大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
10.1.1 创建存储过程
存储过程就是一条或者多条SQL语句的集合,可以视为批文件。它可以定义批量插入的语句,也可以定义一个接收不同条件的SQL。
创建存储过程的语句为 CREATE PROCEDURE,创建存储函数的语句为CREATE FUNCTION。
调用存储过程的语句为CALL。
调用存储函数的形式就像调用MySQL内部函数一样。
DROP TABLE IF EXISTS t_student;
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
age INT(11) NOT NULL
);
INSERT INTO t_student VALUES(NULL,'大宇',22),(NULL,'小宇',20); 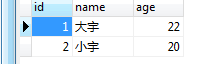

如上述,t_student表中的数据有两条。如果我们要分别查询出来这两条数据,显然就是根据ID来查询。查询出来了第一条数据以后,我们可能会去做其它的操作。等过两天,我们要查询另外一条记录的时候,可能又要再写一次这样的查询语句。
如果能像Java那样,提供一个ID,就能查询到指定ID的记录,这样就可以复用之前写的SQL语句。对于查询SQL语句,我们能不能像Java那样,封装这个查询学生的SQL呢?存储过程与存储函数应运而生。
定义一个根据ID查询学生记录的存储过程。
DROP PROCEDURE IF EXISTS getStuById;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE getStuById(IN stuId INT(11),OUT stuName VARCHAR(255),OUT stuAge INT(11)) -- 定义输入与输出参数
COMMENT 'query students by their id' -- 提示信息
SQL SECURITY DEFINER -- DEFINER指明只有定义此SQL的人才能执行,MySQL默认也是这个
BEGIN
SELECT name ,age INTO stuName , stuAge FROM t_student WHERE id = stuId; -- 分号要加
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号语法: CREATE PROCEDURE sp_name(定义输入输出参数) [ 存储特性 ] BEGIN SQL语句; END
IN 表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出的参数。sp_name为存储过程的名字。
如果此存储过程没有任何输入输出,其实就没什么意义了,但是sp_name()的括号不能省略。
查看刚才创建的存储过程。
SHOW PROCEDURE STATUS LIKE 'g%' 
下面是调用存储过程。对于存储过程提供的临时变量而言,MySQL规定要加上@开头。
#study 是当前数据库名称
CALL study.getStuById(1,@name,@age);
SELECT @name AS stuName,@age AS stuAge; 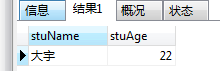
CALL getStuById(2,@name,@age);
SELECT @name AS stuName,@age AS stuAge; 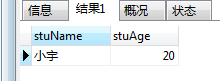
这样做的好处是,如果一段较为复杂的SQL语句,我们可能过了几天再去写它,又费事又费力。存储过程可以封装我们写过的SQL,在下次需要调用它的时候,直接提供参数并指明查询结果输出到哪些变量中即可。
提示:如果存储过程一次查询出两个记录,将会提示出错。[Err] 1172 – Result consisted of more than one row
所以需要在存储过程的SQL后面加上LIMIT 1。从位偏移量为0的,即从查询结果的第一条数据开始,查询一条记录。
10.1.2 创建存储函数
存储函数与存储过程本质上是一样的,都是封装一系列SQL语句,简化调用。
我们自己编写的存储函数可以像MySQL函数那样自由的被调用。
DROP FUNCTION IF EXISTS getStuNameById;
DELIMITER //
CREATE FUNCTION getStuNameById(stuId INT) -- 默认是IN,但是不能写上去。stuId视为输入的临时变量
RETURNS VARCHAR(255) -- 指明返回值类型
RETURN (SELECT name FROM t_student WHERE id = stuId); // -- 指明SQL语句,并使用结束标记。注意分号位置
DELIMITER ;使用存储函数。
SELECT getStuNameById(1); 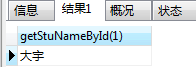
提示:在RETURN 语句后面,有趣的是,分号在SQL语句的外面。如果不加分号,查询结果居然查询出两条记录,很奇怪。
从上述存储函数的写法上来看,存储函数有一定的缺点。首先与存储过程一样,只能返回一条结果记录。另外就是存储函数只能指明一列数据作为结果,而存储过程能够指明多列数据作为结果。
10.1.3 定义变量
如果希望MySQL执行批量插入的操作,那么至少要有一个计数器来计算当前插入的是第几次。
这里的变量是用在存储过程中的SQL语句中的,变量的作用范围在BEGIN …. END 中。
没有DEFAULT子句,初始值为NULL。
定义变量的操作
DECLARE name,address VARCHAR; -- 发现了吗,SQL中一般都喜欢先定义变量再定义类型,与Java是相反的。
DECLARE age INT DEFAULT 20; -- 指定默认值。若没有DEFAULT子句,初始值为NULL。为变量赋值
SET name = 'jay'; -- 为name变量设置值DECLARE var1,var2,var3 INT;
SET var1 = 10,var2 = 20; -- 其实为了简化记忆其语法,可以分开来写
-- SET var1 = 10;
-- SET var2 = 20;
SET var3 = var1 + var2;使用变量实例。如下表,在做了去除主键约束后,我又添加了一条id=1的数据。现在希望查询出id为1的记录的数量。
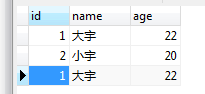
DROP PROCEDURE IF EXISTS contStById;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE contStById(IN sid INT(11),OUT result INT(11)) -- 定义输入变量
BEGIN
DECLARE sCount INT;
SELECT COUNT(*) INTO sCount FROM t_student WHERE id = sid;
SET result = sCount; -- 用变量为输出结果设值
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号
CALL contStById(1,@result);
SELECT @result;
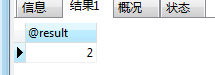
显然,在存储过程中的变量,可以直接与输出变量进行相应的计算。本例直接把sCount这个变量的值赋值到输出中。
10.1.4 定义条件与定义处理程序
定义条件CONDITION定义的是:在执行存储过程中的SQL语句的时候,可能出现的问题。
定义处理程序HANDLER:定义遇到了指定问题应该如何处理,避免存储过程执行异常而停止。
定义条件与定义处理语句程序的位置应该在BEGIN … END 之间。
定义条件的语法:DECLARE condtion_name CONDTION FOR 错误码||错误值
错误码可以视为一个错误的引用,比如404,它代表的就是找不到页面的错误,它的错误值可以视为NullPointerException。
DECLARE command_not_allowed CONDITION FOR SQLSTATE '42000'; -- 错误值
DECLARE command_not_allowed CONDITION FOR 1148; -- 错误码定义处理程序语法:DECLARE HANDLER_TYPE HANDLER FOR condtion_name sp_statement;
MySQL定义了三种HANDLER_TYPE ,CONTIUE是指遇到错误忽略,继续执行下面的SQL。EXIT表示遇到错误退出,默认的策略就是EXIT。
condtion_name可以是我们自己的定义的条件,也可以是MySQL内置的条件,比如SQLWARNING ,匹配01开头的错误代码。sp_statement指遇到错误的时候,需要执行的存储过程或存储函数。

DECLARE CONTINUE HANDLER FOR SQLSATTE '42S02' SET @info = 'NO_SUCH_TABLE'; -- 忽略错误值为42S02的SQL异常
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR_OCCUR'; -- 捕获SQL执行异常并输出信息
DECLARE no_such_table CONDITION FOR 1146; -- 为错误码为1146的错误定义条件
DECLARE CONTINUE HANDLER FOR no_such_table SET @info = 'no_such_table'; -- 为指定的条件设置处理程序DROP TABLE IF EXISTS t_student;
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
age INT(11) NOT NULL
); 
现通过存储过程,为这张表插入数据。因为id属性有主键约束,所以不能插入相同的id。
DROP PROCEDURE IF EXISTS insertStu;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE insertStu(OUT result INT) -- 指定输出结果
BEGIN
DECLARE flag INT(11) DEFAULT 0; -- 指定变量为0
DECLARE primary_key_limit CONDITION FOR SQLSTATE '23000'; -- 主键约束的错误值
DECLARE CONTINUE HANDLER FOR primary_key_limit SET @info = -1; -- 设计如果出现错误,@info将会被设置为 -1
INSERT INTO t_student(id,name,age) VALUES(1,'dayu',22); -- 插入值,设置主键为1
SET flag = 1; -- 普通变量设值为1
SET result = flag; -- 如果下面的SQL执行出现异常,那么就退出,只有上面的SQL生效。将普通变量的值给输出
INSERT INTO t_student(id,name,age) VALUES(1,'dayu',22); -- 插入值,设置主键为1
SET flag = 2; -- 如果处理程序是EXIT,那么就不会执行到这一步了
SET result = flag; -- 将普通变量的值给输出
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号CONTIUE是指遇到错误忽略,继续执行下面的SQL。因为是CONTINUE来处理程序,所以遇到错误将会继续执行。
另外,第二次插入记录,因为违反了主键约束,所以插入失败,但是存储过程仍然继续执行完毕。
CALL insertStu(@result);
SELECT @result,@info; -- @info没有申明就能调用到,可能是是全局变量吧运行结果:
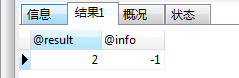
再次查看t_student表,只插入了一条记录,但是所有的存储过程都执行完毕了。
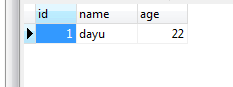
现在,重新执行下面的SQL。先重新建表,再将处理程序的处理策略换为EXIT:在执行存储过程中遇到了错误,那么就立即退出。
DROP TABLE IF EXISTS t_student;
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
age INT(11) NOT NULL
);
DROP PROCEDURE IF EXISTS insertStu;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE insertStu(OUT result INT) -- 指定输出结果
BEGIN
DECLARE flag INT(11) DEFAULT 0; -- 指定变量为0
DECLARE primary_key_limit CONDITION FOR SQLSTATE '23000'; -- 主键约束的错误值
DECLARE EXIT HANDLER FOR primary_key_limit SET @info = -1; -- 使用EXIT策略,遇到SQL错误将会结束这次存储过程
-- 出现SQL错误则直接退出存储过程的执行
INSERT INTO t_student(id,name,age) VALUES(1,'dayu',22); -- 插入值,设置主键为1
SET flag = 1; -- 普通变量设值为1
SET result = flag; -- 如果下面的SQL执行出现异常,那么就退出,只有上面的SQL生效。将普通变量的值给输出
INSERT INTO t_student(id,name,age) VALUES(1,'dayu',22); -- 插入值,设置主键为1
SET flag = 2; -- 如果处理程序是EXIT,那么就不会执行到这一步了
SET result = flag; -- 将普通变量的值给输出
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号
CALL insertStu(@result);
SELECT @result,@info; -- @info没有申明就能调用到,可能是是全局变量吧 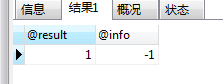
@result的结果为1,说明执行第二条SQL的时候,出现了异常。同样,@info的值为-1,也提示处理条件中定义的存储过程被触发。最后,数据库表中的数据也是
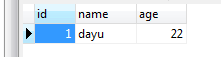
如果都是正确的SQL,会是什么情况呢?
DROP TABLE IF EXISTS t_student;
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
age INT(11) NOT NULL
);
DROP PROCEDURE IF EXISTS insertStu;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE insertStu(OUT result INT) -- 指定输出结果
BEGIN
DECLARE flag INT(11) DEFAULT 0; -- 指定变量为0
DECLARE primary_key_limit CONDITION FOR SQLSTATE '23000'; -- 主键约束的错误值
DECLARE EXIT HANDLER FOR primary_key_limit SET @info = -1; -- 设计如果出现错误,@info将会被设置为 -1
INSERT INTO t_student(id,name,age) VALUES(NULL,'dayu',22); --
SET flag = 1; -- 普通变量设值为1
SET result = flag; -- 如果下面的SQL执行出现异常,那么就退出,只有上面的SQL生效。将普通变量的值给输出
INSERT INTO t_student(id,name,age) VALUES(NULL,'dayu',22); --
SET flag = 2; -- 如果处理程序是EXIT,那么就不会执行到这一步了
SET result = flag; -- 将普通变量的值给输出
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号
CALL insertStu(@result);
SELECT @result,@info; -- @info没有申明就能调用到,可能是是全局变量吧 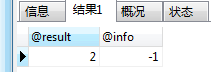
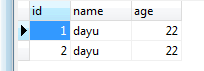
很奇怪,书上说如果遇到异常,将会执行定义条件后面的存储过程,但是从实际情况来看,当前的存储过程都是正确的,@info变量的值却也是-1,我自己也不是太能理解。@result的值为2的结果说明了存储过程执行到结尾。从表中的结果来看,也是正确的插入了两条数据。
在回头琢磨一下书的话:sp_statement参数为程序语句段,表示在遇到定义错误时,需要执行的存储过程或者函数。可能这里欠妥吧。
总之,下面的核心知识点没有疑问:在声明条件后并遇到相关的错误条件后,那就看应该怎么处理。如果是EXIT,那么存储过程只生效到错误处的上一条SQL。如果是CONTINUE,那么将会忽略掉执行错误的SQL,继续执行下面的其它存储过程。
阅读更多
目录贴:从头开始学MySQL——-目录帖
关于博主
博主小大宇,毕业于某本科院校计算机专业,Java高级后端工程师,开发组组长。熟悉JAVA语言,对多线程并发、大型分布式架构等领域有一定的经验。拥有大量原创博客,博客访问量达五十万人次, 追求技术,热爱分享。现就职于国内某顶尖大型金融互联网数据公司,日处理海量金融数据,提供海量数据高并发解决方案,兼职金融业务顾问。
小老弟,你看我都这么努力的分享知识给你了,鼓励一下又何妨

大宇期待与你们共同进步!同时也非常感谢最近兄弟们的支持!

推荐阅读SpringBoot系列
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/171435.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
