大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在了解覆盖索引之前我们先大概了解一下什么是聚集索引(主键索引)和辅助索引(二级索引)
聚集索引(主键索引):
聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。
聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。
辅助索引(二级索引):
非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值。
再来看看什么是覆盖索引,有下面三种理解:
- 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
- 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
- 解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息


从执行结果上看,这个SQL语句只通过索引,就取到了所需要的数据,这个过程就叫做索引覆盖。
几种优化场景:
1.无WHERE条件的查询优化:
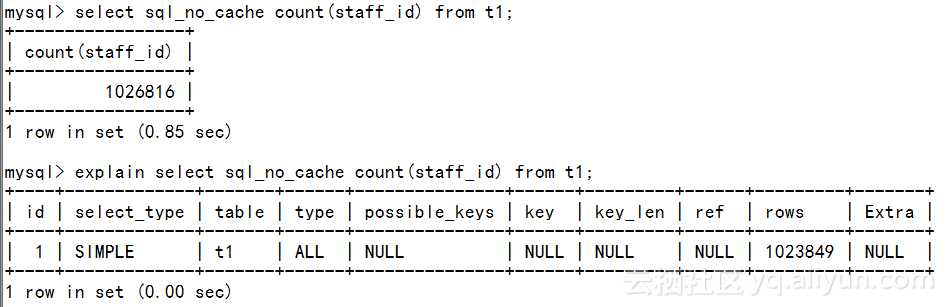
执行计划中,type 为ALL,表示进行了全表扫描
如何改进?优化措施很简单,就是对这个查询列建立索引。如下,
ALERT TABLE t1 ADD KEY(staff_id);- 再看一下执行计划
explain select sql_no_cache count(staff_id) from t1
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: staff_id
key_len: 1
ref: NULL
rows: 1023849
Extra: Using index
1 row in set (0.00 sec)possible_key: NULL,说明没有WHERE条件时查询优化器无法通过索引检索数据,这里使用了索引的另外一个优点,即从索引中获取数据,减少了读取的数据块的数量。 无where条件的查询,可以通过索引来实现索引覆盖查询,但前提条件是,查询返回的字段数足够少,更不用说select *之类的了。毕竟,建立key length过长的索引,始终不是一件好事情。
- 查询消耗
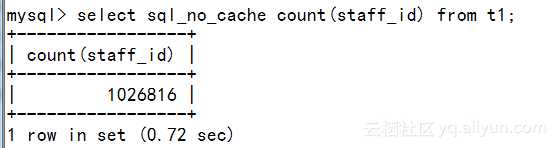
从时间上看,小了0.13 sec
2、二次检索优化
如下这个查询:
select sql_no_cache rental_date from t1 where inventory_id<80000;
…
…
| 2005-08-23 15:08:00 |
| 2005-08-23 15:09:17 |
| 2005-08-23 15:10:42 |
| 2005-08-23 15:15:02 |
| 2005-08-23 15:15:19 |
| 2005-08-23 15:16:32 |
+---------------------+
79999 rows in set (0.13 sec)执行计划:
explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id
key: inventory_id
key_len: 3
ref: NULL
rows: 153734
Extra: Using index condition
1 row in set (0.00 sec)Extra:Using index condition 表示使用的索引方式为二级检索,即79999个书签值被用来进行回表查询。可想而知,还是会有一定的性能消耗的
尝试针对这个SQL建立联合索引,如下:
alter table t1 add key(inventory_id,rental_date);
执行计划:
explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id,inventory_id_2
key: inventory_id_2
key_len: 3
ref: NULL
rows: 162884
Extra: Using index
1 row in set (0.00 sec)Extra:Using index 表示没有会标查询的过程,实现了索引覆盖
3、分页查询优化
如下这个查询场景
select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.75 sec)在未优化之前,我们看到它的执行计划是如此的糟糕
explain select tid,return_date from t1 order by inventory_id limit 50000,10*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1023675
1 row in set (0.00 sec)看出是全表扫描。加上而外的排序,性能消耗是不低的
如何通过覆盖索引优化呢?
我们创建一个索引,包含排序列以及返回列,由于tid是主键字段,因此,下面的复合索引就包含了tid的字段值
alter table t1 add index liu(inventory_id,return_date);
那么,效果如何呢?
select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.03 sec)可以发现,添加复合索引后,速度提升0.7s!
我们看一下改进后的执行计划
explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: liu
key_len: 9
ref: NULL
rows: 50010
Extra: Using index
1 row in set (0.00 sec)执行计划也可以看到,使用到了复合索引,并且不需要回表
对比一下如下的改写SQL,思想是通过索引消除排序
select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
并在此基础上,我们为inventory_id列创建索引,并删除之前的覆盖索引
alter table t1 add index idx_inid(inventory_id); drop index liu;
然后收集统计信息。
select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
+--------+---------------------+
| tid | return_date |
+--------+---------------------+
| 800001 | 2005-08-24 13:09:34 |
| 800002 | 2005-08-27 11:41:03 |
| 800003 | 2005-08-22 18:10:22 |
| 800004 | 2005-08-22 16:47:23 |
| 800005 | 2005-08-26 20:32:02 |
| 800006 | 2005-08-21 14:55:42 |
| 800007 | 2005-08-28 14:45:55 |
| 800008 | 2005-08-29 12:37:32 |
| 800009 | 2005-08-24 10:38:06 |
| 800010 | 2005-08-23 12:10:57 |
+--------+---------------------+这种优化手段较前者时间多消耗了大约140ms。这种优化手段虽然使用索引消除了排序,但是还是要通过主键值回表查询。因此,在select返回列较少或列宽较小的时候,我们可以通过建立复合索引的方式优化分页查询,效果更佳,因为它不需要回表!
4、建了索引但是查询不走索引
表结构:
CREATE TABLE `t_order` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`order_code` char(12) NOT NULL,
`order_amount` decimal(12,2) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uni_order_code` (`order_code`) USING BTREE )
ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;查询语句:
select order_code,order_amount from t_order order by order_code limit 1000; 发现虽然在order_code上建了索引,但是看查询计划却不走索引,为什么呢?因为数据行读取order_amount,所以是随机IO。那怎么办?重新建索引,使用覆盖索引。
ALTER TABLE `t_order` ADD INDEX `idx_ordercode_orderamount` USING BTREE (`order_code` ASC, `order_amount` ASC);这样再查看SQL的执行计划,就发现可以走到索引了。
总结:覆盖索引的优化及限制
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点:
1、索引项通常比记录要小,所以MySQL访问更少的数据。
2、索引都按值得大小存储,相对于随机访问记录,需要更少的I/O。
3、数据引擎能更好的缓存索引,比如MyISAM只缓存索引。
4、覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找了。
限制:
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值。
2、Hash和full-text索引不存储值,因此MySQL只能使用BTree。
3、不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引。
4、如果要使用覆盖索引,一定要注意SELECT列表值取出需要的列,不可以SELECT * ,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
参考文献:
【1】 袋鼠云技术团队博客,https://yq.aliyun.com/articles/62419
【2】MySQL覆盖索引优化,https://yq.aliyun.com/articles/709783
【3】MySQL SQL优化之索引覆盖
【4】 Baron Schwartz等 著,宁海元等 译 ;《高性能MySQL》(第3版); 电子工业出版社 ,2013
来源:mysql-覆盖索引 – 寻找风口的猪 – 博客园 (cnblogs.com)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179234.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
