大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、需求背景
在互联网数据化运营实践中,有一类数据分析应用是互联网行业所独有的——路径分析。路径分析应用是对特定页面的上下游进行可视化展示并分析用户在使用产品时的路径分布情况。比如:当用户使用某APP时,是怎样从【首页】进入【详情页】的,用户从【首页】分别进入【详情页】、【播放页】、【下载页】的比例是怎样的,以及可以帮助我们分析用户离开的节点是什么。
在场景对应到具体的技术方案设计上,我们将访问数据根据session划分,挖掘出用户频繁访问的路径;功能上允许用户即时查看所选节点相关路径,支持用户自定义设置路径的起点或终点,并支持按照业务新增用户/活跃用户查看不同目标人群在同一条行为路径上的转化结果分析,满足精细化分析的需求。
1.1 应用场景
通常用户在需要进行路径分析的场景时关注的主要问题:
- 按转换率从高至低排列在APP内用户的主要路径是什么;
- 用户在离开预想的路径后,实际走向是什么?
- 不同特征的用户行为路径有什么差异?
通过一个实际的业务场景我们可以看下路径分析模型是如何解决此类问题的;
【业务场景】
分析“活跃用户”到达目标落地页[小视频页]的主要行为路径(日数据量为十亿级,要求计算结果产出时间1s左右)
【用户操作】
-
选择起始/结束页面,添加筛选条件“用户”;
-
选择类型“访问次数”/“会话次数”;
-
点击查询,即时产出结果。

二、基本概念
在进行具体的数据模型和工程架构设计前,先介绍一些基础概念,帮助大家更好的理解本文。
2.1 路径分析
路径分析是常用的数据挖据方法之一, 主要用于分析用户在使用产品时的路径分布情况,挖掘出用户的频繁访问路径。与漏斗功能一样,路径分析会探索用户在您的网站或应用上逗留的过程中采取的各项步骤,但路径分析可随机对多条路径进行研究,而不仅仅是分析一条预先设定的路径。
2.2 Session和Session Time
不同于WEB应用中的Session,在数据分析中的Session会话,是指在指定的时间段内在网站上发生的一系列互动。本模型中的Session Time的含义是,当两个行为间隔时间超过Session Time,我们便认为这两个行为不属于同一条路径。
2.3 桑基图
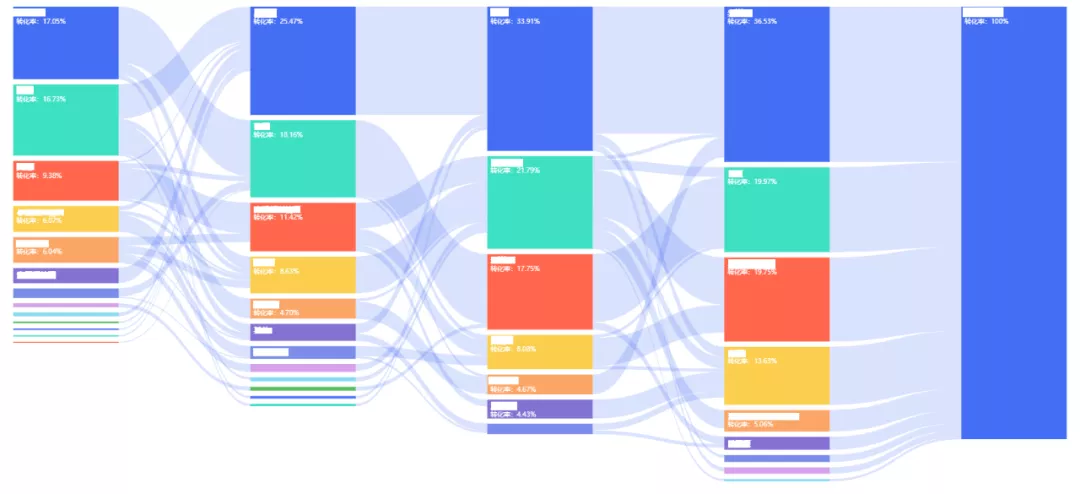
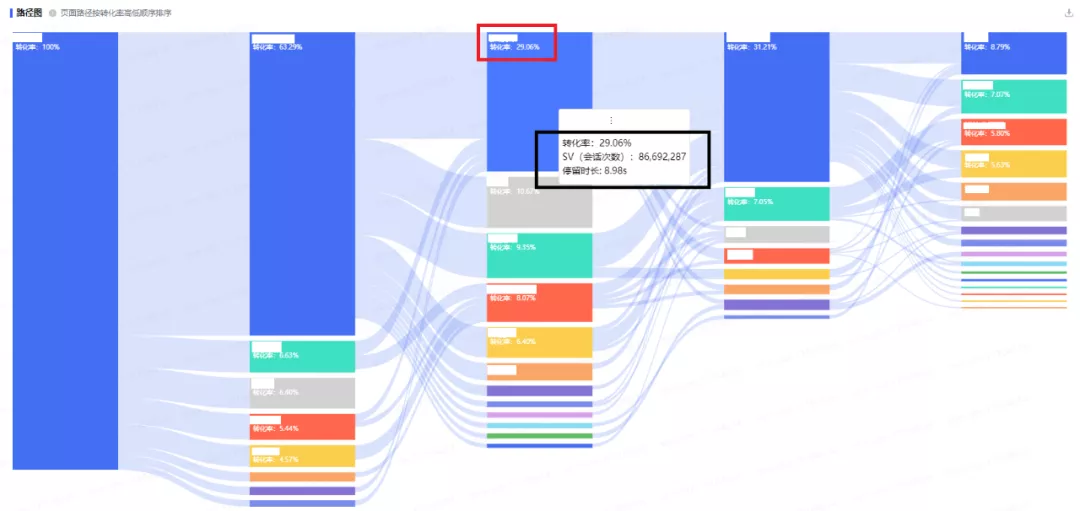
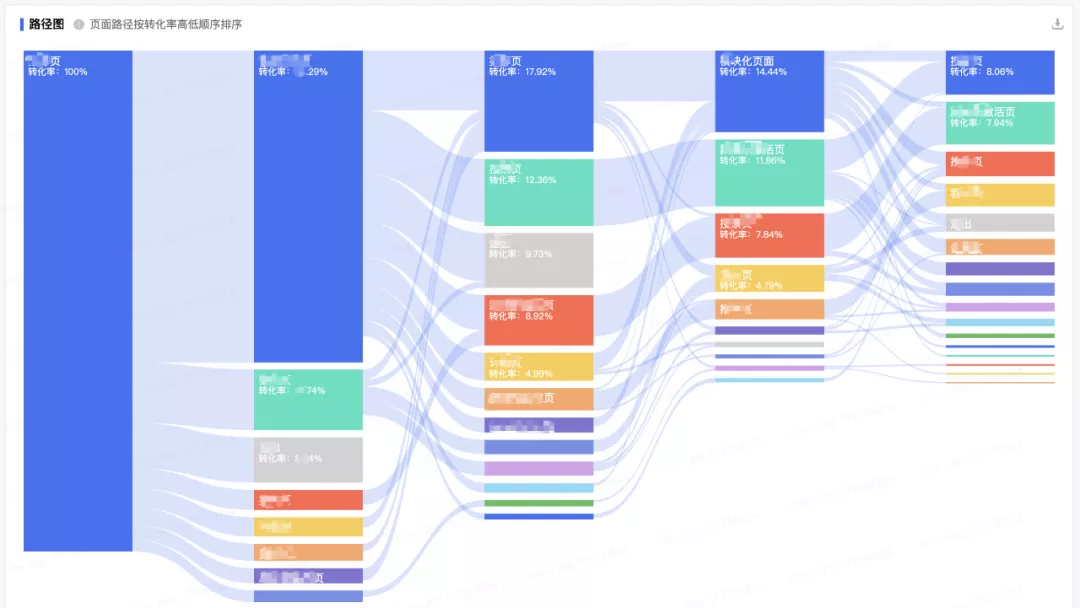
桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图。它是一种特定类型的流程图,图中延伸的分支的宽度对应数据流量的大小。如图4.1-1所示,每条边表示上一节点到该节点的流量。一个完整的桑基图包括以下几个内容:节点数据及节点转化率(下图红框部分)、边数据及边转化率(下图黑框部分)。转化率的计算详见【3.5. 转化率计算】。
2.4 邻接表
构造桑基图可以简化为一个图的压缩存储问题。图通常由几个部分组成:
- 边(edge)
- 点(vertex)
- 权重(weight)
- 度(degree)
本模型中,我们采用邻接表进行存储。邻接表是一种常用的图压缩存储结构,借助链表来保存图中的节点和边而忽略各节点之间不存在的边,从而对矩阵进行压缩。邻接表的构造如下:
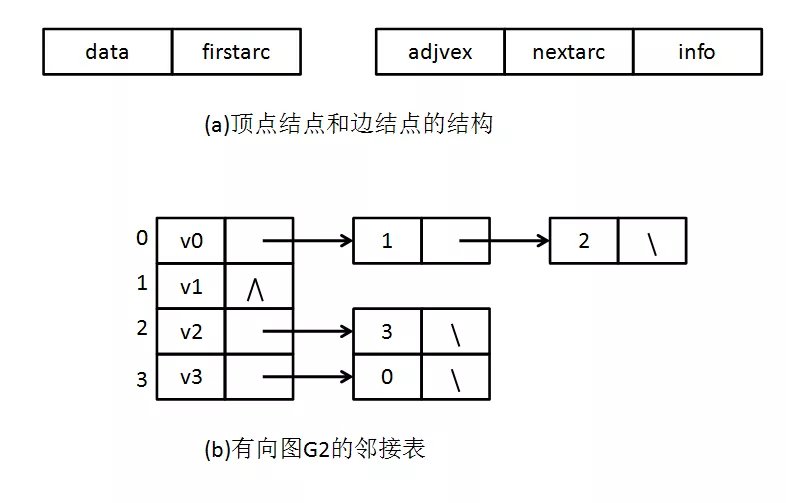
(a)中,左侧为顶点节点,包含顶点数据及指向第一条边的指针;右侧为边节点,包含该边的权重、出入度等边信息以及指向下一条边的指针。一个完整的邻接表类似于Hashmap的结构,如图(b),左侧是一个顺序表,保存的是(a)中的边节点;每个边节点对应一个链表存储与该节点相连接的边。页面路径模型中,为了适应模型的需要,我们对顶点节点和边节点结构做了改造,详情请见【4.1】节。
2.5 树的剪枝
剪枝是树的构造中一个重要的步骤,指删去一些不重要的节点来降低计算或搜索的复杂度。页面路径模型中,我们在剪枝环节对原始数据构造的树进行修整,去掉不符合条件的分支,来保证树中每条根节点到叶节点路径的完整性。
2.6 PV和SV
PV即Page View,访问次数,本模型中指的是一段时间内访问的次数;SV即Session View,会话次数,本模型中指出现过该访问路径的会话数。如,有路径一:A → B → C → D → A → B和路径二:A → B → D,那么,A → B的PV为2+1=3,SV为1+1=2。
三、 数据模型设计
本节将介绍数据模型的设计,包括数据流向、路径划分、ps/sv计算以及最终得到的桑基图中路径的转化率计算。
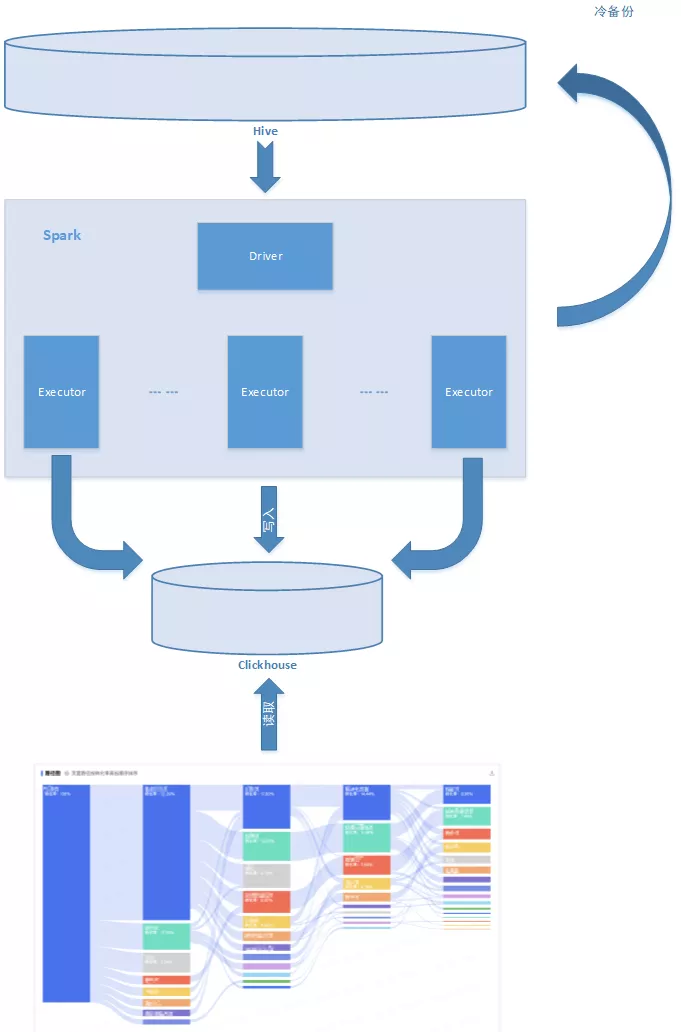
3.1 整体数据流向
数据来源于统一的数据仓库,通过Spark计算后写入Clickhouse,并用Hive进行冷备份。数据流向图见图3.1-1。
3.2 技术选型
Clickhouse不是本文的重点,在此不详细描述,仅简要说明选择Clickhouse的原因。
选择的原因是在于,Clickhouse是列式存储,速度极快。看下数据量级和查询速度(截止到本文撰写的日期):
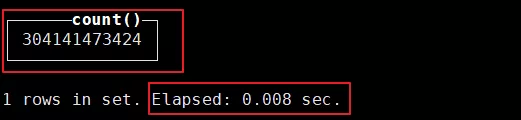
最后得到的千亿数据查询速度是这样,
3.3 数据建模
3.3.1 获取页面信息,划分session
页面路径模型基于各种事件id切割获取到对应的页面id,来进行页面路径分析。Session的概念可见第2.2节,这里不再赘述。目前我们使用更加灵活的Session划分,使得用户可以查询到在各种时间粒度(5,10,15,30,60分钟)的Session会话下,用户的页面转化信息。
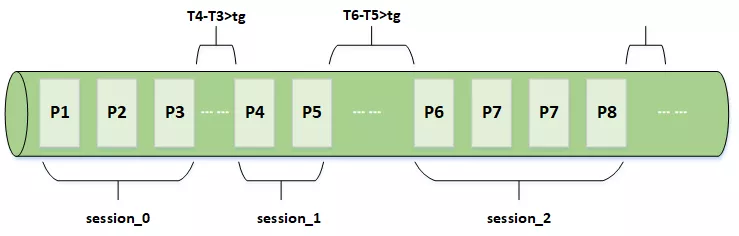
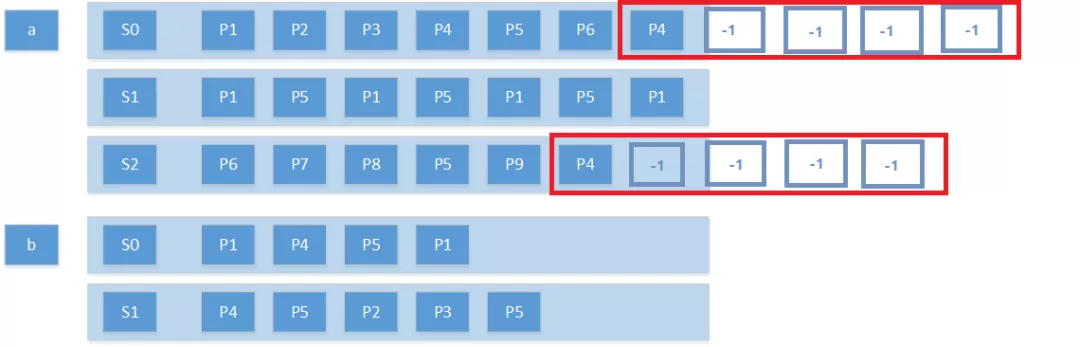
假设有用户a和用户b,a用户当天发生的行为事件分别为 E1, E2, E3… , 对应的页面分别为P1, P2, P3… ,事件发生的时间分别为T1, T2, T3… ,选定的session间隔为tg。如图所示T4-T3>tg,所以P1,P2,P3被划分到了第一个Session,P4,P5被划分到了第二个Session,同理P6及后面的页面也被划分到了新的Session。
伪代码实现如下:
def splitPageSessions(timeSeq: Seq[Long], events: Seq[String], interval: Int)
(implicit separator: String): Array[Array[Array[String]]] = {
// 参数中的events是事件集合,timeSeq是相应的事件发生时间的集合
if (events.contains(separator))
throw new IllegalArgumentException("Separator should't be in events.")
if (events.length != timeSeq.length)
throw new Exception("Events and timeSeq not in equal length.")
val timeBuf = ArrayBuffer[String](timeSeq.head.toString) // 存储含有session分隔标识的时间集合
val eventBuf = ArrayBuffer[String](events.head) // 存储含有session分隔标识的事件集合
if (timeSeq.length >= 2) {
events.indices.tail.foreach { i =>
if (timeSeq(i) - timeSeq(i - 1) > interval * 60000) { // 如果两个事件的发生时间间隔超过设置的时间间隔,则添加分隔符作为后面划分session的标识
timeBuf += separator;
eventBuf += separator
}
timeBuf += timeSeq(i).toString;
eventBuf += events(i)
}
}
val tb = timeBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通过标识符划分成为各个session下的时间集合
val eb = eventBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通过标识符划分成为各个session下的事件集合
tb.zip(eb).map(t => Array(t._1, t._2)) // 把session中的事件和发生时间对应zip到一起,并把元组修改成数组类型,方便后续处理
}
3.3.2 相邻页面去重
不同的事件可能对应同一页面,临近的相同页面需要被过滤掉,所以划分session之后需要做的就是相邻页面去重。

相邻页面去重后得到的结果是这样

3.3.3 获取每个页面的前/后四级页面
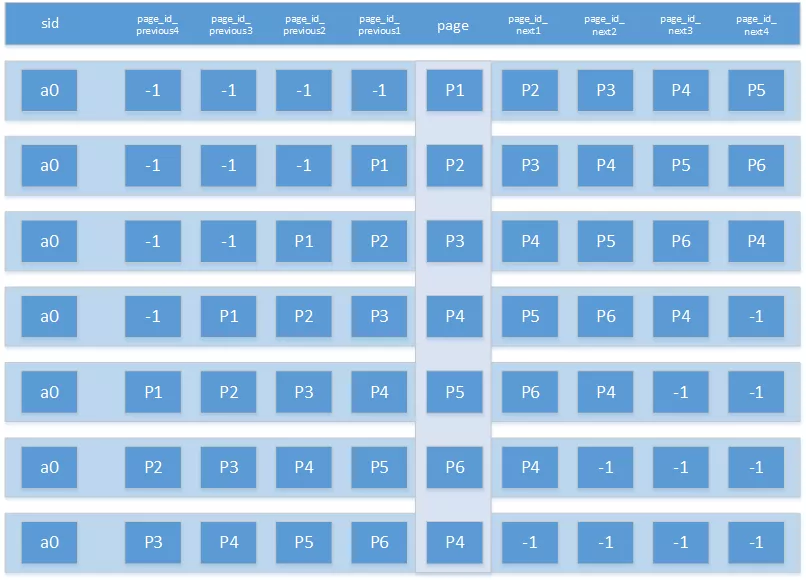
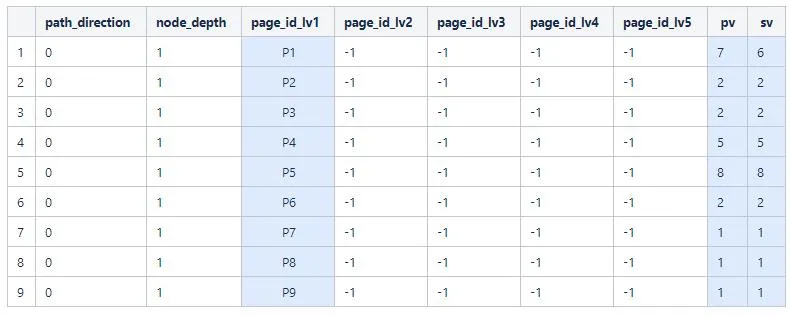
然后对上述数据进行窗口函数分析,获取每个session中每个页面的前后四级页面,其中sid是根据用户标识ID和session号拼接而成,比如,针对上述的用户a的第一个session 0会生成如下的7条记录,图中的page列为当前页面,空页面用-1表示
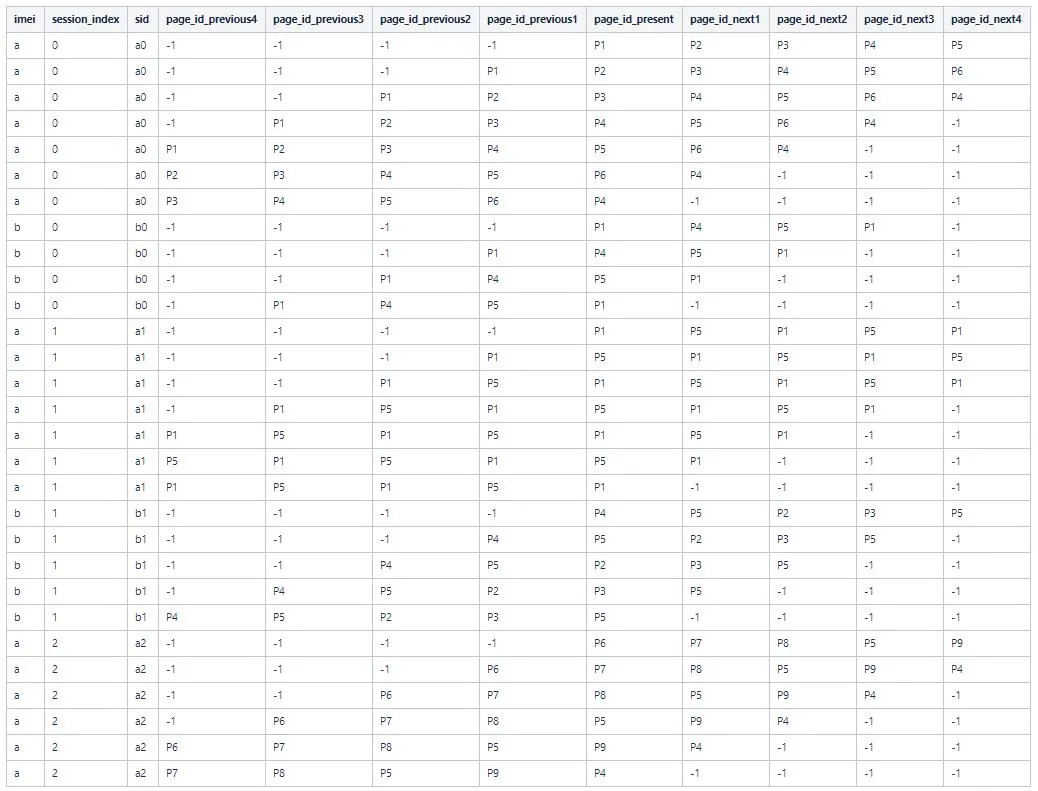
计算剩下的,会得到一共7+7+6+4+5=29条记录。得到全部记录如下
3.3.4 统计正负向路径的pv/sv
取page和page_id_previous1, page_id_previous2, page_id_previous3 ,page_id_previous4得到负向五级路径(path_direction为2),取page和page_id_next1, page_id_next2, page_id_next3, page_id_next4得到正向五级路径(path_direction为1),分别计算路径的pv和sv(按照sid去重),得到如下数据dfSessions,
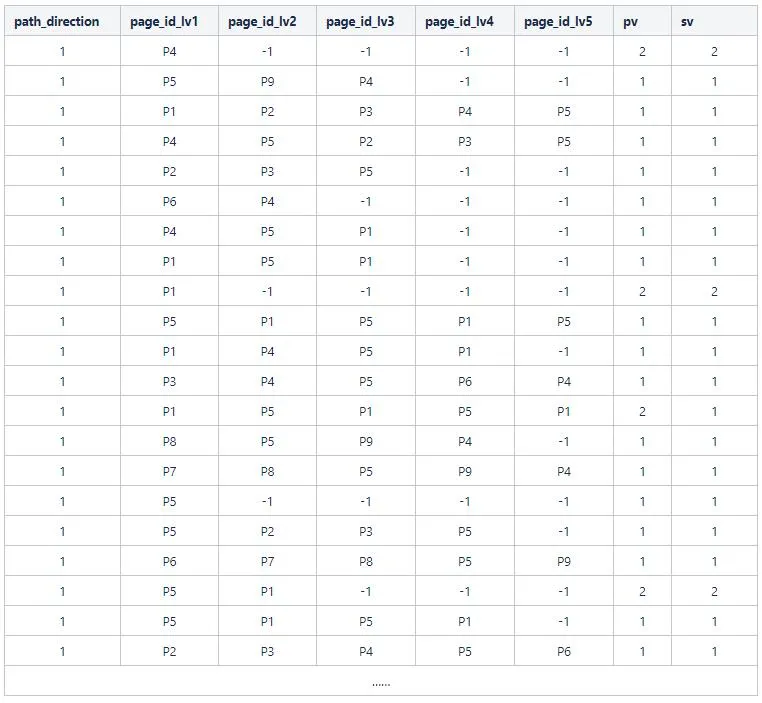
直接看上面的数据可能比较茫然,所以这里拆出两条数据示例,第一条结果数据

这是一条正向的(path_direction为1)路径结果数据,在下图中就是从左到右的路径,对应的两个路径如下
第二条结果数据

也是一条正向的路径结果数据,其中pv为2,对应的两个路径如下,sv为1的原因是这两条路径的sid一致,都是用户a在S1会话中产生的路径

3.3.5 统计计算各级路径的pv/sv
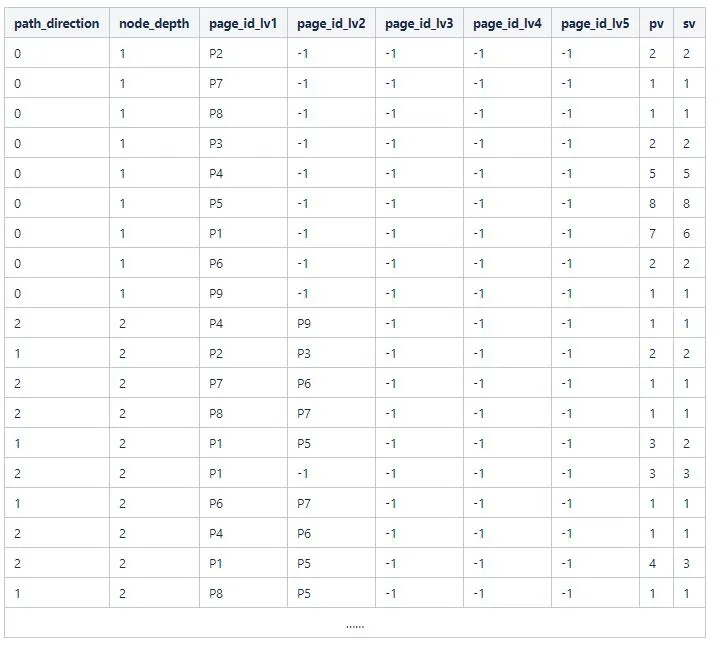
然后根据dfSessions数据,按照page_id_lv1分组计算pv和sv的和,得到一级路径的pv和sv,一级路径特殊地会把path_direction设置为0
然后类似地分别计算二三四五级路径的pv和sv,合并所有结果得到如下
3.4 数据写入
通过Spark分析计算的结果数据需要写入Clickhouse来线上服务,写入Hive来作为数据冷备份,可以进行Clickhouse的数据恢复。
Clickhouse表使用的是分布式(Distributed)表结构,分布式表本身不存储任何数据,而是作为数据分片的透明代理,自动路由到数据到集群中的各个节点,所以分布式表引擎需要配合其他数据表引擎一起使用。用户路径分析模型的表数据被存储在集群的各个分片中,分片方式使用随机分片,在这里涉及到了Clickhouse的数据写入,我们展开讲解下。
有关于这一点,在模型初期我们使用的是写分布式表的方式来写入数据,具体的写入流程如下所示:
- 客户端和集群中的A节点建立jdbc连接,并通过HTTP的POST请求写入数据;
- A分片在收到数据之后会做两件事情,第一,根据分片规则划分数据,第二,将属于当前分片的数据写入自己的本地表;
- A分片将属于远端分片的数据以分区为单位,写入目录下临时bin文件,命名规则如:/database@host:port/[increase_num].bin;
- A分片尝试和远端分片建立连接;
- 会有另一组监听任务监听上面产生的临时bin文件,并将这些数据发送到远端分片,每份数据单线程发送;
- 远端分片接收数据并且写入本地表;
- A分片确认完成写入。
通过以上过程可以看出,Distributed表负责所有分片的数据写入工作,所以建立jdbc连接的节点的出入流量会峰值极高,会产生以下几个问题:
- 单台节点的负载过高,主要体现在内存、网卡出入流量和TCP连接等待数量等,机器健康程度很差;
- 当业务增长后更多的模型会接入Clickhouse做OLAP,意味着更大的数据量,以当前的方式来继续写入的必然会造成单台机器宕机,在当前没有做高可用的状况下,单台机器的宕机会造成整个集群的不可用;
- 后续一定会做ck集群的高可用,使用可靠性更高的ReplicatedMergeTree,使用这种引擎在写入数据的时候,也会因为写分布式表而出现数据不一致的情况。
针对于此数据端做了DNS轮询写本地表的改造,经过改造之后:
- 用于JDBC连接的机器的TCP连接等待数由90下降到25,降低了72%以上;
- 用于JDBC连接的机器的入流量峰值由645M/s降低到76M/s,降低了88%以上;
- 用于JDBC连接的机器因分发数据而造成的出流量约为92M/s,改造后这部分出流量清零。
另外,在Distributed表负责向远端分片写入数据的时候,有异步写和同步写两种方式,异步写的话会在Distributed表写完本地分片之后就会返回写入成功信息,如果是同步写,会在所有分片都写入完成才返回成功信息,默认的情况是异步写,我们可以通过修改参数来控制同步写的等待超时时间。
def splitPageSessions(timeSeq: Seq[Long], events: Seq[String], interval: Int)
(implicit separator: String): Array[Array[Array[String]]] = {
// 参数中的events是事件集合,timeSeq是相应的事件发生时间的集合
if (events.contains(separator))
throw new IllegalArgumentException("Separator should't be in events.")
if (events.length != timeSeq.length)
throw new Exception("Events and timeSeq not in equal length.")
val timeBuf = ArrayBuffer[String](timeSeq.head.toString) // 存储含有session分隔标识的时间集合
val eventBuf = ArrayBuffer[String](events.head) // 存储含有session分隔标识的事件集合
if (timeSeq.length >= 2) {
events.indices.tail.foreach { i =>
if (timeSeq(i) - timeSeq(i - 1) > interval * 60000) { // 如果两个事件的发生时间间隔超过设置的时间间隔,则添加分隔符作为后面划分session的标识
timeBuf += separator;
eventBuf += separator
}
timeBuf += timeSeq(i).toString;
eventBuf += events(i)
}
}
val tb = timeBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通过标识符划分成为各个session下的时间集合
val eb = eventBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通过标识符划分成为各个session下的事件集合
tb.zip(eb).map(t => Array(t._1, t._2)) // 把session中的事件和发生时间对应zip到一起,并把元组修改成数组类型,方便后续处理
}3.5 转化率计算
在前端页面选择相应的维度,选中起始页面:
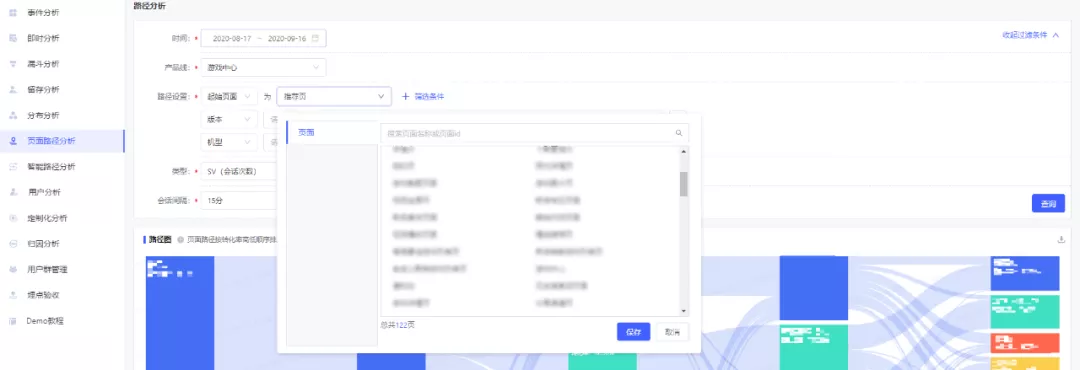
后端会在Clickhouse中查询,
选定节点深度(node_depth)为1和一级页面(page_id_lv1)是选定页面的数据,得到一级页面及其sv/pv,
选定节点深度(node_depth)为2和一级页面(page_id_lv1)是选定页面的数据,按照sv/pv倒序取前10,得到二级页面及其sv/pv,
选定节点深度(node_depth)为2和一级页面(page_id_lv1)是选定页面的数据,按照sv/pv倒序取前20,得到三级页面及其sv/pv,
选定节点深度(node_depth)为2和一级页面(page_id_lv1)是选定页面的数据,按照sv/pv倒序取前30,得到四级页面及其sv/pv,
选定节点深度(node_depth)为2和一级页面(page_id_lv1)是选定页面的数据,按照sv/pv倒序取前50,得到五级页面及其sv/pv,
转化率计算规则:
页面转化率:
假设有路径 A-B-C,A-D-C,A-B-D-C,其中ABCD分别是四个不同页面
计算三级页面C的转化率:
(所有节点深度为3的路径中三级页面是C的路径的pv/sv和)÷(一级页面的pv/sv)
路径转化率
假设有A-B-C,A-D-C,A-B-D-C,其中ABCD分别是四个不同页面
计算A-B-C路径中B-C的转化率:
(A-B-C这条路径的pv/sv)÷(所有节点深度为3的路径中二级页面是B的路径的pv/sv和)
四、工程端架构设计
本节将讲解工程端的处理架构,包括几个方面:桑基图的构造、路径合并以及转化率计算、剪枝。
4.1 桑基图的构造
从上述原型图可以看到,我们需要构造桑基图,对于工程端而言就是需要构造带权路径树。
简化一下上图,就可以将需求转化为构造带权树的邻接表。如下左图就是我们的邻接表设计。左侧顺序列表存储的是各个节点(Vertex),包含节点名称(name)、节点代码(code)等节点信息和一个指向边(Edge)列表的指针;每个节点(Vertex)指向一个边(Edge)链表,每条边保存的是当前边的权重、端点信息以及指向同节点下一条边的指针。
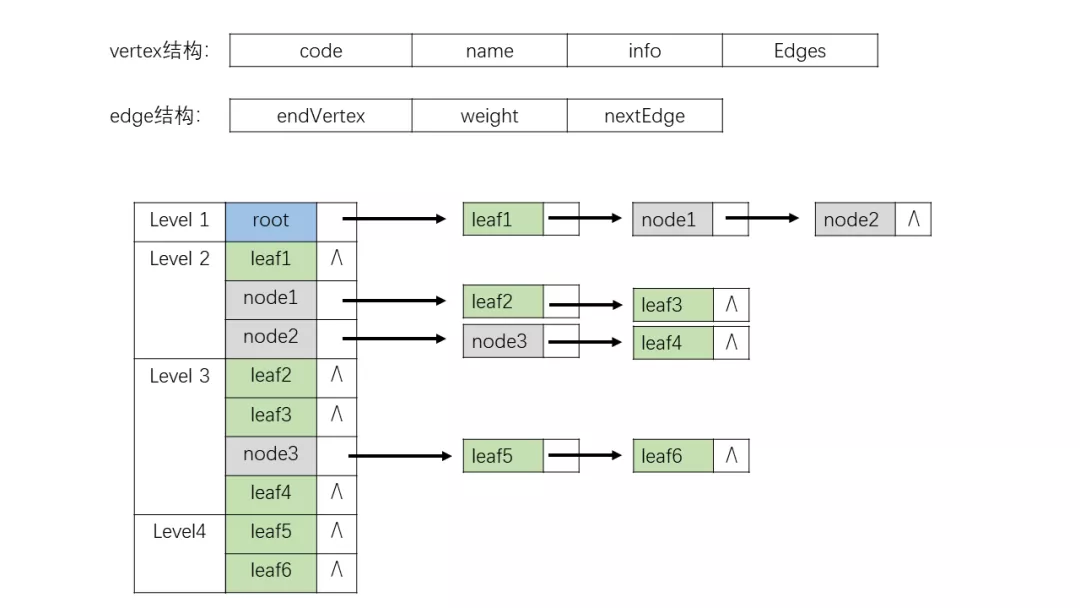
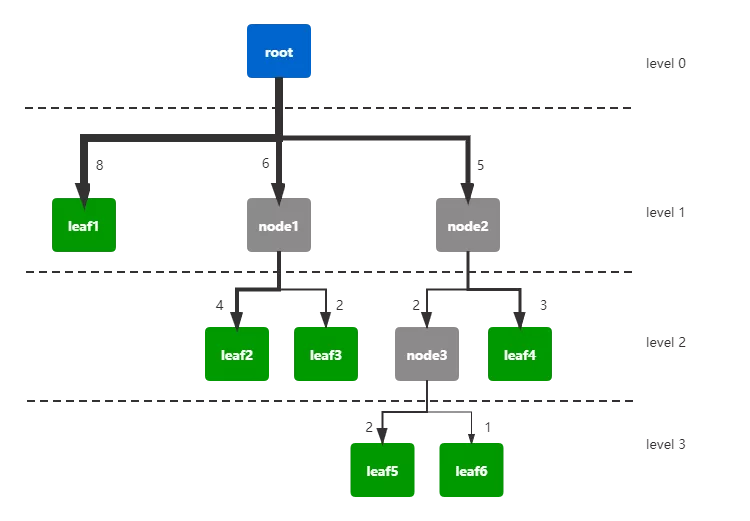
图4.1-2就是我们在模型中使用到的邻接表。这里在2.4中描述的邻接表上做了一些改动。在我们的桑基图中,不同层级会出现相同名称不同转化率的节点,这些节点作为路径的一环,并不能按照名称被看作重复节点,不构成环路。如果整个桑基图用一个邻接表表示,那么这类节点将被当作相同节点,使得图像当中出现环路。因此,我们将桑基图按照层级划分,每两级用一个邻接表表示,如图4.1-2,Level 1表示层级1的节点和指向层级2的边、Level 2表示层级2的节点指向层级3的边,以此类推。
4.2 路径的定义
首先,我们先回顾一下桑基图:
观察上图可以发现,我们需要计算四个数据:每个节点的pv/sv、每个节点的转化率、节点间的pv/sv、节点间的转化率。那么下面我们给出这几个数据的定义:
节点pv/sv = 当前节点在当前层次中的pv/sv总和
节点转化率 = ( 节点pv/sv ) / ( 路径起始节点pv/sv )
节点间pv/sv = 上一级节点流向当前节点的pv/sv
节点间转化率 = ( 节点间pv/sv ) / ( 上一级节点pv/sv )
再来看下存储在Clickhouse中的路径数据。先来看看表结构:
(
`node_depth` Int8 COMMENT '节点深度,共5个层级深度,枚举值1-2-3-4-5' CODEC(T64, LZ4HC(0)),
`page_id_lv1` String COMMENT '一级页面,起始页面' CODEC(LZ4HC(0)),
`page_id_lv2` String COMMENT '二级页面' CODEC(LZ4HC(0)),
`page_id_lv3` String COMMENT '三级页面' CODEC(LZ4HC(0)),
`page_id_lv4` String COMMENT '四级页面' CODEC(LZ4HC(0)),
`page_id_lv5` String COMMENT '五级页面' CODEC(LZ4HC(0))
)上述为路径表中比较重要的几个字段,分别表示节点深度和各级节点。表中的数据包含了完整路径和中间路径。完整路径指的是:路径从起点到退出、从起点到达指定终点,超出5层的路径当作5层路径来处理。中间路径是指数据计算过程中产生的中间数据,并不能作为一条完整的路径。
路径数据:
(1)完整路径


(2)不完整路径

那么我们需要从数据中筛选出完整路径,并将路径数据组织成树状结构。
4.3 设计实现
4.3.1 整体框架
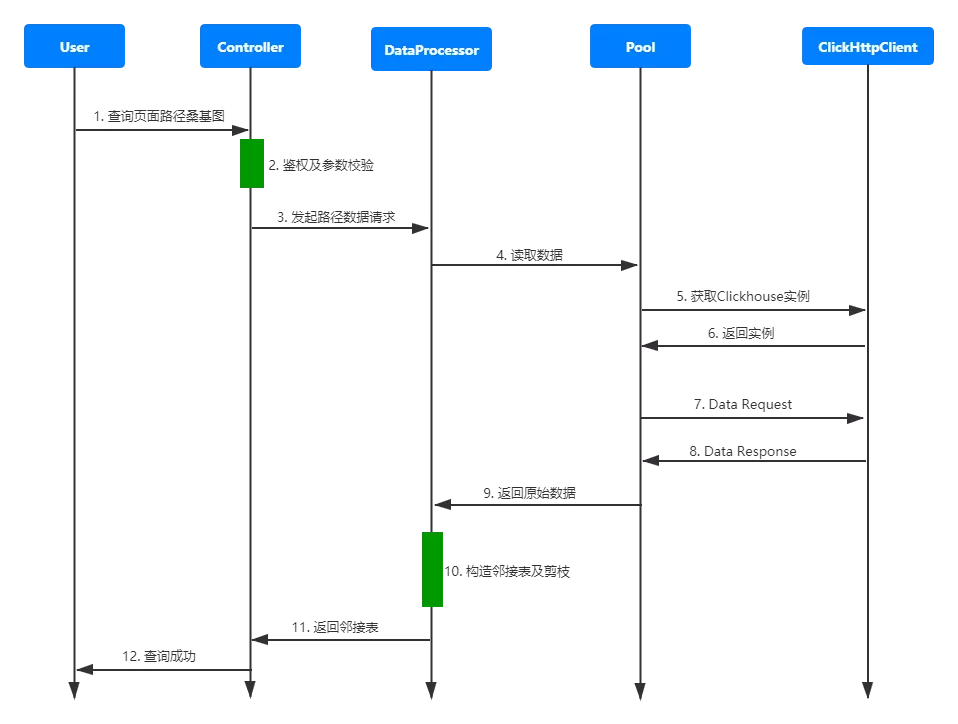
后端整体实现思路很明确,主要步骤就是读取数据、构造邻接表和剪枝。那么要怎么实现完整/非完整路径的筛选呢?我们通过service层剪枝来过滤掉不完整的路径。以下是描述整个流程的伪代码:
// 1-1: 分层读取原始数据
// 1-1-1: 分层构造Clickhouse Sql
for( int depth = 1; depth <= MAX_DEPTH; depth ++){
sql.append(select records where node_depth = depth)
}
// 1-1-2: 读取数据
clickPool.getClient();
records = clickPool.getResponse(sql);
// 2-1: 获取节点之间的父子、子父关系(双向edge构造)
findFatherAndSonRelation(records);
findSonAndFathRelation(records);
// 3-1: 剪枝
// 3-1-1: 清除孤立节点
for(int depth = 2; depth <= MAX_DEPTH; depth ++){
while(hasNode()){
node = getNode();
if node does not have father in level depth-1:
cut out node;
}
}
// 3-1-2: 过滤不完整路径
for(int depth = MAX_DEPTH - 1; depth >= 1; depth --){
cut out this path;
}
// 3-2: 构造邻接表
while(node.hasNext()){
sumVal = calculate the sum of pv/sv of this node until this level;
edgeDetails = get the details of edges connected to this node and the end point connected to the edges;
sortEdgesByEndPoint(edgeDetails);
path = new Path(sumVal, edgeDetails);
}4.3.2 Clickhouse连接池
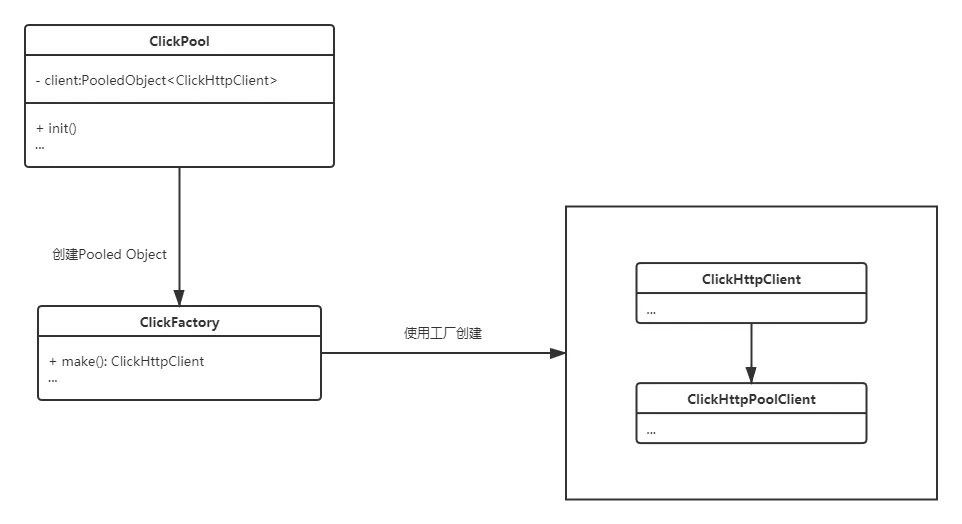
页面路径中我们引入了ClickHouse,其特点在这里不再赘述。我们使用一个简单的Http连接池连接ClickHouse Server。连接池结构如下:
4.3.3 数据读取
如2中描述的,我们需要读取数据中的完整路径。
(
`node_depth` Int8 COMMENT '节点深度,枚举值',
`page_id_lv1` String COMMENT '一级页面,起始页面',
`page_id_lv2` String COMMENT '二级页面',
`page_id_lv3` String COMMENT '三级页面',
`page_id_lv4` String COMMENT '四级页面',
`page_id_lv5` String COMMENT '五级页面',
`val` Int64 COMMENT '全量数据value'
)在上述表结构中可以看到,写入数据库的路径已经是经过一级筛选,深度≤5的路径。我们需要在此基础上再将完整路径和不完整路径区分开,根据需要根据node_depth和page_id_lvn来判断是否为完整路径并计算每个节点的value。
完整路径判断条件:
- node_depth=n, page_id_lvn=pageId (n < MAX_DEPTH)
- node_depth=n, page_id_lvn=pageId || page_id_lvn=EXIT_NODE (n = MAX_DEPTH)
完整路径的条件我们已经知道了,那么读取路径时有两种方案。方案一:直接根据上述条件进行筛选来获取完整路径,由于Clickhouse及后端性能的限制,取数时必须limit;方案二:逐层读取,可以计算全量数据,但是无法保证取出准确数量的路径。
通过观察发现,数据中会存在重复路径,并且假设有两条路径:
A → B → C → D → EXIT_NODE
A → B → E → D → EXIT_NODE
当有以上两条路径时,需要计算每个节点的value。而在实际数据中,我们只能通过不完整路径来获取当前节点的value。因此,方案一不适用。
那么方案二就可以通过以下伪代码逐层读取:
for(depth = 1; depth <= MAX_DEPTH; depth++){
select
node_depth as nodeDepth,
...,
sum(sv) as val
from
table_name
where
...
AND (toInt16OrNull(pageId1) = 45)
AND (node_depth = depth)
...
group by
node_depth,
pageId1,
pageId2,
...
ORDER BY
...
LIMIT
...
}读取出的数据如下:
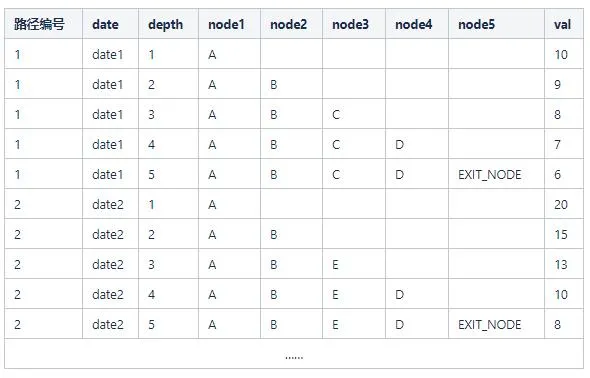
那么,node1_A_val = 10+20,node2_B_val = 9+15 以此类推。
4.3.4 剪枝
根据4.3.3,在取数阶段我们会分层取出所有原始数据,而原始数据中包含了完整和非完整路径。如下图是直接根据原始数据构造的树(原始树)。按照我们对完整路径的定义:路径深度达到5且结束节点为退出或其它节点;路径深度未达到5且结束节点为退出。可见,图中标红的部分(node4_lv1 → node3_lv2)是一条不完整路径。
另外,原始树中还会出现孤立节点(绿色节点node4_lv2)。这是由于在取数阶段,我们会对数据进行分层排序再取出,这样一来无法保证每层数据的关联性。因此,node4_lv2节点在lv2层排序靠前,而其前驱、后继节点排序靠后无法选中,从而导致孤立节点产生。
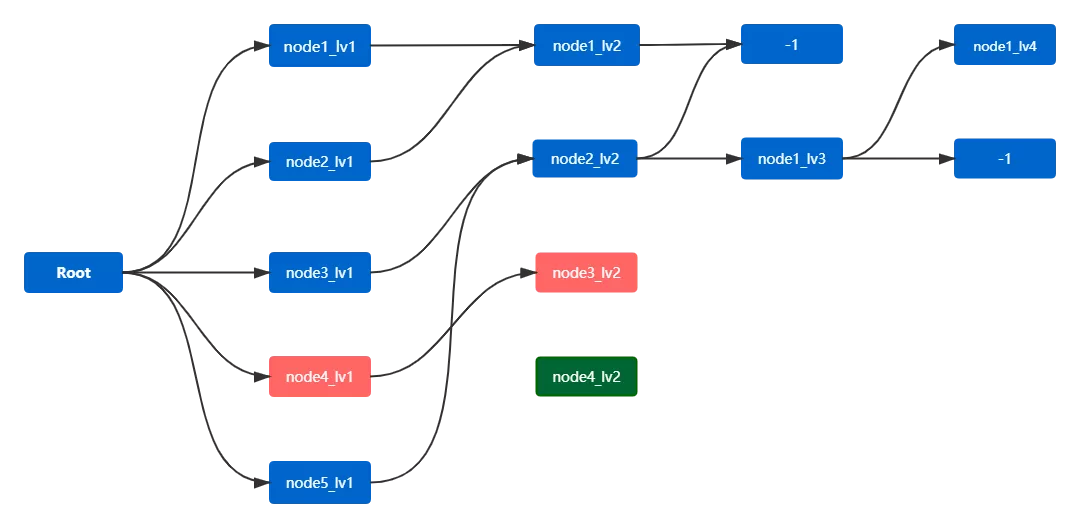
因此,在我们取出原始数据集后,还需要进行过滤才能获取我们真正需要的路径。
在模型中,我们通过剪枝来实现这一过滤操作。
// 清除孤立节点
for(int depth = 2; depth <= MAX_DEPTH; depth ++){
while(hasNode()){
node = getNode();
if node does not have any father and son: // [1]
cut out node;
}
}
// 过滤不完整路径
for(int depth = MAX_DEPTH - 1; depth >= 1; depth --){
cut out this path; // [2]
}在前述的步骤中,我们已经获取了双向edge列表(父子关系和子父关系列表)。因此在上述伪代码[1]中,借助edge列表即可快速查找当前节点的前驱和后继,从而判断当前节点是否为孤立节点。
同样,我们利用edge列表对不完整路径进行裁剪。对于不完整路径,剪枝时只需要关心深度不足MAX_DEPTH且最后节点不为EXIT_NODE的路径。那么在上述伪代码[2]中,我们只需要判断当前层的节点是否存在顺序边(父子关系)即可,若不存在,则清除当前节点。
五、写在最后
基于平台化查询中查询时间短、需要可视化的要求,并结合现有的存储计算资源以及具体需求,我们在实现中将路径数据进行枚举后分为两次进行合并,第一次是同一天内对相同路径进行合并,第二次是在日期区间内对路径进行汇总。本文希望能为路径分析提供参考,在使用时还需结合各业务自身的特性进行合理设计,更好地服务于业务。
方案中涉及到的Clickhouse在这里不详细介绍,感兴趣的同学可以去深入了解,欢迎和笔者一起探讨学习。
作者:vivo 互联网大数据团队
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/172674.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
