大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
图像分割算法总结
1.评价指标:
普通指标:
Pixel Accuracy(PA,像素精度):标记正确的像素点占所有像素点的比例。混淆矩阵中=\(\frac{{\rm{对角线}}}{总和}\)
Mean Pixel Accuracy(MPA 均像素精度):计算每个类内被正确分类像素数的比例,再求所有类的平均。混淆矩阵中=\(\frac{{\rm{对角线值}}}{对角线所在的每行和}\)
mean IU(MIoU 均交并比):按类别平均的交并比,计算真实值和预测值的交集和并集。混淆矩阵中=\(\frac{{\rm{对角线值}}}{对角线所在的行和+列和-对角线值}\)
这些指标在程序中通过混淆矩阵进行计算。
用于医学:
Rand error(兰德指数):两个数据聚类的相似性评价方法,改造之后用来衡量分割性能。给定一张图片,有n个像素点,同时有两个分割X和Y(实际和预测)。a: 两个分割同属于一个聚类的像素点数量; b:两个分割中都不属于一个聚类的像素点数量。RE=1-RI
Rand指数:RI用来衡量相似度,越高越好。和误差相反。$$RI = \frac{{a + b}}{{C_n^2}}$$
Warping error: 主要用来衡量分割目标的拓扑形状效果,给定候选标注T(预测值)和参考标注L(实际值)的warping error可以认为是L对于T最好的汉明距离。
用于实时分割:
ms: 毫秒数
fps:画面每秒传输帧数,通俗来讲就是指动画或视频的画面数
FLOPs:每秒执行的浮点数运算次数
FLOPS:全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,可以理解为计算速度,是一个衡量硬件GPU性能的指标
GFLOPS:1GFLOPS=\(10^9\)FLOPs(10亿次)
Parameters:模型参数
Model size:模型大小
2.先验知识
-
语义分割常用特征提取框架:
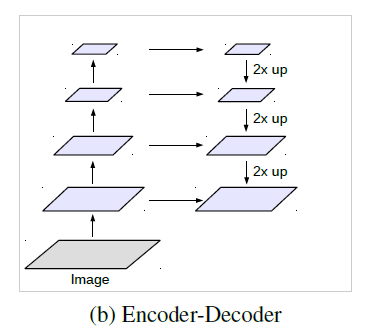
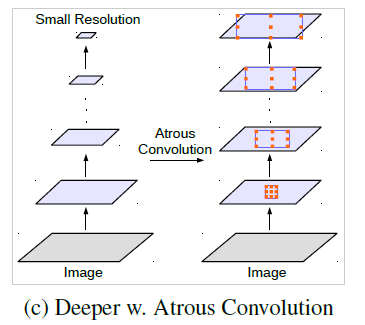
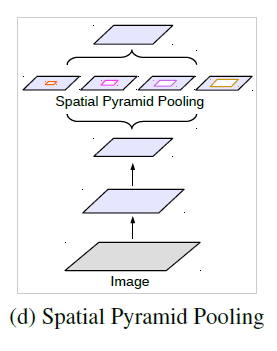
图像金字塔 编解码结构 深度网络vs空洞卷积 空间金字塔结构 从输入图像入手,将不同尺度的图像分别送入网络进行特征提取,后期再融合。 编码器部分利用下采样进行特征提取,解码器部分利用上采样还原特征图尺寸。 经典分类算法利用连续下采样提取特征,而空洞卷积是利用不同的采样率。 除ASPP外,仍有其他网络使用了该思想,如SPPNet、PSPNet等。 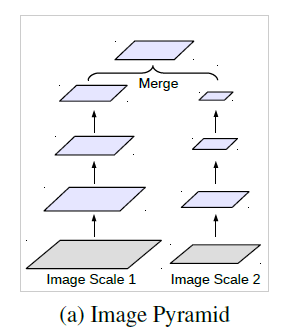

2.注意力机制的作用
注意力机制是把注意力集中在重要的点上,而忽略其他不重要的因素。其中重要程度的判断取决于应用场景,具备注意力机制的神经网络可更好的进行自主学习。核心目标即从众多信息中选择对当前任务目标更关键的信息。
注意力机制包含两个步骤:
1)注意力机制需要先决定整段输入的哪个部分需要更加关注
2)从关键的部分进行特征提取,得到重要信息。
按照注意力的关注域,可分为:空间域,通道域,层域,混合域,时间域。注意力机制可以帮助模型为输入图片的各个部分分配不同的权重,提取更关键、更重要的信息,使模型做出更准确的判断,同时不会给模型的计算和存储带来更多消耗。
3.实时分割算法常用思想
实时分割要在保证分割准确性不会过低的前提下, 尽可能减少参数,压缩模型,因此实时网络对硬件设备的要求不高且省时。
实时分割算法常用思想有:
1)替换主网络: ResNet101或ResNet50替换为ResNet34或ResNet18
2)减少通道数:避免出现2048,1024等过多的通道数
3)减少卷积层
4)将卷积层替换为组卷积或其他能减少计算量的卷积操作
5)增加前期数据处理
6)减少复杂融合方式
7)避免使用全连接
4.样本不平衡
指在训练的时候各个类别的样本数量不均衡,由于检测算法各不相同,以及数据集之间的差异,可能会存在正负样本、难易样本、类别间样本这3种不均衡问题。一般在目标检测任务框架中,保持正负样本的比例为1:3(经验值)。
-
正样本:标签区域内的图像区域,即目标图像块
-
负样本:标签区域以外的图像区域,即图像背景区域
-
易分正样本:容易正确分类的正样本,在实际训练过程中,该类占总体样本的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数
-
易分负样本:容易正确分类的负样本,在实际训练过程中,该类占的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数
-
难分正样本:错分成负样本的正样本,这部分样本在训练过程中单个样本的损失函数较高,但是该类占总体样本的比例较小
-
难分负样本:错分成正样本的负样本,这部分样本在训练过程中单个样本的损失函数教高,但是该类占总体样本的比例教小
1.正负样本不均衡
以Faster RCNN为例,在RPN部分会生成20000个左右的Anchor,由于一张图中通常有10个左右的物体,导致可能只有100个左右的Anchor会是正样本,正负样本比例约为1∶200,存在严重的不均衡。
对于目标检测算法,主要需要关注的是对应着真实物体的正样本,在训练时会根据其loss来调整网络参数。相比之下,负样本对应着图像的背景,如果有大量的负样本参与训练,则会淹没正样本的损失,从而降低网络收敛的效率与检测精度。
2.难易样本不均衡
难样本指的是分类不太明确的边框,处在前景与背景的过渡区域上,在网络训练中难样本损失会较大,也是我们希望模型去学习优化的样本,利用这部分训练可以提升检测的准确率。
然而,大量的样本并非处在前景与背景的过渡区,而是与真实物体没有重叠区域的负样本,或者与真实物体重叠程度很高的正样本,这部分被称为简单样本,单个损失会较小,对参数收敛的作用有限。
虽然简单样本单个损失小,但由于数量众多,因此如果全都计算损失的话,其损失也会比难样本大很多,这种难易样本的不均衡也会影响模型的收敛与精度。
值得注意的是,由于负样本中大量的是简单样本,导致难易样本与正负样本这两个不均衡问题有一定的重叠,解决方法往往能同时对这两个问题起作用。
3.类别间样本不均衡
在有些目标检测的数据集中,还会存在类别间的不均衡问题。举个例子,数据集中有100万个车辆、1000个行人的实例标签,样本比例为1000∶1,属于典型的类别不均衡。
这种情况下,如果不做任何处理,使用该数据集进行训练,由于行人这一类别可参考标签太少,会使得模型主要关注车这一类别的检测,网络中的参数主要根据车辆的损失进行优化,导致行人的检测精度大大下降。
目前,解决样本不均衡问题的一些思路:
机器学习中,解决样本不均衡问题主要有2种思路:数据角度和算法角度。从数据角度出发,有扩大数据集、数据类别均衡采样等方法。在算法层面,目标检测方法使用的方法主要有:
-
Faster RCNN、SSD等算法在正负样本的筛选时,根据样本与真实物体的IoU大小,设置了3∶1的正负样本比例,这一点缓解了正负样本的不均衡,同时也对难易样本不均衡起到了作用。
-
Faster RCNN在RPN模块中,通过前景得分排序筛选出了2000个左右的候选框,这也会将大量的负样本与简单样本过滤掉,缓解了前两个不均衡问题。
-
权重惩罚:对于难易样本与类别间的不均衡,可以增大难样本与少类别的损失权重,从而增大模型对这些样本的惩罚,缓解不均衡问题。
-
数据增强:从数据侧入手,可以在当前数据集上使用随机生成和添加扰动的方法,也可以利用网络爬虫数据等增加数据集的丰富性,从而缓解难易样本和类别间样本等不均衡问题,可以参考SSD的数据增强方法。
5.简述实时语义分割模型的加速方法
1)通过裁剪或resize来限定输入的图片大小,以降低计算复杂度。尽管这种方法简单有效,但空间细节的损失,尤其是边界部分,会导致算法精度下降
2)通过减少网络通道数量加快处理速度,尤其是在骨干模型的早期阶段,但会弱化空间信息
3)为追求极其紧凑的框架而丢掉模型最后阶段(比如ENet),该方法的缺点也很明显,由于ENet抛弃了最后阶段的下采样,模型的感受野不足以涵盖大物体,导致判别能力较差。
4)为弥补空间细节的丢失,很多人采用U型结构,但U型结构在高分辨率特征图上引入额外的计算,会降低模型速度;丢失掉的空间信息无法通过引入浅层修复,因此性价比不高。
6.RGB-D分割算法中的融合方式主要分为:
早期融合,中期融合,后期融合。早期融合
早期融合&浅层中期融合的优点:低层RGB-D特征能很好的保留空间线索
缺点:RGB图像中的视觉信息和深度图像中的几何信息在低层没有得到校正,融合后得到的特征信息较少
后期融合&深层中期融合优点:融合了表示语义信息的高级特征,在不同模式下得到的效果更见兼容
缺点:RGB和深度图像高级特征中的互补空间线索在执行池化后已经被削弱
-
3.算法
| 算法 | 创新点 | 各种网络结构框图 |
|---|---|---|
| FCN | 1. 第一个实现端到端,像素到像素的语义分割网络 2. 将当前分类网络最后全连接层改编成全卷积网络并进行微调,实现稠密预测 3. 设计跳跃连接将全局信息和局部信息连接起来相互补偿 4. 设计shift-and-stich,但是最后没用,因为上采样效果已经很好了。 5. FCN中用反卷积进行上采样,之前都是用插值。 6. backbone: AlexNet, VGG, GooLeNet |
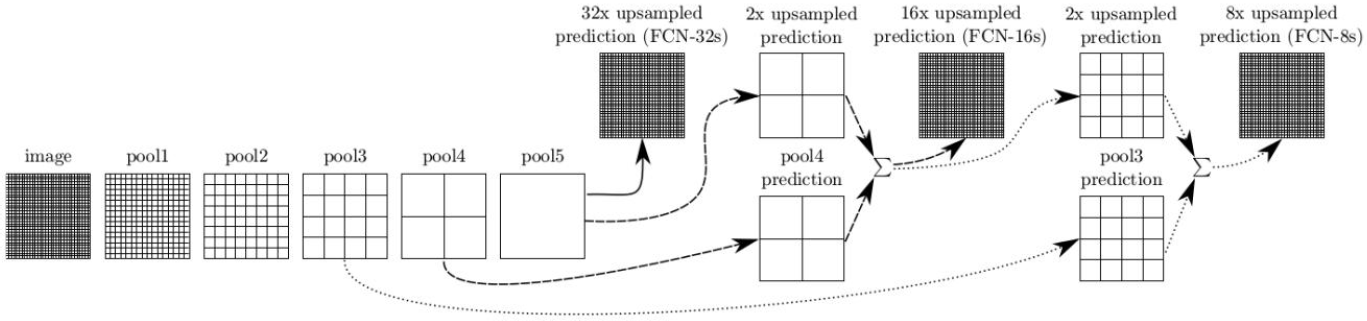 |
| U-Net | 1. 设计了一个完全对称的U型结构。一个收缩路径来获取全局信息,一个对称的扩张路径以精确定位。 2. 采用了镜像输入图片边界的方式补全缺失内容。 3. 设计了加权损失函数,对接触的细胞在loss损失函数中给予较大的权重 4. 因为用来训练的图片非常少,所以对可用的训练图像应用弹性变形来扩充数据,这也可以让网络学到这种变形不变性 5. backbone:自定义 |
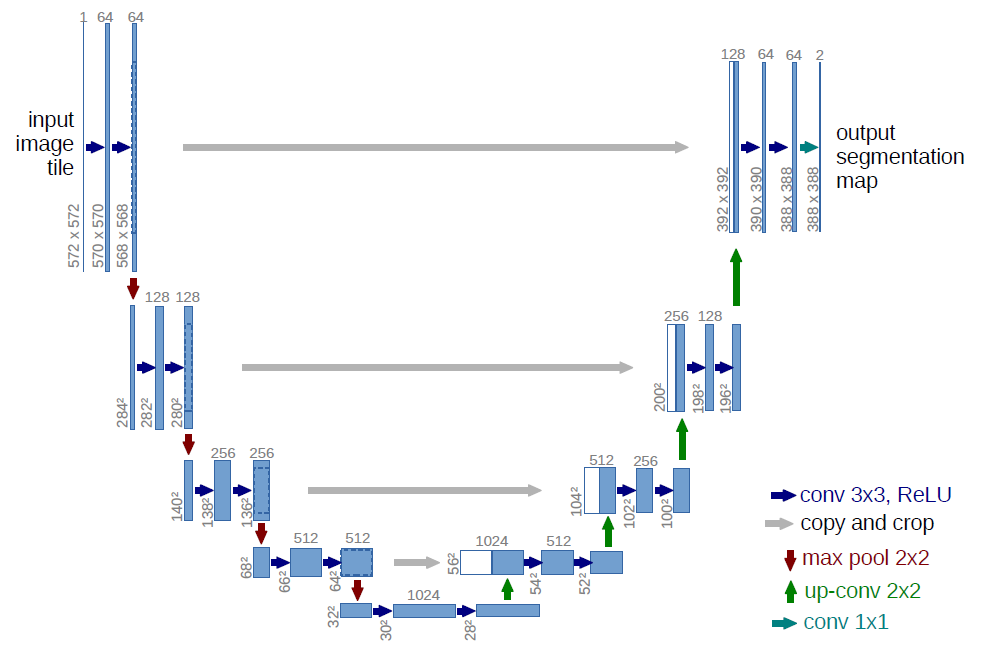 |
| FusionNet | 1.对U-Net的改进引入基于求和的跳跃连接,允许更深入的网络结构以实现更精确的分割 2.每个上采样出来的特征图还和降采样的时相同尺寸的特征图进行skip连接。 3.每个残差块都有两个卷积块 这有两个好处: 1)这些卷积块作为输入特征图和残差块之间的桥梁,因为之前层特征图的数量可能和残差块特征图的数量不一样。2)还有一个作用是保证网络的对称性。 4.程序里关于图片尺寸剪切的部分可以学习。 5. backbone:自定义 |
 |
| DeconvNet | 1. 提出FCN的几个缺点: 1)网络的感受野尺寸是预先固定。因此,对于输入图片中比感受野大或者小的物体可能会被忽略。即对于较大的物体,只有局部的细节信息能够被正确标记,或者标记的结果是不连续的,而对于小物体会被忽略。由于分割的边界细节和语义信息之间的权衡,通过跳跃结构来改善效果这一做法也无法从根本上解决问题。 2)由于,卷积后送入反卷积层的feature map十分稀疏,而且,反卷积的过程又十分的粗糙,输入图片中的结构细节信息会有所损失。 2. 用反池化+反卷积+ReLU作为解码器 3. 论文写作格式非常好 摘抄:1)池化定义:Pooling in convolution network is designed to filter noisy activations in a lower layer by abstracting activations in a receptive field with a single representative value. Although it helps classification by retaining only robust activations in upper layers, spatial information within a receptive field is lost during pooling, which may be critical for precise localization that is required for semantic segmentation. 2) The unpooling records the locations of maximum activations selected during pooling operation in switch variables, which are employed to place each activation back to its original pooled location. But it produce sparse activation map. 3). The deconvolution layers densify the sparse activation obtained by unpooling through convolution-like operations with multiple learned filters. Deconvolutional layers associate a single input activation with multiple outputs. The deconvolutional layers correspond to bases to reconstruct shape of an input object. Therefore, a hierarchical structure of deconvolutional layers are used to capture different level of shape details. 4)Unpooling captures example-specific structures by tracing the original locations with strong activations back to image space, it reconstructs the detailed structure of an object in finer resolutions. On the other hand , learned filters in deconvolutional layers tend to capture class-specific shapes, the activations closely related to the target classes are amplified while noisy activations from other regions are suppressed effectively. 4. backbone:VGG |
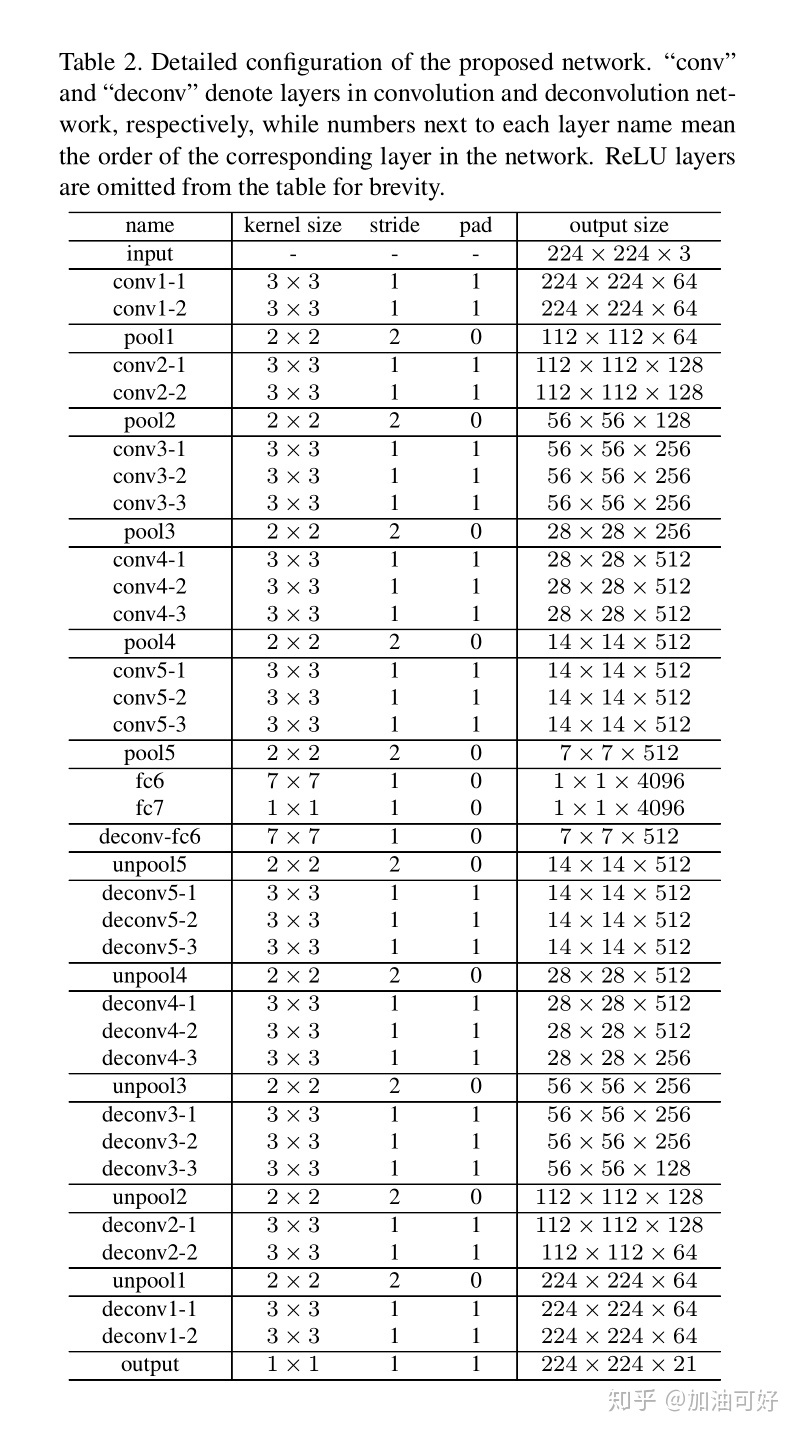 |
| SegNet | 1.提出了SegNet网络,其核心的训练引擎包括一个encoder网络,和一个对称的decoder网络,即编码器-解码器框架,并跟随一个用于Pixel-wise的分类层。 2.用反池化做上采样方式 3.设计了大量的实验可以借鉴 4. backbone:VGG |
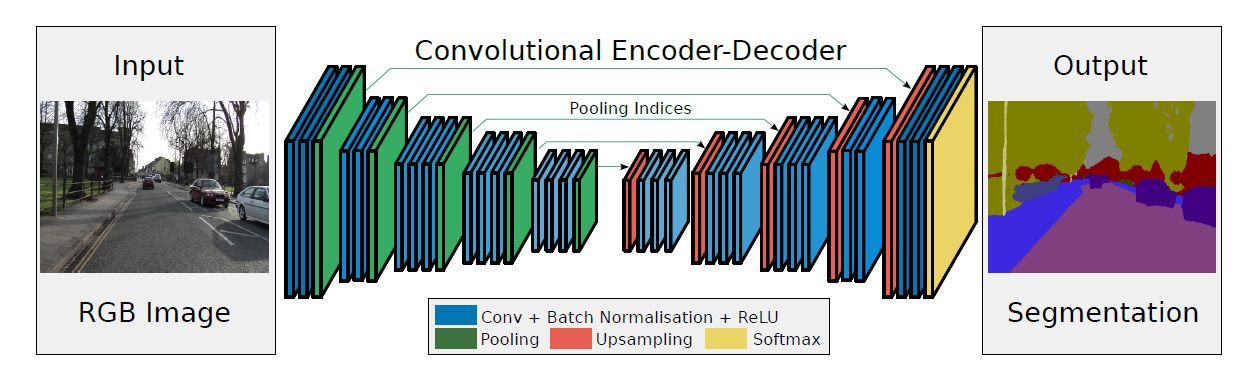 |
| DeepLab v1 | 1)背景:语义分割中连续的池化或下采样会导致图像的分辨率大幅度下降,从而损失原始信息,且在上采样过程中难以恢复。现在越来越多的网络都在试图减少分辨率的损失,比如使用空洞卷积,或者用步长为2的卷积代替池化。本文说明DCNN网络的最后一层并不能准确的用来目标分割,这是因为平移不变性使得DCNN擅长高层次理解,但会损害低层次任务,如姿态估计,语义分割,这些任务中需要精准的定位,而不是抽象高级特征。 2)DeepLab引入了多尺度特征。通过设置不同参数的卷积层或池化层,提取到不同尺度的特征图。将这些特征图送入网络做融合,对于整个网络性能的提升很大。但是由于图像金字塔的多尺度输入,造成计算时保存了大量的梯度,从而导致对硬件的要求很高。多数论文是将网络进行多尺度训练,在测试阶段进行多尺度融合。如果网络遇到了瓶颈,可以考虑引入多尺度信息,有助于提高网络性能。 3)参数同比减少,所以占比内存减小,速度快。 4)结合了深度卷积神经网络和概率图模型的方法,克服了深度网络的局部化特性。 深度卷积神经网络是采样FCN的思想,修改VGG16网络,得到粗略映射图并插值到原图大小。 概率图模型(DenseCRFs):借用fully connected CRF对从DCNN得到的分割结果进行细节上的refine. 5) 把全连接层(fc6、fc7、fc8)改成卷积层(端到端训练),把最后两个池化层(pool4、pool5)的步长2改为1,保证feature的分辨率。 6) 把最后三个卷积层(conv5_1、conv5_2、conv5_3)的dilate rate设置为2, 且第一个00全连接层的dilate rate设置为4(保持感受野)。 7) 把最后一个全连接层fc8的通道数从1000改为21(分类数为21) 8) 第一个全连接层fc6.通道数从4096变为1024,卷积核大小从7×7变为3×3,后续实验中发现此处的dilate rate为12时效果最好。 9)backbone: vgg16 |
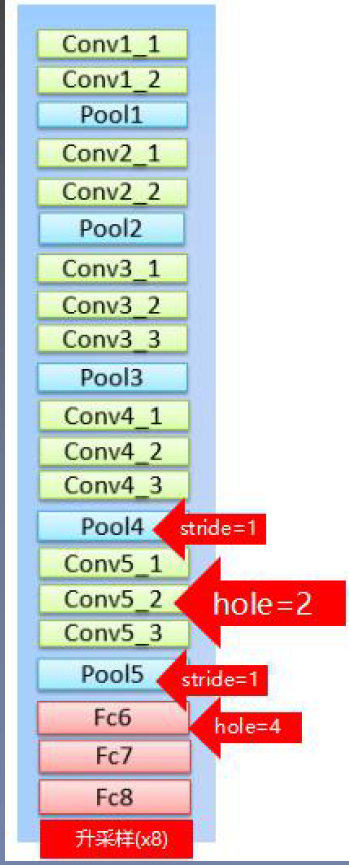 |
| DeepLab v2 | 1)介绍了DCNN应用到语义分割的挑战:减小特征图分辨率;目标存在多尺度;因为DCNN的不变性减少了分割精度。 1) 针对分辨率过低的特征图,文章通过修改最后几个池化操作,避免特征图分辨率损失过大,通过引入空洞卷积,在没有增加参数与计算量的情况下增大了感受野(基本同理v1)。 2)需要分割的目标具有多样的尺度大小。针对这个问题,文章参考了SPP的思想,使用了不同比例的膨胀卷积构造“空间金字塔结构”——ASPP。ASPP增强了网络在多尺度下多类别分割时的鲁棒性,使用不同的采样比例与感受野提取输入特征,能在多个尺度上捕获目标与上下文信息。 3)DCNN网络对目标边界的分割准确度不高,文章引入CRF使得分割边界的定位更加准确,从而解决该问题。 4) backbone: vgg16 |
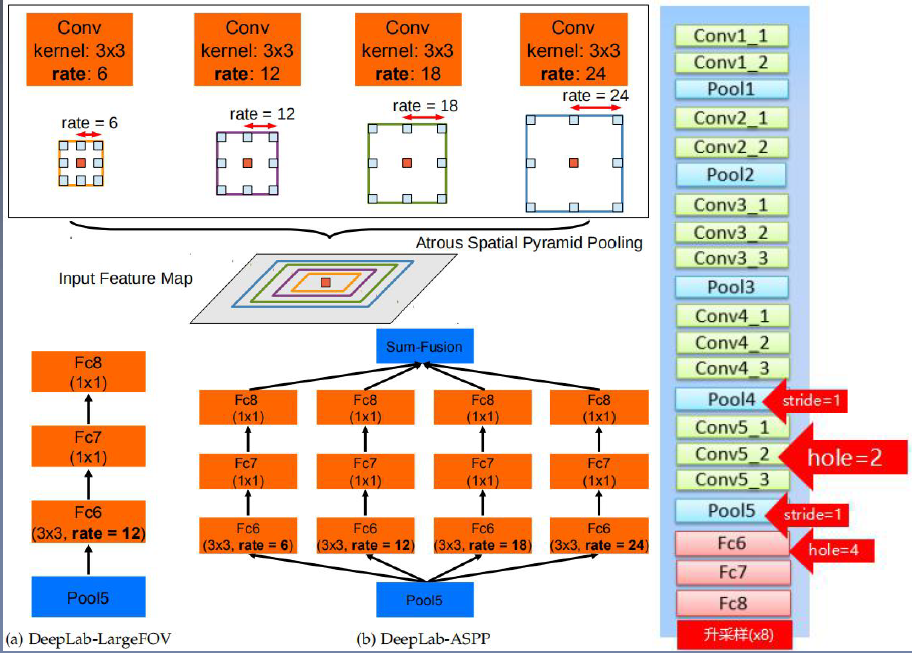 |
| DeepLab v3 | 1) 本文重新讨论了空洞卷积的使用,在串行模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息。 2)改进了ASPP模块,由于不同采样率的空洞卷积核BN层组成,采用了串行和并行的方式布局模块。 3)讨论了一个重要问题:使用大采样率的3×3的空洞卷积,因为图像边界响应无法捕捉远距离信息(小目标),会退化为1×1的卷积,因此将图像级特征融合到ASPP模块中。 4)backbone:ResNet |
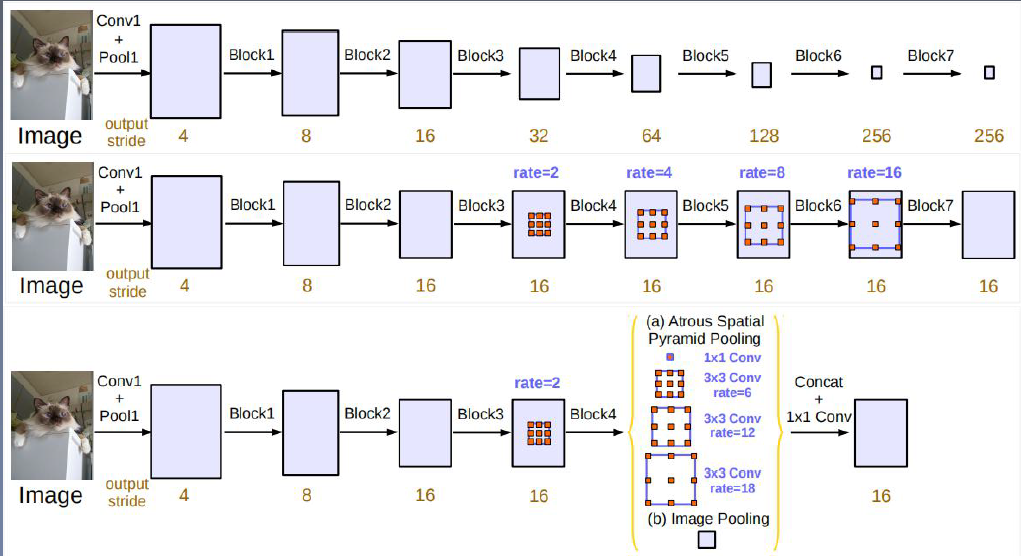 |
| DeepLab v3+ | 1) 提出了一种编码器-解码器结构,采样DeepLab v3作为encoder,输入与输出尺寸之比为16,ASPP:一个1×1卷积+三个3×3卷积(rate=[6,12,18])+全局平均池化。 2)添加decoder得到新的模型。取消了CRF后处理。先把encoder的结果上采样4倍,然后与编码器中相对应尺寸的特征图进行拼接融合,再进行3×3的卷积,最后上采样4倍(通过双线性插值)得到最终结果。 3)融合低层次信息前,先进行1×1的卷积,目的是降低通道数。 4)将Xception模型应用于分割任务,模型中广泛使用深度可分离卷积。 5)backbone: ResNet, Xception |
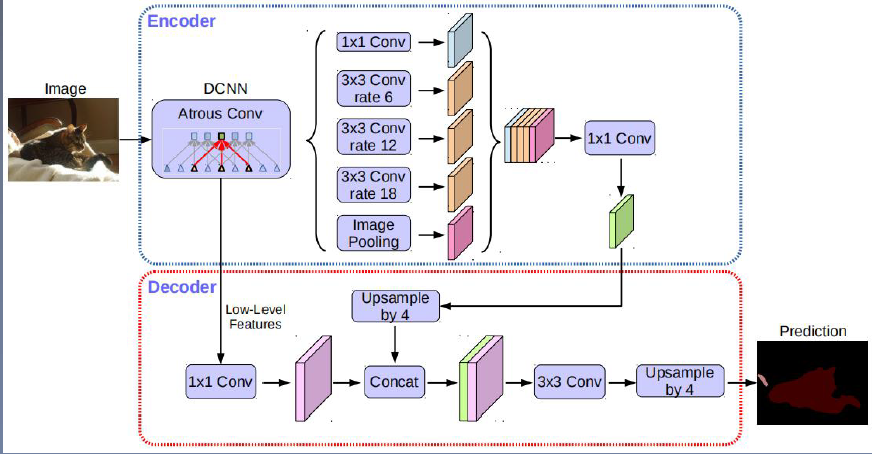 |
| GCN | 1)证明大卷积核的有效性:之前文章多用小卷积核,优点是参数量少,计算量少;并且整合三个非线性激活层代替单一非线性激活层,增加模型判别能力。缺点是感受野不足,深度堆叠卷积容易出现不可控的因素。大卷积核感受野范围大,但是参数量多,计算量大。本文为了减少计算量,用了不对称卷积。 2)卷积方式汇总:1.普通正方形标准卷积 2. 空洞卷积——为了让固定大小的卷积核看到更大范围的区域,用空洞卷积代替pooling下采样。 3.非对称卷积——将标准3×3卷积拆分成一个1×3卷积和3×1卷积,在不改变感受野大小的情况下减少计算量 4.组卷积,深度可分离卷积——组卷积是对输入特征图进行分组,每组分别进行卷积。 5.分组卷积对通道进行随机分组——为了达到特征之间的相互通信,使用channel shuffle。对组卷积之后的特征图进行重组,保证下面的卷积其输入来自不同的组,因此信息可以在不同组之间流转。 6.每组卷积用不同尺寸卷积核——同一层的特征图可以使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核要好。为了尽可能减少参数,一般先用1×1卷积将特征图映射到隐空间,再在隐空间做卷积。 7.通道间的特征分配不同权重——无论是在inception, denseNet, ShuffleNet里面,我们对所有通道产生的特征都是不分权重直接结合。用注意力机制的方法通过学习的方式来自动获取每个特征通道的重要程度,然后依据计算出来的重要程度去提升有用的特征并抑制对当前任务用处不大的特征。 8.可变形卷积——规则形状的卷积核可能会限制特征的提取,如果赋予卷积核形变的特性,让网络根据Label反传下来的误差自动的调整卷积核的形状,适应网络重点关注的感兴趣的区域,就可以提取更好的特征。例如网络会根据原始位置学习一个offset偏移量,得到新的卷积核,那么一些特殊情况就会成为这个更泛化的模型的特例。 3)卷积层连接方式: 1.使用skip connection,让模型更深 2. densely connection, 使每一层模型都融合其他层的特征输出(DenseNet) 4)表明语义分割的两个挑战:语义分割可以看成是一个逐像素分类任务,包括分类和定位两个挑战。这两个方面天生对立。对于分类任务,模型必须具有不变性,以适应目标的各种形式,如平移和倒转。对于定位任务,模型应该是对变换敏感的,即能够精确定位语义类别的每个像素。从上面两个方面出发,可以引申出设计网络的两个原则:第一,从定位的角度出发,应该采用全卷积的结构,去掉全连接层或全局池化层;第二,从分类的角度出发,应该采用较大的卷积核,使得像素与特征图的结合更加紧密,增强处理不同变换的能力。而且一旦卷积核过小,造成感受野过小,覆盖不了较大的目标,不利于分类。 5)模型结构:backbone为ResNet,使用FCN作为语义分割框架。使用了ResNet中不同stage的特征图,是多尺度架构。GCN模块用于产生低分变率的score map,并上采样与更高分辨率的score map相加产生新的score map。最后经过上采样,输出预测结果。 6)实验证明,GCN使用大卷积核不仅能提高分割准确性,设计的结构比堆叠小卷积核参数量更少。并且GCN主要是提高内部区域的精度,对边界区域的精度影响较小。 |
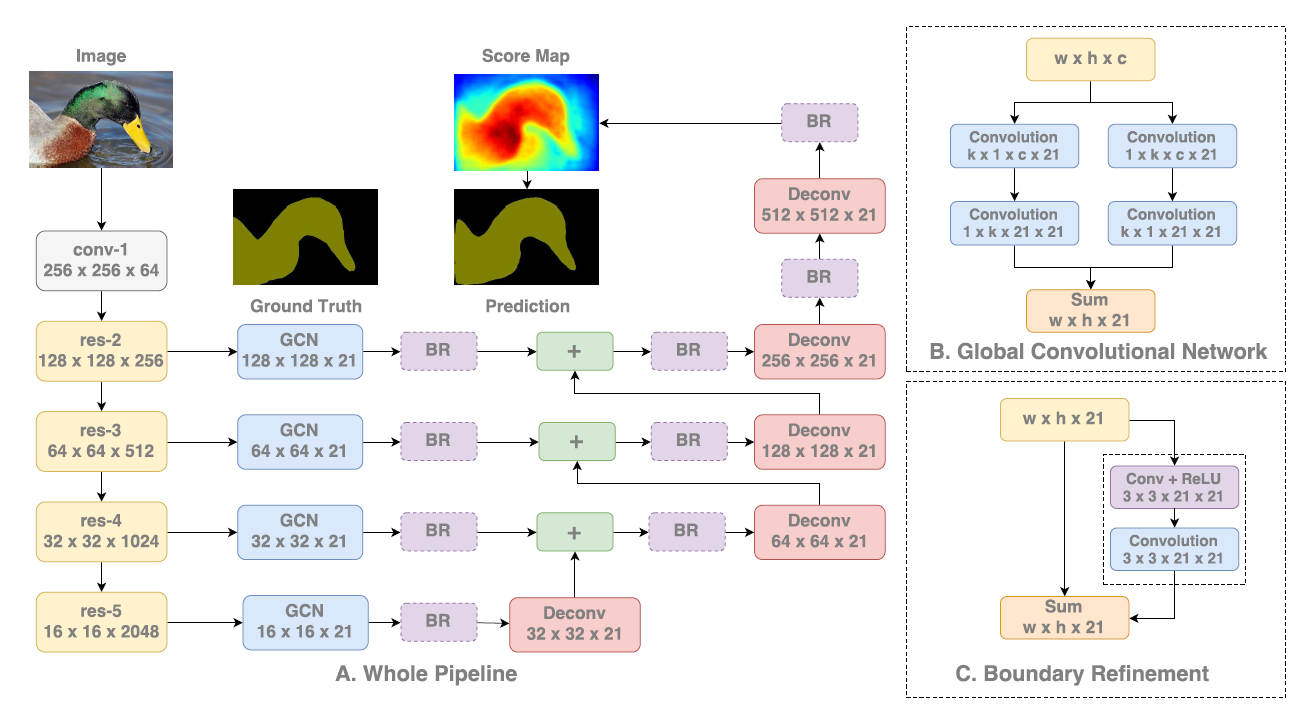 |
| ExFuse | 1) 现代语义分割框架通常使用特征融合的方式提升性能,但由于高级特征和低级特征之间存在差距,直接融合的效果并不好。本文在底层特征中引入语义信息,在高层特征中引入细节信息,使后续融合更有效。 2) 一般而言,低级特征和高级特征相辅相成。假定存在一个极端实例。“纯”低级特征只编码低级概念比如点、线或者边缘。直观的讲,高级特征与这些“纯”的低级特征的融合意义不大,因为后者噪声太多,无法提高高分辨率的语义信息。相反,如果低级特征包含更多的语义信息,比如,编码相对明确的语义框再做融合会简单不少——良好的分割结果可通多对齐高级特征图和低级特征中的语义框获得。相似的,“纯”高级特征的空间信息也很少,不能充分利用低级特征,但是,通过嵌入额外的高分辨特征,高级特征从而有机会通过对齐最近的低级语义框实现自我优化。 3)以ResNet50或ResNeXt101为主网络,延续GCN思想,另加入SS模块进行深度语义监督,SEB模块进行特征那个融合,DAP模块优化最终结果。 4)测试了GCN不同level融合时的表现,由于低级和高级特征之间的差距,直接进行特征融合会使结果很快达到饱和,即使增加融合数量也无法大幅度提升算法效果。 |
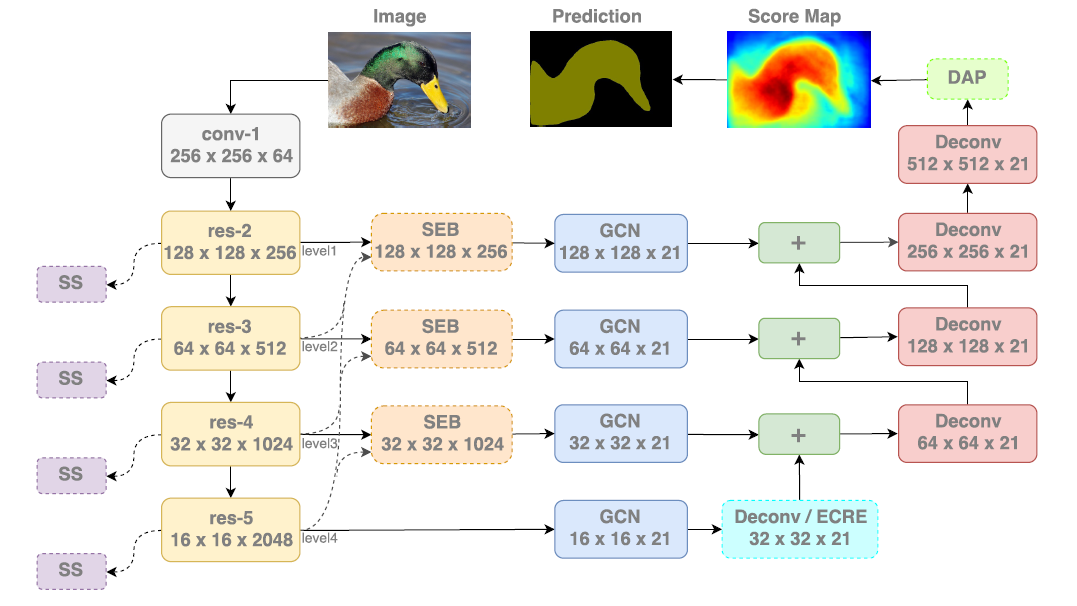 |
| DFN | 1)现代语义分割存在类内不一致和类间不一致的问题。因此DFN网络包括平滑网络和边界网络两部分。平滑网络解决类内不一致,通过引入注意力机制平均池化选择更具代表性的特征。边界网络通过深度语义边界监督更好的区分双边特征。 2)从FCN、PSPNet、RefineNet、GCN等网络学习到特征不具备类内与类间不一致的判别能力。 3)创新角度:从宏观的角度看待语义分割任务,以往的文章都是从微观角度看待语义分割,即对每个像素进行分类,这样就会造成类内与类间不一致。本文将一致的语义标签分配给事物的类别,而不是每个像素点。将每类像素作为一个整体,内在地考虑类内一致性和类间变化。因此这要求提取到的特征具有判别能力。 4) DFN有边界网络和平滑网络。 边界网络主要思想:利用多监督,使网络学习到的特征具有很强的类间不一致性,利用bottom-up,获取更多的语义信息。优点:该模块可以从低阶网络获得边界信息,从高阶网络获得语义信息,再融合,避免缺失某类信息的情况出现。高阶语义信息具有优化低阶边缘信息的作用。使用focal loss监督边界网络的输出。 平滑网络主要思想:不同尺度的感受野产生的特征具有不同程度的判别能力,导致结果不一致。用高阶信息的一致性指导低阶信息从而可以提升预测效果。现有方法大致可分为两种类型,一是“Backbone style”, 如PSPNet、DeepLab,将不同尺度的全局信息嵌入PSP模块或ASPP模块来提高网络的一致性(consistency);二是“Encoder-Decoder style”,如RefineNet、GCN,即利用不同阶段固有的多尺度语境,但缺乏具有强一致性的全局语境。 |
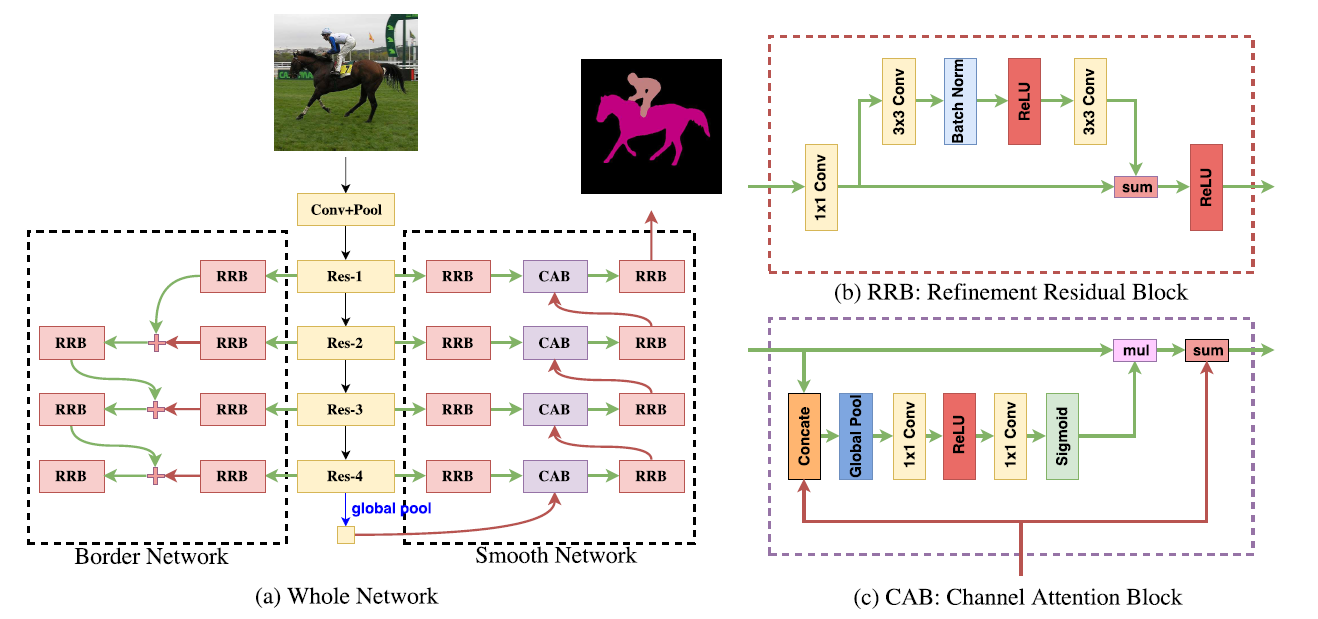 |
| ENet | 1)实时执行像素级语义分割的能力在移动应用程序中至关重要。最近的DCNN网络的缺点在于需要大量浮点运算,运行时间长,阻碍了语义分割的可用性。 2)提出ENet,专门针对需要低延迟操作的任务 3)ENet与现存模型相比,速度提升了18倍,FLOPs减少了75倍,参数减少了79倍,并能保证不错的准确度 4)ENet算法架构:初始化模块(a)并行执行步长为2的卷积和最大池化,完成对输入图片的下采样,可有效减少参数和计算量 bottleneck(b):以残差结构为主,可衍生出五种形态,每个卷积层后均接BN和PReLU。五种形态为:normal: 无maxpooling和Padding, conv为3×3卷积。 downsampling:有Maxpooling和Padding,第一个1×1卷积替换为步长为2的2×2卷积。dilated:为3×3卷积设置空洞率 asymmetric:将3×3卷积替换为1×5和5×1非对称卷积 upsampling:将maxpooling替换为unpool 5)feature map resolution:对图像的下采样有两个缺点:1.降低特征图分辨率会丢失细节信息,比如边界信息。 2.语义分割的输出与输入有着相同的分辨率,strong downsampling对应着strong upsampling,这增加了模型的大小和计算量。下采样的好处在于可以获取更大的感受野,获取更多的上下文信息,便于分类。针对问题1,有两个解决方案: 1)FCN的解决办法是将编码阶段的特征图与对应解码阶段相融合 2)SegNet的解决办法是将编码阶段的maxpooling indices保留到解码阶段做上采样使用 ENet采用的是SegNet的方法,可以减少内存需求,同时为了增加更好的上下文信息,使用dilated conv(空洞卷积)扩大感受域。 Early downsampling:早期处理高分辨率的输入会耗费大量计算资源,ENet的初始化模型会大大减少输入的大小。这是考虑到视觉信息在空间上是高度冗余的,可以压缩成更有效的表达方式。 Decoder size:相比于SegNet中encoder和decoder的镜像对称,ENet的encoder和decoder并不对称,而是由一个较大的encoder和一个较小的decoder组成,原因在于作者认为解码器的作用在于还原尺寸,对模型结果只起到了微调作用,不必耗费大量参数。 Nonlinear operations:一般在卷积层之前做ReLU和BN会提升效果,但是在ENet上使用ReLU却降低了精度,论文分析了ReLU没有起作用的原因是因为网络架构深度,在类似ResNet的模型上有上百层,而ENet层数很少,较少的层需要快速过滤信息,故最终使用PReLUs Information-preserving dimensionality changes Initial Block中,将Pooling操作和卷积操作并行,再concat到一起,这将推理阶段时间加速了倍。同时做下采样时,ENet使用2×2的卷积核,有效的改善了信息的流动和准确率 Factorizing filters:将nxn的卷积核拆成nx1和1xn,可以有效的减少参数量 Dilated convolutions:空洞卷积可以有效的提高感受野,有效的使用空洞卷积提高了4%的IoU,空洞卷积是交叉使用,而非连续使用. Regularization:因为数据集本身不大,很快会过拟合,使用L2效果不佳,最后选择Spatial Dropout,效果相对好一点。 |
 |
| LinkNet | 1)用于场景理解的像素级语义分割不仅需要准确度。还要保证高效性,才能应用在实时应用程序中。 2)现有算法虽然比较准确,但参数计算量比较庞大,速度很慢,本文提出的LinkNet无需增加大量参数量即可进行学习 3)本文最主要贡献是直接将编码器与解码器对应部分连接起来从而提高准确率,一定程度上减少了处理时间,通过这种方式可以保留编码部分中不同层丢失的信息,在进行重新学习丢失的信息时并未增加额外的参数与操作。 4)算法结构是:每个编码器(基于ResNet18)与解码器相连接,编码器的输出连接到对应解码器的输入,可更好的提升效率和精度。 |
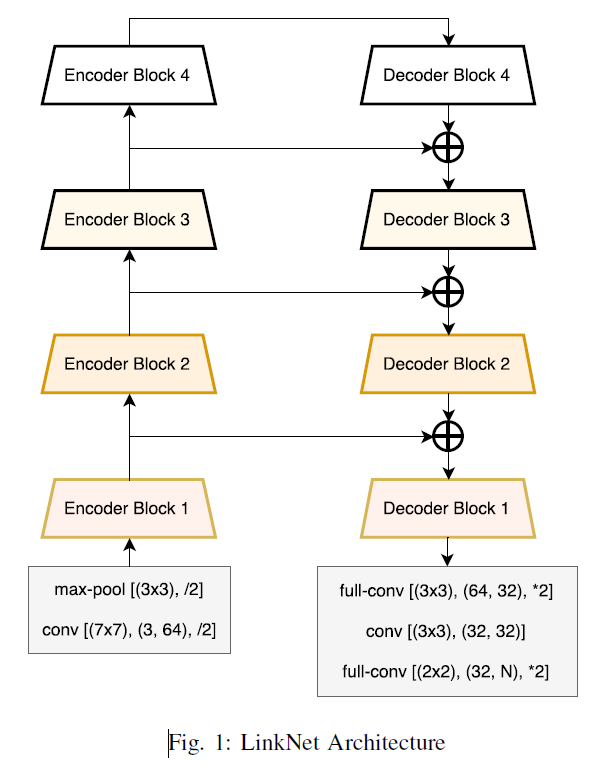 |
| BiSeNet | 为了追求更好更快,设计了两个路径,Spatial Path和Context Path,并行执行,分别满足语义分割的两个需求,并且研究了两个组件的融合,以及最后预测的优化,分别提出特征融合模块,和注意力优化模块。 算法包含三部分:空间分支、上下文分支和特征融合模块。 空间分支:现有的语义分割任务中,一些方法用空洞卷积保留输入图像的分辨率去编码足够的空间信息,另一些方法通过使用金字塔池化模块、ASPP或大的卷积核捕捉丰富的感受野,这些方法表明空间分辨率和感受野对达到较高的准确率是至关重要的。然而在实时语义分割中很难同时满足两种要求。本文提出了空间分支路径,保留原始输入图像的空间尺寸并编码丰富的空间信息。空间分支主要包含三层,每一层包括一个步长为2的3*3卷积、bn和relu。最终空间分支得到的特征图是原图的1/8。 上下文分支:为了兼顾感受野的大小和实时性两个因素,上下文分支采用轻量级和全局平均池化去提供更大的感受野。轻量级模型可以快速的下采样从而获得更大的感受野,来编码高级特征的上下文信息;然后,使用全局平均池化提供具有全局上下文信息的最大感受野。最后,结合全局池化上采样输出的特征图和轻量级模型的特征图。为了改善特征。作者提出了ARM。ARM使用全局平均池化去捕捉全局上下文并且计算一个注意力向量去引导特征学习。这个设计可以使特征图更加精细。 特征融合模块:两个分支所提取的特征是不同level的。所以不能简单把两者相加。空间分支捕捉空间信息编码更丰富的细节信息,上下文分支主要编码了上下文信息。空间分支的特征是低级特征的,而上下文分支的特征是高级特征的,因此本文提出了专门的特征融合模块。 |
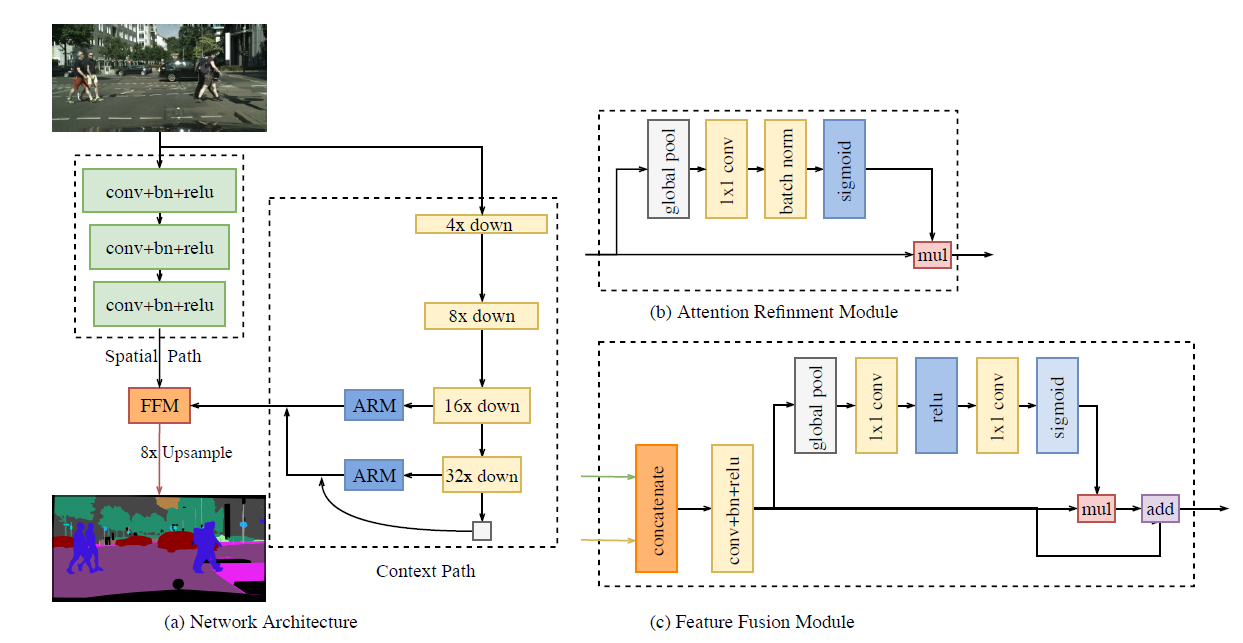 |
| DFANet | 实时语义分割网络,用于资源约束下的语义分割。网络从单个轻量级网络框架开始,分别通过子网和子阶段级联聚合判别特征。网络级聚合可以看成是用后一个网络优化前一个网络生成的特征图。阶段级聚合的目标是不同网络的层之间传递语义和空间信息,来解决深度增加造成的空间细节信息丢失问题。编码器为三个改进的轻量级Xception网络,由网络级特征聚合和阶段级特征聚合链接在一起。解码器则是简单地将特征图按尺寸上采样后融合在一起。作者认为在ImageNet上预训练的网络中全连接层具有强大的全局特征提取能力,因此保留了网络的全连接层作为全连接注意力模块的一部分,在其后接一个1×1卷积,并将结果和全连接层之前的特征层按通道相乘。解码器将三个网络输出的深层特征融合,并用双线性插值的方式上采样至4倍尺寸,网络的浅层特征融合,最后上采样4倍至原图尺寸。 | 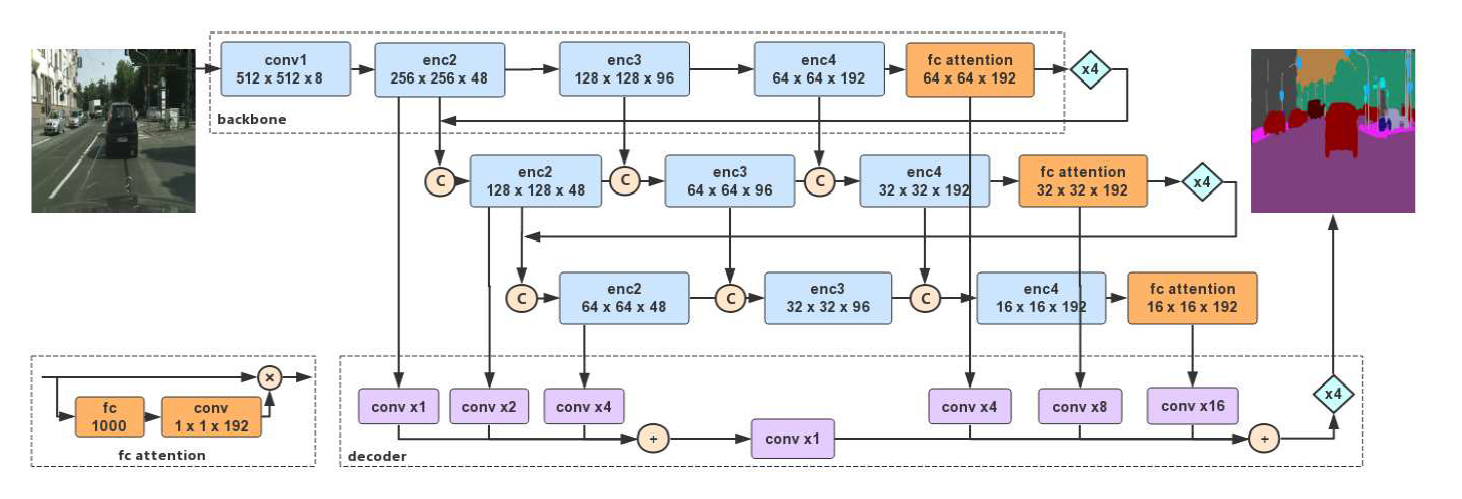 |
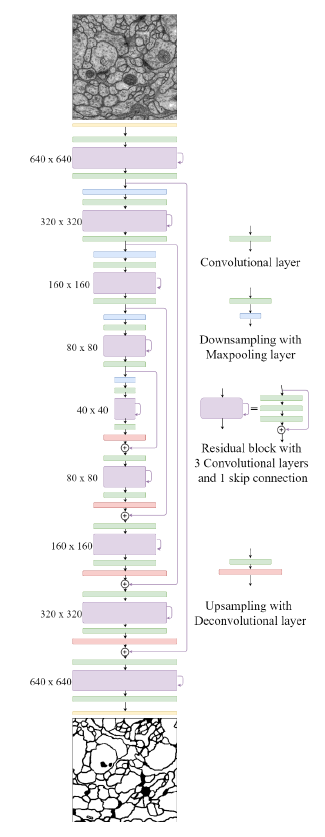
| RedNet | 基于FCN的主流分割网络一般分为两种类型:编码器-解码器结构和空洞卷积。本文选择了编解码结构,构建了应用于室内的RGB-D分割网络,该结构将残差块作为编码器和解码器路径中的基本构件,提出了金字塔监督训练方案以优化网络。由于物体之间的颜色和结构的高度相似性以及室内环境中的照明不均匀,准确的室内语义分割是一个挑战性问题。算法分为ResNet34和ResNet50两种情况。 | 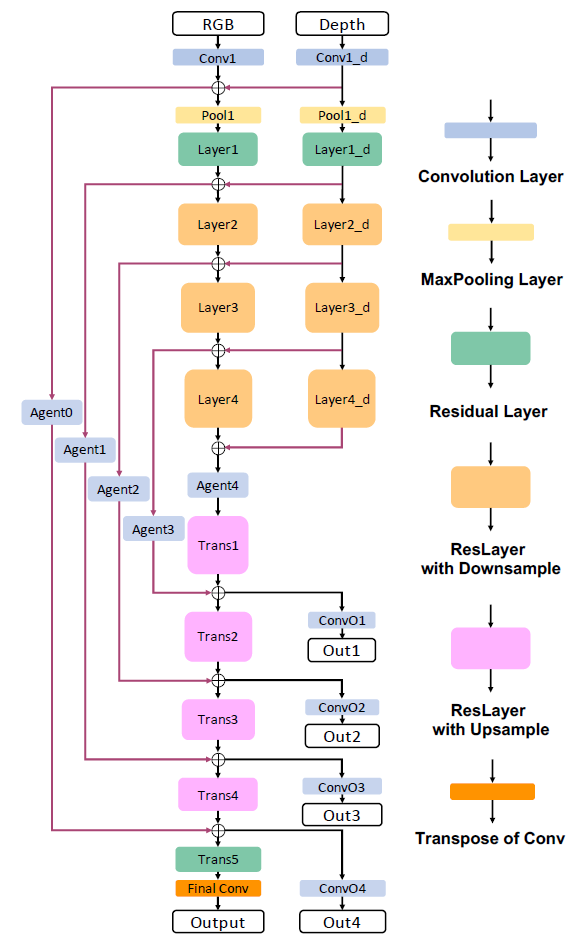 |
| RefineNet | 多路径优化网络,可明确利用下采样过程中的所有可用信息,以使用残差连接实现高分辨率预测,并引入链式残差池化结构,有效地捕捉丰富地上下文信息。 反卷积不能恢复low-level特征图,Deeplab系列使用空洞卷积来解决这一问题,但是空洞卷积仍有两个缺点:对高分辨率特征图进行卷积会消耗大量算力,同时也需要大的GPU内存。空洞卷积的特性决定了它会损失一些细节信息。RefineNet是一种多路径的提炼网络,利用多级抽象特征进行高分辨率的语义分割。级联的RefineNet可以进行端到端训练,使用了残差结构和跳跃连接。并提出了链式残差池化模块。 |
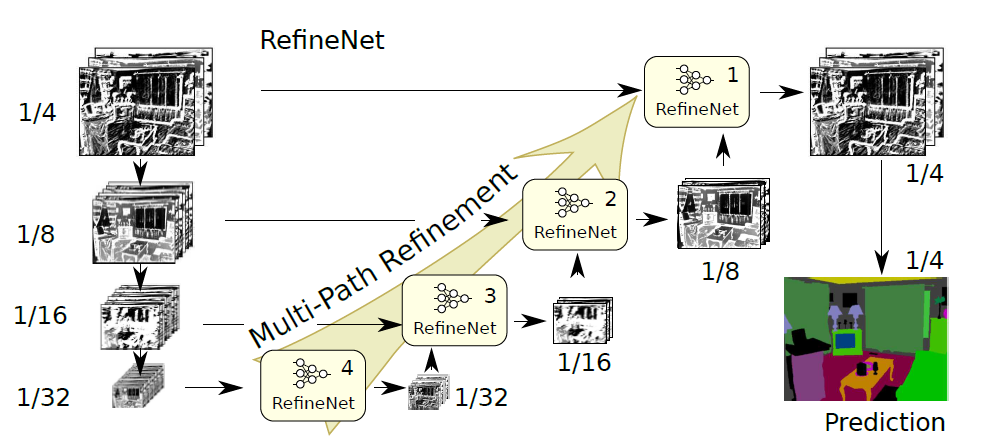 |
| Light-weight RefineNet | 将RefineNet改编为更加紧凑地架构,使其适用于需要在高分辨率输入上实现实时性能的任务。 将RefineNet中的3×3卷积替换为1×1卷积 |
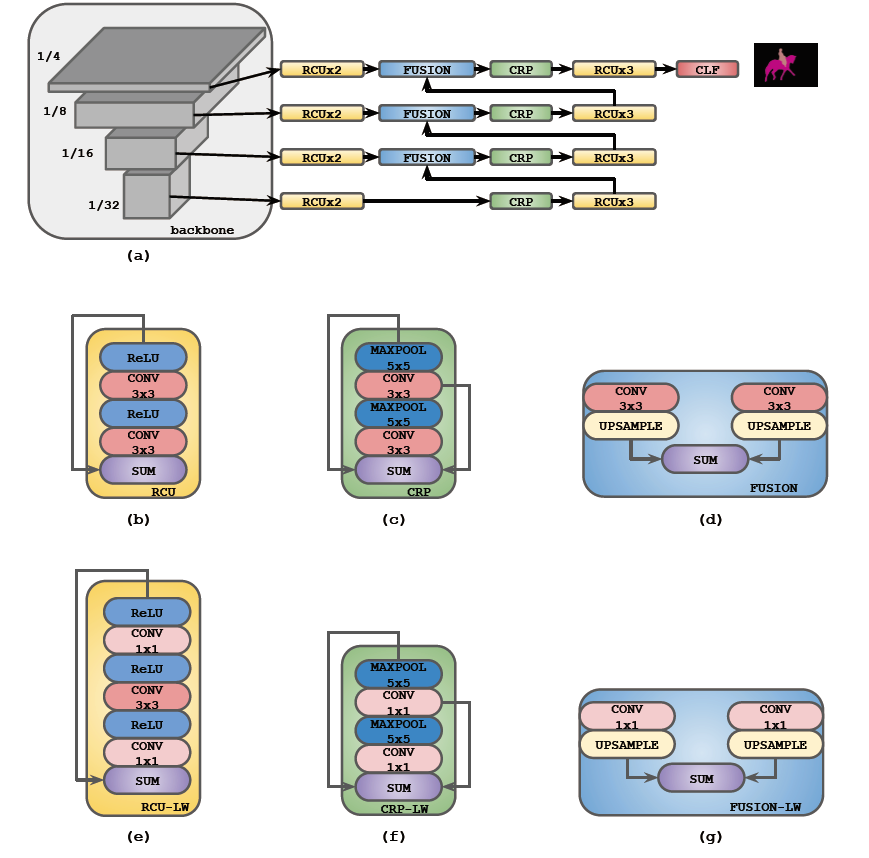 |
| RDFNet | 在使用RGB-D数据的多类室内语义分割中,已经表明将深度特征合并到RGB特征中有助于提高分割精度。但是先前的研究尚未充分利用多模式特征融合的潜力,RDFNet网络通过包含多模式特征融合模块和多级特征优化模块,有效地捕获了多级RGB-D特征。特征融合模块利用残差结构学习RGB和深度特征及其结合,以充分利用其互补特征。特征细化块从多个级别学习融合特征的组合,以实现高分辨率预测。 重新设计了融合模块,更好的针对RGB和深度图,后期沿用RefineNet中的Refine模块进行后端优化。 |
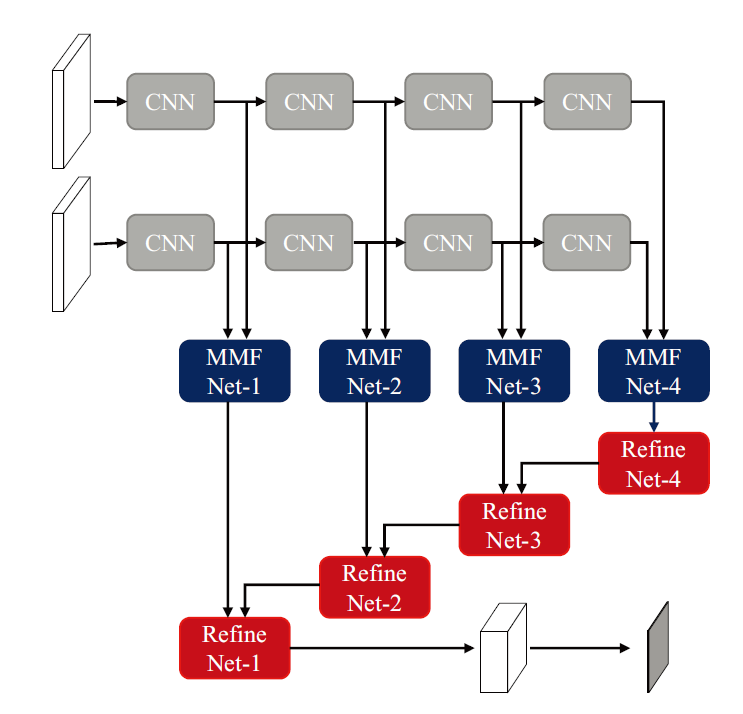 |
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167241.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
