大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
P1
一、线性回归中的模型选择


上图所示:
五个模型,一个比一个复杂,其中所包含的function就越多,这样就有更大几率找到一个合适的参数集来更好的拟合训练集。所以,随着模型的复杂度提高,train error呈下降趋势。

上图所示:
右上角的表格中分别体现了在train和test中的损失值大小,可以看出,从第三个模型开始,就呈过拟合(Overfitting)状态。
二、分种类的训练模型
当模型会根据种类不同而有较大区别时,可以分种类来形成多个不同的model。在李宏毅老师举例中,不同的精灵在进化前和进化后CP值得变化曲线是不同的。如下图所示:
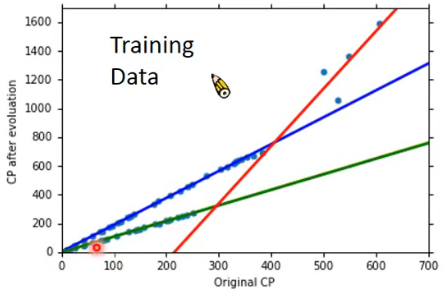
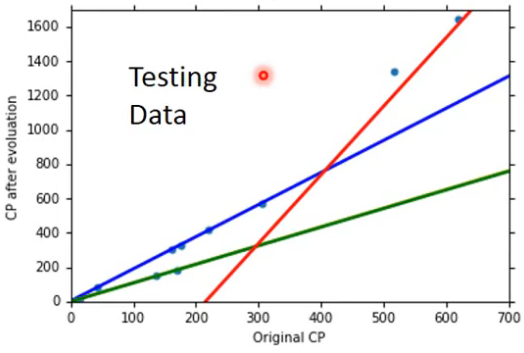
这样分类别来训练模型,可以更好的让model拟合真实数据。
三、添加正则化

使用正则化后,当w非常小(接近0)的时候,我们的输入变化对结果的影响会趋于0。所以我们可以通过调整λ参数来调整正则化的强度。λ越大时,模型曲线更平滑。
在这里,我们不需要对b进行正则化,因为b只会影响模型曲线上下移动(b是常数),所以无需对其进行调整。
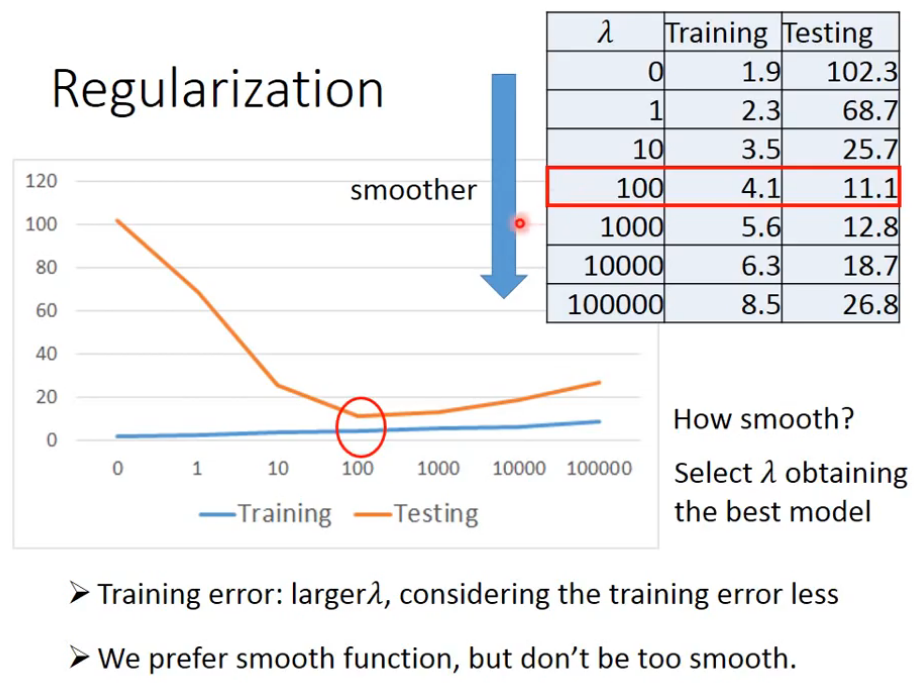
如上图所示:
根据λ从小变大,test的损失越来越小,达到一个最小值后,又越来越大。而train的损失值逐渐变大。这是因为当λ变大时,模型越来越平滑,在降低过拟合的同时,也使得对训练数据的拟合度降低。如图中曲线所示,我们可以找到一个train和test损失值最相近的地方,这里就是λ的最佳取值。
我们需要将曲线变得平滑一点,但又不能将其变得过于平滑,如果过于平滑就会从过拟合(train的loss低,test的loss高)变为欠拟合(train的loss高,test的loss也比较高)。
P2
一、学习率的调整

在我们调整学习率的时候,我们尽量画出右边的曲线,观察学习率是否过大或过小,然后选择一个最合适的学习率η。
二、学习率的自动调整
Adagrad:
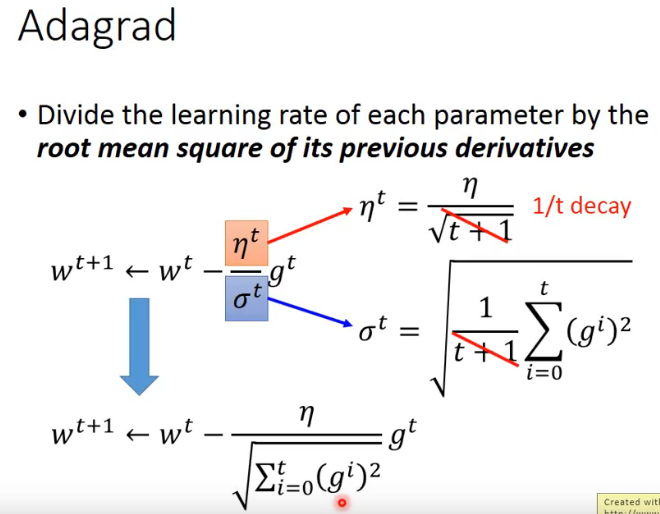
在Adagrad中,学习率在每次迭代的时候,都除以以前所有步数的梯度的平方和根。但是Adagrad有个问题,就是学习率衰减很快,有可能提前结束训练,从而无法从后面的数据中学习到有用的信息。
在这里面,可以看出一个比较矛盾的地方,即gt比较大的时候,分母也会比较大,与我们初衷不符(应该是在陡峭的地方,我们希望学习率越大),这背后的原理我们可以参考P2中19:30-31:00的讲解。
SGD:
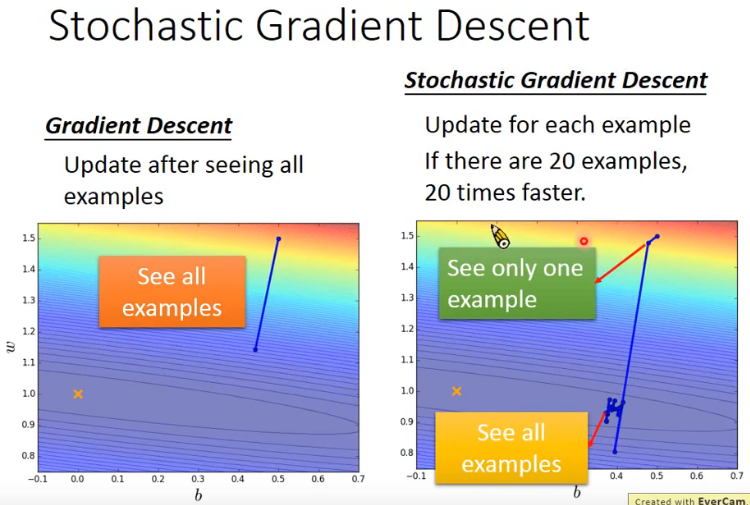
SGD就是每看一个样本就更新一次权重。假设一共有20个样本,普通的梯度下降每次迭代都要看20个样本,然后使用平均的梯度来更新权重,但是如果使用SGD的话,我们同样看20个样本,则已经更新20次。如图中所示,后者在更新20次后,所前进到的位置优于前者。
但SGD有一个缺点,就是每一个样本都更新权重,则使得在计算上可能无法充分发挥矩阵运算的效率。而且在接近最优解的地方可能震荡范围比较大。
特征伸缩(Gradient Descent):
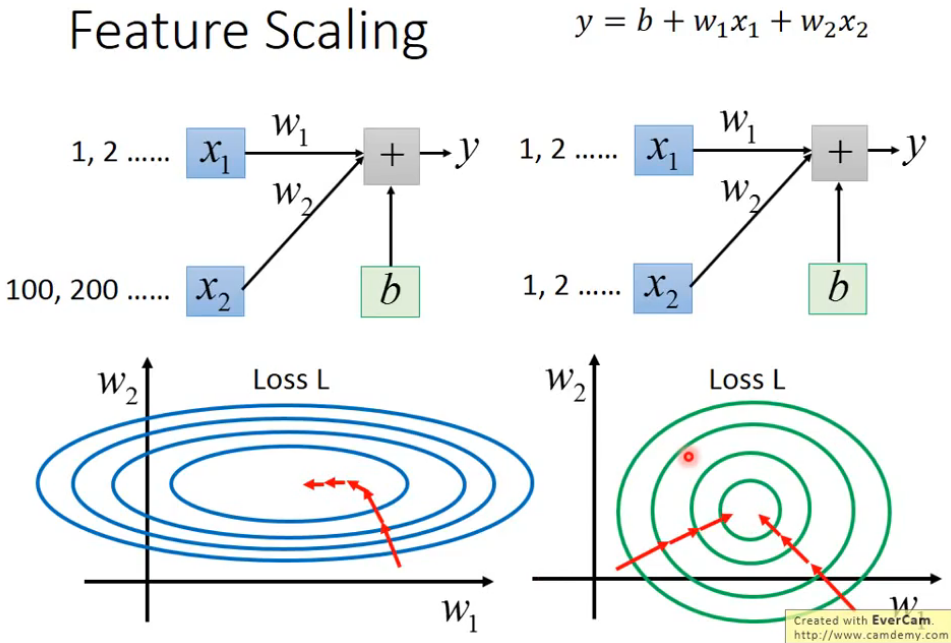
特征伸缩可以将取值范围差别很大的特征伸缩到范围处于同一量级,这样的话相当于同一了各个维度的梯度(不会出现一个方向很平缓、一个方向很陡峭的极端情况)。这样在更新权重的时候,每个方向的更新速度就相差不大,这样可以加快收敛的速度。
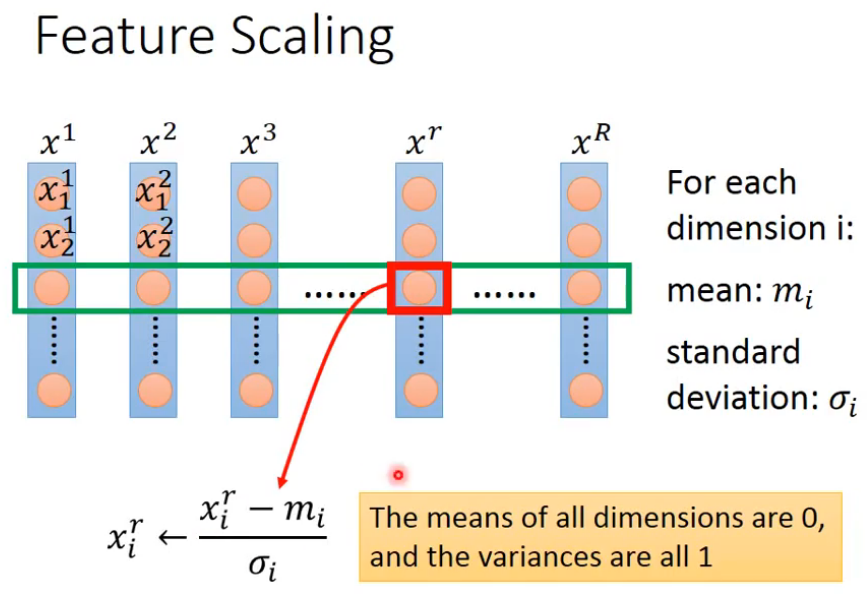
如上图所示,对于R个样本,每个样本中不同Feature分别求平均值Mi,然后各个值减去相应的平均值,然后再除以方差。这样就会使得该Feature的所有数据的平均值为0,方差为1。如下图所示:

三、梯度下降的来源
参考P2 44:20-59:30对梯度下降的推导过程。
1.通过泰勒级数(Taylor Series)将Loss function展开。

2.在梯度下降中,我们只考虑k=0和k=1的情况,也就是说只使用一阶微分。在多变量的情况下:

3.当红框非常小的时候,以上式子才成立
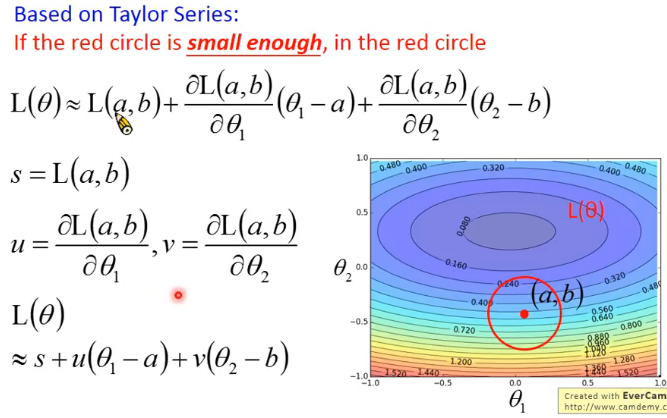
4.我们将式子做一定变换,然后忽略常数S,我们如何来使L(θ)最小,我们就需要取(Δθ1,Δθ2)的方向与(u,v)相反,如下图所示:
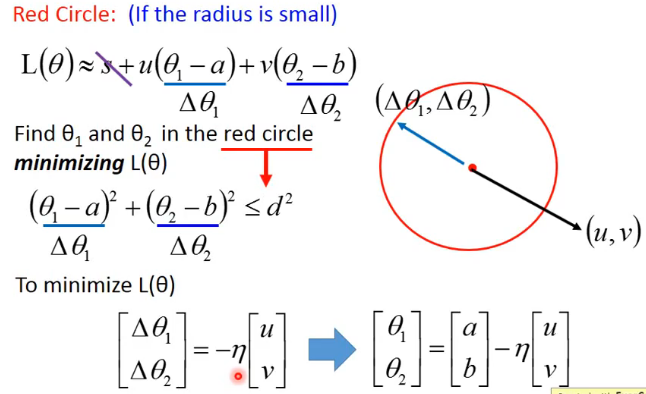
5.下图中描述,当红圈非常小时,L(θ)式子才成立,我们将u和v的计算式带入L(θ)就可以得到梯度下降对权重更新公式。当然,在梯度下降中,我们只考虑了泰勒级数的一阶微分项。在某种情况下,我们也可以将二阶甚至三阶加入考虑(例如牛顿法就考虑了二次式),但是由于二阶以上的微分求解消耗比较大,所以在梯度下降中并未做考虑。一定要注意,要让梯度下降算法生效,最重要的就是红色圆圈要足够小,也就是说学习率要足够小。

四、我们无法知道梯度更新接近0的时候是不是局部最优
P3

当我们执行梯度下降时,我们就像上图中游戏一样,我们无法知道我们走到的一个梯度接近0的位置到低是不是局部最优(甚至全局最优),因为周边都是黑雾,除非我们作弊开天眼。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168398.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
