大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
本文发表在ACL2019,使用信息实体增强语言表示的ERNIE的翻译。同时还有另一种百度提出的ERNIE
– By Brisk Yu
感觉关键在于知识实体的构建 看TransE
ERNIE:使用信息实体增强语言表示
摘要
在大规模语料上预训练的自然语言表征模型(如BERT)可以从纯文本中捕获丰富的语义模式,并且能够通过微调以继续提升各种NLP任务的性能。然而,目前的预训练语言模型没有与知识图(KG)相结合,其可以为更好的语言理解提供丰富的结构化知识事实。我们认为,KG中的信息实体可以通过外部知识提升语言表示。本文中,我们利用大规模文本语料库和知识图训练了一个增强语言表征模型(ERNIE),其可以同时利用词汇、句法和知识信息。实验结果显示,ERNIE在不同的知识驱动任务取得了显著的改进,同时在其它常见任务上与现有的BERT模型具有可比性。源代码与实验详情可见:https://github.com/thunlp/ERNIE。
1 概述
预训练语言表征模型包括基于特征和微调的方法,可以从文本中获得丰富的语言信息并使许多NLP应用受益。BERT作为最近才提出的方法,通过简单的微调在不同的NLP应用中获得了最好的结果,包括NER、机器问答、自然语言推理和文本分类。
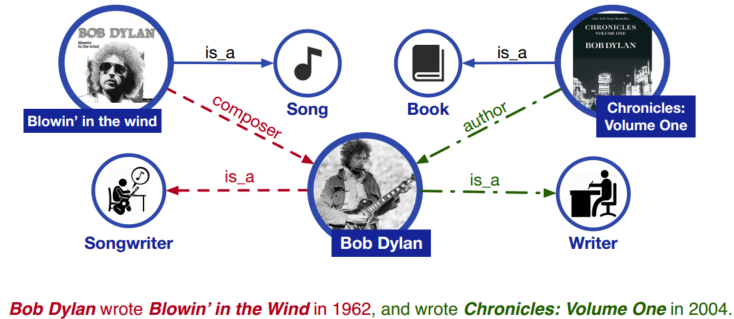

图1 一个将知识信息包含在语言理解中的例子。实线代表目前存在的知识事实,红虚线代表从红色句子中抽取的知识,绿色线条代表从绿色句子中抽取的知识
虽然预训练语言表征模型取得了很好的效果并在许多NLP任务中作为常规模块,但是其忽略了将知识信息整合到语言理解中。如图1,如果不知道Blowin’ in the Wind和Chronicles: Volume One分别是歌曲和书名,我们在实体分类任务中就很难知道Bob Dylan的两种职业:歌曲创作人和作家。此外,在关系分类任务中几乎不可能抽取细粒度关系,如作曲家和作者。对于现有的预训练语言模型,这两句话在句法上是不明确的,类似“UNK wrote UNK in UNK”。因此,考虑丰富的知识信息可以获得更好的语言理解,从而有利于各种知识驱动的应用,例如实体分类和关系分类。
将外部知识整合进语言表征模型具有两个挑战:1)结构化知识编码:对于给定的文字,如何为语言表征模型有效地抽取和编码与KG相关的信息实体是十分重要的问题;2)异构信息融合:语言表征的预训练过程与知识表征过程略有不同,这会产生两个独立的向量空间。如何设计一个特殊的预训练任务来融合词汇、语义和知识信息是另一个挑战。
为了克服以上两个挑战,我们提出了基于信息实体的增强语言表征模型,该模型基于大规模语料库和KG预训练语言表征模型:
1)为了抽取和编码知识信息,我们首先识别文本中的命名实体mention,然后将这些mention与KG中的实体相对齐。我们使用TransE这样的知识嵌入算法编码KG的图结构,而不是直接使用KG中基于图的事实,然后将信息实体嵌入作为ERNIE的输入。基于KG和文本的对齐,ERNIE将知识模型中的实体表征整合进了语义模型的底层中。
2)类似BERT,我们使用MASK和预测下一句作为训练任务。此外,为了更好的融合文本和知识特征,我们设计了新的训练任务:随机mask输入文本中的实体对其,并让模型从KG中选择合适的实体来完成对齐。与传统模型仅使用本地上下文信息预测token不同,我们的训练任务需要模型合并上下文和知识事实来预测token和实体,这样就可以得到含有知识的语言表征模型。
我们在两种知识驱动NLP任务上进行我们的实验:实体分类和关系分类。实验结果表名,ERNIE充分利用了词汇、语义和知识信息,显著超越了BERT在知识驱动模型上的表现。我们也评估了ERNIE在其它常见NLP任务上的效果,ERNIE也取得了可比较的结果。
2 相关工作
为了从文本中捕获语言信息并将这些信息用于特定的NLP任务,人们致力于语言表征模型的预训练。这些预训练方法可以分为两类:基于特征的方法和微调方法。
早期的工作关注如何使用基于特征的方法将词转换为分布表征。由于这些预训练词表征捕获了语料库中的句法和语义信息,它们常常被用于多种NLP模型的输入或初始化参数,相较于随机初始化参数效果更好。由于模型无法分辨一词多义,因此Peters等人采用句级模型(ELMo)捕获不同上下文中复杂的词特征,并使用ELMo生成上下文敏感的词嵌入。
与上文提及的基于特征的语言方法仅使用预训练语言表征作为输入特征不同,Dai和Le在未标注文本上训练了自编码器,然后使用预训练模型结构和参数作为其它特定NLP任务的起点。受Dai和Le的启发,更多使用微调的预训练表征模型被提出。Devlin等人提出了一种含有多层Transformer的深度双向模型BERT,该模型目前在多个NLP任务上获得最好的效果(注:截至本文发布)
虽然基于特征和微调的语言模型取得了巨大的成功,但是它们忽视了语言模型与知识信息间的关系。正如最近的研究表明,注入额外的知识信息可以显著地增强原始模型,如阅读理解、机器翻译、自然语言推理、知识获取和对话系统。因此,我们认为外部知识信息可以有效地提升现有预训练模型。事实上,一些工作尝试联合词和实体的表征学习来有效地利用外部KG,并取得了不错的效果。Sun等人提出了基于mask语言模型的知识mask策略,通过知识提示语言表征。本文中,我们基于BERT,利用语料库和KG训练了一个增强语言表征模型。
3 方法
本节,我们展示了ERNIE的整体框架以及实现细节。3.2节介绍模型框架,3.4节介绍为了编码信息实体和融合异构信息而设计的新颖预训练任务,3.5节介绍了微调过程的细节。
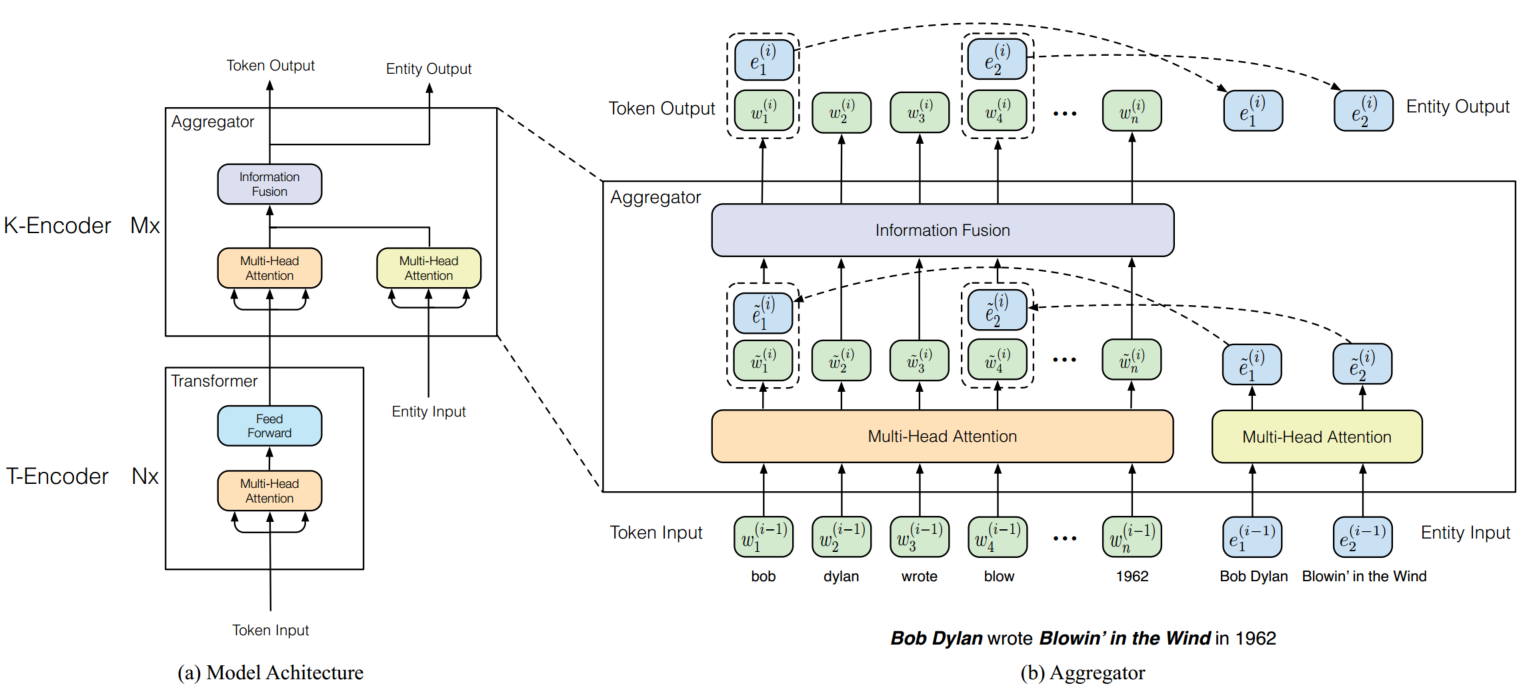
图2 左边是ERNIE的架构。右边是用于将输入的token和实体相互整合的聚合器。信息融合层有两种输入:一种是token嵌入,另一种是token嵌入和实体嵌入的连接。信息融合层为下一层输出新的token嵌入和实体嵌入。
3.1 符号
我们用  代表输入token(注:在本文中,token是字符级的),n是序列长度。与此同时,我们用表示实体对齐序列,m是序列长度。注意,在大部分情况下m和n都不一致,并且不是每个token都能对齐到KG中的实体。此外,我们用表示词典中所有的token,用表示KG中的实体。如果一个token有对应的实体,它们之间的对齐关系被描述为。本文中,我们将实体与对应的命名短语的第一个token对齐,如图2所示。
代表输入token(注:在本文中,token是字符级的),n是序列长度。与此同时,我们用表示实体对齐序列,m是序列长度。注意,在大部分情况下m和n都不一致,并且不是每个token都能对齐到KG中的实体。此外,我们用表示词典中所有的token,用表示KG中的实体。如果一个token有对应的实体,它们之间的对齐关系被描述为。本文中,我们将实体与对应的命名短语的第一个token对齐,如图2所示。
3.2 模型架构
如图2所示,整个ERNIE的模型架构有两个堆叠模块组成:1)下层的文本编码器(T-Encoder)负责从输入的token中捕获词汇和语义信息,2)上层的知识编码器(K-Encoder)负责将外部token导向的知识信息整合进下层输出的文本信息中,这样就可以将token 和实体的异构信息表征到统一的特征空间中。此外我们用N表示T-Ecoder的层数,用M表示K-Encoder的层数。
具体来说,给定一个序列 和其对应的实体序列,文本编码器先对每个token的token嵌入、段嵌入、位置嵌入求和,获得输入嵌入。接下来通过下式计算词汇和语义特征(加粗):
和其对应的实体序列,文本编码器先对每个token的token嵌入、段嵌入、位置嵌入求和,获得输入嵌入。接下来通过下式计算词汇和语义特征(加粗):
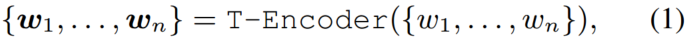
T-Encoder是一个多层的双向Transformer。T-Encoder和其在BERT中的实现完全相同,所以这里省略了其详细描述。
计算 之后,ERNIE使用知识编码器K-Encoder将知识信息注入到语言表征中。详细来说,我们先用实体嵌入(加粗)来表示,实体嵌入由高效的知识嵌入模型TransE预训练。然后,和都被丢给K-Encoder进行异构信息融合并计算最终的输出嵌入,
之后,ERNIE使用知识编码器K-Encoder将知识信息注入到语言表征中。详细来说,我们先用实体嵌入(加粗)来表示,实体嵌入由高效的知识嵌入模型TransE预训练。然后,和都被丢给K-Encoder进行异构信息融合并计算最终的输出嵌入,
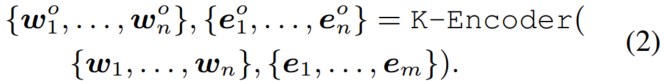
 和将作为特定任务的特征。3.3节将详细介绍知识编码器。
和将作为特定任务的特征。3.3节将详细介绍知识编码器。
3.3 知识编码器
如图2所示,知识编码器K-Encoder由堆叠聚合器组成,其不仅可以编码token和实体,也能融合异构特征。在第i个聚合器,由前一个聚合器输入的token嵌入 和实体嵌入被分别扔进多头自注意力中,
和实体嵌入被分别扔进多头自注意力中,
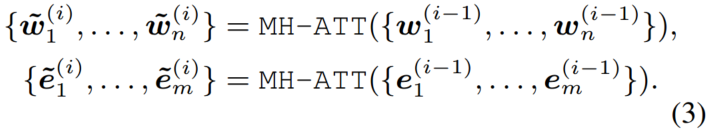
然后,第i个聚合器使用信息融合层实现token和实体序列的相互整合,并且计算每个token和实体的输出嵌入。对于token 和其对齐的实体,信息融合的过程如下:
和其对齐的实体,信息融合的过程如下:
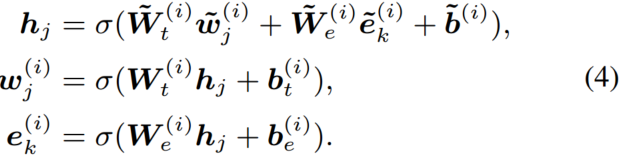
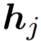 是整合token和实体后的内部隐层状态。是非线性函数,一般选择GELU。对于没有对应实体的token,信息融合层直接计算输出嵌入,
是整合token和实体后的内部隐层状态。是非线性函数,一般选择GELU。对于没有对应实体的token,信息融合层直接计算输出嵌入,
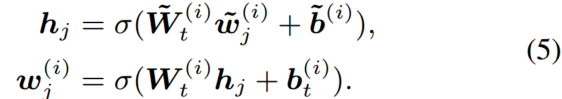
为了简化,第i层的聚合器操作由以下公式表示,
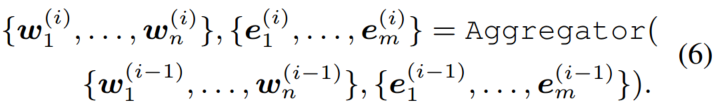
最上层聚合器计算的token和实体输出嵌入作为K-Encoder最终输出嵌入。
3.4 为注入知识而预训练
为了通过信息实体将知识注入语言表征,我们提出了新的预训练模型ERNIE,其随机mask一些token和实体对齐对,然后要求系统基于对齐的token预测对应的实体。既然我们的任务类似于训练去噪自编码器,我们将此过程称为去噪实体自编码器(dEA)。考虑到 对于softmax层来说太大了,因此我们仅要求系统基于给定的实体序列进行预测,而不是基于整个KG。给定token序列和对应的实体序列,我们将的对齐实体分布表示为,
对于softmax层来说太大了,因此我们仅要求系统基于给定的实体序列进行预测,而不是基于整个KG。给定token序列和对应的实体序列,我们将的对齐实体分布表示为,
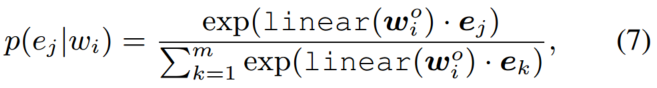
公式7用来计算dEA的交叉熵损失函数。
考虑到token-实体对中会存在一些错误,我们针对dEA进行以下操作:1)有5%的几率,我们将token-实体对中的实体换成其它任意实体,让模型可以分辨出token对齐到了错误的实体上;2)有15%的几率,我们mask某个token-实体对,训练模型能够发现实体对齐系统没有抽取所有存在的token-实体对;3)其余情况,我们让token-实体对保持不变,让模型将实体信息整合进token表征来获得更好的语言理解。
类似BERT,ERNIE也采用了掩码语言模型(MLM)以及预测下一句(NSP)作为预训练任务,让ERNIE可以捕获词汇和语义信息。预训练的总损失包括dEA、MLM和NSP损失(注:相较于BERT增加了dEA)。
3.5 对特定任务进行微调
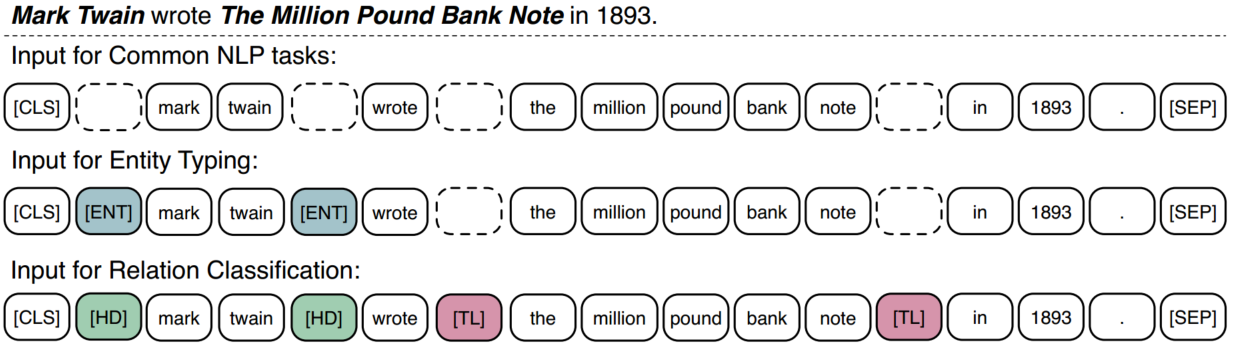
图3 对于特定任务调整输入序列。为了在不同类型的输入间对齐标记,我们使用虚线方框作为占位符。彩色的方框表示特定标记token。
如图3所示,对于不同的NLP任务,ERNIE采用了不同的微调方法。我们将第一个token作为区分任务的标记。对于一些知识驱动任务,我们设计了特殊的微调方法:
关系分类任务要求系统基于上下文对给予的实体对的关系标签进行分类。最直接的方法是将池化层用于给定实体引用的最终输出嵌入,并将用于分类的引用嵌入连接作为给定实体对的表示。在本文中,我们设计了另一种方法,通过添加两个mark tokens突出实体引用来调整输入token序列。这些额外的mark token同传统关系分类模型的位置嵌入扮演同样的角色。然后,我们也使用CLS标记表明是一个分类任务。注意我们使用HD和TL分别表示实体的头和尾。
实体分类任务的微调是关系分类任务微调的简单版本。之前的分类模型充分利用了上下文嵌入和实体引用嵌入,我们认为修改后的序列加上引用标记ENT可以让ERNIE注意结合上下文信息和实体引用信息。
4 实验
本节,我们将展示ERNIE在五个NLP数据库上预训练和微调的细节,这五个数据库包括知识驱动任务和传统NLP任务。
4.1 数据库预训练
预训练过程与现有文献记载的预训练语言模型方法一致。从零开始训练ERNIE代价太高,我们采用Google训练的BERT参数来初始化用于编码token的Transformer模块。因为预训练是由NSP,MLM和dEA多任务组成的,我们使用英文维基百科作为我们的预训练语料库并且将文本和Wiki-data对齐。在将语料库转换为用于预训练的格式化数据后,注释后的输入有接近45亿的子单词和1.4亿的实体,并且抛弃了实体数小于3的句子。
预训练ERNIE之前,我们采用通过TransE在Wikidata上训练的知识嵌入作为实体的输入嵌入。具体来说,我们从Wikidata中采样,其包括5040986个实体和24267796个事实三元组。在训练中固定实体嵌入,并随机初始化实体编码模块的参数。
5 总结
本文中,我们提出ERNIE将知识信息整合进语言表征模型。相应的,我们提出知识聚合器和预训练任务dEA将文本和KG中的异构信息融合。实验结果表明ERNIE相较于BERT在远程监控数据去噪和有限数据微调上有更好的能力。未来的研究方向有三个:1)将知识注入ELMo等基于特征的预训练模型;2)在不同于世界知识库Wikidata的ConceptNet数据库中加入多样的结构化知识;3)对真实语料库进行启发式标注,建立更大的预训练数据。这样可能会获得更全面和有效的语言理解。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167346.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
