大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
转自: https://blog.csdn.net/lyl771857509/article/details/78990215
神经网络
好了,前面花了不少篇幅来介绍激活函数中那个暗藏玄机的e,下面可以正式介绍神经元的网络形式了。
下图是几种比较常见的网络形式:
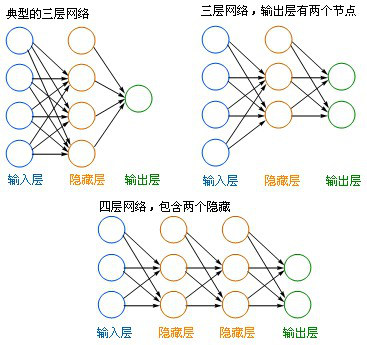
- 左边蓝色的圆圈叫“输入层”,中间橙色的不管有多少层都叫“隐藏层”,右边绿色的是“输出层”。
- 每个圆圈,都代表一个神经元,也叫节点(Node)。
- 输出层可以有多个节点,多节点输出常常用于分类问题。
- 理论证明,任何多层网络可以用三层网络近似地表示。
- 一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
计算方法:
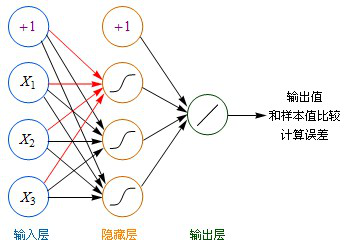
- 虽然图中未标识,但必须注意每一个箭头指向的连线上,都要有一个权重(缩放)值。
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
前面讲过,使用梯度下降的方法,要不断的修改k、b两个参数值,使最终的误差达到最小。神经网络可不只k、b两个参数,事实上,网络的每条连接线上都有一个权重参数,如何有效的修改这些参数,使误差最小化,成为一个很棘手的问题。从人工神经网络诞生的60年代,人们就一直在不断尝试各种方法来解决这个问题。直到80年代,误差反向传播算法(BP算法)的提出,才提供了真正有效的解决方案,使神经网络的研究绝处逢生。

BP算法是一种计算偏导数的有效方法,它的基本原理是:利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。
为了便于理解,后面我一律用“残差(error term)”这个词来表示误差的偏导数。
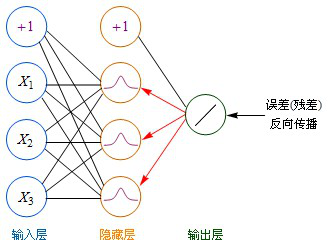
输出层→隐藏层:残差 = -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 激活函数的导数
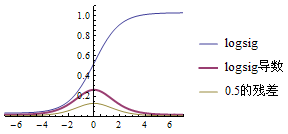
如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数 = Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差 = -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)输出值(1-输出值)
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 – tansig^2
残差全部计算好后,就可以更新权重了:
输入层:权重增加 = 当前节点的Sigmoid * 右层对应节点的残差 * 学习率
隐藏层:权重增加 = 输入值 * 右层对应节点的残差 * 学习率
偏移值的权重增加 = 右层对应节点的残差 * 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
BP神经网络的特点和局限:
– BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
– BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性 > 生理相似性。
– BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
– BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
文字的公式看上去有点绕,下面我发一个详细的计算过程图。
参考这个:http://www.myreaders.info/03_Back_Propagation_Network.pdf 我做了整理
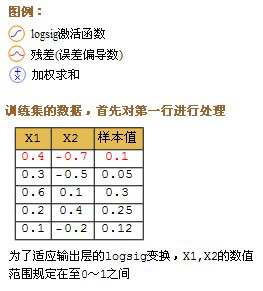
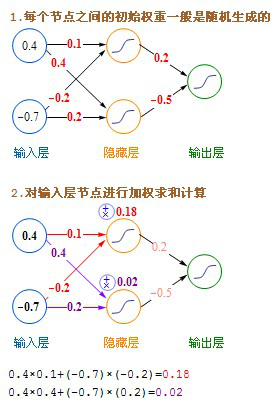

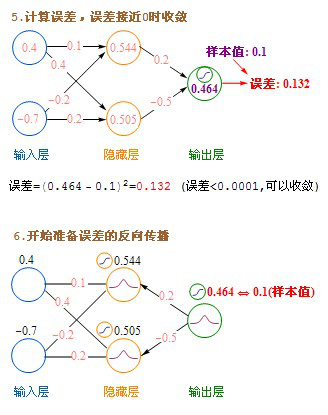
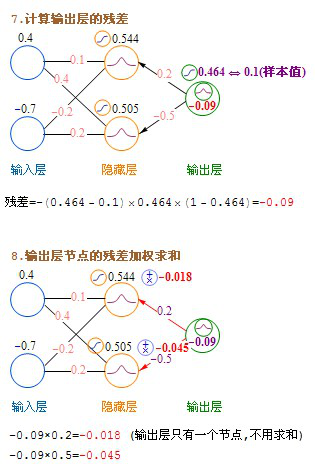
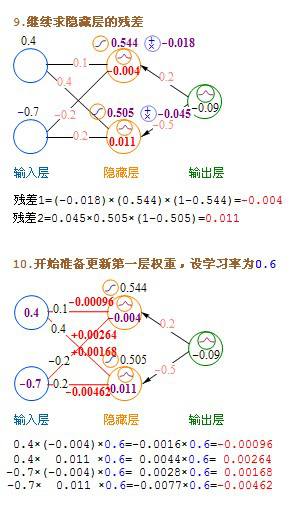

这里介绍的是计算完一条记录,就马上更新权重,以后每计算完一条都即时更新权重。实际上批量更新的效果会更好,方法是在不更新权重的情况下,把记录集的每条记录都算过一遍,把要更新的增值全部累加起来求平均值,然后利用这个平均值来更新一次权重,然后利用更新后的权重进行下一轮的计算,这种方法叫批量梯度下降(Batch Gradient Descent)。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168089.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...