大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章目录
一、表连接的简介
create table t1(m1 int, n1 char(1));
create table t2(m2 int, n2 char(1));
insert into t1 values(1,'a'),(2,'b'),(3,'c');
insert into t2 values(2,'b'),(3,'c'),(4,'d');
t1表数据如下
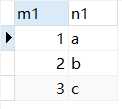

t2表数据如下
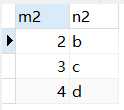
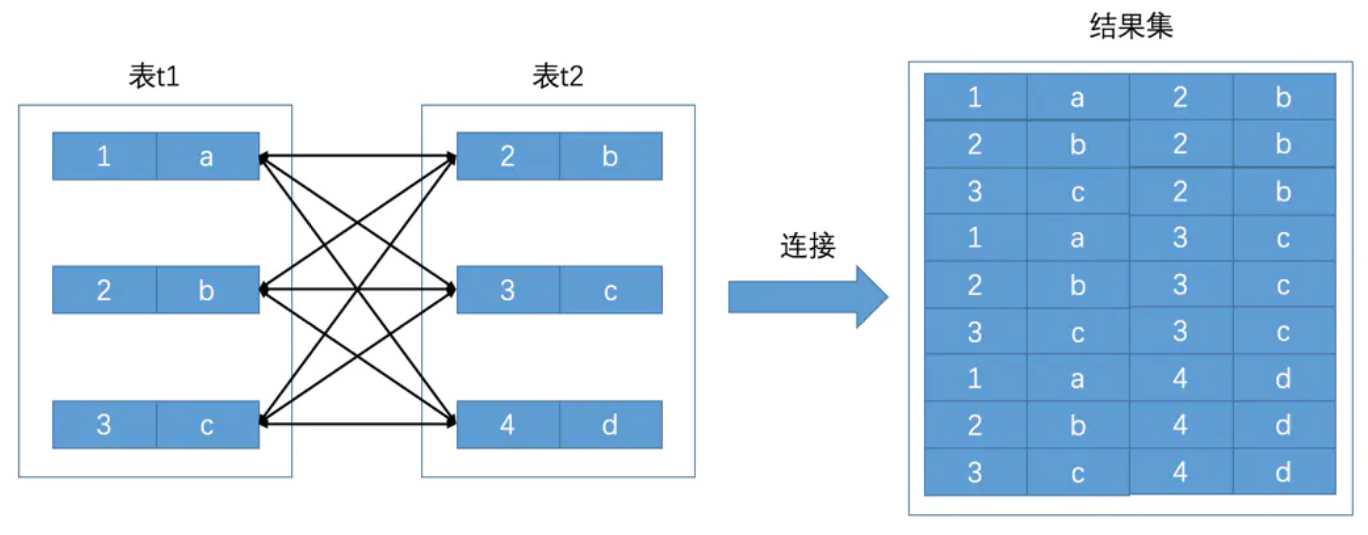
我们知道,所谓表连接就是把各个表中的记录都取出来进行依次匹配,最后把匹配组合的记录一起发送给客户端。比如下面把t1表和t2表连接起来的过程如下图
什么是连接查询?
比如上面t1和t2表的记录连接起来组成一个新的更大的记录,这个查询过程就称为连接查询。
什么是笛卡尔积?
如果连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配组合的记录,那么这样的结果集就可以称为笛卡尔积。
# 这三者效果一样,只要不写条件,就产生笛卡尔积,结果集的数量一样。
select * from t1, t2;
# 内连接
select * from t1 inner join t2;
# 全连接
select * from t1 cross join t2;
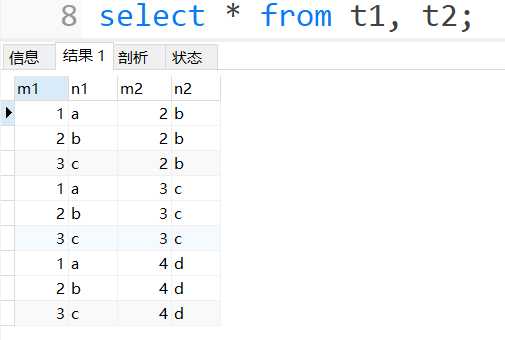
表t1中有3条记录,表t2中也有3条记录,两个表连接后的笛卡尔积就有3 x 3 = 9条记录,只要把两个表的记录数相乘,就能得到笛卡尔积的数量。
二、表连接的过程
笛卡尔积也是一个很大的问题,不加限制条件,结果集的数量就会很大。比如你在开发过程中需要2个表的连接,表1有20000条记录,表2有10000条记录,表3有100条记录,那么3张表连接后产生的笛卡尔积就有20000 x 10000 x 100 = 20000000000条记录(两百亿条记录)。
所以在连接时过滤掉特定的记录组合是很有必要的,为了避免笛卡尔积,一定要在表连接的时候加上条件!
下面来看一下有过滤条件的表连接的执行过程。
# 下面两种写法都一样,执行效率没有区别,看看自己习惯于哪种写法
select * from t1 join t2 on t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 < 'd';
select * from t1, t2 where t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 < 'd';
注意:先说明条件的概念,要区分什么是连接条件和过滤条件!!
连接条件是针对两张表而言的,比如t1.m1 = t2.m2、t1.n1 > t2.n2,表达式两边是两个表的字段比较。
过滤条件是针对单表而言的,比如t1.m1 > 1是针对t1表的过滤条件,t2.n2 < 'd'是针对t2表的过滤条件。
1.首先确定第一个需要查询的表,这个表称之为驱动表。
在单表中选择代价最小的查询方式,简单理解就是走合适的索引即可。此处假设使用t1作为驱动表,那么就需要到t1表中找满足过滤条件t1.m1 > 1的记录,因为表中的数据太少,我们也没在表上建立索引,所以此处查询t1表的查询的方式就是all,也就是采用全表扫描的方式执行单表查询,筛选出符合条件的驱动表记录。
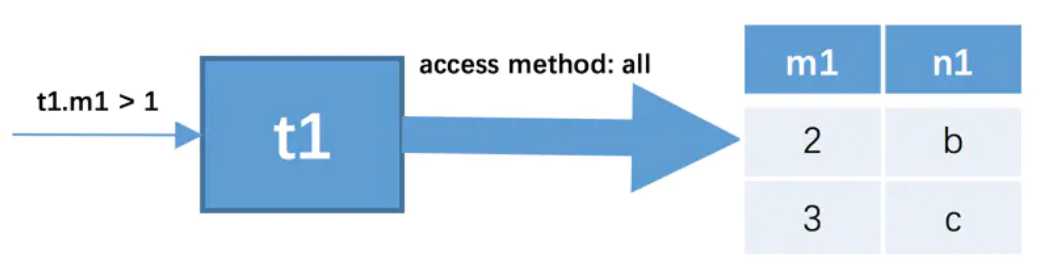
这里筛选出来的t1驱动表记录有2条。
2.从第1步中驱动表筛选出来的每一条记录,都要到t2表中查询匹配记录。
匹配记录就是找到满足连接条件和过滤条件的记录。因为是根据t1表中的记录去找t2表中的记录,所以t2表也可以称为被驱动表。上一步从驱动表筛选出了2条记录,意味着需要从头到尾将t2表查询2次,此时就得看两表之间的连接条件了,这里就是t1.m1 = t2.m2。
对于从t1表查询得到的第一条记录,而这条记录t1.m1=2,根据连接条件t1.m1 = t2.m2,就相当于在t2表加上过滤条件t2.m2 = 2,此时t2表相当于有了两个过滤条件t2.m2 = 2 and t2.n2 < 'd',然后到t2表执行单表查询,每当匹配到满足条件的一条记录后立即返回给MySQL客户端,以此类推。
所以整个连接查询的执行过程如下:
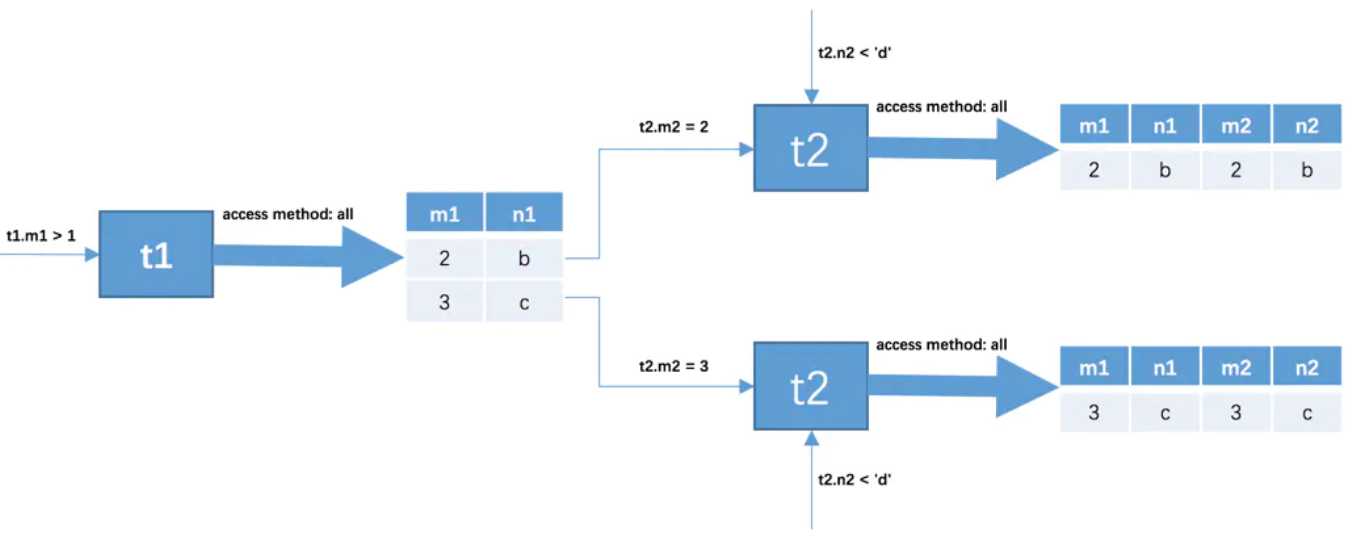
最后连接查询的结果只有2条记录。
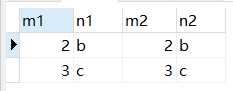
如果把t1.m1 > 1这个过滤条件去掉了,那么从t1表查出的记录就有3条,就需要从头到尾扫3次t2表了。
其实这个流程的套路就是用伪代码说明非常合适,你细品,看懂这个伪代码,你就理解了表连接的步骤。
for 筛选 驱动表 满足条件的每条记录 {
for 筛选 被驱动表 满足条件的每条记录 {
发送到MySQL客户端;
}
}
从这个伪代码可以看出,驱动表的每一条记录都会尝试遍历被驱动表的每条记录并匹配连接,每成功连接一条就返回给MySQL客户端。
总结:
1.在两表连接查询中,驱动表只需访问一次,而被驱动表可能需要访问多次。
2.并不是将所有满足过滤条件的驱动表记录先查询出来放到一个地方,然后再去被驱动表查询的(因为如果满足过滤条件的驱动表很大,需要的临时存储空间就会非常大)。而是每获得一条满足过滤条件的驱动表记录,就立即到被驱动表中查询匹配的记录。
三、内连接和外连接
1.内连接
上面第二节所讲的,都是内连接。
先建立2张表,后续根据这2张表来讲解。
CREATE TABLE student (
stu_no INT NOT NULL AUTO_INCREMENT COMMENT '学号',
name VARCHAR(5) COMMENT '姓名',
major VARCHAR(30) COMMENT '专业',
PRIMARY KEY (stu_no)
) Engine=InnoDB CHARSET=utf8mb4 COMMENT '学生信息表';
CREATE TABLE score (
stu_no INT COMMENT '学号',
subject VARCHAR(30) COMMENT '科目',
score TINYINT COMMENT '成绩',
PRIMARY KEY (stu_no, subject)
) Engine=InnoDB CHARSET=utf8mb4 COMMENT '学生成绩表';
插入一些数据
insert into student values(20210901, '王大个', '软件工程');
insert into student values(20210902, '刘帅哥', '物联网工程');
insert into student values(20210903, '张小伟', '电子工程');
insert into score values(20210901, '数据结构', 92);
insert into score values(20210901, '计算机网络', 94);
insert into score values(20210902, '计算机网络', 88);
insert into score values(20210902, '数据结构', 80);
student表数据如下:
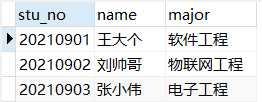
score表数据如下:
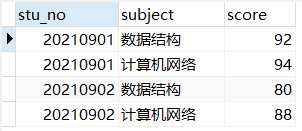
如果想要把学生的成绩都查出来,就需要表连接(score表中没有姓名,所以不能只查score表),连接过程就是从student表取出记录,然后在score表中查找number相同的成绩记录,连接条件是student.stu_no= score.stu_no;
select * from student join score where student.stu_no = score.stu_no;
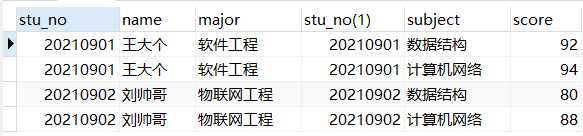
表连接的全部字段就在这里了,字段有点多,stu_no是重复的,我们修改一下
select s1.stu_no, s1.name, s2.subject, s2.score from student as s1 join score as s2 on s1.stu_no = s2.stu_no;

可以看到,学生的各科成绩都被查出来了。但是张小伟(学号为20210903的同学)因为缺考,在score表中没有记录。要是老师想查看所有学生的成绩(包括缺考的同学)该怎么办呢?也就是说,哪怕成绩为空,也要显示这位同学在这个表里面,咱们不能把他给踢了吧!
这个问题就化为这个模型:对于驱动表中的某条记录,哪怕根据连接条件或者过滤条件在被驱动表中没有找到对应的记录,也还是要把该驱动表的记录加到结果集。
这就是内连接的局限性。
其实我们想要看到的结果集是这样的
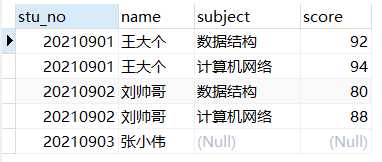
为了解决这个问题,就有了内连接和外连接的区别。
对于内连接来说,若驱动表中的记录按照连接条件或者过滤条件在被驱动表中找不到匹配的记录,则该记录不会加入到最后的结果集。
前面提到的都是内连接,比如前面例子中,当t1.m1 = 2时,根据连接条件t1.m1 = t2.m2,在被驱动表中如果没有记录满足过滤条件t2.m2 = 2 and t2.n2 < 'd',驱动表的记录就不会加到最后的结果集。
注意:我们说过,内连接语法有很多种。对于内连接来说,连接条件选择on或者where都可以,凡是不符合on子句或者where子句条件的记录都会被过滤掉,不会被连接,更不会在最后的结果集。
# 以下三者效果一样,当用join进行内连接时,条件用on或者where连接都可以。
select * from student join score on student.stu_no= score.stu_no;
select * from student join score where student.stu_no= score.stu_no;
select * from student, score where student.stu_no= score.stu_no;
2.外连接
对于外连接来说,即使驱动表中的记录按照连接条件和过滤条件在被驱动表中找不到匹配的记录,该记录也仍然需要加入到结果集。
对于外连接来说,又有左(外)连接和右(外)连接的区别
左(外)连接:选取左侧的表为驱动表。
右(外)连接:选取右侧的表为驱动表。
重点强调:对于内连接来说,选取哪个表为驱动表都没关系。而外连接的驱动表是固定的,左(外)连接的驱动表就是左边那个表,右(外)连接的驱动表就是右边那个表。
左(外)连接的语法:
比如要把t1表和t2表进行左连接查询。
select * from t1
left [outer] join t2
on 条件
[where 普通过滤条件]
# 注意这个on条件包括连接条件和驱动表与被驱动表的单表过滤条件。
# []括号代表可以省略
左表所有记录都会有,右表没有与之匹配的则用NULL填充。
对于外连接来说,on和where是有区别的。
即使被驱动表中的记录无法匹配on子句的条件,该驱动表的记录仍然是满足条件的一条记录,对应被驱动表的各个字段用NULL填充。
简言之,对于外连接,驱动表的记录一定都有,被驱动表不匹配就用NULL填充。
而where过滤条件是在记录连接过后的普通过滤条件,即连接的记录会再次判断是否符合条件,不符合就从结果集中剔除。
回到刚刚的问题,要把所有学生成绩显示出来(包括缺考的学生)
select s1.stu_no, s1.name, s2.subject, s2.score from student as s1
left join
score as s2
on s1.stu_no = s2.stu_no;
从上面结果集可以看出,虽然张小伟缺考,但是还是在结果集中,只不过对应的科目成绩用NULL填充。
右(外)连接的语法
select * from t1
right [outer] join t2
on 条件
[where 普通过滤条件]
# 注意这个on条件包括连接条件和驱动表与被驱动表的单表过滤条件。
# []括号代表可以省略
右连接中,驱动表是右边的表,被驱动表是左边的表,右表所有记录都会有,左表没有与之匹配的则用NULL填充。这里就不举例了。
四、表连接的原理
1.简单的嵌套循环连接(Simple Nested-Loop Join)
我们前边说过,对于两表连接来说,驱动表只会访问一遍,但被驱动表要被访问到好多遍,具体访问几遍取决于驱动表执行单表查询后满足条件的记录条数。
假设t1表和t2表都没有索引,t1表和t2表内连接的大致过程如下:
步骤1:选取驱动表t1,使用与驱动表t1相关的过滤条件,选取成本最低的单表访问方法来执行对驱动表的单表查询。(根据你的索引和记录数量,查询优化器会选择成本最低的访问方法,这里没有索引则全表扫描)
步骤2:对上一步中查询驱动表得到的每一条满足条件的记录,都分别到被驱动表t2中查找匹配的记录。
具体细节在第二节说过,这里就不细致展开。
如果有第3个表t3进行连接的话,那么总体查询过程就是,查找t1表满足单表过滤条件的第一条记录,匹配连接t2表满足单表过滤条件的第一条记录(此时驱动表是t1,被驱动表是t2),然后匹配连接t3表满足单表过滤条件的第1条记录(此时驱动表是t2,被驱动表是t3),将这条满足所有条件的一条记录返回给MySQL客户端;前面条件不变,接着匹配连接t3表满足单表过滤条件的第2条记录…
这个过程最适合用伪代码来说明了
for 筛选t1表满足条件的每条记录 {
for 筛选t2表满足条件的每条记录 {
for 筛选t3表满足条件的每条记录 {
发送到MySQL客户端;
}
}
}
这个过程就像是一个嵌套的循环,驱动表每一条记录,都要从头到尾扫描一遍被驱动表去尝试匹配。这种连接执行方式称之为简单的嵌套循环连接(Simple Nested-Loop Join),这是比较笨拙的一种连接查询算法。
注意:对于嵌套循环连接算法来说,每当从驱动表获得一条记录,就根据这条记录立即到被驱动表查一次,如果得到匹配连接记录,那就把这条连接的记录立即发送给MySQL客户端,而不是等查询完所有结果后才返回。然后再到被驱动表获取下一条符合条件的记录,直到被驱动表遍历完成,就切换到驱动表的下一条记录再次遍历被驱动表的每条记录,以此类推。
2.基于索引的嵌套循环连接(Index Nested-Loop Join)
在上一小节嵌套循环连接的步骤2中可能需要访问多次被驱动表,如果访问被驱动表的方式都是全表扫描,扫描次数就非常多。
幸好MySQL优化器会找出所有可以用来执行该语句的方案,并会对比之后找出成本最低的方案,简单理解就是使用哪个索引最好。所以既然会多次访问被驱动表,索引好不好就是性能的瓶颈。
查询被驱动表其实就相当于一次单表扫描,那么我们可以利用索引来加快查询速度。
回到最开始介绍的t1表和t2表进行内连接的例子:
select * from t1 join t2 on t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 < 'd';
这其实是嵌套循环连接算法执行的连接查询,再把上边那个查询执行过程拿下来给大家看一下:
查询驱动表t1后的结果集中有2条记录,嵌套循环连接算法需要查询被驱动表2次:
当t1.m1 = 2时,去查询一遍t2表,对t2表的查询语句相当于:
select * from t2 where t2.m2 = 2 and t2.n2 < 'd';
当t1.m1 = 3时,再去查询一遍t2表,此时对t2表的查询语句相当于:
select * from t2 where t2.m2 = 3 and t2.n2 < 'd';
可以看到,原来的t1.m1 = t2.m2这个涉及两个表的过滤条件在针对t2表进行查询时,选出t1表的一条记录之后,t2表的条件就已经确定了,即t2.m2 = 常数值,所以我们只需要优化对t2表的查询即可,上述两个对t2表的查询语句中利用到的列是m2和n2列,我们可以进行如下尝试:
-
在
m2列上建立索引,因为对m2列的条件是等值查找,比如t2.m2 = 2、t2.m2 = 3等,所以可能使用到ref的访问方法,假设使用ref的访问方法去执行对t2表的查询的话,需要回表之后再判断t2.n2 < 'd'这个条件是否成立。 -
在
n2列上建立索引,涉及到的条件是t2.n2 < 'd',可能用到range的访问方法,假设使用range的访问方法对t2表进行查询,需要在回表之后再判断在m2列的条件是否成立。
假设m2和n2列上都存在索引,那么就需要从这两个里面挑一个代价更低的索引来查询t2表。也有可能不使用m2和n2列的索引,只有在非聚集索引 + 回表的代价比全表扫描的代价更低时才会使用索引。
Index Nested-Loop Join与Simple Nested-Loop Join的不同就是被驱动表加了索引,后面只说Index Nested-Loop Join。
扩展思考:假设驱动表全表扫描,行数是
N,被驱动表走索引,行数是M。那么
- 1.每次在被驱动表查一行数据,则要先搜索索引,再回表查找主键索引。
- 2.每次被驱动表查找次数是以
2为底的M的对数,记为log M,所以在被驱动表上查一行的扫描次数是2*log M(因为要回表查找利用到主键索引)。 驱动表执行过程就要扫描驱动表N行,然后对于每一行,到被驱动表上匹配一次。因此整个执行过程,查找的总次数是N+N*2*log M。- 3.显然
N对扫描行数的影响更大,因此应该让小表来做驱动表。N扩大1000倍的话,扫描行数就会扩大1000倍;而M扩大1000倍,扫描行数扩大不到10倍。总结:如果被驱动表可以使用索引,那么驱动表一定要选择数据量小的小表。
3.基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。
实际开发中的表可不像t1、t2这种只有3条记录,几千万甚至几亿条记录的表到处都是。现在假设我们不能使用索引加快被驱动表的查询过程,所以对于驱动表的每一条记录,都需要对被驱动表进行全表扫描。而对被驱动表全表扫描时,可能表前面的记录还在内存中,表后边的记录可能还在磁盘上。等扫描到后边记录的时候,可能由于内存不足,所以需要把表前面的记录从内存中释放掉给正在扫描的记录腾地方,这样就非常消耗性能。
采用嵌套循环连接算法的两表连接过程中,被驱动表是要被访问好多次的,所以我们得想办法,尽量减少被驱动表的访问次数。
驱动表中满足筛选条件的有多少条记录,就得把被驱动表中的所有记录从磁盘上加载到内存中多少次。
读磁盘代价太大,能不能在内存中操作呢?于是一个Join Buffer(连接缓冲区)的概念就出现了,Join Buffer就是执行连接查询前申请的一块固定大小的内存(默认256K),先把满足条件的若干条驱动表的记录装在这个Join Buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性与Join Buffer中的所有记录进行匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。使用Join Buffer的过程如下图所示:
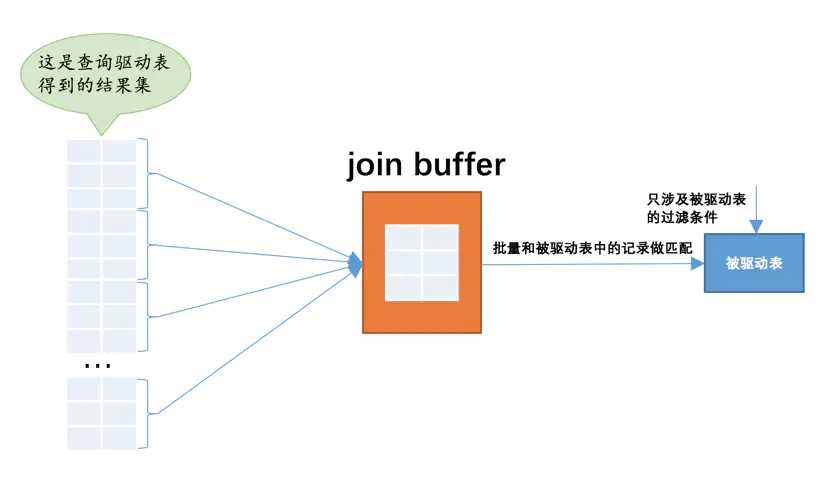
为什么Join Buffer要装驱动表而不是被驱动表呢?上面说过,小表作为驱动表,Join Buffer装小表更容易装得下,下一节会讲这个原因。
其实很好记忆,想想笛卡尔积顺序也很奇妙。笛卡尔积的顺序就是一条被驱动表记录匹配多条驱动表记录的顺序,而不是一条驱动表记录去匹配被驱动表的记录的顺序,你看看这个顺序是不是很神奇,可以自行键两张表连接看看笛卡尔积,观察一下。
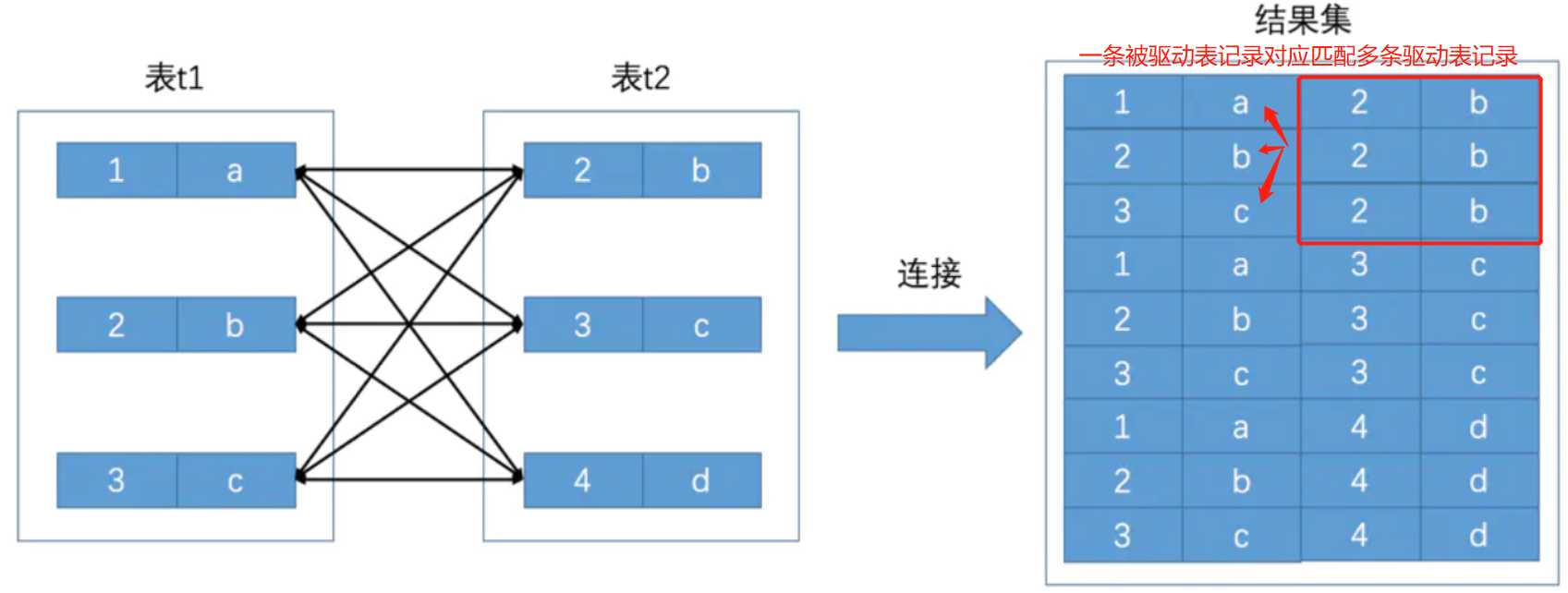
笛卡尔积顺序是
1 a 2 b
2 b 2 b
3 c 2 b
.....
而不是
1 a 2 b
1 a 3 c
1 a 4 d
...
你发现了吗?
其实最好的情况是Join Buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。这种加入了Join Buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
这个Join Buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节。对于被驱动表,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,只有满足条件的select中的列才会被放到Join Buffer中,所以再次提醒我们,最好不要把*作为查询列表,这样还可以在Join Buffer中放置更多的记录。
4.Nested-Loop Join和Block Nested-Loop Join对比说明
假设t1表的行数是N,t2表的行数是M,t1表是小表,即N < M
Simple Nested-Loop Join算法:
- 驱动表的每一条记录都会去被驱动表逐一匹配,所以总的扫描行数是
N * M(开头说了,扫描表就是把表从磁盘加载到内存中); - 内存中的判断次数是
N * M(扫描一次就会在内存中判断一次)。
别纠结了,这种方法太笨了,不管选择哪个表作为驱动表,最后扫描和内存中判断的成本都是一样的。
Index Nested-Loop Join算法
该算法被驱动表的查询条件字段加上了合适的索引。
- 驱动表的每一条记录都会去被驱动表逐一匹配,所以总的扫描行数是
N * log M(扫描行数不变,但是因为被驱动表有索引,扫描速度会大大增加); - 内存中的判断次数是
M * N(扫描一次就会在内存中判断一次)。
Block Nested-Loop Join算法:
该算法又得区分Join Buffer装得下和装不下的情况。
Join Buffer装得下的情况
t1表和t2表都做一次全表扫描,将t1表记录都装入Join Buffer,总的扫描行数是M + N(开头说了,扫描表就是把表从磁盘加载到内存中,驱动表扫描M行一次性装到Join Buffer,被驱动表扫描一行会在Join Buffer进行比较,最终扫描N行);- 内存中的判断次数是
M * N,由于Join Buffer是以无序数组的方式组织的,因此对t2表中的每一行数据,都要与Join Buffer中的记录相比较。
可以看到,调换这两个算式中的M和N没差别,因此这时候选择t1还是t2表做驱动表,成本都是一样的。
Join Buffer装不下的情况
我们先用直观的数据说明过程,假如表t1是100行,而Join Buffer放不下,此时就分段放,执行过程就变成了:
- 扫描表
t1,顺序读取数据行放入Join Buffer中,放完第80行Join Buffer满了,继续第2步; - 扫描表
t2,把t2中的每一行取出来,跟Join Buffer中的所有记录做对比,满足join条件的,返回该条记录给MySQL客户端; - 清空
Join Buffer; - 继续扫描表
t1,顺序读取最后的20行数据放入Join Buffer中,继续执行第2步。
这个流程体现出了这个算法名字中“Block”的由来,表示“分块的join”。
现在总结一下这个过程。驱动表t1的数据行数是N,假设需要分K次才能完成算法流程,被驱动表t2的数据行数是M。
注意,这里的K不是常数,N越大K就会越大。所以,在这个执行过程中:
- 扫描行数是
N + K * M,每次装完一次Join Buffer,被驱动表t2的M条记录就会从头到尾去Join Buffer匹配,Join Buffer需要装K次,则扫描K次t2表; - 内存判断
N * M次,由于Join Buffer是以无序数组的方式组织的,因此对t2表中的每一行数据,都要与Join Buffer中的记录相比较。
显然,内存判断次数是不受选择哪个表作为驱动表影响的。而扫描行数考虑到Join Buffer的大小,在M和N大小确定的情况下,驱动表的数据行数N小一些,则分段K就少一些,那么整个表达式的结果会更小。
总结:如果
Join Buffer能装任意一张表里的所有数据,那么不管选择哪个表作为驱动表,执行成本都一样。对于Join Buffer一次装不下驱动表的情况下,应该让小表当驱动表,因为小表记录总行数N越小,Join Buffer装完所需的次数K就越小,在N + K * M这个式子里,表达式的值越小。
刚刚我们说了N越大,分段数K越大。那么N固定的时候,什么参数会影响K的大小呢?答案是join_buffer_size。join_buffer_size越大,Join Buffer中一次可以放入的行越多,分成的段数K也就越少,对被驱动表的全表扫描次数就越少。
join_buffer_size默认256K,我所在的公司配置的是4M。
1.不能使用被驱动表的索引,只能使用
Block Nested-Loop Join算法,这样的语句就尽量不要使用
2.Explain下,没用Index Nested-Loop的全要优化
综上:从上面1234小节来看,无论哪种情况,总是应该选择小表作为驱动表。并且两张表有个各自的索引,这样表连接才能达到更好的性能。在内连接中,你可以使用STRAIGHT_JOIN替换JOIN,这样在内连接中就是强制左表为驱动表。
欢迎一键三连~
有问题请留言,大家一起探讨学习
———————-Talk is cheap, show me the code———————–
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179040.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
