大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺

绪论
最近由于小编颈椎病犯了,所以最近停更了文章,今天下午刚收到几千里地老父亲寄来的艾灸贴,晚上贴上之后,伴随着火辣辣的感觉开始创作现在这篇文章;若大家get到了东西,请爱心三连。
废话不再多言,下面我们进入正题。
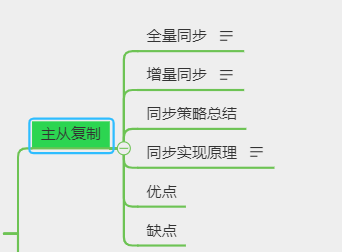
主从复制
同步策略
- 全量同步
时机:slave初始化阶段;
机制:slave服务器需要将master服务器上的所有数据都复制一份。 - 增量同步
时机:slave初始化之后且正常工作;
机制:master服务器每执行一次新的写操作命令同步到slave服务器上,从服务器接收并执行该写命令操作;
总结
- 主、从服务器刚建立连接时,采用全量同步;
- 全量同步结束且正常工作,则新的写命令采用增量同步;
- 此外,从服务器(slave)可以任意时刻发起全量同步命令;
- 总之,redis策略,正常工作之后先进行增量同步,如失败,则要求从服务器发起全量同步。
同步过程
全量复制
- 从服务器连接主服务器时,发送SYNC命令;
- 主服务器接收SYNC命令后,执行bgsave命令开始生成RDB文件,并将之后所有的写入命令存储到缓冲区;
- 主服务器bgsave命令执行结束后,向所有的从服务器发送RDB快照文件,发送期间所有的写入命令继续存储到缓冲区;
- 从服务器接收到快照文件之后,替换旧的快照文件,并载入数据;
- 主服务器传输结束快照文件后,将缓冲区中的所有写入命令发给从服务器;
- 从服务器载入快照文件结束后,开始接收命令请求,并执行来自主服务器缓冲区的写命令;(从服务器初始化完成);
- 主服务器每执行一个写命令,就会给从服务器发送相同的写命令,从服务器接收并执行写命令(从服务器初始化完成之后的操作:增量);
部分复制
-
工作原理:
主服务器端为复制流维护一个内存缓冲区(in-memory backlog)。主从服务器都维护一个复制偏移量(replication offset)和master run id ,
当连接断开时,从服务器会重新连接上主服务器,然后请求继续复制,假如主从服务器的两个master run id相同,并且指定的偏移量在内存缓冲
区中还有效,复制就会从上次中断的点开始继续。如果其中一个条件不满足,就会进行完全重新同步(在2.8版本之前就是直接进行完全重新同步)。
因为主运行id不保存在磁盘中,如果从服务器重启了的话就只能进行完全同步了。 -
工作过程:
- 当主从节点之间网络出现中断时,如果超过了 repl-timeout 时间,主节点会认为从节点故障并中断复制连接。
- 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在复制积压缓冲区( repl-backlog-buffer ),依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
- 当主从节点网络恢复后,从节点会再次连上主节点。
- 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们作为 psync 参数发送给主节点,要求进行补发复制操作。
- 主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送 +CONTINUE 响应,表示可以进行部分复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
扩展点:
服务器运行ID(run_id):每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;run_id用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的run_id。
总结
特点
a. 采用异步复制的方式;
b. 一个master服务器可以存着多个slave服务器;每个slave服务器可以接受其他slave服务器的连接;
c. 无论对于master、slave服务器都是非阻塞的,master服务器进行主从复制期间时,master服务器依然可以处理外部访问请求;
而slave服务器依然可以处理外部的查询请求,但是查询的结果为旧数据。
优点
a. 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
b. 为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
c. Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
d. Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
e. Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
缺点
a. Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
c. 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
d. Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/170311.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
