大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
k8s
service用于4层路由负载 ingress用于7层路由负载
Service介绍
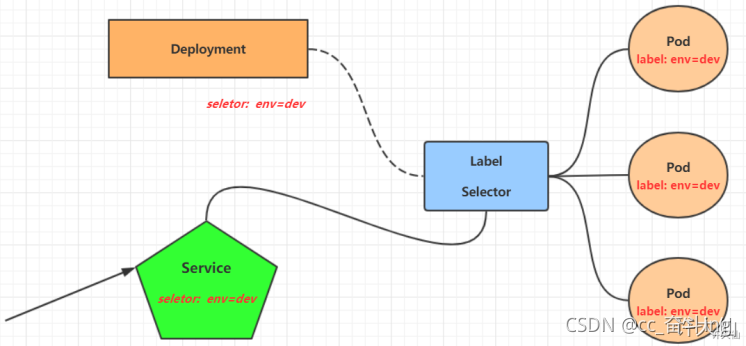
在kubernetes中,Pod是应用程序的载体,我们可以通过Pod的IP来访问应用程序,但是Pod的IP地址不是固定的,这就意味着不方便直接采用Pod的IP对服务进行访问。
为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个Pod进行聚合,并且提供一个统一的入口地址,通过访问Service的入口地址就能访问到后面的Pod服务。
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行了一个kube-proxy的服务进程。当创建Service的时候会通过API Server向etcd写入创建的Service的信息,而kube-proxy会基于监听的机制发现这种Service的变化,然后它会将最新的Service信息转换为对应的访问规则。
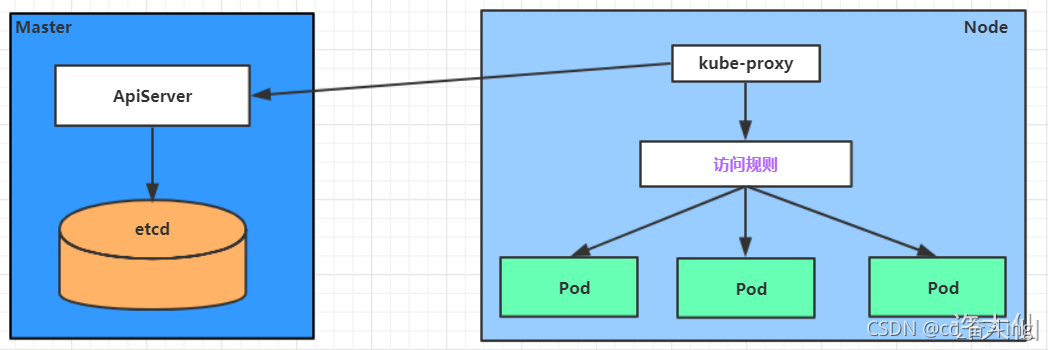
service本质 底层proxy会把service转换为访问规则 最后实际工作的是访问规则 service只是一个表象
# 10.97.97.97:80 是service提供的访问入口
# 当访问这个入口的时候,可以发现后面有三个pod的服务在等待调用,
# kube-proxy会基于rr(轮询)的策略,将请求分发到其中一个pod上去
# 这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上访问都可以。
[root@k8s-node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
• kube-proxy目前支持三种工作模式:
-
userspace模式:
userspace模式下,kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被iptables规则重定向到kube-proxy监听的端口上,kube-proxy根据LB算法(负载均衡算法)选择一个提供服务的Pod并和其建立连接,以便将请求转发到Pod上。
该模式下,kube-proxy充当了一个四层负载均衡器的角色。由于kube-proxy运行在userspace中,在进行转发处理的时候会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率非常低下。

-
iptables模式:
iptables模式下,kube-proxy为Service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod的IP上。
该模式下kube-proxy不承担四层负载均衡器的角色,只负责创建iptables规则。该模式的优点在于较userspace模式效率更高,但是不能提供灵活的LB策略,当后端Pod不可用的时候无法进行重试。
-
ipvs模式:
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高,除此之外,ipvs支持更多的LB算法。
开启ipvs(必须安装ipvs内核模块,否则会降级为iptables):
kubectl edit cm kube-proxy -n kube-system
kubectl delete pod -l k8s-app=kube-proxy -n kube-system
更改配置
# 测试ipvs模块是否开启成功
ipvsadm -Ln
小结
创建service本质上是生成一批转发规则
Service类型
• Service的资源清单:
apiVersion: v1 # 版本
kind: Service # 类型
metadata: # 元数据
name: # 资源名称
namespace: # 命名空间
spec:
selector: # 标签选择器,用于确定当前Service代理那些Pod 本质是通过访问规则
app: nginx
type: NodePort # Service的类型,指定Service的访问方式
clusterIP: # 虚拟服务的IP地址 service ip
sessionAffinity: # session亲和性,支持ClientIP、None两个选项,默认值为None 来自同一个ip的会被打到同一个Pod上
ports: # 端口信息
- port: 8080 # Service端口
protocol: TCP # 协议
targetPort : # Pod端口
nodePort: # 主机端口
spec.type的说明:
- ClusterIP:默认值,它是kubernetes系统自动分配的虚拟IP,只能在集群内部访问。
- NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务。
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境的支持。
- ExternalName:把集群外部的服务引入集群内部,直接使用。
实验环境准备
在使用Service之前,首先利用Deployment创建出3个Pod,注意要为Pod设置app=nginx-pod的标签。
创建deployment.yaml文件,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
# 创建Deployment:
kubectl create -f deployment.yaml
# 查看Pod信息:
kubectl get pod -n dev -o wide --show-labels
# 为了方便后面的测试,修改三台Nginx的index.html:
kubectl exec -it pc-deployment-7d7dd5499b-59qkm -c nginx -n dev /bin/sh
echo "10.244.1.30" > /usr/share/nginx/html/index.html
kubectl exec -it pc-deployment-7d7dd5499b-fwpgx -c nginx -n dev /bin/sh
echo "10.244.1.31" > /usr/share/nginx/html/index.html
kubectl exec -it pc-deployment-7d7dd5499b-nb6sv -c nginx -n dev /bin/sh
echo "10.244.2.67" > /usr/share/nginx/html/index.html
# 修改完毕之后,测试访问:
curl 10.244.1.30
curl 10.244.1.31
curl 10.244.2.67
ClusterIP类型的Service
可以在集群外部进行访问
创建service-clusterip.yaml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service的IP地址,如果不写,默认会生成一个
type: ClusterIP
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
• 创建Service:
kubectl create -f service-clusterip.yaml
#查看Service
• 查看Service:
kubectl get svc -n dev -o wide
# 查看Service的详细信息
• 查看Service的详细信息:
kubectl describe svc service-clusterip -n dev
# 查看ipvs的映射规则
• 查看ipvs的映射规则:
ipvsadm -Ln
# 访问10.97.97.97:80,观察效果
• 访问10.97.97.97:80,观察效果:
curl 10.97.97.97:80
我们创建的service k8s底层是会帮我们创建映射规则
Endpoint(实际中使用的不多)
• Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有Pod的访问地址,它是根据service配置文件中的selector描述产生的。
• 一个service由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合。换言之,service和Pod之间的联系是通过Endpoints实现的。
• 查看Endpoint:
kubectl get endpoints -n dev -o wide
负载分发策略
对Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
- 如果不定义,默认使用kube-proxy的策略,比如随机、轮询等。
- 基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上,这对于传统基于Session的认证项目来说很友好,此模式可以在spec中添加sessionAffinity: ClusterIP选项。
• 查看ipvs的映射规则,rr表示轮询:
ipvsadm -Ln
• 循环测试访问:
while true;do curl 10.97.97.97:80; sleep 5; done;
修改分发策略:
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service的IP地址,如果不写,默认会生成一个
type: ClusterIP
sessionAffinity: ClientIP # 修改分发策略为基于客户端地址的会话保持模式
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
# 创建
kubectl apply -f service-clusterip.yaml
• 循环测试访问:
while true;do curl 10.97.97.97:80; sleep 5; done;
3.2.8 删除Service
• 删除Service:
kubectl delete -f service-clusterip.yaml
HeadLiness类型的Service
概述
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLinesss Service,这类Service不会分配Cluster IP,如果想要访问Service,只能通过Service的域名进行查询。
创建Service
创建service-headliness.yaml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None # 将clusterIP设置为None,即可创建headliness Service
type: ClusterIP
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
# 创建Service:
kubectl create -f service-headliness.yaml
# 查看Service
# 查看Service:
kubectl get svc service-headliness -n dev -o wide
# 查看Service详情
# 查看Service详情:
kubectl describe svc service-headliness -n dev
# 查看域名解析情况
# 查看Pod:
kubectl get pod -n dev
# 进入Pod中,执行cat /etc/resolv.conf命令:
kubectl exec -it pc-deployment-7d7dd5499b-59qkm -n dev /bin/sh
cat /etc/resolv.conf
# 通过Service的域名进行查询
# 通过Service的域名进行查询:
dig @10.96.0.10 service-headliness.dev.svc.cluster.local
NodePort类型的Service
可以在集群外部使用
概述
在之前的案例中,创建的Service的IP地址只能在集群内部才可以访问,如果希望Service暴露给集群外部使用,那么就需要使用到另外一种类型的Service,称为NodePort类型的Service。NodePort的工作原理就是将Service的端口映射到Node的一个端口上,然后就可以通过NodeIP:NodePort来访问Service了。
创建Service
创建service-nodeport.yaml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: dev
spec:
selector:
app: nginx-pod
type: NodePort # Service类型为NodePort
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
nodePort: 30002 # 指定绑定的node的端口(默认取值范围是30000~32767),如果不指定,会默认分配
# 创建Service:
kubectl create -f service-nodeport.yaml
# 查看Service
# 查看Service:
kubectl get svc service-nodeport -n dev -o wide
# 访问
# 通过浏览器访问:http://192.168.18.100:30002/即可访问对应的Pod。
LoadBalancer类型的Service
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境的支持,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中。
ExternalName类型的Service
概述
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定一个服务的地址,然后在集群内部访问此Service就可以访问到外部的服务了。
创建Service
创建service-externalname.yaml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-externalname
namespace: dev
spec:
type: ExternalName # Service类型为ExternalName
externalName: www.baidu.com # 改成IP地址也可以
# 创建Service:
kubectl create -f service-externalname.yaml
# 域名解析
# 域名解析:
dig @10.96.0.10 service-externalname.dev.svc.cluster.local
网络通讯方式
k8s中Pod相互之间如何通信?以及Pod与外部如何通信?
Flannel
通过Flannel可以实现不通主机内
同一个主机内的Pod可以直接ping通(同一个网段)通过Docker0(lo)
不同主机内的Pod需要通过Flannel才能ping通(overlay netowork)
所以同一个集群内的Pod之间是可以ping通的
ETCD之Flannel提供说明
存储管理Flannel可分配的IP地址段资源 (ETCD中记录着那个节点是那个网段 避免集群中ip冲突)
监控ETCD中每个Pod的实际地址 并在内存中简历维护Pod节点路由表 (如找到别放Pod对应的主机ip 这些信息都存储在ETCD中)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168525.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...