大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
思维导图

本篇只涉及到导图的右侧,只讲述硬盘的结构
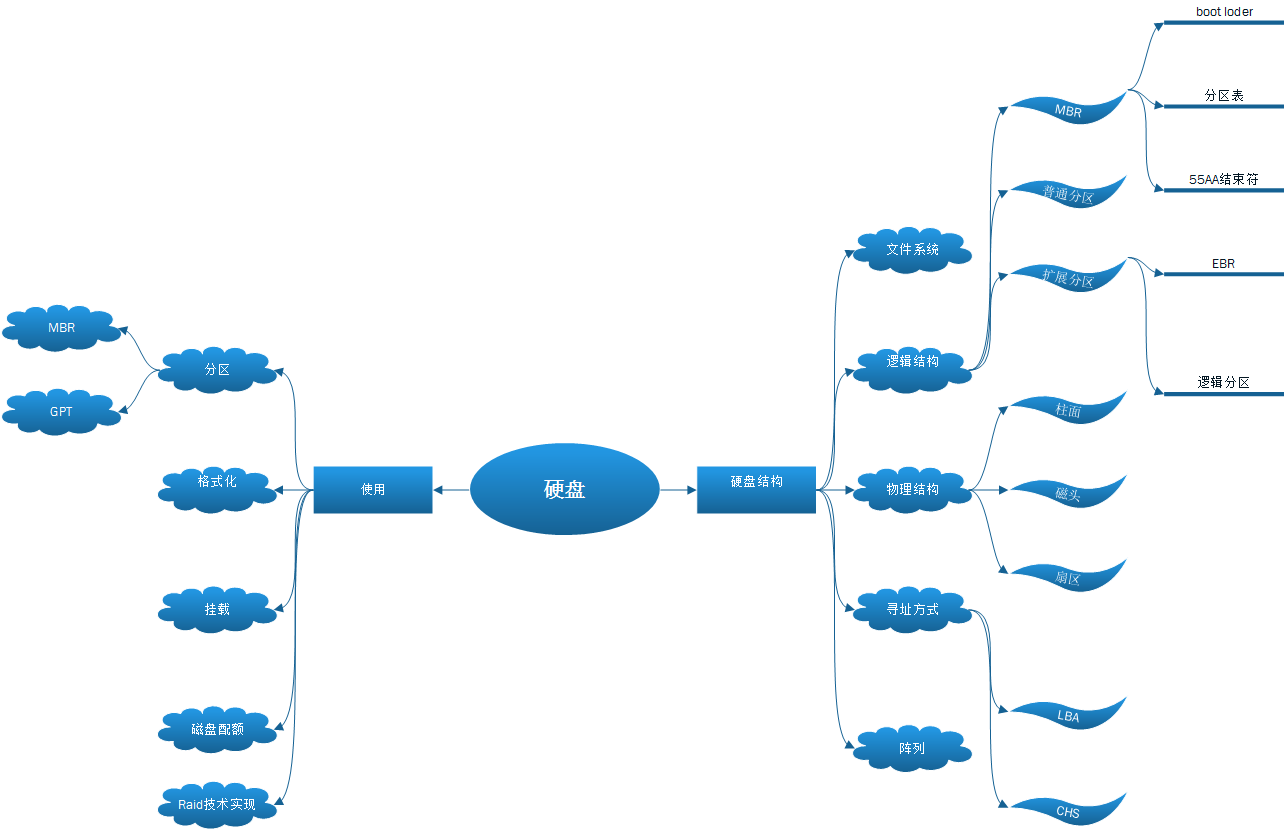
硬盘的物理结构
硬盘的物理结构是比较复杂的,这里我们只需要知道最常用到的几个术语即可,也就是chs寻址中所涉及到的结构
- 磁头(Heads):每张磁片的正反两面各有一个磁头,一个磁头对应一张磁片的一个面。因此,用第几磁 头就可以表示数据在哪个磁面。
- 柱面(Cylinder):所有磁片中半径相同的同心磁道构成“柱面”,意思是这一系列的磁道垂直叠在一起,就形成一个柱面的形状。简单地理解,柱面数=磁道数。
- 扇区(Sector):将磁道划分为若干个小的区段,就是扇区。虽然很小,但实际是一个扇子的形状,故称为扇区。每个扇区的容量为512字节。
硬盘结构图解:
硬盘读写过程
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
所以,数据的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数据也按照这种方式进行,这样就提高了硬盘的读/写效率。
寻址方式
首先,我们需要了解寻址是在干嘛?
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
所以当我们需要对磁盘进行读写操作时就涉及到了对磁盘进行定位操作,我们要去找到要存储数据或者取数据的这个扇区,而寻址就是一种定位。更恰当的讲,寻址就是利用CHS告诉你,你住在某栋楼几层几房
CHS寻址
由硬盘结构图我们可以清楚地了解到硬盘三大件的含义,利用这三大件催生出了一种以扇区为单位的寻址方式CHS.知道了磁头数、柱面数、扇区数,就可以很容易地确定数据保存在硬盘的哪个位置。也很容易确定硬盘的容量,其计算公式是:
硬盘容量=磁头数×柱面数×扇区数×512字节
CHS是一个三元组,组成如下:
1. 一共24个 bit位。
2. 其中前10位表示cylinder,中间8位表示head,后面6位表示sector。
3. 最大寻址空间
LBA寻址
计算机技术日新月异,由于CHS寻址技术最多只能用于8G大小的硬盘,所以,在如今的生活中我们使用LBA进行寻址。对于LBA寻址,我们只需要知道以下内容
- LBA采用48个bit位寻址,最大寻址空间128PB。
- LBA编址方式将CHS这种三维寻址方式转变为一维的线性寻址,它把硬盘所有的物理扇区的C/H/S编号通过一定的规则转变为一线性的编号。简单来讲,原本你需要的信息是5栋7层02户,但是现在LBA通过一定的运算,你现在只需要知道你要去第N个房间就好了,由三维的定位,变成了现在的一围定位
计算公式
LBA(逻辑扇区号)=磁头数 × 每磁道扇区数 × 当前所在柱面号 + 每磁道扇区数 × 当前所在磁头号 + 当前所在扇区号 – 1
硬盘的分区结构
我们在linux下经常使用两种分区结构,一种是MBR分区结构,一种是GPT分区结构
MBR分区结构
我们来看下面这张图,当我们对磁盘以MBR的结构进行分区的时候,磁盘的结构就如下图所示
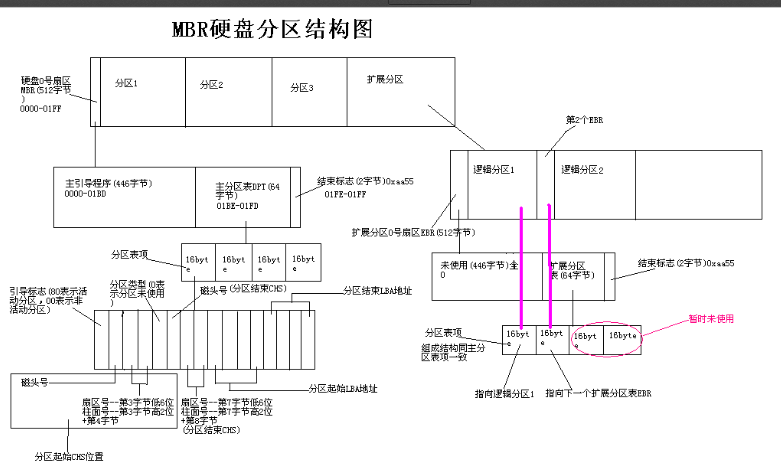
0号扇区内容
我们经常把硬盘第一个扇区叫做MBR扇区,这512字节包含三块儿内容
- 引导代码:引导代码占MBR分区的前446字节,负责整个系统启动。如果引导代码被破坏,系统将无法启动。
- MBR分区表:引导代码后的64个字节,是整个硬盘的分区表。有四张分区表
- MBR结束标志:占MBR扇区最后2个字节,一直为“55 AA”。
在分区表中记录分区的起始地址和结束地址(既可以使用CHS寻址也可以使用LBA进行寻址),这两个地址相减就是我们这个分区的实际容量
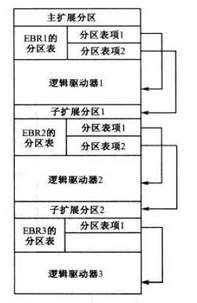
扩展分区
由于MBR仅仅为分区表保留了64字节的存储空间,而每个分区则占用16字节的空间,也就是只能分4个分区,而4个分区在实际情况下往往是不够用的。因此就有了扩展分区,扩展分区中的每个逻辑分区的分区信息都存在一个类似MBR的扩展引导记录(简称EBR)中,扩展引导记录包括分区表和结束标志“55 AA”,没有引导代码部分。也就是EBR中的前446个字节是空的
扩展分区的结构如下图所示
如上图:EBR中分区表的第一项描述第一个逻辑分区,第二项指向下一个逻辑分区的EBR。如果下一个逻辑分区不存在,第二项就不需要了。
MBR分区的结构大致就介绍到这了。如果硬盘的MBR被破坏,可以复制其他硬盘的MBR到故障盘,然后修复分区表,也可以初始化故障盘然后修复分区表。
GPT分区结构
GPT磁盘分区结构解决了MBR只能分4个主分区的的缺点,理论上说,GPT磁盘分区结构对分区的数量好像是没有限制的。但某些操作系统可能会对此有限制。
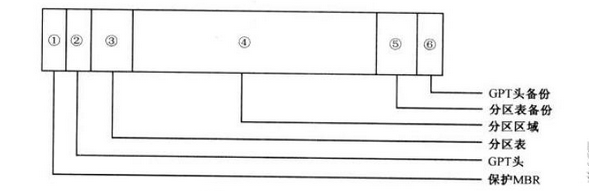
- 保护MBR
保护MBR位于GPT磁盘的第一扇区,也就是0号扇区,有磁盘签名,MBR磁盘分区表和结束标志组成,没有引导代码。而且分区表内只有一个分区表项,这个表项GPT根本不用,只是为了让系统认为这个磁盘是合法的。 - GPT头
GPT头位于GPT磁盘的第二个扇区,也就是1号扇区,该扇区是在创建GPT磁盘时生成,其作用是定义分区表的位置和大小。GPT头还包含头和分区表的校验和,这样就可以及时发现错误。 - 分区表
分区表位于GPT磁盘的2-33号扇区,一共占用32个扇区,能够容纳128个分区表项。每个分区表项大小为128字节。因为每个分区表项管理一共分区,所以允许GPT磁盘创建128个分区。
每个分区表项中记录着分区的起始,结束地址,分区类型的GUID,分区的名字,分区属性和分区GUID。 - 分区区域
GPT分区区域就是用户使用的分区,也是用户进行数据存储的区域。分区区域的起始地址和结束地址由GPT分区表定义。 - GPT头备份
GPT头有一个备份,放在GPT磁盘的最后一个扇区,但这个GPT头备份并非完全GPT头备份,某些参数有些不一样。复制的时候根据实际情况更改一下即可。 - 分区表备份
分区区域结束后就是分区表备份,其地址在GPT头备份扇区中有描述。分区表备份是对分区表32个扇区的完整备份。如果分区表被破坏,系统会自动读取分区表备份,也能够保证正常识别分区。
GPT的分区结构相对于MBR要简单许多,并且分区表以及GPT头都有备份。
文件系统
我们把最初始的硬盘比作一个毛坯房,那么对硬盘进行分区,就相当于给毛坯房通水电,对硬盘进行格式化(添加文件系统),就相当于对毛坯房进行装修。毛坯房只有通水电,装修之后才能住人;同理只有将硬盘进行分区和格式化,硬盘才能够使用。
文件系统的定义
文件系统是操作系统用于明确存储设备(常见的是磁盘,也有基于NAND Flash的固态硬盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。
文件系统的结构
我们知道Linux操作系统支持很多不同的文件系统,比如ext2、ext3、XFS、FAT等等,而Linux把对不同文件系统的访问交给了VFS(虚拟文件系统),VFS能访问和管理各种不同的文件系统。所以有了区之后就需要把它格式化成具体的文件系统以便VFS访问。标准的Linux文件系统Ext2是使用「基于inode的文件系统].
- 我们知道一般操作系统的文件数据除了文件实际内容外,还带有很多属性,例如 Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、 时间参数等),文件系统通常会将属性和实际内容这两部分数据分别存放在不同的区块
- 在基于inode的文件系统中,权限与属性放置到inode中,实际数据放到data block 区块中,而且inode和data block都有编号.
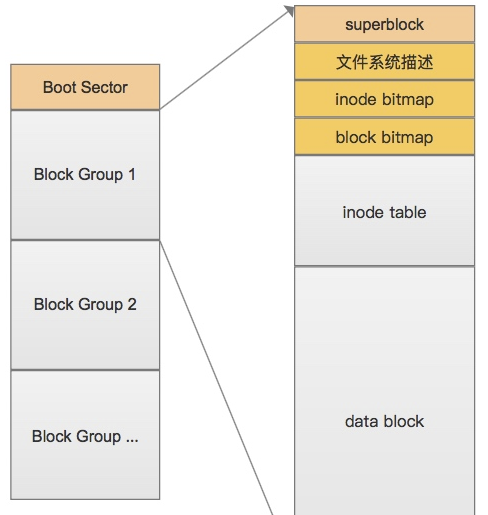
如上图所示,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序, 这个设计让我们能将不同的引导装载程序安装到个别的文件系统前端,而不用覆盖整个硬盘唯一的MBR, 也就是这样才能实现多重引导的功能
- 把每个区进一步分为多个块组 (block group),每个块组有独立的inode/block体系如果文件系统高达数百 GB 时,把所有的 inode 和block 通通放在一起会因为 inode 和 block的数量太庞大,不容易管理
- 分区是用户的分区,实际计算机管理时还有个最适合的大小,于是计算机会进一步的在分区中分块
- 每个块组实际还会分为分为6个部分,除了inode table 和 data block外还有4个附属模块,起到优化和完善系统性能的作用
raid磁盘阵列技术
前面讲的都是磁盘内部的结构,下面我们来讨论一下多个磁盘如何组合能发挥更大的作用。我们采用raid技术的优点:
- 提升读写性能
- 增加容错能力,也就是增加硬盘的可用性
raid -0

- 要实现RAID0必须要有两个以上硬盘驱动器,RAID0实现了带区组,数据并不是保存在一个硬盘上,而是分成数据块保存在不同驱动器上。因为将数据分布在不同驱动器上,所以数据吞吐率大大提高,驱动器的负载也比较平衡。如果刚好所需要的数据在不同的驱动器上效率最好。它不需要计算校验码,实现容易。它的缺点是它没有数据差错控制,如果一个驱动器中的数据发生错误,即使其它盘上的数据正确也无济于事了。不应该将它用于对数据稳定性要求高的场合。如果用户进行图象(包括动画)编辑和其它要求传输比较大的场合使用RAID0比较合适。
- 同时,RAID可以提高数据传输速率,比如所需读取的文件分布在两个硬盘上,这两个硬盘可以同时读取。那么原来读取同样文件的时间被缩短为1/2。在所有的级别中,RAID 0的速度是最快的。但是RAID 0没有冗余功能的,如果一个磁盘(物理)损坏,则所有的数据都无法使用。
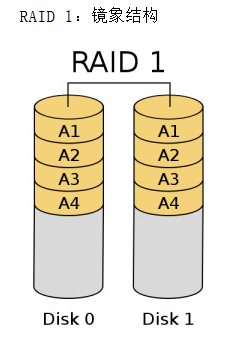
raid -1
对于使用这种RAID1结构的设备来说,RAID控制器必须能够同时对两个盘进行读操作和对两个镜象盘进行写操作。通过下面的结构图您也可以看到必须有两个驱动器。因为是镜象结构在一组盘出现问题时,可以使用镜象,提高系统的容错能力。它比较容易设计和实现。每读一次盘只能读出一块数据,也就是说数据块传送速率与单独的盘的读取速率相同。因为RAID1的校验十分完备,因此对系统的处理能力有很大的影响,通常的RAID功能由软件实现,而这样的实现方法在服务器负载比较重的时候会大大影响服务器效率。当您的系统需要极高的可靠性时,如进行数据统计,那么使用RAID1比较合适。而且RAID1技术支持”热替换”,即不断电的情况下对故障磁盘进行更换,更换完毕只要从镜像盘上恢复数据即可。当主硬盘损坏时,镜像硬盘就可以代替主硬盘工作。镜像硬盘相当于一个备份盘,可想而知,这种硬盘模式的安全性是非常高的,RAID 1的数据安全性在所有的RAID级别上来说是最好的。
raid -5
从它的示意图上可以看到,它的奇偶校验码存在于所有磁盘上,其中的p0代表第0带区的奇偶校验值,其它的意思也相同。RAID5的读出效率很高,写入效率一般,块式的集体访问效率不错。因为奇偶校验码在不同的磁盘上,所以提高了可靠性,允许单个磁盘出错。RAID5也是以数据的校验位来保证数据的安全,但它不是以单独硬盘来存放数据的校验位,而是将数据段的校验位交互存放于各个硬盘上。这样,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。硬盘的利用率为n-1。 但是它对数据传输的并行性解决不好,而且控制器的设计也相当困难。

raid -10 和raid -01
至少需要4块硬盘
DISK1, DISK2, DISK3, DISK4
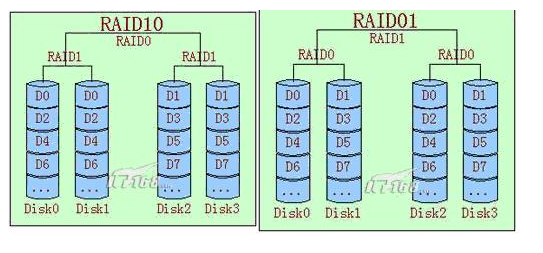
- RAID-01 不可以两边RAID0中各坏一块硬盘,但可以在单边同时坏掉单边的两块硬盘。
原因:假如DISK1 A1,DISK A2,DISK3 B1, DISK B2
A(A1,A2) B (B1,B2)
1.A中和B中的任何一块硬盘同进坏了,则都破坏了RAID0技术。所有整
个硬盘数据被破坏。因此不允A和B中的任何一个块硬盘同时损坏.
2.当中A中所有硬盘坏了,因为B中的RAID0的格式保持完整,因做的是
RAID0+1,I不影响数据的完整性.所以允许A中所有磁盘损坏.同理B也是
这样. - RAID-10可以两边RAID1中各坏一块硬盘,但不能同时坏掉单边的两个硬盘。
原因:
1.A中的任何一个硬盘都可以坏,因为做的是RAID1格式,同时B中的任何一
个硬盘的数据也可坏,因为也做的是RAID1的格式.所以允许A和B中的任何一块硬盘同时损坏,即不影响数据的完整性.
2.A中(B中)的两块同时硬盘损坏,从图中可以看到,数据无法保持完整性.所
以不允许单边的两块硬盘同时损坏
但是,当硬盘的数量比较多的时候,能有一个直观的反应就是,使用raid-10会使得服务器的稳定性能更高,具有高可用性。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169753.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
