大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
watcher架构
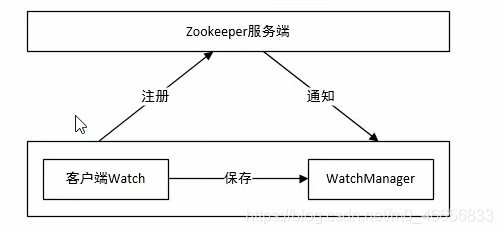

客户端首先将Watcher注册到服务器,同时将Watch对象保存到客户端的Watch管理器中。当Zookeeper服务器监听到的数据发生变化时,服务器会通知客户端,接着客户端的Watch管理器会触发相关的Watcher来回调响应处理逻辑,从而完成整体的数据发布/订阅流程。



javaAPI
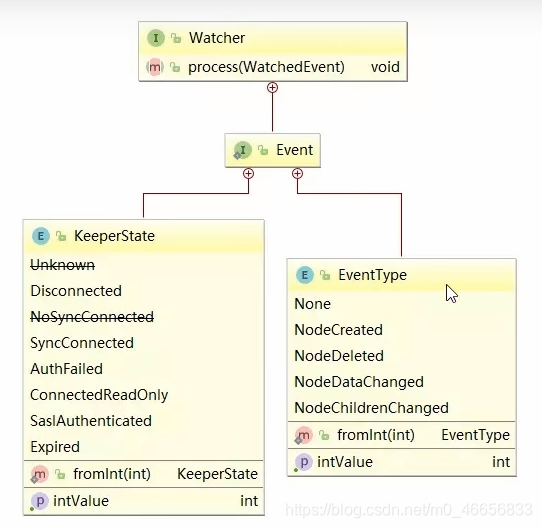
Java watch案例
public class WatcherDemo implements Watcher {
static ZooKeeper zooKeeper;
static {
try {
zooKeeper = new ZooKeeper("192.168.3.39:2181", 4000,new WatcherDemo());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void process(WatchedEvent event) {
System.out.println("eventType:"+event.getType());
if(event.getType()==Event.EventType.NodeDataChanged){
try {
zooKeeper.exists(event.getPath(),true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
String path="/watcher";
if(zooKeeper.exists(path,false)==null) {
zooKeeper.create("/watcher", "0".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
Thread.sleep(1000);
System.out.println("-----------");
//true表示使用zookeeper实例中配置的watcher
Stat stat=zooKeeper.exists(path,true);
System.in.read();
}
}
运行完程序,控制台显示
:此时启动 zookeeper 命令行终端,查看并且删除 watcher 节点:

IDE 控制台输出,触发了节点删除事件:
zookeeper 配置中心
使用zookeeper作为配置中心,通常情况下java应用程序会依赖很多配置文件,建议将配置信息配置在zookeeper中,将zookeeper作为服务器的配置中心,当配置发生变换之后,可以用zookeeperz中的watch机制捕获到发生变化的事件,以便客户端获得配置信息。
设计思路
- 连接zookeeper服务器
- 读取zookeeper中的配置信息,注册watcher监听器,存入本地变量
- 当zookeeper中的配置信息发生变化时,通过watcher的回调方法捕获数据变化事件
- 当zookeeper中的配置数据发生变化时,通过watcher的回调方法捕获数据变化事件
java案例
package com.cc.duoxiancheng;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.util.concurrent.CountDownLatch;
public class MyConfigCenter implements Watcher {
// zookeeper地址
String IP = "192.168.60.130:2181";
// zookeeper是异步连接的,所以要使用countDownLatch 当响应返回的时候才继续改线程
CountDownLatch countDownLatch = new CountDownLatch(1);
static ZooKeeper zooKeeper;
// 配置信息
private String url;
private String username;
private String password;
@Override
public void process(WatchedEvent event) {
try {
if(event.getType() == Event.EventType.None) {
if(event.getState() == Event.KeeperState.SyncConnected){
System.out.println("连接成功");
countDownLatch.countDown();
}
else if(event.getState() == Event.KeeperState.Disconnected){
System.out.println("连接断开");
}
else if(event.getState() == Event.KeeperState.Expired){
System.out.println("连接超时");
}
else if(event.getState() == Event.KeeperState.AuthFailed){
System.out.println("认证失败");
}
}else if(event.getType() == Event.EventType.NodeDataChanged){
//当有数据变华的时候,重新从配置信息中读取信息
initValue();
}
}catch (Exception e){
e.printStackTrace();
}
}
private MyConfigCenter(){
initValue();
}
public void initValue()
{
try {
zooKeeper = new ZooKeeper(IP,50000,this);
countDownLatch.await();
//注册配置信息的watch道主watch中
this.url = new String(zooKeeper.getData("/config/url",true,null));
this.username = new String(zooKeeper.getData("/config/username",true,null));
this.password = new String(zooKeeper.getData("/config/password",true,null));
}catch (Exception e){
e.printStackTrace();
}
}
}
分布式ID
在过去的单库单表系统中,通常可以使用数据库的AUTO_INCREMENT属性来自动为每条记录生成一个唯一的ID,d但是分库分表后,就无法在依靠数据库的auto_increment属性来唯一表示一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一id
设计思路
- 连接zookeeper服务器
- 指定路径下生成临时有序节点
- 取序列号及为分布式环境下的唯一ID
zookeeper中创建分布式唯一ID

public String getUniqueId(){
String path = "";
try{
//生成zookeeper有序临时节点
path = zookeeper.create(path,new byte[0],Ids.OPEN_ACL_UNSAFE,CREATEMode.EPHEMERAL_SEQUENTIAL);
}catch(Exception e){
e.printStackTrace();
}
//
return path.subString(...);
}
分布式锁
分布式锁有多种实现方式,比如数据库,Redis都可以实现分布式锁,作为分布式协同工具zookeeper,当然也有着标准的实现方式。
设计思路
- 每个客户端往/Locks下创建l临时有序节点/Locks/Lock_,创建成功后/Locks下面会有每个客户端对应的节点。如/Locks/Lock_000000001
- 客户端获取/Locks下子节点,并进行排序,判断排在最前面的是否为自己,如果自己的锁节点排在第一位,代表获取锁成功
- 如果自己的锁节点不在第一位,则监听自己前一位的锁节点。例如,自己锁节点Lock_000000002,那么监听Lock_0000000001
- 当前一位锁节点(Lock_0000000001)对应的客户端执行完成,释放了锁,将会触发监听客户端
- 监听客户端重新执行第2步逻辑,判断自己是否获得了锁
java案例
private void createLock() throws Exception{
//判断节点是否存在
Stat stat = zooKeeper.exists(LOCK_ROOT_PATH,false);
if(stat == null){
zooKeeper.create(LOCK_ROOT_PATH,new byte[0],ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
//创建临时有序节点
lockPath = zooKeeper.create(LOCK_ROOT_PATH + "/" + LOCK_NODE_NAME,new byte[0],ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
Watcher watch = new Watcher(){
public void process(){
if(event.getType == Event,EventType.NodeDeleted){
synchronized(this){
notifyAll();
}
}
}
}
private void attemptLock() throws Exception{
//获取Locks节点下所有孩子节点
List<String>list = zooKeeper.getChildren(LOCK_ROOT_PATH,false);
//对节点进行排序
Collection.sort(list);
int index = list.indexOf(lockPath.subString(LOCK_ROOT_PATH.length() + 1));
if(index == 0){
System.out.println("获取锁成功");
}else {
//上一个节点路径
String path = list.get(index-1);
zooKeeper.exists(LOCK_ROOT_PATH + "/" + path,wathcer);
if(stat == nukk){
attemptLock();
}else{
synchronized(watcher){
watcher.wait();
}
attemptLock();
}
}
}
public void releaseLock() throws Exception{
zooKeeper.delete(this.lockPath,-1);
zooKeeper.close();
System,out.println("锁已经释放" + this.lockPath);
}
集群搭建
Ubuntu进行虚拟集群搭建。模拟共有3台服务器,端口分别为2181,2182,2183
- 基于zookeeper-3.4.10复制3份好的服务器文件
cp -r zookeeper-3.4.10 zookeeper2181
cp -r zookeeper-3.4.10 zookeeper2182
cp -r zookeeper-3.4.10 zookeeper2183
- 修改zookeeper2181,2182,2183服务器配置文件(以2181为例)
# 指定ip
clientPortAddress=192.168.0.120
# 配置集群
server.服务器编号=ip地址:Zookeeper服务器之间的通信端口:Leader选举的端口
server.1=192.168.0.120:2287:3387
server.2=192.168.0.120:2288:3388
server.3=192.168.0.120:2289:3389
- 在上一步dataDir指定的目录下,创建myid文件,然后在该文件添加上一步server配置的对应的服务器编号
# zookeeper2181对应的服务器编号是1
# /home/zookeeper/zookeeper2181/data目录下
echo "1" > myid
- 登录三个zookeeper服务器
# 启动
zkServer.sh start
# 状态
zkServer.sh status
# 登录
zkCli.sh -server 192.168.60.130:2181
数据一致性协议:zab协议
zab协议的全程是Zookeeper Atomic Broadcast,zookeeper是通过zab协议来保证分布式事务的最终一致性
基于zab协议,zookeeper集群中的角色主要有以下三类,如下表所示:

zab原子广播模式工作原理,通过类似两阶段提交协议的方法解决数据一致性:
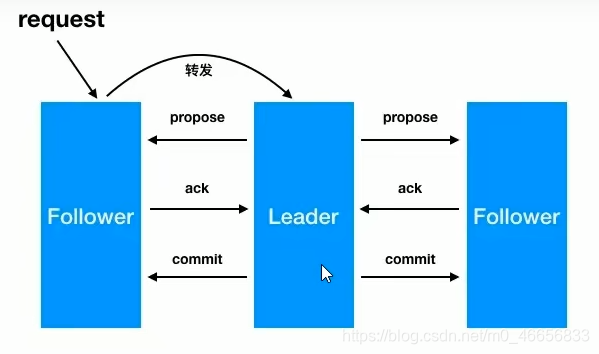
- leader从客户端收到一个写请求
- leader生成一个新的事务并为这个事务生成一个唯一的ZXID
- leader将这个事务提议(propose)发送给所有的follow节点
- follower节点将受到的事务请求加入到历史队列(history queue)中,并发送ack给leader
- 当leader收到大多数follower(半数以上节点)的ack消息,leader会发送commit请求
- 当follow收到commit请求时,从历史队列中将事务请求commit
Zookeeper Leader选举
服务器状态
- looking:寻找leader状态,当服务器处于该状态时,他会认为当前集群中没有leader,因此需要进入leader选举状态
- leading:领导者状态。表明当前服务器是领导者
- following:跟随者状态,表明当前服务器角色是follower
- observing:观察者状态。表明当前服务角色是observer
服务器启动时的leader选举
每个节点启动的时候状态都是LOOKING,处于观望状态,接下来就开始进行选主流程
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程如下
-
每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID、epoch,使用(myid, ZXID,epoch)来表示,此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
-
接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING状态的服务器。
-
处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下
-
优先比较epoch
-
其次检查ZXID。ZXID比较大的服务器优先作为Leader
-
如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
-
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader。
-
改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
运行时的leader选举
当集群中的leader服务器出现宕机或者不可用的情况时,那么整个集群将无法对外提供服务,而是进入新一轮的Leader选举,服务器运行期间的Leader选举和启动时期的Leader选举基本过程是一致的。
-
变更状态。Leader挂后,余下的非Observer服务器都会将自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
-
每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同,此时假定Server1的ZXID为123,Server3的ZXID为122;在第一轮投票中,Server1和Server3都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。接收来自各个服务器的投票。与启动时过程相同。
-
处理投票。与启动时过程相同,此时,Server1将会成为Leader。
-
统计投票。与启动时过程相同。
-
改变服务器的状态。与启动时过程相同
Observer角色及其配置
Observer角色特点:
- 不参与集群的leader选举
- 不参与集群中写数据时的ack反馈
为了使用observer角色,在任何想变成observer角色的配置文件中加入如下配置:
peerType=observer
并在所有server的配置文件中,配置成observer模式的server的呐喊配置追加:observer,例如:
server.3=192.168.60.130:2289:3389:observer
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168952.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
