大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
卡方介绍
卡方检验是针对自变量和因变量都是分类数据,也就是说带有属性的数据;而单因素方差分析是自变量是分类数据,因变量是连续型的数据。还有一点:方差分析是参数检验,而卡方检验是属于非参数检验。
卡方检验是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小:卡方值越大,偏差越大,越趋于不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
案例介绍
本次实验是研究聚类结果和标签DR的关系,即检验我们的聚类有没有意义。标签是0、1区分,聚类是0、1、2区分的
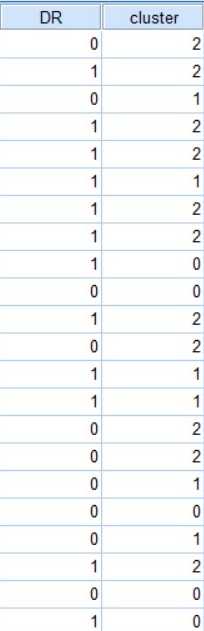

首先我们需要检查他们的交叉表,即
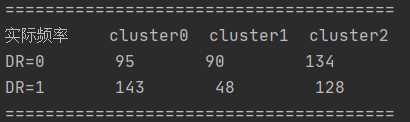
然后我们通过这个表看不出聚类结果的簇间患病差异性大小,因此采用卡方检验,首先做出假设:

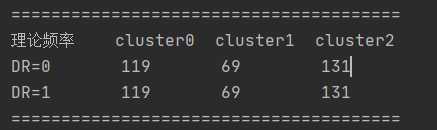
然后计算理论值:
示例:比如cluster0&DR=0的理论值是:sum(cluster0)*sum(DR=0)/总数
然后通过卡方的公式:
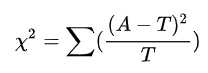
A是实际值,T是理论值,
再计算卡方的 自由度 v:
v=(行数-1)(列数-1)=(2-1)(3-1) = 2
最后根据计算结果查表即可。

卡方临界值 为 (一般取 p=0.05),因此对应表中的结果是5.99,我们的程序结果:
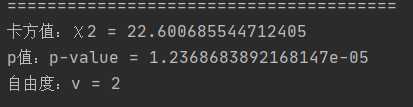
22.6>5.99,因此拒绝0假设,即两个因素之间存在联系。
python实现
程序示例如下:
# -*- encoding: utf-8 -*-
""" @Modify Time 2021/6/26 15:44 @Author Tunan @Filename test1.py @Desciption """
from scipy.stats import chi2_contingency
class CHISQUARE:
def __init__(self, d0, d1):
self.d0 = d0
self.d1 = d1
def get_tabel(self):
dd0 = []
dd1 = []
y0 = sum(self.d0)
y1 = sum(self.d1)
x0 = self.d0[0] + self.d1[0]
x1 = self.d0[1] + self.d1[1]
x2 = self.d0[2] + self.d1[2]
total = y0+y1
dd0.append(x0 * y0 / total)
dd0.append(x1 * y0 / total)
dd0.append(x2 * y0 / total)
dd1.append(x0 * y1 / total)
dd1.append(x1 * y1 / total)
dd1.append(x2 * y1 / total)
return dd0, dd1
def get_classification(self):
print('=======================================')
print('实际频率 cluster0 cluster1 cluster2')
# d0, d1 = [93, 83, 143], [143, 45, 131]
print("DR=0 %(dd0)d %(dd1)d %(dd2)d" % {
'dd0': self.d0[0], 'dd1': self.d0[1], 'dd2': self.d0[2]})
print("DR=1 %(dd0)d %(dd1)d %(dd2)d" % {
'dd0': self.d1[0], 'dd1': self.d1[1], 'dd2': self.d1[2]})
print('=======================================')
print('理论频率 cluster0 cluster1 cluster2')
dd0, dd1 = self.get_tabel()
print("DR=0 %(dd0)d %(dd1)d %(dd2)d" % {
'dd0': dd0[0], 'dd1': dd0[1], 'dd2': dd0[2]})
print("DR=1 %(dd0)d %(dd1)d %(dd2)d" % {
'dd0': dd1[0], 'dd1': dd1[1], 'dd2': dd1[2]})
print('=======================================')
x = [self.d0, self.d1]
chi2, p, df, expected = chi2_contingency(x) # 卡方值、P值、自由度、理论值
print('卡方值:χ2 = %s' % chi2)
print('p值:p-value = %s' % p)
print('自由度:v = %s' % df)
if __name__ == "__main__":
y = [95, 90, 134]
y_pred = [143, 48, 128]
chi = CHISQUARE(y, y_pred)
chi.get_classification()
SPSS实现
第一步:
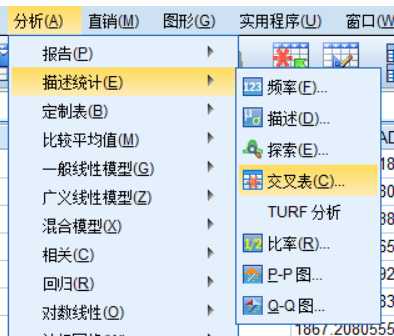
第二步:
选择你要比较的因素,分别加入行和列中:
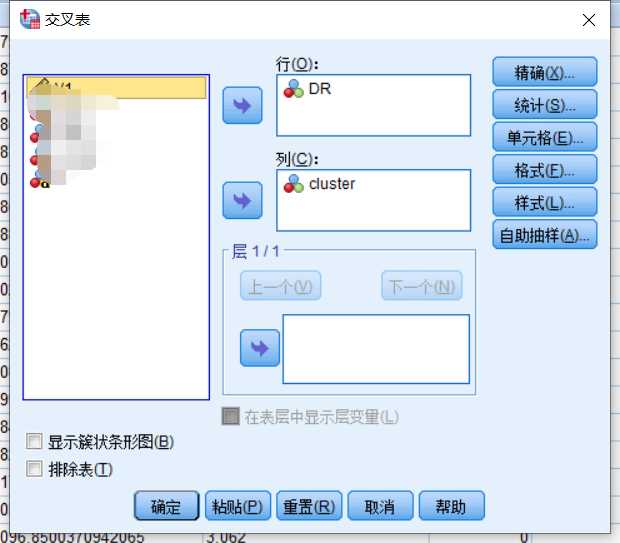
第三步:
在统计选显卡中,选择卡方检验
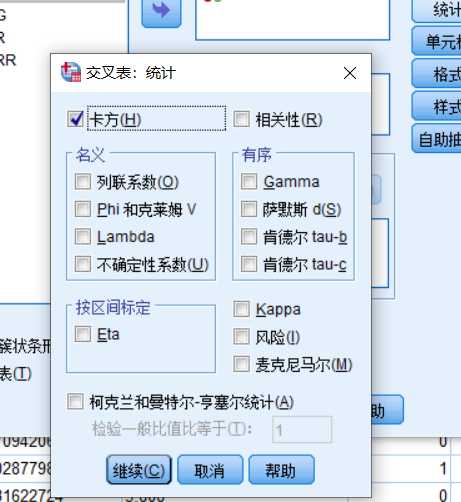
第四步,点击确定,分析结果:
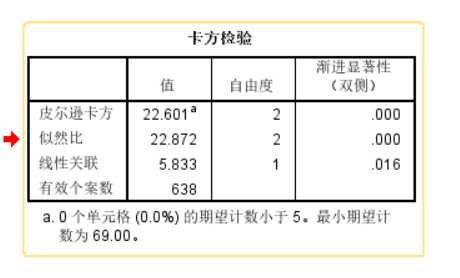
常用的是皮尔逊卡方,他的显著性远小于0.05,因此拒绝原假设,与我们程序分析结果一样。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179198.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
