大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc。
目录
loc:通过行、列的名称或标签来索引
iloc:通过行、列的索引位置来寻找数据
首先,我们先创建一个Dataframe,生成数据,用于下面的演示
import pandas as pd
import numpy as np
# 生成DataFrame
data = pd.DataFrame(np.arange(30).reshape((6,5)),
columns=['A','B','C','D','E'])
# 写入本地
data.to_excel("D:\\实验数据\\data.xls", sheet_name="data")
print(data)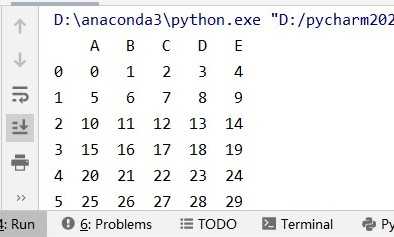

1.loc方法
loc方法是通过行、列的名称或者标签来寻找我们需要的值。
(1)读取第二行的值
# 索引第二行的值,行标签是“1”
data1 = data.loc[1]
结果:

备注: #下面两种语法效果相同 data.loc[1] == data.loc[1,:]
(2)读取第二列的值
# 读取第二列全部值
data2 = data.loc[ : ,"B"]结果:

(3)同时读取某行某列
# 读取第1行,第B列对应的值
data3 = data.loc[ 1, "B"]结果:

(4)读取DataFrame的某个区域
# 读取第1行到第3行,第B列到第D列这个区域内的值
data4 = data.loc[ 1:3, "B":"D"]结果:

(5)根据条件读取
# 读取第B列中大于6的值
data5 = data.loc[ data.B > 6] #等价于 data5 = data[data.B > 6]结果:
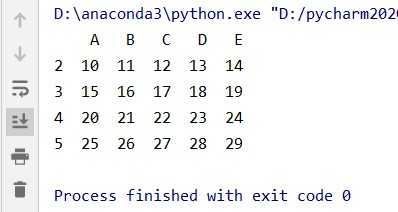
(6)也可以进行切片操作
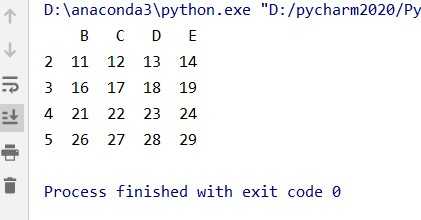
# 进行切片操作,选择B,C,D,E四列区域内,B列大于6的值
data1 = data.loc[ data.B >6, ["B","C","D","E"]]结果:
2.iloc方法
iloc方法是通过索引行、列的索引位置[index, columns]来寻找值
(1)读取第二行的值
# 读取第二行的值,与loc方法一样
data1 = data.iloc[1]
# data1 = data.iloc[1, :],效果与上面相同结果:
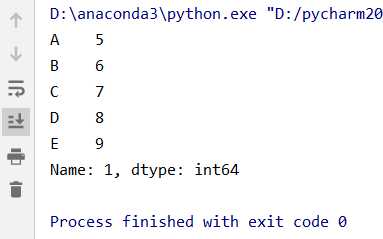
(2)读取第二列的值
# 读取第二列的值
data1 = data.iloc[:, 1]
结果:
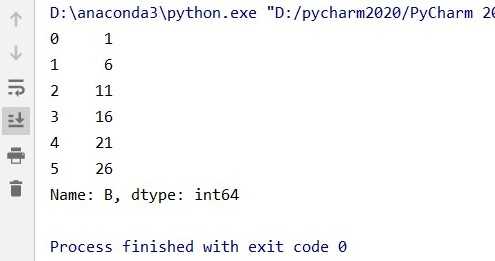
(3)同时读取某行某列
# 读取第二行,第二列的值
data1 = data.iloc[1, 1]结果:

(4)进行切片操作
# 按index和columns进行切片操作
# 读取第2、3行,第3、4列
data1 = data.iloc[1:3, 2:4]结果:
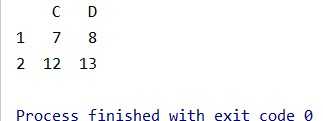
注意:
这里的区间是左闭右开,data.iloc[1:3, 2:4]中的第4行、第5列取不到
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/178799.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
