大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1. 什么是用户路径分析
用户行为分析是数据分析中非常重要的一项内容,在统计活跃用户,分析留存和转化率,改进产品体验、推动用户增长等领域有重要作用。单体洞察、用户分群、行为路径分析是用户行为数据分析的三大利器。
用户路径分析,就是用户在APP或网站中的访问行为路径。用户行为路径分析是互联网行业特有的一类数据分析方法,它主要根据每位用户在App或网站中的点击行为日志,分析用户在App或网站中各个模块的流转规律与特点,挖掘用户的访问或点击模式,进而实现一些特定的业务用途,如App核心模块的到达率提升、特定用户群体的主流路径提取与浏览特征刻画,App产品设计的优化与改版等。
d3js可视化效果图:
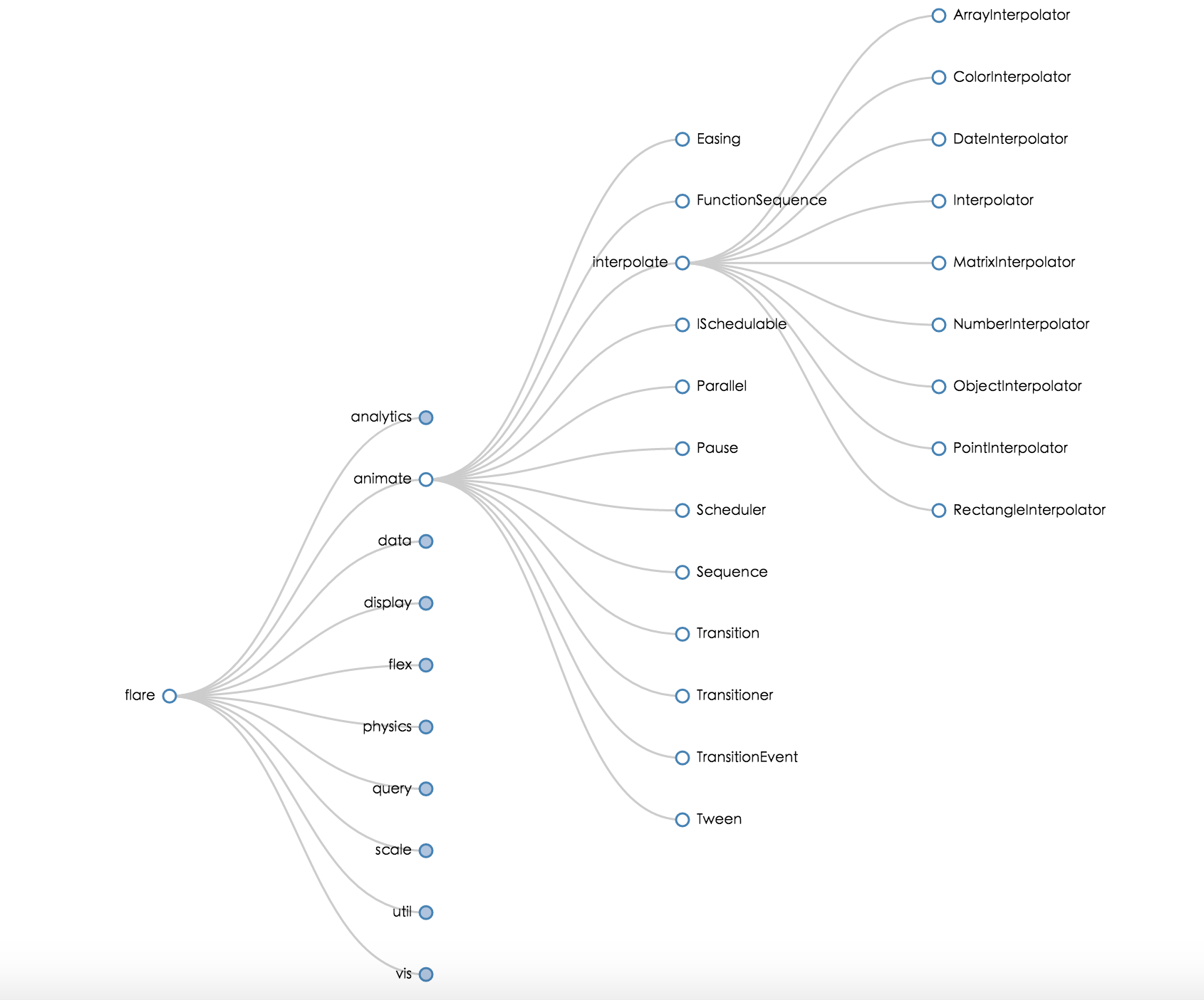

2. 路径分析的业务场景
2.1 业务场景
无论是产品、运营还是市场团队都希望能够清晰的了解其用户行为路径,从纷繁的用户行为中,寻找以下问题的答案:
-
用户从进入产品到离开都发生了什么?主要遵循什么样的行为模式?
可以选用用户路径模型,观察用户的整体行为路径,通过用户频繁路径发现其行为模式。 -
用户是否按照产品设计引导的路径在行进?哪些步骤上发生了流失?
可以选用转化漏斗模型,将各个引导设置为漏斗的各个步骤,分析其转化和流失。 -
用户离开预想的路径后,实际走向是什么?
可以选择转化漏斗模型,查看经过流失环节的用户后续的行为路径,或者在智能路径中选择预设的事件为目标事件,分析其后续行为路径。 -
不同渠道的带来的用户,不同特征的用户行为差异在哪里?哪类用户更有价值?
可以选择用户路径模型,细分渠道维度,查看不同维度的用户行为路径。
在互联网数据化运营的实践中,路径分析技术与数据挖掘算法相结合,将会产生更大的应用价值和更为广阔的前景。比如:通过聚类技术划分出不同的群体,然后分析不同群体的路径特征,针对特定人群进行的路径分析,比如,对比付费人群的主要路径与非付费人群的主要路径,优化页面布局等、根据下单付费路径中频繁出现的异常模式可能来对付费环境的页面设计进行优化,提升付费转化率,减少下单后的流失风险等。
举个例子:
某电商网站客户通过用户路径分析,看出有两条主要的路径:
- 一是: 启动App-搜索商品-提交订单-支付订单;
- 二是: 启动App-未支付订单-搜索相似商品-取消订单;
通过第一条用户路径相关数值显示,客户提交订单后,大约75%的用户会支付,而高达25%的用户没有支付订单;第二条用户路径显然是一条有明确目的:打开app后直奔“未支付订单”,但是此用户再次“搜索相似商品”,这一行为可以判断客户可能存在比价行为,表明价格一定程度上影响了这部分用户的支付欲望,这是一批“价格导向”的客户。
对此,该电商运营人员采取针对性措施:
- 未支付订单”超过30分钟则自动取消,刺激用户支付;
- 将支付页面附近放置优惠券领取,促进购买。
当该电商新版本上线后,再次通过用户路径分析模型,发现客户在提交订单后,由于30分钟的时间限制,有更多的客户愿意立即支付订单,这次改版获得了成功。
2.2 漏斗模型
以上提到的路径分析与我们较为熟知的漏斗模型有相似之处,广义上说,漏斗模型可以看作是路径分析中的一种特殊情况,是针对少数人为特定模块与事件节点的路径分析。
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。
漏斗分析模型已经广泛应用于流量监控、产品目标转化等日常数据运营与数据分析的工作中。例如在一款产品服务平台中,直播用户从激活 APP 开始到花费,一般的用户购物路径为激活 APP、注册账号、进入直播间、互动行为、礼物花费五大阶段,漏斗能够展现出各个阶段的转化率,通过漏斗各环节相关数据的比较,能够直观地发现和说明问题所在,从而找到优化方向。
下面是一个美团的有序漏斗

漏斗模型的演化
漏斗模型的概念最早由St. Elmo Lewis (美国知名广告人)在1898年提出的,叫做消费者购买漏斗(the purchase funnel),也叫消费者漏斗(customer funnel)、营销漏斗(sales/marketing funnel)。Lewis提出的这个策略,后来被称为AIDA模型,即意识-兴趣-欲望-行动。
AIDMA模型是在AIDA模型(Attention, Interest, Desire, Action)的基础上,增加了Memory,形成的注意 → 兴趣 → 欲望 → 记忆 → 行动(购买)的模型。AIDMA模型主要适用于品牌营销方面,当然现在很多互联网产品也开始把自己作为品牌去打造,比如拼多多、抖音冠名综艺节目,爆款H5刷屏,网易云音乐的地铁刷屏广告等,都是从引起用户的兴趣,强化品牌记忆,从而吸引潜在用户。
因为AIDMA模型缺少用户反馈的环节,且随着互联网用户教育的完成,消费者行为模式发生了改变,随之衍生出了AISAS模型(Attention,Interest,Search,Action,Share),也就是注意-兴趣-搜索-行动-分享。用户从接受到产品的宣传营销信息(硬广or软文),到引起兴趣,然后开始搜索进行了解(百度、知乎、微博、淘宝),到在线下载或支付,以及后续的评价分享环节(产品内、微信微博)。
AARRR模型 是2007年由Dave McClure(500 Startups创始人)提出的一种业务增长模式。它包括5个阶段:获客(Acquisition)、激活(Activation)、留存(Retention)、商业变现(Revenue)、自传播(Referral)。它被做为公司关注的五个最重要的指标,因为这些指标有效地衡量了产品的增长,同时又简单且可操作。
互联网行业主要用AARRR模型:

路径分析与漏斗模型的区别
漏斗模型是路径分析的一个重要分支。二者都是针对用户访问路径所进行的发现、分析与提炼,都是以上下环节转化率的计算为核心的。他们的不同表现在以下三方面:
- 侧重点不同。漏斗模型更多、更主要用于网站和产品的运营监控和管理中,主要是针对网站或者产品运营中的关键节点和关键环节所进行的分析、监控、管理;而路径分析的用途更加广泛,除了网站和产品的运营监控和管理外,还包括产品设计与优化、用户频繁路径模式识别、用户特征分析等。
- 粒度不同。漏斗模型更多时候要经过抽象的过程来搭建漏斗的每一个环节。而路径分析(不包括漏斗模型在内的路径分析),则更多的时候是就事论事,不需要经过抽象、转化、整合这些过程。举例来说,电商行业最有名的漏斗模型曝光→点击→反馈→成交这个漏斗模型中,每一个环节都是经过抽象汇总后产生的。比如曝光这个环节可能要汇总多个不同的曝光场景,反馈环节则要汇总多种不同形式的反馈,有的是在线问答,有的是即时通信反馈,有的是点击查看售后保障条款等。
- 分析技术有差别。相对来说,漏斗模型的分析技术更直观、更直接、更容易理解,就是根据两个关键环节的先后顺序,计算出从头到尾的转化率即可。而路径分析所采用的分析技术相对来说更为多样化,也更具有一定的专业深度。比如Sequence Analysis、Social Network Analysis等。
3. 产品化要求
路径分析
大体目标要完成
- 基于访问次数和人数(pv/uv)的用户行为路径,筛选不同客户端,
- 统计各个页面的曝光数(热度)、进入和流出数、跳出率,
- 可以支持从任意事件起下查后续行为或者上查来源行为,
- 并且要支持最多30天时间内发生的行为路径的查看。
最重要的一点是强调用户体验需要较实时处理获得结果。
根据埋点的情况,粒度暂定为页面,也可细化到页面上的widget。这里的事件就是埋点时定义的事件动作。结果可以在前端展示为网状图、桑葚图,也可以简单展示为树状图。图形的节点和边分别有自己的Tag、Weight,代表不同的含义。通常节点的权重代表曝光数,边的权重代表跳出率。如果页面图中层级的节点特别多,还要可以设置每层最多显示几个节点,按曝光数筛选Top(k)。
筛选条件参考神策公开文档 中的图:
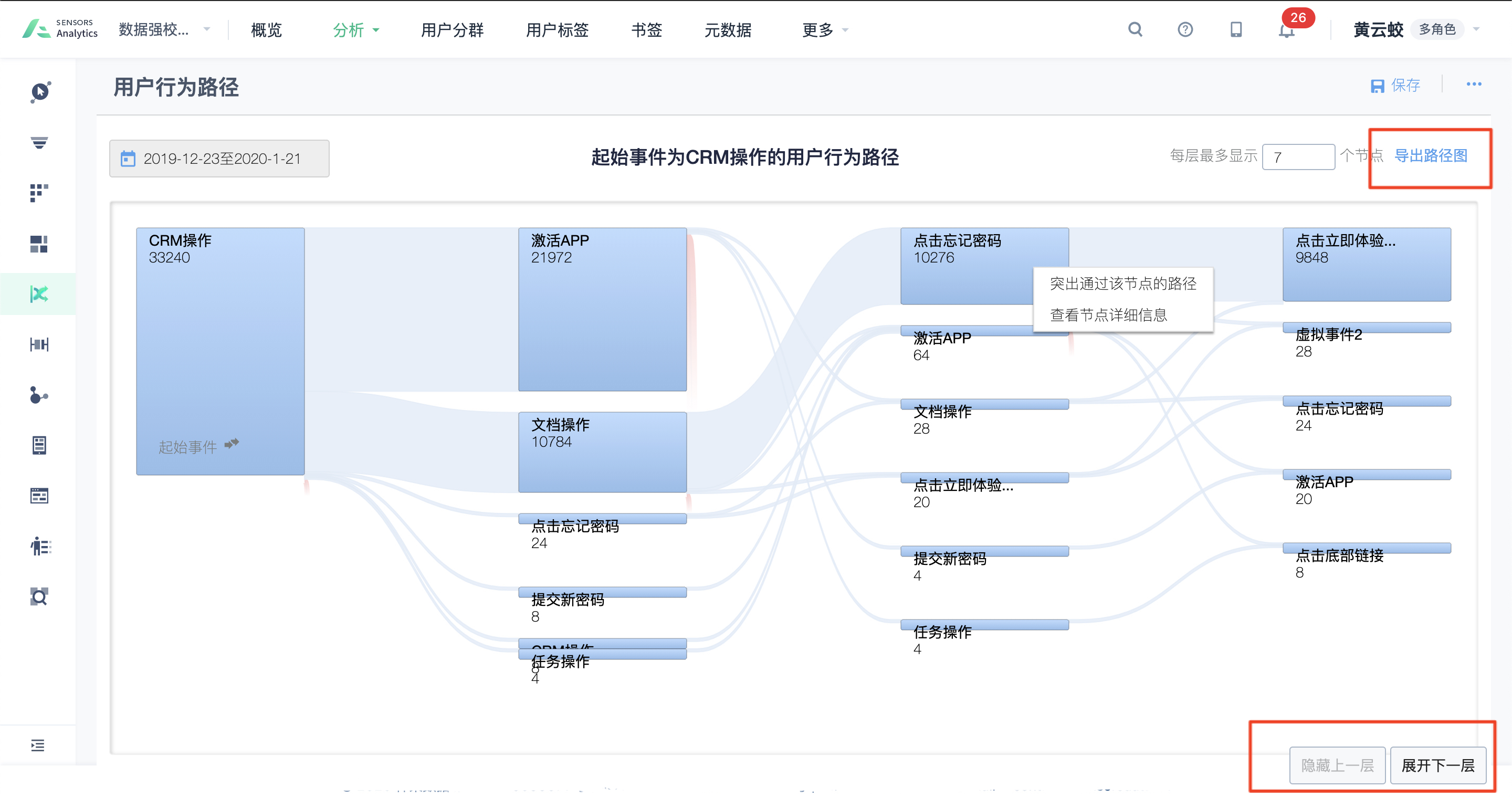
用 js 库做成动态Graph图会更好看一点。
漏斗图
与路径分析图类似,漏斗图的用户数是逐层收敛的。要指定访问路径,并满足时间窗口,客户端类型,和地区的筛选条件。
可以分开做,也可以合并在路径分析里面。
4. 技术路线
4.1 实现流程
埋点采集
页面埋点是用户路径分析的前置条件。

我们采用前端埋点的方式,可获取用户意向行为、页面曝光、用户倾向等精细化运营的数据,可定制上报时机、上报内容、上报频次,可判断用户是否作弊;日志量小,有效率高。数据上报到nginx服务器,然后从服务器日志转存到Hive仓库进行清洗。
数据清洗:
根据埋点字典表,排除伴随用户行为触发而不是用户主动触发的事件,匹配出这些埋点的描述,排查异常情况,最终得到用以统计用户路径的事件动作。
聚合统计
采用简单统计的方法,用Sql的方式直接计算各种指标,然后汇总到结果表。但是对于以二维邻接表形成的复杂的分支,传统的sql难以直接统计计算。假设用户一共访问了10步到达最终页面或者退出,要统计这10步的各个路径情况,SQL方式这样实现:选出所有用户的第1步,left outer join第2步,以此类推,做10个这样的join,便可以得到10步中有多少个路径,每个路径有多少用户。
可以利用Graph这一数据结构,以及图论中丰富的算法,来方便的进行各种计算。比如图的遍历,出入度,PageRank,最短路径等。 这些算法在python的networkx,spark ML库中都有实现。
基于图(Graph)的算法可以对访问路径形成的复杂网络进行更深入的挖掘。
可视化展示
前端使用vis.js、echarts、D3.js等,都可以方便地对图进行定制展示。
桑葚图的Demo:
https://gallery.echartsjs.com/editor.html?c=xtqTC6G-PQ
Graph图的vis.js Demo:
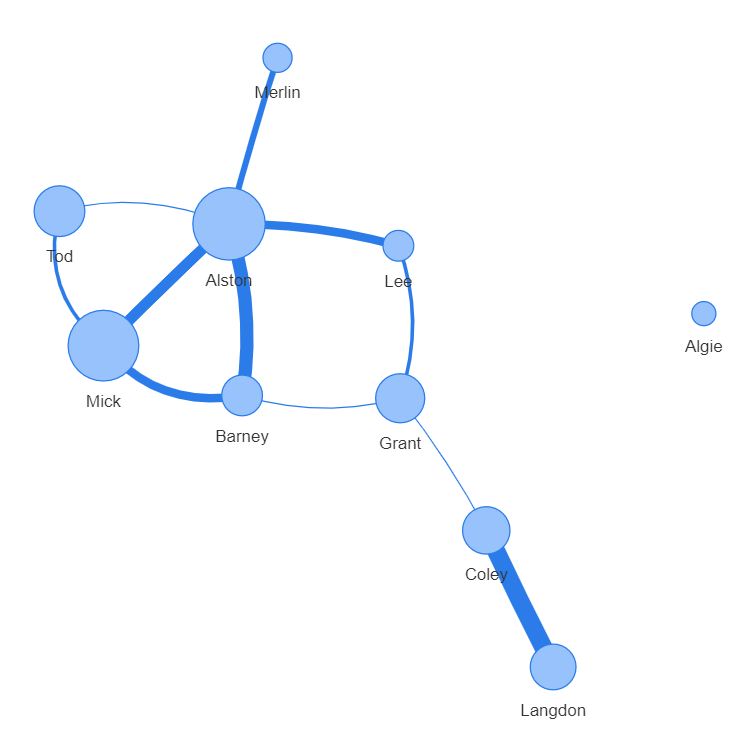
图中的节点代表城市,圆的大小表示节点的权重,边的粗细表示边的权重。
没有边与外界相连的”Algie”表示离群点。
4.2 路径分析算法
常用的用户行为路径算法有基于关联分析的序列路径挖掘方法和社会网络分析的方法。
(1) 基于序列的关联分析
基于序列的关联分析又称序列分析,这种分析方法是在关联分析(Association Analysis)的基础上,进一步考虑了关联品之间的先后顺序,即只分析先后顺序中的关联关系。
通过改进关联规则中的Apriori或FP-Growth算法,使其可以挖掘存在严格先后顺序的频繁用户行为路径,不失为一种重要的用户路径分析思路。我们可以仔细考量发掘出来的规则序列路径所体现的产品业务逻辑,也可以比较分析不同用户群体之间的规则序列路径。
(2) 社会网络分析方法
社会网络分析(Social Network Analysis),也叫做链接分析,其初衷是研究社会实体,即组织中的人,或称参与者,以及他们之间的活动和关系,这种网络关系和活动可以用图来表示。
在社会网络分析方法中,最常见最成熟的一种方法就是中心性分析方法(Centrality)。所谓中心性,是指某个个体在社会(网络)中的重要性。中心性程度高的个体,就是那些广泛与其他参与者连接或者发生关系的参与者。在一个单位或一个团体中,与其他同事有广泛交流或联系的人,其重要程度要高于那些与其他同事联系较少的人,也就是前者的中心性程度高于后者的中心性程度。
中心性算法能够帮助我们识别最重要的节点,帮助我们了解组动态,例如可信度、可访问性、事物传播的速度以及组与组之间的连接。
(3) 随机游走算法
随机游走(Random Walk)算法从图上获得一条随机的路径。随机游走算法从一个节点开始,随机沿着一条边正向或者反向寻找到它的邻居,以此类推,直到达到设置的路径长度。随机游走算法一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。比如 node2vec/graph2vec算法,可以通过节点的组合(Random Walk)来训练节点向量。这些向量可以表征词或者节点的含义,用来挖掘路径相关性等。
参考:
- 《数据挖掘与数据化运营实战》
- 用户行为路径分析的产品化实践 李亮,前Intel 移动事业部算法成员。
- 知乎-玩转用户行为路径分析的三种方法
- 漏斗分析模型(转化率)
- 及策-数据分析卡片
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/172672.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
