大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章目录
-
- 一、java基础
- 二、hashMap相关问题
- 三、java多线程问题
-
- 3.1 实现多线程的方式
- 3.2 线程安全
- 3.3 多线程如何进行信息交互
- 3.4 多线程共用一个数据变量需要注意什么?
- 3.5 什么是线程池?如果让你设计一个动态大小的线程池,如何设计,应该有哪些方法?
- 3.6 volatile与synchronized区别
- 3.7 sleep和wait分别是哪个类的方法,有什么区别?
- 3.8 synchronized与lock的区别,使用场景,看过synchronized的源码没?
- 3.9 synchronized底层如何实现的?用在代码块和方法上有什么区别?
- 3.10 java中的NIO、BIO、AIO分别是什么
- 3.11 什么是java内存模型(java memory model jmm)
- 3.12 JVM线程死锁,你该如何判断是什么原因?如果用VisualVM,dump打印线程信息出来,会有哪些信息?
- 四、异常问题
- 五、加载问题
- 六、关键字的比较
- 七、字符串
- 八、java协议
- 九、其他
一、java基础
1.1 java 集合类问题
二、hashMap相关问题
2.1 HashMap的实现原理?
回答主要是三个方面:
hashmap基本原理;hashmap的put存源码解读;hashmap的get取源码解读;
hashmap是基于hash算法的key-value键值对,通过key可以快速的找到value值,解决了数组的增加和删除以及链表的查询效率低的问题。
public V put(K key, V value) {
if (key == null)//如果key为空,调用putForNullKey()处理
return putForNullKey(value);
int hash = hash(key);//通过key值获得hash码(看hash函数,是通过右移位,这种方式使数据散列均匀)
//通过indexFor()获得对应table中的索引
int i = indexFor(hash, table.length);//源码采用&的方式
//取出table表中的元素,并循环单链表,判断key是否存在
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//hash码相同,且对象相同key值相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
{
//新值替换旧值,并返回旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//key不存在,加入新的元素
modCount++;
addEntry(hash, key, value, i);//hash码每个key都对应唯一的hash码,i是table的索引(通过hash函数算出来的)
return null;
}
Hashmap通过调用put函数,实现键值对的存储。
- 为了保证
key的唯一性,一般选用final修饰的类型,比如基本类型的引用类型、String。
问:如果不用这些类型,别人把key都改了,取出来的值肯定就是错。
-
获得
hash值int hashhash(key);先得到key的hashcode值(因为每一个key的hashcode值都是唯一的),然后通过hash算法(底层是通过移位实现的),hash算法的目的就是让hashcode值能均匀的填充table表,而不是造成大量的集中冲突。 -
将
hash值与table数组的长度进行与运算,获得table数组下标int i = indexFor(hash,table.length);
问题:传统的方法是通过hashcode与table数组长度相除取余,这个使得table表中的数据分布不均匀,产生大量集中冲突。
- 通过下标获得元素存储的位置,先判断该位置上有没有元素(
hashmap定义的一个类entity,基本结构包含三个元素key、value和指向下一个entity的next),若不同的hash值算在同一个table下标下,这就产生了冲突。常用的冲突解决算法是:拉链法(采用头插法)、线性探测法。 - 若不等,调用addEntry()将新创建一个元素添加到table中。创建元素entity时,要判断table的填充容量是否大于负载因子0.75,若大于就要扩容,容量扩充到两倍。
- 扩容的时候,是在内存中开辟新的内存空间,然后把原来的对象放到新的
table数组中,这个过程叫做重新散列(rehashing)。但是在多线程的时候,会出现条件竞争。比如两个线程发现hashmap需要重新调整大小,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
可以参考这篇文章:http://coolshell.cn/articles/9606.html - 为了解决这个问题,采用了线程安全的
CocurrentHashMap,它是行级锁,而hashtable是整体加锁。
2.2 常用的hash算法有哪些?
2.2.1 构造哈希函数的方法有哪些?
- 直接定址法(或直接寻址法)
- 数字分析法
- 平方取中法(平方散列法)
求index是一个非常频繁的操作,而乘法运算比除法来的省事(对CPU而言),所以把除法换成乘法和一个移位操作,公式: Index=(value*value)>>28(右移,是除以2^28. 记住:左移变大,是乘。右移变小,是除)
- 折叠法
- 除留余数法(这是最简单也是最常用的构造hash函数的方法)即对关键字取模Index=value%16(取模)
- 随机数法
2.2.2 解决hash冲突的方法有哪些?
开放定址法(线性探测再散列、二次探测再散列)(线性探测法)
再哈希法(双散列函数法):在发生冲突的时候,再次使用另一个散列函数,计算哈希函数地址,直到冲突不再发生。
链地址法(拉链法)(常用重点):就是一个数组+链表(链表采用头插法)
建立一个公共溢出区。
常见的hash算法:
- MD4
- MD5
- SHA-1算法
2.2.3 HashMap为什么要扩容?
Hashmap初始容量是16,若实际填充的容量是初始容量*负载因子,若全部填满查询的开销太大。因此hashmap的容量达到75%,就会扩容。扩容的大小是原来的一倍。
注意⚠️:jdk1.8中若链表的结点数大于8,则会转化成红黑树(目的提高查询效率)
链接
2.3 load factor的作用
负载因子load factor=hashmap的数据量(entry的数量)/初始容量(table数组长度),负载因子越高,表示初始容量中容纳的数据会越多,虽然在空间中减少了开销,但是大量数据聚集,造成查询上的大量开销。负载因子越低,表示初始容量中容纳的数据会越少,造成大量的内存空间浪费,但是查询的效率比较高。这是一个矛盾体,为了寻求平衡点,负载因子0.75效果是最好的。
2.4 ConcurrentHashMap 的实现原理?
要知道ConcurrentHashMap的结构、put和get方法。
ConcurrentHashMap类中包含两个静态的内部类HashEntry和Segment.HashEntry用来封装映射表的键值对;Segment用来充当锁的角色,每个Segment对象守护整个散列映射表的若干个桶。每个桶由若干个HashEntry对象链接起来的链表。一个ConcurrentHashMap实例中包含由若干个Segment对象组成的数组。- 用分离锁实现多个线程间的并发写操作(put方法实现的过程)
散列码通过segmentFor找到对应的Segment(不允许value为空)
- 将散列值右移segmentShift 个位,并在高位填充 0
- 然后把得到的值与 segmentMask 相“与”
- 从而得到 hash 值对应的 segments 数组的下标值
- 根据下标值返回Segment对象
在Segment中执行具体的put操作:
- 加锁(锁定某个
segment,而非整个ConcurrentHashMap)- 判断
HashEntry是否超过阀值(负载因子*数组长度),若超过要进行散列;- 没超过,判断键值对是否存在,采用头插法加入链表中;
- 然后解锁。
2.5 HashMap与ConcurrentHashMap的关联与区别?
2.6 HashTable的实现原理?与ConcurrentHashMap的区别
2.7 concurrent包的并发容器有哪些?
三、java多线程问题
3.1 实现多线程的方式
- 继承
Thread类,重写run函数 - 实现
Runnable接口(最常用) - 实现
Callable接口
三种方式的区别:
- 实现Runnable接口可以避免java单继承特性带来的局限,增强程序健壮性,代码能够被多个线程共享。
- Thread和Runnable启动线程都是使用start方法,然后JVM将此线程放到就绪队列中,如果有处理机可用,则执行run方法。
- 实现Callable接口要实现call方法,并且线程执行完毕后会有返回值,其他的两种方法都是重写run方法,没有返回值。Callable接口提供了一个call()方法可以作为线程执行体,但call()方法比run()方法功能更为强大:call()方法可以有返回值;call()方法可以声明抛出异常。
3.2 线程安全
定义:
(1)某个类的行为与其规范一致;
(2)不管多个线程是怎样的执行顺序和优先级,或是wait,sleep,join等控制方式。 如果一个类在多个线程访问下运转一切正常,并且访问类不需要进行额外的同步处理或协调,那么我们认为它是线程安全的。
如何保证线程安全?
- 对变量使用
volatile; - 对程序段进行加锁(
synchronized,lock);
注意⚠️:非线程安全的集合在多线程环境下可以使用,但并不能作为多个线程共享的属性,可以作为某个线程独立的属性。例如:Vector是线程安全的,ArrayList不是线程安全的,如果每一个线程new一个ArrayList,而这个ArrayList在这个线程中使用肯定没有问题。(若再new一个ArrayList,就会线程不安全)
3.3 多线程如何进行信息交互
- 采用object方法:
wait(),notify(),notifyAll();- 在
java 1.5中采用condition,比传统的wait,notify()更加安全高效;- 采用生产者-消费者模式(采用队列的形式);
生产者发布消息在队列中,消费者从队列中取任务去执行。
3.4 多线程共用一个数据变量需要注意什么?
出现的问题:当我们在线程对象(Runnable)中定义了全局变量,run方法修改该变量时,如果有多个线程同时使用该线程对象,那么就会造成全局变量的值被同时修改,造成错误。
- 解决方法1:
ThreadLocal是JDK引入的一种机制,它用于解决线程共享变量,使用ThreadLocal声明的变量,会在每个线程内产生一个变量副本,从而解决了线程不安全。- 解决方法2:
volatile变量每次被线程访问时,都强迫线程从主内存中重新取该变量的最新值到工作内存中,而当该变量发生修改变化时,也会强迫线程将最新的值刷新会到主内存中。这样一来,不同的线程都能及时的看到该变量的最新值。
3.5 什么是线程池?如果让你设计一个动态大小的线程池,如何设计,应该有哪些方法?
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建(类似于工厂设计模式),使用完毕不需要销毁线程而是返回池中,从而减少创建和销毁线程对象的开销。
设计一个动态大小的线程池,如何设计,应该有哪些方法?
一个线程池包括以下四个基本单位:
- 线程管理器(
ThreadPool):用于创建并管理线程池,包括创建线程,销毁线程池,添加新任务;- 工作线程(
PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;- 任务接口(
Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定任务的入口,任务执行完成后的收尾工作,任务的执行状态等。- 任务队列(
TaskQueue):用于存放没有处理的任务,提供一种缓冲机制。
所包含的方法:
private ThreadPool()创建线程池;Public static ThreadPool getThreadPool()获得一个默认线程个数的线程池;Public void execute(Runnable task)执行任务,其实只是把任务加入任务队列,什么时候执行由线程池管理器确定;Public void execute(Runnable[] task)批量执行任务,其实只是把任务加入任务队列,什么时候执行由线程管理器确定。Public void destroy()销毁线程池,该方法保证所有任务都完成的情况下才销毁所有线程,否则等待任务完成销毁。Public int getWorkThreadNumber()返回工作线程的个数。Public int getFinishedTasknumber()返回已完成任务的个数,这里的已完成是指出了任务队列的任务个数,可能该任务并没有实际执行完成。Public void addTread()在保证线程池中所有线程正在执行,并且要执行线程的个数大于某一值时(就是核心池大小),增加线程池中线程的个数(最大是线程池大小)。Public void reduceThread()在保证线程池中有很大一部分线程处于空闲状态,并且空闲状态的线程在小于某一值时(就是核心池大小),减少线程池中线程的个数。
3.6 volatile与synchronized区别
Volatile 关键字的作用
- 保证内存可见性
- 防止指令重排序
注意⚠️:volatile并不保证原子性。
内存的可见性:
Volatile保证可见性的原理是在每次访问变量时都会进行刷新,因此每次访问都是在主内存中得到最新的版本。所以volatile关键字的作用之一就是保证变量修改的实时可见性。
当且仅当满足以下所有条件时,才应该使用volatile变量:
- 在两个或更多的线程需要访问的成员变量上使用
volatile。当需要访问的变量已在synchronized代码块中,或者为常量,没必要使用volatitle;- 由于使用
volatile屏蔽了JVM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
Volatile和synchronized区别
volatile不会进行加锁操作。Volatile变量是一种稍弱的同步机制,在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比synchronized关键字更轻量级的同步机制。(其实volatitle在读写时,就相当于加锁)Volatile变量作用类似于同步变量读写操作。从内存可见性的角度看,写入volatile变量相当于退出同步代码块,而读取volatile变量相当于进入同步代码块。volatile不如synchronized安全。在代码中如果过度依赖volatile变量来控制状态的可见性,通常会比加锁的代码更加脆弱,也更加难以理解。仅当volatile变量能简化代码的实现以及对同步策略的验证时,才应该使用它。一般来说,用同步机制更安全些。volatile无法同时保证内存可见性和原子性。加锁机制(即同步机制)既可以确保可见性又可以确保原子性,而volatile变量只能确保可见性,原因是声明为volatile的简单变量如果当前值与该变量以前的值相关,那么volatile关键字不起作用,也就是说以下的表达式都不是原子操作:“count++”“count=count+1”。
3.7 sleep和wait分别是哪个类的方法,有什么区别?
Sleep是Thread类的方法。Wait是object类方法(与notify(), notifyAll();连用,即等待唤醒)
两者区别
Sleep()方法(休眠)是线程类(Thread)的静态方法,调用此方法会让当前线程暂停执行指定的时间,将执行机会(cpu)让给其他线程,但是对象的锁依然保持,因此休眠时间结束后会自动回复(线程回到就绪状态)。Wait()是Object类的方法,调用对象的wait方法导致当前线程放弃对象的锁(线程暂停执行),进入对象的等待池(wait poo),只有调用对象的notify方法或notifyAll时才能唤醒等待池中的线程进入等锁池(lock
pool),如果线程重新获得对象的锁就可以进入就绪状态。
3.8 synchronized与lock的区别,使用场景,看过synchronized的源码没?
Synchronized与lock的区别
(1)(用法)synchronized(隐式锁):在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中。
(2)(用法)Lock(显示锁):需要显示指定起始位置和终止位置,一般使用ReentrantLock类做为锁,多个线程中必须要使用一个 ReentrantLock类做为对象才能保证锁的生效。且在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般在finally块中写unlock以防死锁。
(3)(性能)synchronized是托管给JVM执行的,而lock是java写的控制锁代码。在java1.5中,synchronized是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用java提供的lock对象,性能更高一些。但是到了java1.6,发生了变化。Synchronized在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在java1.8上synchronized的性能并不比lock差。
(4)(机制)synchronized原始采用的是cpu悲观锁机制,即线程获得是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止,乐观锁实现的机制就是CAS操作(Compare and Swap)。
3.9 synchronized底层如何实现的?用在代码块和方法上有什么区别?
Synchronized底层如何实现的?(看源码)用在代码块和方法上有什么区别?
synchronized用在代码块锁的是调用该方法的对象(this),也可以选择锁住任何一个对象。Synchronized用在方法上锁的是调用该方法的对象。Synchronized用在代码块可以减少锁的粒度,从而提高并发性能。- 无论用在代码块上还是用在方法上,都是获取对象的锁。每一个对象只有一个锁与之相关联;实现同步需要很大的系统开销为代价,甚至可能造成死锁,所以尽量避免无谓的同步控制。
Synchronized与static Synchronized的区别
synchronized是对类的当前实例进行加锁,防止其他线程同时访问该类的该实例的所有synchronized块,同一个类的两个不同实例就没有这种约束(这个对象压根就是两个不相关的东西)。- 那么
static synchronized恰好就是要控制类的所有实例的访问,static synchronized是限制线程同时访问jvm中该类的所有实例同时访问对应的代码块。
3.10 java中的NIO、BIO、AIO分别是什么
BIO:
- 同步并阻塞(互斥同步),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个链接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善;
- BIO方式适用于链接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,jdk1.4以前的唯一选择,但程序直观简单易理解。
NIO:
- 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的链接请求都会注册到多路复用器上,多路复用器轮询到链接有I/O请求时才启动一个线程进行处理。
- NIO方式适用于链接数目多且链接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,jdk1.4开始支持。
AIO:
- 异步非阻塞,服务器实现模式为一个有效一个线程,客户端的I/O请求都是由OS(操作系统)先完成了在通知服务器应用去启动线程进行处理;
- AIO方式使用于链接数目多且链接比较长(重操作)的架构,比如相册服务器,充分调用os参与并发操作,编程比较复杂,jdk7开始支持。
3.11 什么是java内存模型(java memory model jmm)
描述了java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取出变量这样的低层细节。
- 所有的变量都存储在主内存中。
- 每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中该变量的一份拷贝)。
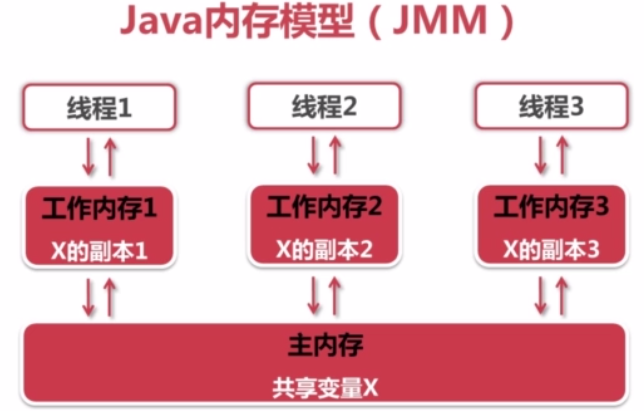

Java内存模型的两条规定:
- 线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写;
- 不同线程无法直接访问其他线程工作内存中的变量,线程间变量值的访问都需要通过主内存来完成。
3.12 JVM线程死锁,你该如何判断是什么原因?如果用VisualVM,dump打印线程信息出来,会有哪些信息?
常常需要在隔两分钟后再收集一次thread dump,如果得到的输出相同,仍然是大量thread都在等待给同一个地址上的锁,那么肯定是死锁了。锁分类如下:
- 悲观锁:无论共享数据是否产生争用、是否由于争用产生冲突,都会加锁。
- 乐观锁:假设没有共享数据争用,就执行成功。若监测出有共享数据争用产生冲突,就进行补救措施(如:重试)。
- 可重入锁:一个线程加锁了,该线程中调用其他的方法,也同样加锁了,如递归;
- 读写锁:对一个资源的访问,可以分成读锁和写锁;
- 可中断锁:一个线程等待的时间太长,可以中断等待的过程,去执行其他的事情;
- 公平锁:尽量以锁的顺序来获取锁;
优化方面的锁:
- 自旋锁(自适应锁):共享数据锁定状态比较短,对于阻塞的线程不要立马挂起,而是自旋一下就可得到,避免线程切换的开销。
- 锁消除:有些数据是不会被其他线程访问到的,这时候就不需要加同步措施,进行锁消除。
- 锁粗化:同步块的作用域一般越小越好,但是对一个对象的连续操作,不停的加锁解锁,这样会出现很大的性能问题。
轻量级锁:为了减少获得锁和释放锁所带来的性能消耗。Java 1.6有无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态四个状态。随着竞争,不断升级,不能降级。
偏向锁:目的是消除数据在无竞争情况下的同步原语。进一步提升程序的运行性能。 偏向锁就是偏心的锁,意思是这个锁会偏向第一个获得他的线程。
四、异常问题
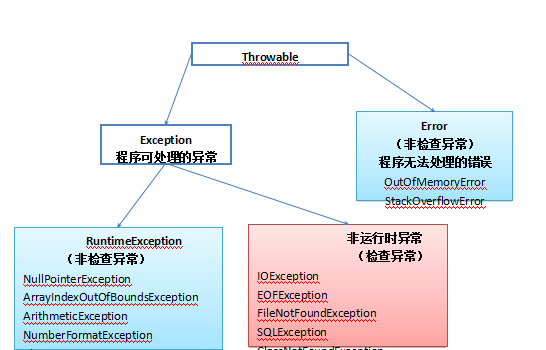
4.1 常见异常分为两种(Exception,Error)
Throwable是java语言中所有错误和异常的基类,它由两个子类:Error, Exception.
异常种类
Error: Error为错误,是程序无法处理的,如OutOfMemoryError,ThreadDeath等,出现这种情况你唯一能做的就是听之任之,交由JVM来处理,不过大多数情况下会选择终止线程。Exception: Exception是程序可以处理的异常,它又分为两种CheckedException(受检异常)和unCheckedException(不受检异常)。其中,CheckedException发生在编译阶段,必须要使用try……catch(或则throws)否则编译不通过;unCheckedException发生在运行期,具有不确定性,主要是由于程序的逻辑问题所引起的,难以排查,我们一般都需要纵观全局才能够发现这类的异常错误。
常见异常的基类:
IOExceptionRuntimeException
五、加载问题
六、关键字的比较
6.1 static和final的区别和用途
Static
- 修饰变量:静态变量随着类加载时被完全初始化,内存中只有一个,且JVM也只会为它分配一次内存,所有类共享静态变量。
- 修饰方法:在类加载的时候就在,不依赖任何实例;static方法必须实现,不能用abstract修饰。
- 修饰代码块:在类加载完成后就会执行代码块中的内容
- 执行顺序:
父类静态代码块--->子类静态代码块---->父类非静态代码块---->父类构造方法----->子类非静态代码块----->子类构造方法
Final
- 修饰变量:编译期常量(类加载的过程完成初始化,编译后带入到任何计算式中,只能是基本类型) 运行时常量(基本数据类型或引用数据类型,引用不可变,但引用的对象内容可变);
- 修饰方法:不能被继承,不能被子类修改;
- 修饰类:不能被继承;
- 修饰形参:
final形参不可变;
七、字符串
7.1 String、StringBuffer、StringBuilder以及对String不变性的理解
- 都是
final类,都不允许被继承;String长度是不可变动的,StringBuffer、StringBuilder长度是可变的;StringBuffer是线程安全的(在StringBuilder方法上添加关键字synchronized),StringBuilder线程不安全;StringBuilder比StringBuffer拥有更好的性能;- 如果一个
String类型的字符串,在编译时就可以确定是一个字符串常量,则编译完成之后,字符串会自动拼接成一个常量,此时String的速度比StringBuilder和StringBuffer的性能好的多。
String不变性的理解
String类是被final进行修饰的,不能被继承;- 在用
+号连接字符串的时候会创建新的字符串;String s=new String(“helle world”);可能创建两个对象也可能创建一个对象。如果静态区中有“hello world”字符串常量对象的话,则仅仅在堆中创建一个对象。如果静态区没有“hello world”对象,则在堆和静态区中都创建对象。- 在
java中,通过使用“+”符合来链接字符串的时候,实际底层会转成通过StringBuilder实例的append()方法实现。
7.2 String有重写Object的hashcode和toString吗?如果重写equals不重写hashcode会出现什么问题?
有重写这些方法。
当equals方法被重写,通常有必要重写hashCode方法,才能保证相等。如:object1.equal(object2)为true, object1.hashCode==object2.hashCode()为true。
两个对象内容相等,那么hashCode指向的是同一个内容,返回的哈希值是相同的;
object1.hashCode==object2.hashCode()为false时,object1.equal(object2)为false
两个hashCode不等,那么两个对象的内容必然不同(每个对象的哈希值是唯一的);
object1.hashCode==object2.hashCode()为true时,object1.equal(object2)不一定为true;
比如hashmap,hashCode是数组的下标,但是会产生hash冲突,比如一个数组下标后连接一个链表;
重写equals不重写hashcode会出现什么问题?
在存储散列集合时(如set类),如果原对象.equals(新对象),但没有对hashcode重写,即两个对象拥有不同的hashcode,则在集合中会存储两个值相同的对象,从而导致混淆,因此在重写equals方法时,必须重写hashcode方法。
7.3 如果你定义一个类,包括学号,姓名,分数,如何把这个对象作为key?要重写equals和hashcode吗?
需要重写equals方法和hashcode,必须保证对象的属性改变时,其hashcode不能改变。
八、java协议
8.1 java序列化、如何实现序列化和反序列化,常见的序列化协议有哪些
将那些实现Serializable接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复为原来的对象,序列化可以弥补不同操作系统之间的差异。
Java序列化的作用
- Java远程方法调用(RMI)
- 对
javaBeans进行序列化
如何实现系列化和反序列化
8.1.1 实现序列化
- 实现Serializable接口
- 该接口只是一个可序列化的标志,并没有包含实际的属性和方法;
- 如果不在该方法中添加
readObject()和writeObject()方法,则采取默认的序列化机制,如果添加了这两个方法之后还想利用java默认的序列化机制,则在这两个方法中分别调用defaultReadObject()和defaultWriteObject()两个方法;- 为了保证安全性,可以使用
transient关键字进行修饰不必序列化的属性。因为在反序列化时,private修饰的属性也能查看到。
- 实现
ExternalSerializable方法
自己对要序列化的内容进行控制,控制哪些属性被序列化,哪些不能被序列化;
8.1.2 实现反序列化
- 实现
Serializable接口的对象在反序列化时不需要调用对象所在类的构造方法,完全基于字节;- 实现
ExternalSerializable接口的方法在反序列化时会调用构造方法;
注意事项⚠️
- 被
static修饰的属性不能被序列化;- 对象的类名、属性都会被序列化,方法不会被序列化;
- 要保证序列化对象所在类的属性也是可以序列化的;
- 当通过网络、文件进行序列化时,必须按照写入的顺序读取对象;
- 反序列化时有序列化对象的
class文件;- 最好显式的声明
serializableID,因为在不同的JVM之间,默认生成serializableID;可能不同,会造成反序列化失败。
常见的序列化协议有哪些?
COMCORBAXML&SOAPJSONThrift
……
九、其他
9.1 java 的四个基础特性(抽象、封装、继承、多态),对多态的理解(多态的实现方式,以及在项目中用到的多态)
java的四个基本特性
- 抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面,抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
- 继承:继承是从已有类得到继承信息创建新类的过程,提供继承信息的类称为父类(超类、基类);得到继承信息的类被称为子类(派生类),继承让变化中的软件系统有了一定的延续性,同时继承也是封装程序中可变因素的重要手段。
- 封装:通常认为封装是把数据和操作方法绑定起来,对数据的访问只能通过已定义的接口,面向对象的本质就是将现实世界描绘成一系列完全自治、封闭的对象,我们在类中编写的方法就是对实现细节的一种封装;我们编写一个类就是对数据和数据操作的封装。可以说,封装就是隐藏一切可隐藏的东西,只向外界提供最简单的编程接口。
- 多态:是指允许不同子类型的对象对同一消息做出不同的响应。
多态的理解(多态的实现方式)
- 方法重载(
overload)实现编译时的多态性(也称为前绑定)(1、类型不同 2、参数个数不同 3、与返回值无关)。 - 方法重写(
override)实现运行时的多态(也称为后绑定)。(核心精髓)
项目中多态的应用:
- 单继承
- 接口实现
例如:在接口中写一个爬虫的方法
在不同的网站,爬虫实现的方法都不同,如网易采用jsoup进行解析、百度采用RSS,今日头条采用ajax异步传输,实现就要采用获取json进行解析。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169257.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
