大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
————恢复内容开始————
特征:
持续到达,数据量大,注重数据整体价值,数据顺序可能颠倒,丢失,实时计算,
海量,分布,实时,快速部署,可靠
linked in Kafka
spark streaming:微小批处理,模拟流计算,秒级响应
DStream 一系列RDD 的集合
支持批处理




创建文件流

10代表每10s启动一次流计算
textFileStream 定义了一个文件流数据源
任务: 寻找并跑demo代码 搭建环境 压力测试 产品
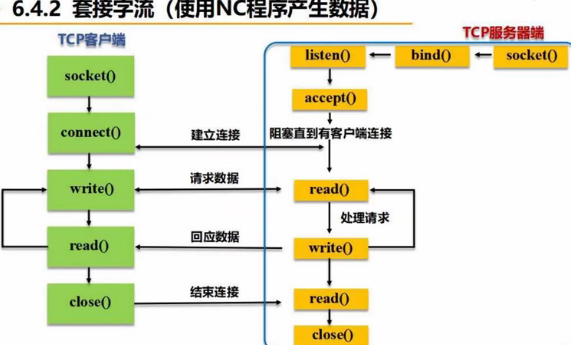
套接字流
插播: futrue使用(为了兼容老版本python)
https://www.liaoxuefeng.com/wiki/897692888725344/923030465280480
客户端进行刺频统计,并显示结果。
#!/usr/bin/env python3 from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv)!=3: print("Usage: NetworkWordCount.py <hostname><port>",file=sys.stderr) exit(-1) # this is for two arg plus itself sc=SparkContext(appName="PythonStreamingNetworkWordCount") ssc=StreamingContext(sc,1) lines=ssc.socketTextStream(sys.argv[1],int(sys.argv[2])) counts=lines.flatMap(lambda line:line.split(""))\ .map(lambda word:(word,1))\ .reduceByKey(lambda a,b:a+b) counts.pprint() ssc.start() ssc.awaitTermination()
客户端从服务端接收流数据:
# 用客户端向服务端发送流数据 $ /usr/local/spark/bin/spark-submit NetworkWordCount.py localhost <端口>
服务端,发送
(a) 系统自带服务端 nc。
# 打开服务端 $nc -lk <端口号>
#!/usr/bin/env python3
# NetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == “__main__”:
if len(sys.argv) != 3:
print(“Usage: NetworkWordCount.py <hostname> <port>”, file=sys.stderr)
exit(-1)
sc = SparkContext(appName = “PythonStreamingNetworkWordCount”)
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(” “)) \
.map(lambda word: (word, 1))\
.reduceByKey(lambda a,b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc=SparkContext(appName=”RDDstream”)
ssc=StreamingContext(sc,2)
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1,1001)],10)]
time.sleep(1)
inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x:(x%10,1))
reducedStream=mappedStream.reduceByKey(lambda a,b:a+b)
reducedStream.pprint()
ssc.start()
ssc.stop(stopSparkContext=True,stopGraceFully=True)
kafka作为高级数据源
1。安装
先查看spark版本,spark-shell查看
version2。4。4 scala 2。11。12
具体参见课程64 以及
需要安装jar包到spark内
Dstream(Discreted stream 离散的)无状态转换
https://www.cnblogs.com/jesse123/p/11452388.html
https://www.cnblogs.com/jesse123/p/11460101.html
只统计当前批次,不会去管历史数据
Dstream 有状态转换
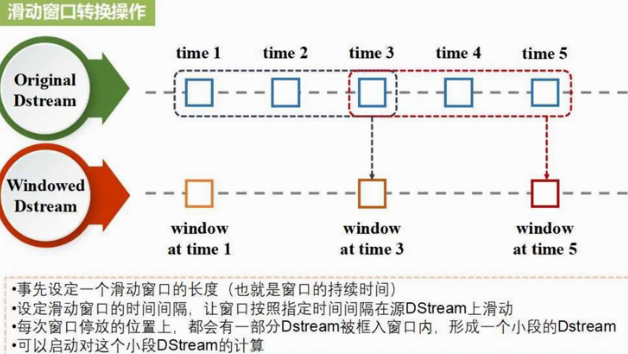
(windowLength,slideInterval)滑动窗口长度,滑动窗口间隔


名称一样 但function不一样 逆函数减少计算量

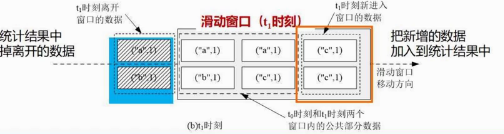
新进来的x+y,离开的x-y,当中的数据(几百万条)不动 30 (应该是秒为单位)滑动窗口大小 10秒间隔
有状态转换upstatebykey操作
跨批次之间维护
https://www.cnblogs.com/luotianshuai/p/5206662.html#autoid-0-3-0
这篇blog很详细 kafka相关概念 集群搭建
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167477.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
