大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1、KL散度的概念
KL散度(Kullback-Leibler Divergence)一般用于度量两个概率分布函数之间的“距离”,其定义如下(参考文献[2]2、[4]4):
K L [ P ( X ) ∥ Q ( X ) ] = ∑ x ∈ X [ P ( x ) log P ( x ) Q ( x ) ] = E x ∼ P ( x ) [ log P ( x ) Q ( x ) ] K L[P(X) \| Q(X)]=\sum_{x \in X}\left[P(x) \log \frac{P(x)}{Q(x)}\right]=E_{x \sim P(x)}\left[\log \frac{P(x)}{Q(x)}\right] KL[P(X)∥Q(X)]=x∈X∑[P(x)logQ(x)P(x)]=Ex∼P(x)[logQ(x)P(x)]
由于KL散度的计算公式中对 x x x 进行了积分(连续型随机变量)或求和(离散型随机变量),因此KL与 x x x 无关,因此也可以记为 K L [ P ∥ Q ] K L[P \| Q] KL[P∥Q] 。
注意到KL散度的定义中 K L [ P ( X ) ∥ Q ( X ) ] K L[P(X) \| Q(X)] KL[P(X)∥Q(X)] 关于 P ( X ) P(X) P(X) 、 Q ( X ) Q(X) Q(X) 并不对称。根据公式,KL散度不满足对称性,即: K L [ P ( X ) ∥ Q ( X ) ] ≠ K L [ Q ( X ) ∥ P ( X ) ] K L[P(X) \| Q(X)] ≠ K L[Q(X) \| P(X)] KL[P(X)∥Q(X)]=KL[Q(X)∥P(X)] ,因此,KL散度显然不是数学意义上的“度量”。
KL散度的典型应用场景如下:假设某优化问题中, P ( X ) P(X) P(X) 是真实分布(true distribution), Q ( X ) Q(X) Q(X) 是一个用于拟合 P ( X ) P(X) P(X) 的近似分布(approximate distribution),可以尝试通过修改 Q ( X ) Q(X) Q(X) 使得二者间的 K L [ P ( X ) ∥ Q ( X ) ] K L[P(X) \| Q(X)] KL[P(X)∥Q(X)] 尽可能小,来实现用 Q ( X ) Q(X) Q(X) 拟合 P ( X ) P(X) P(X) ,如下图所示[4]。
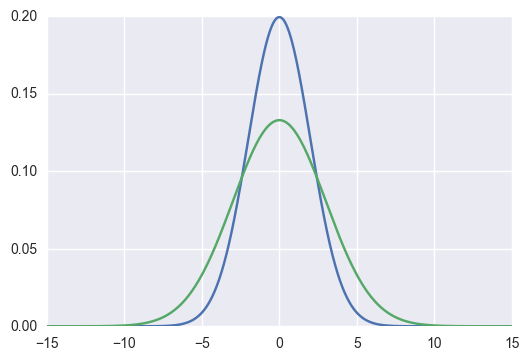

在上面的概率拟合应用场景下, K L [ P ( X ) ∥ Q ( X ) ] K L[P(X) \| Q(X)] KL[P(X)∥Q(X)] 也被称为前向KL散度(forward Kullback-Leibler Divergence),将 K L [ Q ( X ) ∥ P ( X ) ] K L[Q(X) \| P(X)] KL[Q(X)∥P(X)] 称为反向KL散度(reverse Kullback-Leibler Divergence)。
这里需要注意的是,只有在概率拟合的应用场景下(也就是确定了真实分布和拟合分布两个角色之后),前向KL散度 K L [ P ( X ) ∥ Q ( X ) ] K L[P(X) \| Q(X)] KL[P(X)∥Q(X)] 和反向KL散度 K L [ Q ( X ) ∥ P ( X ) ] K L[Q(X) \| P(X)] KL[Q(X)∥P(X)] 的定义才是有意义的,否则二者只是相同公式改变正负号、并交换 P P P 和 Q Q Q 符号表示之后的平凡结果。
2、两类KL散度拟合效果的定性分析
极小化前向KL代价下的拟合行为特性:寻找均值(Mean-Seeking Behaviour)
前向KL的计算式中, P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x) 在每个样本点 x x x 上的差异程度被 P ( x ) P(x) P(x) 加权平均,我们基于此对前向KL的特性进行分析。
考虑随机变量 X X X 的子集 X 0 = x ∣ P ( x ) = 0 X_0 = { x|P(x) = 0 } X0=x∣P(x)=0 ,由于 P ( x ) P(x) P(x) 是前向KL公式中的权重系数,因此 X 0 X_0 X0 中的元素实际上对前向KL的值没有任何影响。换言之,对任意 x ∈ X 0 x \in X_0 x∈X0 ,无论 P ( x 0 ) P(x_0) P(x0)与 Q ( x 0 ) Q(x_0) Q(x0) 相差多大都对前向KL的计算结果毫无影响,因此前向KL值不受 Q ( x ) Q(x) Q(x) 在子集 { x ∣ P ( x ) = 0 } \{x|P(x) = 0\} {
x∣P(x)=0} 上取值的影响。在极小化前向KL散度的过程中,每当 P ( x ) = 0 P(x) = 0 P(x)=0 , Q ( x ) Q(x) Q(x) 就会被无视。从连续性角度推理,最小化前向KL散度倾向于忽视“ Q ( x ) Q(x) Q(x) 在满足 P ( x ) P(x) P(x) 近似为 0 的随机变量取值集合上的拟合精度”,而去更努力的实现“ Q ( x ) Q(x) Q(x) 在满足 P ( x ) > 0 P(x) > 0 P(x)>0的随机变量取值集合上的拟合精度”。上述分析结论总结如下:
Wherever P ( ⋅ ) P(·) P(⋅) has high probability, Q ( ⋅ ) Q(·) Q(⋅) must also have high probability.[4]
下图展示了使用前向KL散度代价拟合一个多峰(实际上是双峰)分布的效果示意图(参考文献[4])。
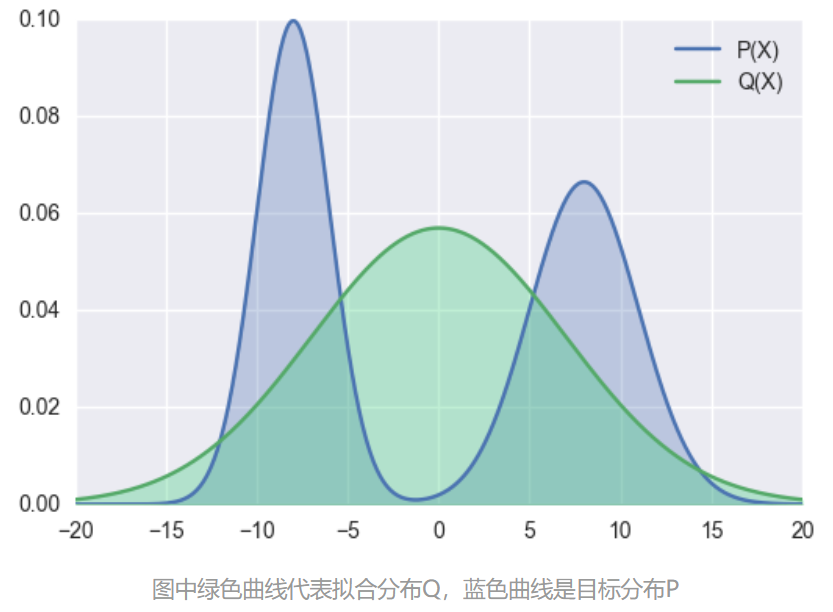
前向KL散度的这种特性一般也被称为 zero avoiding,原因是它倾向于避免在任何 P ( x ) > 0 P(x) > 0 P(x)>0的位置 x x x 使得 Q ( X ) = 0 Q(X) = 0 Q(X)=0 [4]。
极小化反向KL代价下的拟合行为特性:搜寻模态(Mode-Seeking Behaviour)
在反向KL中,差异加权求和时的权重系数是 Q ( x ) Q(x) Q(x) 。此时, P ( x ) P(x) P(x) 在子集 { x ∣ Q ( x ) = 0 } \{ x|Q(x) = 0 \} {
x∣Q(x)=0} 的取值不影响反向KL值的计算,而当 Q ( x ) > 0 Q(x) >0 Q(x)>0时, Q ( x ) Q(x) Q(x) 与 P ( x ) P(x) P(x) 的差异需要尽可能小以使得反向KL值尽可能小。上述分析结论总结如下(参考文献[4]):
Wherever Q ( ⋅ ) Q(·) Q(⋅) has high probability, P ( ⋅ ) P(·) P(⋅) must also have high probability.[4]
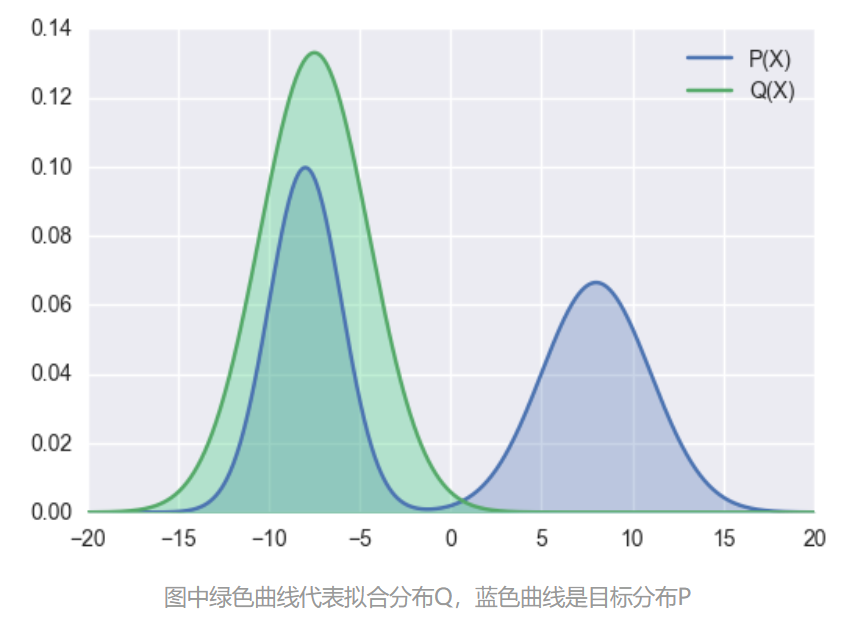
下图展示了使用前向反向KL散度代价拟合一个多峰(实际是双峰)分布的效果示意图(参考文献[4])。
关于在前向KL拟合特性分析中,为什么说当 P ( x ) P(x) P(x)近似为 0 时,无论 Q ( x ) Q(x) Q(x) 的取值如何(即使绝对值非常大),一般都不会对前向KL散度计算产生影响的原因定性的论述如下。
首先,如果当 P ( x ) → 0 P(x) \rightarrow 0 P(x)→0 时, Q ( x ) Q(x) Q(x) 并不趋近于0,用数学语言可以描述为:存在一个 ε > 0 \varepsilon > 0 ε>0, 有 Q ( x ) > ε Q(x) > \varepsilon Q(x)>ε。那么这时一定有
∣ P ( x ) log ( Q ( x ) ) ∣ < ∣ P ( x ) log ε ∣ → 0 |P(x) \log (Q(x))|<|P(x) \log \varepsilon| \rightarrow 0 ∣P(x)log(Q(x))∣<∣P(x)logε∣→0
这说明,当概率分布 Q ( x ) Q(x) Q(x)有下大于0的下界(注意:由于 Q Q Q 是概率分布,所以 Q ( x ) Q(x) Q(x) 取值本就一定在 [ 0 , 1 0,1 0,1] 上)时, P ( x ) log ( Q ( x ) ) P(x) \log (Q(x)) P(x)log(Q(x)) 在 P ( x ) P(x) P(x) 近似为0时实际可忽略的。
其次,考虑如果 Q ( x ) Q(x) Q(x) 也趋向于0,也就是 ∣ l o g Q ( x ) ∣ → ∞ |logQ(x)| \to \infty ∣logQ(x)∣→∞ 时, P ( x ) log ( Q ( x ) ) P(x) \log (Q(x)) P(x)log(Q(x)) 的极限是否还是0?具体是如下问题:假设当 P → 0 P \to 0 P→0 时,也有 Q → 0 Q \to 0 Q→0 ,且二者趋于0的“速度”是相近的,求 P ( x ) log ( Q ( x ) ) P(x) \log (Q(x)) P(x)log(Q(x)) 的极限。不妨将该问题按如下方法求解:
lim x → 0 x ln x = lim n → ∞ 1 n ln 1 n = − lim n → ∞ ln n n = 0 \lim _{x \rightarrow 0} x \ln x=\lim _{n \rightarrow \infty} \frac{1}{n} \ln \frac{1}{n}=-\lim _{n \rightarrow \infty} \frac{\ln n}{n}=0 x→0limxlnx=n→∞limn1lnn1=−n→∞limnlnn=0
上面的定性证明过程中的第一个等号左边的表达式,其实也可以使用洛必达法则(L’Hospital’s rule)求解。该证明的意义在于说明:若 P l o g Q PlogQ PlogQ 中的 P P P 和 Q Q Q 以近似相同的速度趋向于0,则 P l o g Q PlogQ PlogQ 也会趋向于0。这背后隐含的意义是:只要 P ( x ) P(x) P(x) 在 x x x 处接近于0,那么 Q ( x ) Q(x) Q(x) 无论取何值(这里的“无论”是指 Q Q Q 有大于0的下界或至多是 P P P 的等价无穷小量),那么 P ( x ) l o g ( Q ( x ) ) P(x)log(Q(x)) P(x)log(Q(x)) 就是可忽略的。这也就定性的证明,在拟合中 Q Q Q 在在 P ( x ) P(x) P(x) 中接近于0的那部分自变量集合上花费精力基本是无意义的,因此拟合结果 Q Q Q 会表现为倾向于拟合 P > 0 P > 0 P>0 的那些区域。
其他示例
前向KL和反向KL拟合效果的二维多峰(实际上是双峰 P P P )分布情况示例(参考文献[1]):
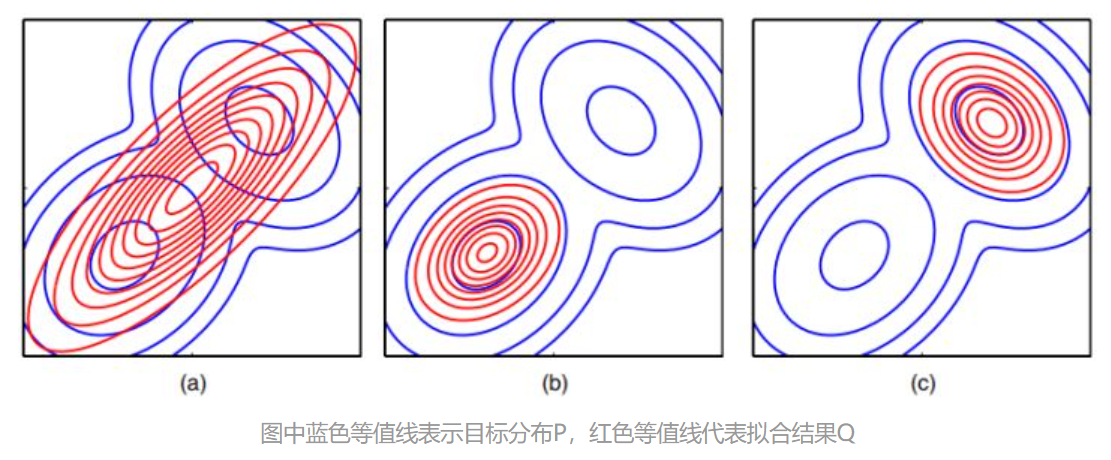
上面图中蓝色的轮廓线代表一个有两个高斯分布组成双峰分布 P ( x ) P(x) P(x) ,红色的轮廓线是使用单一高斯分布在最小化KL散度意义下对 P ( x ) P(x) P(x) 进行拟合得到的最佳结果。其中图(a)是拟合代价选择前向KL散度 [公式] 时的拟合效果,图(b)时拟合代价选择反向KL散度 K L ( P ∣ ∣ Q ) KL(P||Q) KL(P∣∣Q) 时的拟合效果,图©和图(b)使用相同的代价但展示的是到达反向KL散度代价的另外一个局部极小值点的效果。
3、两类KL散度拟合效果的数学推导
考虑到需要用人工设计的近似分布 Q θ ( X ) Q_{\theta }(X) Qθ(X) 来拟合真实分布 P ( x ) P(x) P(x) ,这里下标 θ \theta θ 强调 Q ( x ) Q(x) Q(x) 是一个受到参数 θ \theta θ控制的分布。例如: Q ( x ) Q(x) Q(x) 是正态分布 N ( μ , σ 2 ) N(\mu ,\sigma^2 ) N(μ,σ2) , P P P是正态分布 N ( μ , σ 0 2 ) N(\mu ,\sigma_0^2 ) N(μ,σ02) ,现在希望用 Q Q Q 来拟合 P P P ,其中 Q Q Q 的均值和方差 { μ , σ 2 } \{\mu ,\sigma^2\} {
μ,σ2} 就是拟合过程中可以调整的参数 θ \theta θ 。于是基于前向KL和反向KL代价的分布拟合问题分别转化为以下两个优化问题(参考文献[4]):
命题1. 极小化前向KL: arg min θ K L ( P ∣ ∣ Q θ ) \arg \min _{\theta} KL(P||Q_{
{\theta}}) argminθKL(P∣∣Qθ)等价于对参数 θ {\theta} θ 的极大似然估计。
命题2. 极小化反向KL: arg min θ K L ( Q θ ∣ ∣ P ) \arg \min _{\theta} KL(Q_{
{\theta}}||P) argminθKL(Qθ∣∣P) 相当于在要求 Q θ Q_{
{\theta}} Qθ在拟合 P P P 的同时尽可能保持单一模态。
首先,证明命题一,过程如下:
arg min θ K L ( P ∣ ∣ Q ) = arg min θ ( E X ∼ P [ − log Q θ ( X ) ] ) + H ( P ( X ) ) \arg \min _{\theta} KL(P||Q) = \arg \min _{\theta}\left(E_{X \sim P}\left[-\log Q_{\theta}(X)\right]\right)+H(P(X)) argθminKL(P∣∣Q)=argθmin(EX∼P[−logQθ(X)])+H(P(X))
= arg min θ E X ∼ P [ − log Q θ ( X ) ] =\arg \min _{\theta} E_{X \sim P}\left[-\log Q_{\theta}(X)\right] =argθminEX∼P[−logQθ(X)]
= arg max θ E X ∼ P [ log Q θ ( X ) ] =\arg \max _{\theta} E_{X \sim P}\left[\log Q_{\theta}(X)\right] =argθmaxEX∼P[logQθ(X)]
≈ arg max θ E X ∼ P data [ log Q θ ( X ) ] \approx \arg \max _{\theta} E_{X \sim P_{\text {data }}}\left[\log Q_{\theta}(X)\right] ≈argθmaxEX∼Pdata [logQθ(X)]
其中 H ( P ( X ) ) = − ∑ x [ P ( x ) log P ( x ) ] H(P(X))=-\sum_{x}[P(x) \log P(x)] H(P(X))=−∑x[P(x)logP(x)],代表信息熵(Entropy)。上述推导的最终结果正好就是极大似然代价的定义式。
推导过程分析:上面的推导过程中,第2行到第3行利用了 H ( P ( X ) ) H(P(X)) H(P(X)) 是与优化自变量 θ \theta θ 无关的,故删除该项不会改变最优化问题的解,因此可以直接省略。第3行到第4行则是通过来将求最小值问题转化为求最大值问题消去负号。第4行到第5行利用了机器学习训练中一般假设特征在样本集上的分布可以被近似看作真实分布,即: H ( P ( X ) ) = − ∑ x [ P ( x ) log P ( x ) ] H(P(X))=-\sum_{x}[P(x) \log P(x)] H(P(X))=−∑x[P(x)logP(x)] 。
综上命题1成立。
其次,证明命题2,推导如下:
arg min θ K L ( P ∣ ∣ Q ) = arg min θ ( E X ∼ P [ − log Q θ ( X ) ] ) + H ( Q θ ( X ) ) \arg \min _{\theta} KL(P||Q) = \arg \min _{\theta}\left(E_{X \sim P}\left[-\log Q_{\theta}(X)\right]\right)+H(Q_{\theta}(X)) argθminKL(P∣∣Q)=argθmin(EX∼P[−logQθ(X)])+H(Qθ(X))
观察上面的等式右侧 [公式] 中的两项:
E X ∼ Q θ [ − log P ( X ) ] + H ( Q θ ( X ) ) E_{X \sim Q_{\theta}}[-\log P(X)]+H\left(Q_{\theta}(X)\right) EX∼Qθ[−logP(X)]+H(Qθ(X))
要想令上面两项之和最小,就意味着要找到参数 θ {\theta} θ 的一个合适的取值,使得上面两项中的每一项 E X ∼ Q θ [ − log P ( X ) ] E_{X \sim Q_{\theta}}[-\log P(X)] EX∼Qθ[−logP(X)] 和 H ( Q θ ( X ) ) H\left(Q_{\theta}(X)\right) H(Qθ(X)) 都尽可能小。根据熵的性质可知,当 Q θ Q_{
{\theta}} Qθ 越接近于均匀分布(当 X X X 是连续随机变量时,若 X X X 是离散型随机变量便是离散取值的等概率分布,总之就是都可以看作等高多峰分布的极限情况)第二项 H ( Q θ ( X ) ) H\left(Q_{\theta}(X)\right) H(Qθ(X)) 的值越大,反之当 Q θ Q_{
{\theta}} Qθ 越去向于单一模态分布(可以通俗理解为单峰分布) H ( Q θ ( X ) ) H\left(Q_{\theta}(X)\right) H(Qθ(X)) 的值越小。因此反向KL散度相当于在要求 Q θ Q_{
{\theta}} Qθ 在拟合 P P P 的同时尽可能保持单一模态。
综上命题2成立。
4、KL散度的计算
考虑有两个样本分布 P P P 和 Q Q Q 如下:
| 取值类型 | x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | x 4 x_4 x4 |
|---|---|---|---|---|
| P P P | 3/5 | 1/5 | 2/5 | 0 |
| Q Q Q | 5/9 | 3/9 | 0 | 1/9 |
由于 P P P 和 Q Q Q 中都在某个取值上概率为 0,因此直接计算前向KL散度和反向KL散度
K L forward ( P ∥ Q ) = ∑ i = 1 4 [ P ( x i ) log P ( x i ) Q ( x i ) ] K L_{\text {forward }}(P \| Q)=\sum_{i=1}^{4}\left[P\left(x_{i}\right) \log \frac{P\left(x_{i}\right)}{Q\left(x_{i}\right)}\right] KLforward (P∥Q)=i=1∑4[P(xi)logQ(xi)P(xi)]
K L backward ( Q ∥ P ) = ∑ i = 1 4 [ Q ( x i ) log Q ( x i ) P ( x i ) ] K L_{\text {backward }}(Q \| P)=\sum_{i=1}^{4}\left[Q\left(x_{i}\right) \log \frac{Q\left(x_{i}\right)}{P\left(x_{i}\right)}\right] KLbackward (Q∥P)=i=1∑4[Q(xi)logP(xi)Q(xi)]
都会由于遇到分母为 0 的问题导致不可行。为此,介绍计算KL散度的平滑(Smoothing)方法[5]:
引入一个微小常量 ε \varepsilon ε,例如: ε = 1 0 − 3 \varepsilon=10^{-3} ε=10−3 ,然后定义平滑的分布 P ′ P’ P′ 和 Q ′ Q’ Q′ 如下:
| 取值类型 | x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | x 4 x_4 x4 |
|---|---|---|---|---|
| P P P | 3 / 5 − ε / 3 3/5 – \varepsilon/3 3/5−ε/3 | 1 / 5 − ε / 3 1/5 – \varepsilon/3 1/5−ε/3 | 2 / 5 − ε / 3 2/5 – \varepsilon/3 2/5−ε/3 | ε \varepsilon ε |
| Q Q Q | 5 / 9 − ε / 3 5/9 – \varepsilon/3 5/9−ε/3 | 3 / 9 − ε / 3 3/9 – \varepsilon/3 3/9−ε/3 | ε \varepsilon ε | 1 / 9 − ε / 3 1/9 – \varepsilon/3 1/9−ε/3 |
分别用 K L forward ( P ′ ∥ Q ′ ) K L_{\text {forward }}(P’ \| Q’) KLforward (P′∥Q′) 和 K L backword ( P ′ ∥ Q ′ ) K L_{\text {backword }}(P’ \| Q’) KLbackword (P′∥Q′) 作为 K L forward ( P ∥ Q ) K L_{\text {forward }}(P \| Q) KLforward (P∥Q) 和 K L backword ( P ∥ Q ) K L_{\text {backword }}(P \| Q) KLbackword (P∥Q) 的替代,这样正向KL和反向KL就都变得可以计算了。
5、KL散度 Python 实现
def kld_softmax(x, y):
px = get_dis(x)
py = get_dis(y)
softmax_x = softmax(px)
softmax_y = softmax(py)
KL = 0.0
for i in range(len(softmax_x)):
KL += softmax_x[i] * np.log(softmax_x[i] / softmax_y[i])
return KL
def kld_smooth(x, y):
px = get_dis(x)
py = get_dis(y)
# smoothing
px -= 0.001/3
py -= 0.001/3
KL = 0.0
for i in range(len(px)):
KL += px[i] * np.log(px[i] / px[i])
return KL
def softmax(x,t=1):
# 计算每行的最大值
row_max = x.max()
# 每行元素都需要减去对应的最大值,否则求exp(x)会溢出,导致inf情况
row_max=row_max.reshape(-1, 1)
x = x - row_max
# 计算e的指数次幂
x_exp = np.exp(x/t)
x_sum = np.sum(x_exp, keepdims=True)
s = x_exp / x_sum
return s
6、References
[1]. Pattern Recognition and Machine Learning.
[2]. KL Divergence for Machine Learning.
[3]. Intuitive Guide to Understanding KL Divergence.
[4]. KL Divergence: Forward vs Reverse.
[7]. GAP: Differentially Private Graph Neural Networks with Aggregation Perturbation
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169740.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
