大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
加里·卡斯帕罗夫 vs 深蓝(1997年)


1997年,美国IBM公司的“深蓝”(Deep Blue)超级计算机以2胜1负3平战胜了当时世界排名第一的国际象棋大师卡斯帕罗夫。
深蓝能算出12手棋之后的最优解,而身为人类的卡斯帕罗夫只能算出10手棋。
深蓝的核心是通过穷举方法,生成所有可能的下法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳的一手。
简单地说,深蓝是以暴力穷举为基础,并且是专注国际象棋的专用人工智能
李世石 vs Alpha Go(2016年)


2016年3月,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜
AlphaGo 核心是基于深度神经网络,从数据中预测人类棋手在做任意的棋盘状态下走子的概率,模拟人类棋手的思维方式。在整个算法中,除了“获胜”概念,AlphaGo对于围棋规则一无所知。
简单地说,AlphaGo是基于机器学习,不限定领域的人工智能。
AlphaGo vs AlphaGo Zero(2017年)
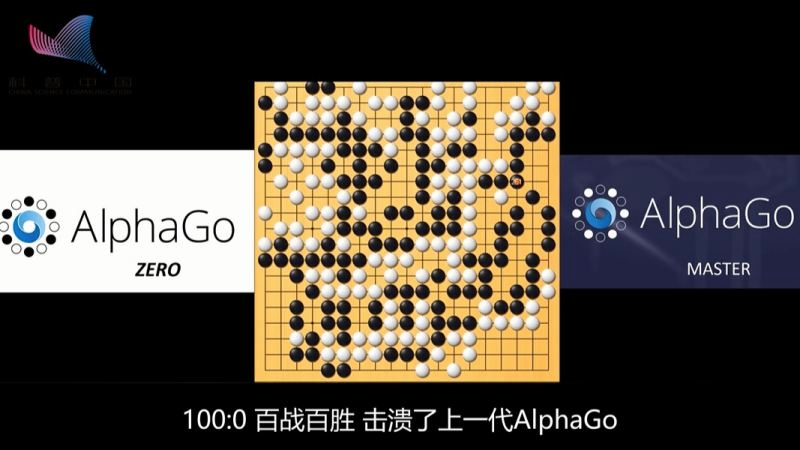
2017年,仅仅通过3天的自我训练的,AlphaGo Zero就打败了战胜李世石的AlphaGo,战绩100:0。
和AlhaGo不同,AlphaGo Zero完全抛弃来自棋谱数据的人类经验,而是通过“左右手互搏”,迅速提战力。
AlphaGo Zero依赖神经网络来评估落子位置,成功证明了在没有人类指导和经验的前提下,深度强化学习方法在围棋领域里仍然能够出色的完成指定的任务。
AlphaGo和AlphaGo Zero的核心都是深度学习,那深度学习究竟是什么呢?
一、什么是深度学习

深度学习是利用包含多个隐藏层的人工神经网络实现的学习。
深度学习思想来源于人类处理视觉信息方式,人类视觉系统是这个世界上最为神奇的一个系统。
1981年的诺贝尔医学奖得主David H.Hubel 和Torsten Wiesel的研究表明:即人脑视觉机理,是指视觉系统的信息处理在可视皮层是分级的,大脑的工作过程是一个不断迭代、不断抽象的过程。视网膜在得到原始信息后,首先经由区域V1初步处理得到边缘和方向特征信息,其次经由区域V2的进一步抽象得到轮廓和形状特征信息,如此迭代地经由更多更高层的抽象最后得到更为精细的分类。
人眼处理来自外界的视觉信息时,首先提取出目标物的边缘,再从边缘特性中提取出目标物的特征,最后将不同特征组合成相应的整体,进而准确地区分不同的物体,在这个过程中,高层特征是低层特征的组合,从低导到高层,特征变得越来越抽象,对目标物的识别也越来越精确 。
在深度学习中,每个层可以对数据进行不同水平的抽象,层间的交互使较高层在较低层得到的特征基础上实现更加复杂的特征提取。
深度学习是建立在大数据量和超强的计算能力之上,因为多个隐藏层使用了大量的隐藏神经元,庞大的数据处理需要有非常强的计算能力做支撑
前馈神经网络
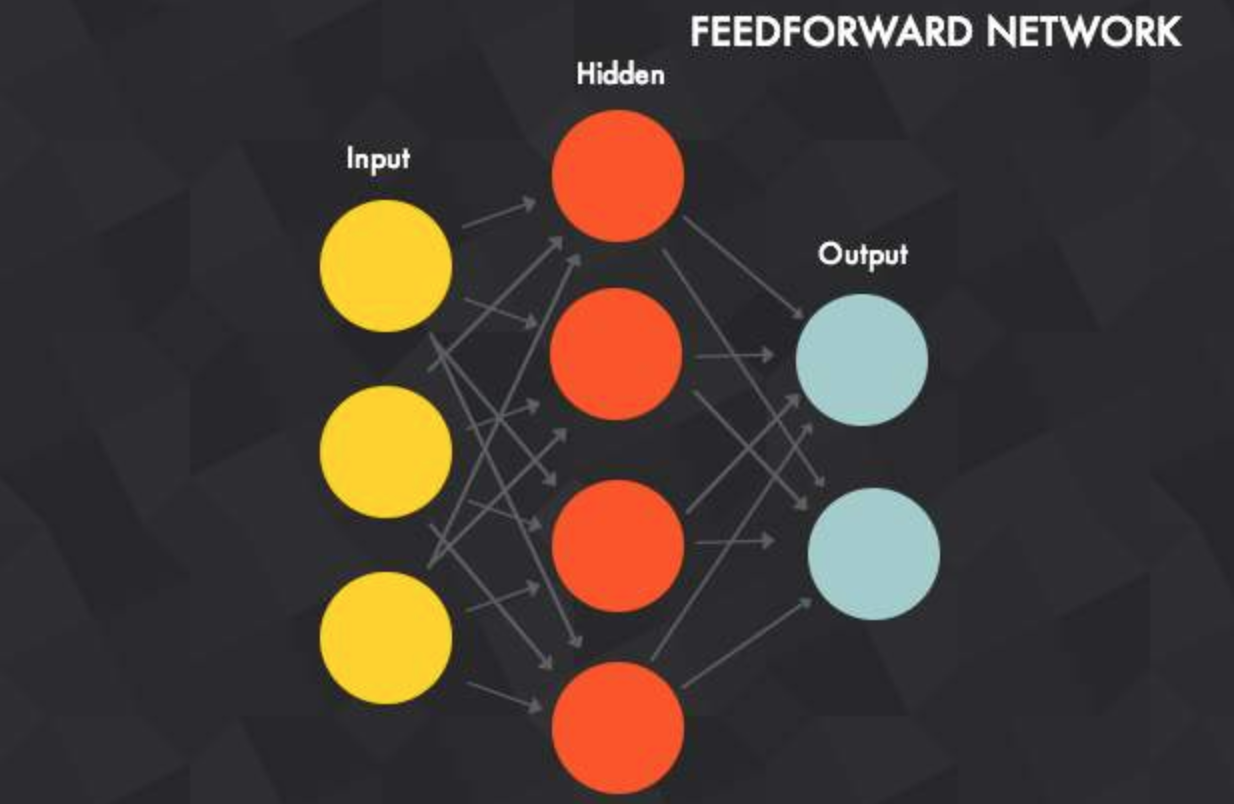
具有深度结构的前馈神经网络,可以看成是进化版的多层感知器。
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。
在层与层之间,深度架构采用的最常见的方式是全连接,意味着相邻层次中的任意神经元都是两两相连。
任何机器学习算法都可以看成是对某个预设函数的最优化方法,深度前馈网络也一样。深度前馈神经网络也是利用梯度信息进行学习,处理误差采用反向传播方法,利用反向传播求出梯度后再使用随机梯度下降法寻找损失函数的最小值。
深度前馈网络的损失函数通常是交叉熵或最小均方差,回归问题的损失函数通常是最小均方误差,而分类问题的损失函数通常是交叉熵。
二、正则化

正则化是抑制过拟合的手段,是一类通过显式设计降低泛化误差,提升通用性的策略的统称。
通常来说,泛化误差的下降是以训练误差的上升为代价的。
从概率论角度,许多正则化技术对应的是在模型参数上施加一定的先验分布,作用是改变泛化误差的结构。机器学习的任务是拟合出一个从输入x到输出y的分布,拟合过程是使期望风险函数最小化的过程。
奥卡姆剃刀原则

正则化处理可以看成是奥卡姆剃刀原则在学习算法上的应用。
奥卡姆剃刀原则 :如无必要,勿增实体
简单地说,就是当两个假说具有完全相同的解释力和预测力时,以那个较为简单的假说作为讨论依据。
机器学习中,正则化得到的是更加简单的模型、
常用正则化
- 数据增强。数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来人工增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转通常应用在视觉表象和图像分类中
- Dropout。一种集成方法,通过结合多个模型来降低泛化误差,在训练期间从神经网络中随机丢弃神经元及其连接,得到简化的网络。
- L2 & L1 正则化。L1 和 L2 正则化是最常用的正则化方法。L1和L2是最常见的正则化方法。它们在损失函数中增加一个正则项,权重矩阵的值减小,会在一定程度上减少过拟合。
- 早停法。是一种交叉验证策略,将一部分训练集作为验证集, 当看到验证集的性能越来越差时,立即停止对该模型的训训。
三、优化

深度神经网络中隐藏层比较多,将整个网络作为一个整体进行优化是非常困难的事,出于效率和精确性的考虑,需要采取一些优化的手段。
存在问题
- 病态矩阵
在线性方程 \(Ax=b\) 中,当系数矩阵A的微小扰动会给解集 x 带来较大幅度的波动时,这样的矩阵就被称为病态矩阵。
在神经网络训练中,病态矩阵的影响体现在梯度下降的不稳定性上,在使用随机梯度下降解决优化解决优化问题时,病态矩阵对输入的敏感性会导致很小的更新步长也会增加代价函数,使得学习的速度变得异常缓慢 - 局部极小值
绝大多数深度学习的目标函数有若干局部最优值。当一个优化问题的数值解在局部最优解附近时,由于梯度接近或变成零,最终得到的数值解可能只令目标函数局部最小化而非全局最小化。 - 鞍点
梯度接近或变成0可能是由于当前解在局部最优解附近所造成的。事实上,另一种可能性是当前解在鞍点附近。鞍点是梯度为 0 的临界点,由于牛顿法的目标是寻找梯度为0的临界点,因而会受鞍点的影响较大,高维空间中鞍点数目的激增就会严重限制牛顿法的性能。
优化方法

随机梯度下降法是在机器学习的经典算法,是对原始梯度下降法的一种改良。为了节省每次迭代的计算成本,随机梯度下降在每一次迭代中都使用训练数据集的一个较小子集来求解梯度的均值,随机梯度下降法让每几个样本的风险函数最小化,虽然不是每次迭代的结果都是指向全局的最优方向,但是大方向没有错,最终的结果也在全局最优解附近。
在随机梯度下降法的基础上改进,常见方法有:
- 随机降低噪声。常用的降噪方法有动态采样 、梯度聚合、迭代平均。
- 使用二阶导数近似。主要的优势在于提升收敛速度,可以看成对传统的牛顿法的改进
- 动量法、加速下降、坐标下降法。
四、自编码器
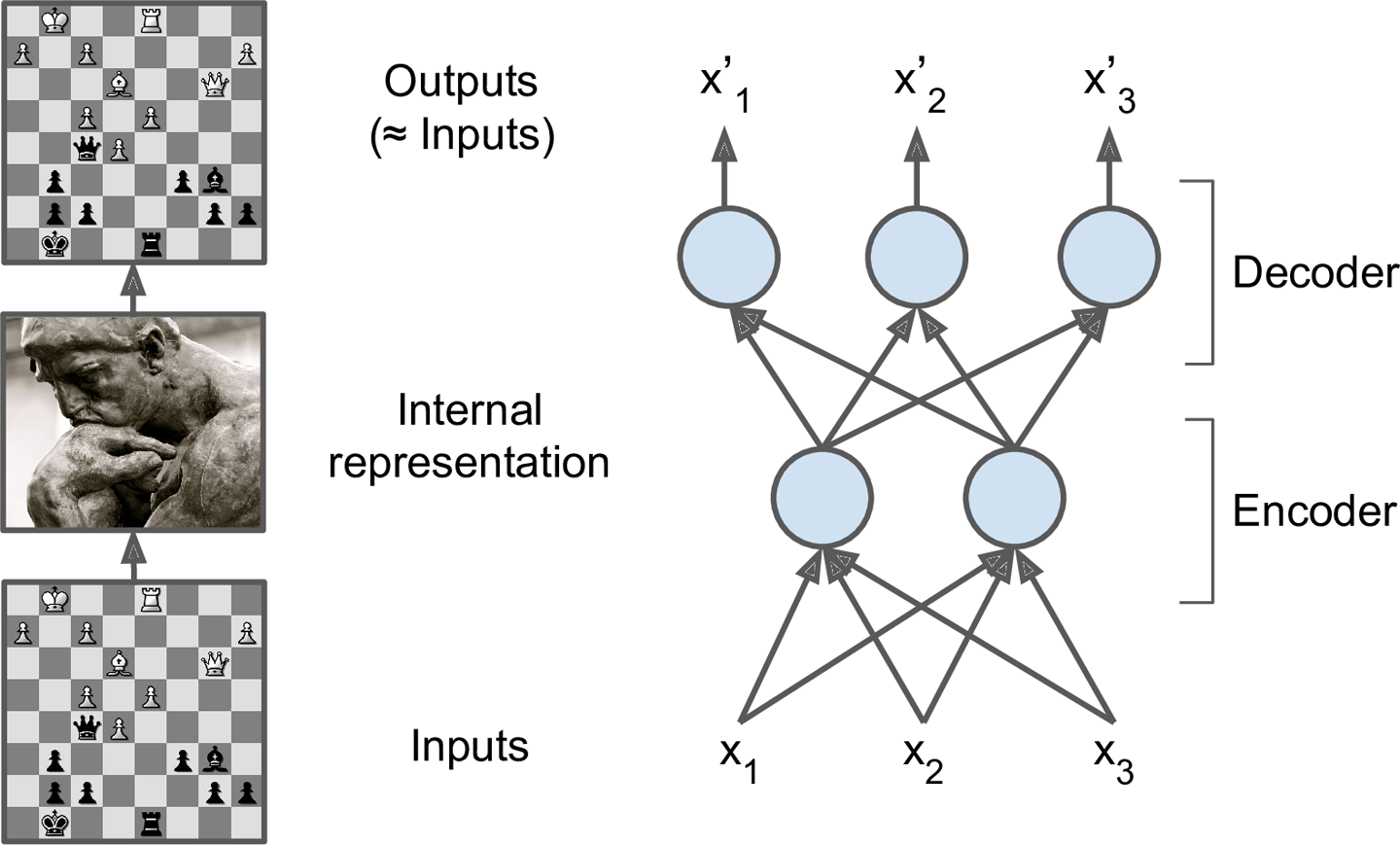
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习.
自编码器包含编码器和解码器两部分。
一个自编码器接收输入,将其转换成高效的内部表示,然后再输出输入数据的类似物。
自编码器通常包括两部分:encoder(也称为识别网络)将输入转换成内部表示,decoder(也称为生成网络)将内部表示转换成输出。
从信息论的角度看,编码器可以看成是对输入信源的有损压缩。
深度神经网络既可以用于分类,也可以用于特征提取,而自编码器具有提取特征的作用。
栈式自编码器
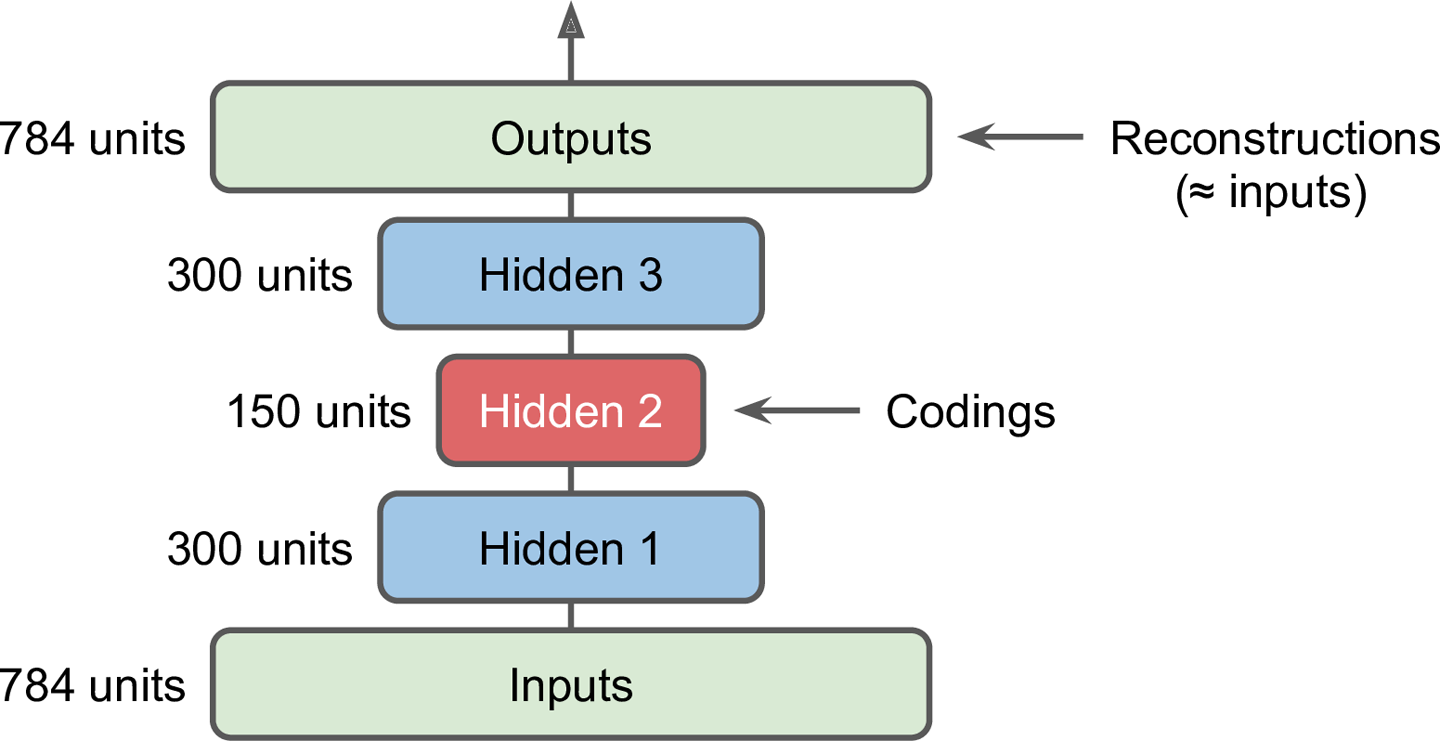
自编码器可以有多个隐层,这被称作栈式自编码器(或者深度自编码器)
增加隐层可以学到更复杂的编码,但也不能过于强大。
栈式自编码器的架构一般是关于中间隐层对称的。如果一个自编码器的层次是严格轴对称的,一个常用的技术是将decoder层的权重捆绑到encoder层。这使得模型参数减半,加快了训练速度并降低了过拟合风险。
去噪自编码器
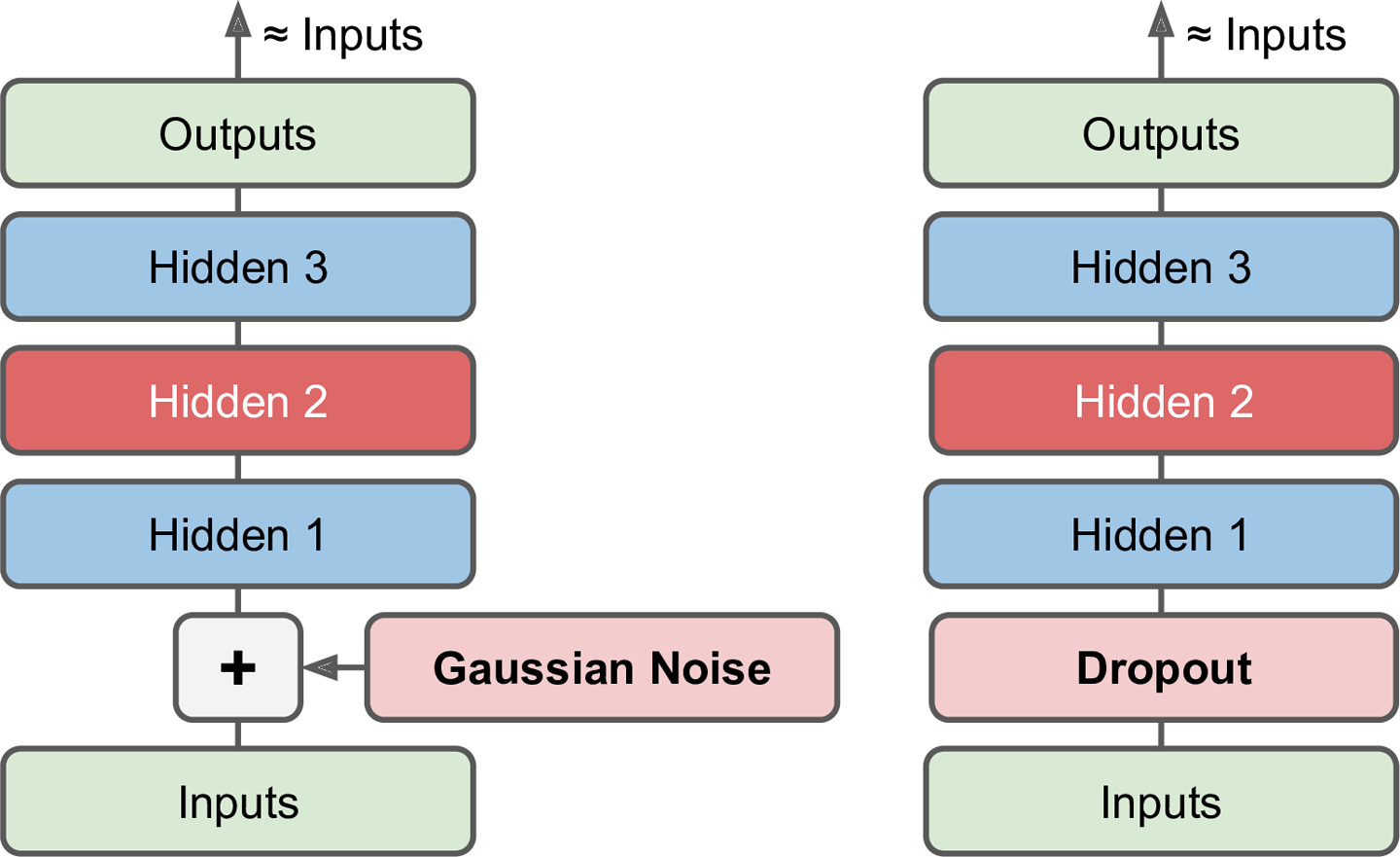
接受损坏数据作为输入,通过训练之后得到无噪声的输出的自编码器。
去噪自编码器要求对非理想数据的处理结果尽可能逼近原始数据,这防止了自编码器简单的将输入复制到输出,从而提取出数据中有用的模式。噪声可以是添加到输入的纯高斯噪声,也可以是随机丢弃输入层的某个特征,类似于dropout。
五、强化学习

强化学习是智能系统从环境到行为的学习过程,智能体通过与环境的互动来发送自身的行为,改善准则是使某个累积奖励函数最大化。
强化学习是基于环境反馈实现决策制定的通用框架,根据不断试错得到来自环境的奖励或者惩罚,从而实现对趋我晚上信念的不断增强。强调在与环境的交互过程中实现学习,产生能获得最大利益的习惯性行为。
最常用的模式是马尔可夫决策过程。
马尔可夫决策过程

马尔可夫决策过程(Markov Decision Processes,MDPs),简单说是一个智能体(Agent)采取行动从而改变自己的状态(State)获得奖励(Reward)与环境(Enviroment)发生交互的过程。
可以简单表示为\(M=<S,A,P_{s,a},R>\),基本概念如下:
- S:由智能体和环境所处的所有可能状态构成的有限集合,s表示某个特定状态
- A:由智能体的所有可能动作构成的有限集合,a表示某个特定动作
- \(Pa(s,s′)=Pr(s_{t+1}=s′∣s_t=s,a_t=a)\):智能体在t时刻做出的动作a使马尔可夫过程的状态从\(t\)时刻的\(s\)转移为\(t+1\)时刻的\(s′\)的概率
- \(Ra(s,s′)\):智能体通过a使状态从\(s\)转移到\(s′\)得到的实时奖励
在某个时间点上,智能体对环境进行观察,得到这一时刻的奖励,接下来会在动作集中选择一个动作发送给环境。来自智能体的动作既能改变环境的状态,也会改变来自环境的奖励。
在智能体与环境不断互动的过程是为了让自己得到的奖励最大化。
深度强化学习

是深度学习和强化学习的结合,将深度学习的感知能力和强化学习的决策能力融为一体,用深度学习的运行机制达到强化学习的优化目标,是一种更接近人类思维方式的人工智能方法。
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。按实施方式,分为以下三类
- 基于价值。建立一个价值函数的表示,通过优化价值函数得到最优策略
- 基于策略。直接搜索能够使未来奖励最大化的最优策略
- 基于模型。构造关于环境的转移概率模型,再用这个模型来指导决策。
以上由chenqionghe整理,light weight baby!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167776.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...