with:
cd TXmovies
scrapy genspider example example.com
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms v.qq.com
Created spider 'txms' using template 'basic' in module:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>3创建后目录大致页如下
ProjectName #项目文件夹
ProjectName #项目目录
items.py #定义数据结构
middlewares.py #中间件
pipelines.py #数据处理
settings.py #全局配置
spiders
__init__.py #爬虫文件
baidu.py
scrapy.cfg #项目基本配置文件
五、案例
1.创建项目
打开一个终端输入(建议放到合适的路径下,默认是C盘)
Microsoft Windows [版本 10.0.19043.1586]
(c) Microsoft Corporation。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
New Scrapy project 'TXmovies', using template directory 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project', created in:
C:\WINDOWS\system32\TXmovies
You can start your first spider with:
cd TXmovies
scrapy genspider example example.com
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms v.qq.com
Created spider 'txms' using template 'basic' in module:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>2.修改setting
修改三项内容,第一个是不遵循机器人协议,第二个是下载间隙,由于下面的程序要下载多个页面,所以需要给一个间隙(不给也可以,只是很容易被侦测到),第三个是请求头,添加一个User-Agent,第四个是打开一个管道
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'TXmovies.pipelines.TxmoviesPipeline': 300,
}3.确认要提取的数据,item项
item定义你要提取的内容(定义数据结构),比如我提取的内容为电影名和电影描述,我就创建两个变量。Field方法实际上的做法是创建一个字典,给字典添加一个建,暂时不赋值,等待提取数据后再赋值。下面item的结构可以表示为:{‘name’:”,’descripition’:”}。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class TxmoviesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()4.写爬虫程序
我们要写的部分是parse方法里的内容,重点在于如何写xpath,关于xpath我不多讲,有兴趣可以看看我另一篇文章,XPATH教程
引入刚刚写好的item,刚刚说了item里面创建的变量就是字典的键值,可以直接进行赋值。赋值后交给管道处理。
简单讲一下这一段代码的思路,首先腾讯视频的url为https://v.qq.com/x/bu/pagesheet/list?append=1&channel=cartoon&iarea=1&listpage=2&offset=0&pagesize=30
我们注意到offset这一项,第一页的offset为0,第二页为30,依次推列。
在程序中这一项用于控制抓取第一页,但是也要给一个范围,不可能无限大,否则会报错,可以去看看腾讯一共有多少页视频,也可以写一个异常捕获机制,捕捉到请求出错则退出。我这里仅仅是示范,所以只给了120,也就是4页。
yield程序里一共有两个yield,我比较喜欢叫它中断,当然中断只在CPU中发生,它的作用是移交控制权,在本程序中,我们对item封装数据后,就调用yield把控制权给管道,管道拿到处理后return返回,又回到该程序。这是对第一个yield的解释。
第二个yield稍微复杂点,这条程序里利用了一个回调机制,即callback,回调的对象是parse,也就是当前方法,通过不断的回调,程序将陷入循环,如果不给程序加条件,就会陷入死循环,如本程序我把if去掉,那就是死循环了。
yield scrapy.Request(url=url,callback=self.parse)
xpath还有一个要注意的是如何提取xpathl里的数据,我们的写法有四种,第一种写法拿到selector选择器,也就是原数据,里面有一些我们用不到的东西。第二个extract(),将选择器序列号为字符串。第三个和第四个一样,拿到字符串里的第一个数据,也就是我们要的数据。
items['name']=i.xpath('./a/@title')[0]
items['name']=i.xpath('./a/@title').extract()
items['name']=i.xpath('./a/@title').extract_first()
items['name']=i.xpath('./a/@title').get()
# -*- coding: utf-8 -*-
import scrapy
from ..items import TxmoviesItem
class TxmsSpider(scrapy.Spider):
name = 'txms'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/x/bu/pagesheet/listappend=1&channel=cartoon&iarea=1&listpage=2&offse=0&pagesize=30']
offset=0
def parse(self, response):
items=TxmoviesItem()
lists=response.xpath('//div[@class="list_item"]')
for i in lists:
items['name']=i.xpath('./a/@title').get()
items['description']=i.xpath('./div/div/@title').get()
yield items
if self.offset < 120:
self.offset += 30
url = 'https://v.qq.com/x/bu/pagesheet/listappend=1&channel=cartoon&iarea=1&listpage=2&offset={}&pagesize=30'.format(str(self.offset))
yield scrapy.Request(url=url,callback=self.parse)5.交给管道输出
管道可以处理提取的数据,如存数据库。我们这里仅输出。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class TxmoviesPipeline(object):
def process_item(self, item, spider):
print(item)
return item6.run,执行项目
from scrapy import cmdline
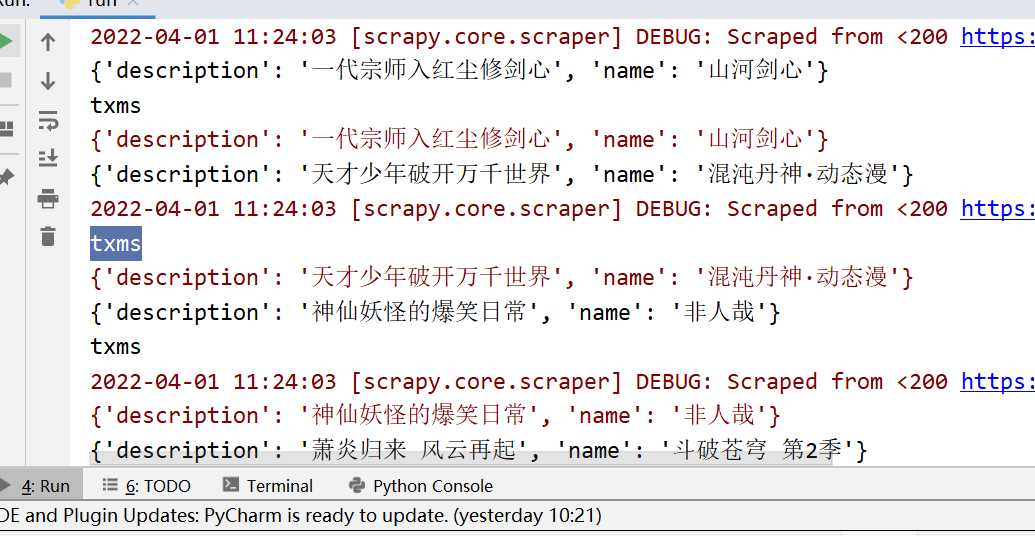
cmdline.execute('scrapy crawl txms'.split())7.测试结果
白色的管道输出的结果,红色的调试信息
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179246.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
