大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
ZAB协议用来保持数据一致性,主要有两种模式,第一是消息广播模式;第二是崩溃恢复模式
除此之外我门还应该了解Leader的选出机制
消息广播模式
在zookeeper集群中数据副本的传递策略就是采用消息广播模式。
ZAB协议中Leader等待follower的ACK反馈是指”只要半数以上的follower成功反馈即可,不需要收到全部follower反馈”;下图中展示了消息广播的具体流程图:
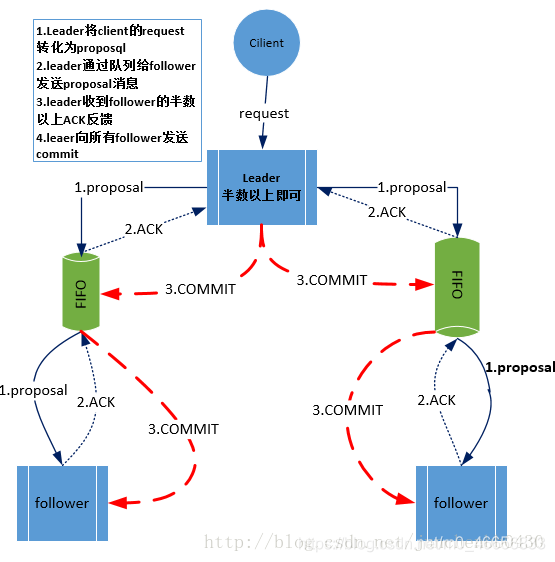

zookeeper中消息广播的具体步骤如下:
客户端发起一个写操作请求
-
Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个proposal分配一个全局唯一的ID,即ZXID。(proposql是根据ZXID生成的,同一个请求生成的proposql中的ZXID是一样的)
-
leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列
-
follower机器从队列中取出消息处理完(写入本地事物日志中)毕后,向leader服务器发送ACK确认。
-
leader服务器收到半数以上的follower的ACK后,即认为可以发送commit
-
leader向所有的follower服务器发送commit消息。
leader服务器与每个follower之间都有一个单独的队列进行收发消息,使用队列消息可以做到异步解耦。leader和follower之间只要往队列中发送了消息即可。如果使用同步方式容易引起阻塞。性能上要下降很多。
崩溃恢复机制
1、当leader出现问题,zab协议进入崩溃恢复模式,并且选举出新的leader。当新的leader选举出来以后,如果集群中已经有过半机器完成了leader服务器的状态同(数据同步),退出崩溃恢复,进入消息广播模式。
2、当新的机器加入到集群中的时候,如果已经存在leader服务器,那么新加入的服务器就会自觉进入崩溃恢复模式,找到leader进行数据同步。
崩溃恢复需要保证两件事情:
- 已经被处理的事务请求(proposal)不能丢(commit的)
- 没被处理的事务请求(proposal)不能再次出现
问题一:已经被处理的事务请求(proposal)不能丢(commit的)
当 leader 收到合法数量 follower 的 ACKs 后,就向各个 follower 广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端返回「成功」。但是如果在各个 follower 在收到 COMMIT 命令前 leader 就挂了,导致剩下的服务器并没有执行都这条消息。
如何解决 已经被处理的事务请求(proposal)不能丢(commit的) 呢?
1、选举拥有 proposal 最大值(即 zxid 最大) 的节点作为新的 leader。
由于所有提案被 COMMIT 之前必须有合法数量的 follower ACK,即必须有合法数量的服务器的事务日志上有该提案的 proposal,因此,zxid最大也就是数据最新的节点保存了所有被 COMMIT 消息的 proposal 状态。
2、新的 leader 将自己事务日志中 proposal 但未 COMMIT 的消息处理。
3、新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息。通过以上策略,能保证已经被处理的消息不会丢。
问题二:没被处理的事务请求(proposal)不能再次出现什么时候会出现事务请求被丢失呢?
当 leader 接收到消息请求(客户端的)生成 proposal 后就挂了,其他 follower 并没有收到此 proposal,因此经过恢复模式重新选了 leader 后,这条消息是被跳过的。 此时,之前挂了的 leader 重新启动并注册成了 follower,他保留了被跳过消息的 proposal 状态,与整个系统的状态是不一致的,需要将其删除。
如果解决?
Zab 通过巧妙的设计 zxid 来实现这一目的。
一个 zxid 是64位,高 32 是纪元(epoch)编号,每经过一次 leader 选举产生一个新的 leader,新 leader 会将 epoch 号 +1。低 32 位是消息计数器,每接收到一条消息这个值 +1,新 leader 选举后这个值重置为 0。
这样设计的好处是旧的 leader 挂了后重启,它不会被选举为 leader,因为此时它的 zxid 肯定小于当前的新 leader。当旧的 leader 作为 follower 接入新的 leader 后,新的 leader 会让它将所有的拥有旧的 epoch 号的未被 COMMIT 的 proposal 清除
数据同步
在zookeeper集群中新的leader选举成功之后,leader会将自身的提交的最大proposal的事物ZXID发送给其他的follower节点。follower节点会根据leader的消息进行回退或者是数据同步操作。最终目的要保证集群中所有节点的数据副本保持一致。
选Leader
Zookeeper集群初始化启动时Leader选举
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。
初始化启动期间Leader选举流程如下图所示。
在集群初始化阶段,当有一台服务器ZK1启动时,其单独无法进行和完成Leader选举,当第二台服务器ZK2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程开始,过程如下:
(1) 每个Server发出一个投票。由于是初始情况,ZK1和ZK2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时ZK1的投票为(1, 0),ZK2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下
· 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
· 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于ZK1而言,它的投票是(1, 0),接收ZK2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时ZK2的myid最大,于是ZK2胜。ZK1更新自己的投票为(2, 0),并将投票重新发送给ZK2。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于ZK1、ZK2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出ZK2作为Leader。
(5) 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。当新的Zookeeper节点ZK3启动时,发现已经有Leader了,不再选举,直接将直接的状态从LOOKING改为FOLLOWING。
Zookeeper集群运行期间Leader重新选
在Zookeeper运行期间,如果Leader节点挂了,那么整个Zookeeper集群将暂停对外服务,进入新一轮Leader选举。
假设正在运行的有ZK1、ZK2、ZK3三台服务器,当前Leader是ZK2,若某一时刻Leader挂了,此时便开始Leader选举。选举过程如下图所示。
(1) 变更状态。Leader挂后,余下的非Observer服务器都会讲自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
(2) 每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同,此时假定ZK1的ZXID为124,ZK3的ZXID为123;在第一轮投票中,ZK1和ZK3都会投自己,产生投票(1, 124),(3, 123),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同,由于ZK1事务ID大,ZK1将会成为Leader。
(5) 统计投票。与启动时过程相同。
(6) 改变服务器的状态。与启动时过程相同。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168795.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
